一种围术期患者数据降维装置及样本数据集获取系统
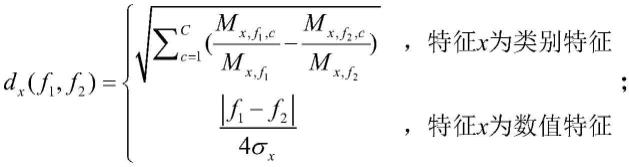
1.本发明涉及计算机技术领域,尤其涉及一种围术期患者数据降维装置及样本数据集获取系统。
背景技术:
2.围术期即围手术期,围手术期是围绕手术的一个全过程,从病人决定接受手术治疗开始,到手术治疗直至基本康复,包含手术前、手术中及手术后的一段时间,具体是指从确定手术治疗时起,直到与这次手术有关的治疗基本结束为止,时间约在术前5-7天至术后7-12天。
3.据世界卫生组织(who)发布的《world health statistics 2021》报告数据来看,全球人口预期寿命增加到73.3岁,预计到2050年,全球老年人将超过15亿人。世界各地不断增加的老年人口已被确定为外科手术市场的主要人群,且老年患者的风险事件预测已经成为了热门研究方向之一。对老年手术患者群体进行术后风险预测,有助于医生制定诊治计划,合理配置救治资源,进而降低术后风险事件发生的概率。目前,一些诊断工具可以帮助医院为高风险病人提供全面、可靠的救治,如公开号为cn111009322a和cn114038565a的中国专利已公开了基于患者围术期数据集利用预测模型进行围术期风险评估,然而,在患者围术期数据集中,多存在数据维度较高的问题,这会直接影响到围术期预测模型的运行效率,但盲目降维又会使得降低围术期预测模型的预测效果。
技术实现要素:
4.本发明旨在解决现有技术中存在的技术问题,提供一种围术期患者数据降维装置及样本数据集获取系统。
5.为了实现本发明的上述目的,根据本发明的第一个方面,本发明提供了一种围术期患者数据降维装置,包括:输入模块,获取患者的包含多维特征的原始围术期特征数据,以及原始围术期特征数据对应的分类标签;初次降维模块,基于主成分分析算法对原始围术期特征数据进行降维处理获得第一围术期特征数据;二次降维模块,基于遗传算法对第一围术期特征数据进行降维处理获得围术期特征数据;输出模块,输出围术期特征数据。
6.上述技术方案:结合了主成分分析算法和遗传算法进行数据降维,先通过主成分分析算法进行初次降维,得到可以良好代表原始围术期特征数据的第一围术期特征数据,再以第一围术期特征数据作为遗传算法的输入,第一围术期特征数据作为遗传算法的启发数据集,这样,遗传算法的初始种群就是一个相对原始围术期特征数据来说纬度较低且较优的组合,为进一步特征选择营造小规模的搜索范围,可以达到提高运行效率,筛选出对后续分类处理更有利的更低维的围术期特征数据,加快后续分类处理运行效率的同时保持较高的分类效果。
7.为了实现本发明的上述目的,根据本发明的第二个方面,本发明提供了一种围术期患者样本数据集获取系统,包括:数据获取模块,用于获取多个患者的原始围术期特征数
据和病例;分类标签集获取模块,基于多个病例获取分类标签集合,分类标签表征围术期患者风险事件;分类标签关联模块,用于将患者的原始围术期特征数据与分类标签集中至少一个分类标签关联对应;以及本发明第一方面所述的围术期患者数据降维装置,对所有患者的原始围术期特征数据进行降维处理获得对应的围术期特征数据;样本数据集获取模块,以患者的围术期特征数据作为样本,为样本关联原始围术期特征数据对应的分类标签集,获得围术期患者的样本数据集。
8.上述技术方案:构建了围术期患者的多分类标签样本数据集,该数据集中样本的特征维度较低能够加快后续分类处理、模型训练的效率,同时样本中的特征均为对后续分类影响较大的特征,能使后续分类具有较好的表现效果。
附图说明
9.图1是本发明实施例1中围术期患者数据降维装置的结构示意图;
10.图2是本发明实施例2中围术期患者样本数据集获取系统的结构示意图;
11.图3是本发明实施例3中样本数据集均衡方法流程示意图;
12.图4是本发明实施例4中样本数据集均衡装置结构示意图;
13.图5是本发明实施例5中样本数据集获取系统的结构示意图;
14.图6是本发明实施例6中围术期患者数据多标签分类方法的流程示意图;
15.图7是实施例6中分类模型的结构示意图;
16.图8是实施例6中围术期患者数据多标签分类方法的一种优选流程示意图;
17.图9是本发明实施例7中围术期患者数据多标签分类装置的结构示意图;
18.图10是本发明实施例8中围术期患者风险事件预测系统的结构示意图。
具体实施方式
19.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
20.在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
21.在本发明的描述中,除非另有规定和限定,需要说明的是,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是机械连接或电连接,也可以是两个元件内部的连通,可以是直接相连,也可以通过中间媒介间接相连,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
22.实施例1
23.本实施例公开了一种围术期患者数据降维装置,如图1所示,该装置包括:
24.输入模块,获取患者的包含多维特征的原始围术期特征数据,以及原始围术期特征数据对应的分类标签;
25.初次降维模块,基于主成分分析算法对原始围术期特征数据进行降维处理获得第一围术期特征数据;
26.二次降维模块,基于遗传算法对第一围术期特征数据进行降维处理获得围术期特征数据;
27.输出模块,输出围术期特征数据。
28.在本实施例中,为更好的体现患者围术期状态,提高后续分类处理准确性,以及规避术后患者数据不易收集管理的问题,优选地,原始围术期特征数据包括患者术前、术中的指标数据,如术前的血压、心率、血脂等,术中的心率、血压、失血量、手术时长等。与现有的部分分类预测模型中只纳入手术患者的术前基础状况并未考虑手术进行中的具体情况不同,众多研究已经证实,术中心率、血压、失血量、手术时间等术中指标均与患者的手术术后情况相关,因此本实施例提供的原始围术期特征数据能够提高后续模型预测术后事件的准确性,并且不依赖术后患者指标数据。
29.在本实施例中,分类标签用于表征围术期患者风险事件,围术期患者风险事件优选但不限于包括非计划再入院、死亡。
30.在本实施例中,为提高数据的丰富性,指标数据包括类别数据和数值数据,类别数据为通过类别表示指标数据,比如术中出血量可用多、中、少来表示,数值数据用数值表示指标数据,如血压值。
31.在本实施例中,原始围术期特征数据可为已知围术期患者风险事件的患者的数据,因此,可将已知围术期患者风险事件作为原始围术期特征数据关联对应的分类标签。原始围术期特征数据也可为未知围术期患者风险事件的患者的数据,由专家给原始围术期特征数据设置对应的分类标签。原始围术期特征数据对应的分类标签可以为一个、两个或多个。
32.在本实施例中,经过主成分分析算法处理后,第一围术期特征数据的特征维度小于原始围术期特征数据的特征维度,基于第一围术期特征数据构建遗传算法的初始种群。
33.在本实施例中,为通过遗传算法对第一围术期特征数据进一步降维,优选地,二次降维模块包括:
34.初始种群设置单元,基于第一围术期特征数据设置个体,个体的基因数小于等于第一围术期特征数据中的特征总数,多个个体组成初始种群;个体的基因为第一围术期特征数据中的特征,在满足个体的基因数小于等于第一围术期特征数据中的特征总数的条件下,可随机设置每个个体的基因数;
35.进化迭代单元,重复执行以下过程直到达到终止条件,并输出达到终止条件时适应度最大的个体:获取本代种群中每个个体的适应度;从本代种群中基于个体的适应度选取部分个体作为下一代种群的个体;对下一代种群的个体进行交叉运算和变异运算。
36.在本实施例中,终止条件优选但不限于为进化迭代次数达到了预设的最大进化迭代次数,或者,进化迭代中个体的适应度最大值不再增加,或者,进化迭代中个体的适应度最大值增加幅度低于增幅阈值。每次迭代中,对本代种群中的个体的适应度进行从高到低排序,选取排名靠前的部分个体作为下一代种群的个体。交叉运算主要是对配对的父代的同点基因位进行交换,交换后获得子代,将子代作为下一代种群的个体。
37.在本实施例中,为使得降维后的围术期特征数据在后续分类处理中具有更优异的
表现,提高分类准确性,优选地,获取个体的适应度的过程:获取多个患者的原始围术期特征数据和对应的分类标签,按照个体的特征信息对多个原始围术期特征数据进行降维处理获得与个体特征一致的多个降维样本;将多个降维样本划分为降维训练集和降维测试集;构建降维多层感知神经网络;利用降维训练集对构建的降维多层感知神经网络进行训练获得降维分类预测模型;利用降维测试集对降维分类预测模型进行测试获得该模型的准确率,将该准确率作为个体的适应度。
38.实施例2
39.本实施例公开了一种围术期患者样本数据集获取系统,如图2所示,该围术期患者样本数据集获取系统包括:
40.数据获取模块,用于获取多个患者的原始围术期特征数据和病例;病例数据一般是文本数据,包括医生诊断、既往病史、术后随访记录等;
41.分类标签集获取模块,基于多个病例获取分类标签集合,分类标签表征围术期患者风险事件;
42.分类标签关联模块,用于将患者的原始围术期特征数据与分类标签集中至少一个分类标签关联对应,因此原始围术期特征数据对应有一个分类标签集,分类标签集包括至少一个分类标签;
43.以及实施例1提供的围术期患者数据降维装置,对所有患者的原始围术期特征数据进行降维处理获得对应的围术期特征数据;
44.样本数据集获取模块,以患者的围术期特征数据作为样本,为样本关联相应的原始围术期特征数据对应的分类标签集,获得围术期患者的样本数据集。
45.在本实施例中,优选地,分类标签集获取模块具体执行:对患者病例进行分词处理获得至少一个术后事件结果(术后事件结果即围术期患者风险事件),对多个患者的术后事件结果利用训练好的cbow模型进行相似词类比获得多个相似术后事件结果集合,将相似术后事件结果集合与事件字典匹配,从事件字典中查找与相似术后事件结果集合匹配的分类标签,多个分类标签构成分类标签集。
46.在本实施例中,将word2vec的cbow multi-word context model模型对大量医学语料库进行训练,通过pkuseg分词工具(pkuseg可以对多领域的单词进行分割,其中就包括医学领域的独立模型)将本实施例中的病例集对应的文本信息进行分词处理得到多个术后事件结果。事件字典优选但不限于为世界卫生组织发布的统一国际疾病分类规范的中文版icd-11事件字典,事件字典中包含有很多分类标签。相似术后事件结果集合与事件字典是否匹配优选但不限于通过语义相似度来判断,若两者语义相似度大于预设的相似度阈值,则认为两者匹配,否则不匹配。
47.在本实施例中,优选地,为对数据中的缺失值进行填补,提升数据质量,还包括缺失填补装置,用于对患者的原始围术期特征数据中的缺失值进行填补处理,并将填补处理后的原始围术期特征数据输入围术期患者数据降维装置进行降维处理。缺失填补装置优选但不限于通过现有的randomforestregressor填补法或missforest填补法或均值mean填补法或中位数填补法进行填补处理。
48.在本实施例中,进一步优选地,缺失填补装置基于贝叶斯高斯过程隐变量模型对原始围术期特征数据进行缺失填补处理。
49.在本实施例中,对于缺失值的数据填补不可避免地会给原始围术期特征数据集引入不确定性。本实施例运用贝叶斯高斯过程隐变量模型(bayesian gaussian process latent variable model,bgplvm)来进行数值型特征的缺失值填补,具体包括:
50.首先,近似地计算观察到的测试数据向量y
*
∈rn×m的概率密度p(y
*
|y)(其中n为病人样本总数,m为特征总数),与观测值y
*
相关的隐变量的变分分布为q(x
*
)。当模型参数和隐变量被学习到后,bgplvm可以用来估计缺失值:其中是向量y
*
中可以观察到的值,是需要预测的缺失值。给定部分观察到的点y
*
,本实施例希望重建丢失的部分通过在一个小型完整数据集上学习对可观察变量的低维embedding,来填补缺失数据集。将bgplvm在完整的数据集d上进行训练,引入隐变量x和新的测试隐变量x
*
,如前所述表示单个病人测量值的行向量,代表已知观测值,表示缺失值,通过最大化下面概率密度,得到y
*
对应的隐变量x
*
的高斯概率分布。
[0051][0052]
接下来,通过最大化在的变分下界来优化变分分布q(x
*
),保持除q(x
*
)之外的所有优化量不变。为了预测缺失值本发明采用标准高斯过程预测方法,同时将输入x
*
的不确定因素也考虑进去,因为x
*
存在分布q(x
*
)。与gp预测形式相似,为了预测本发明先预测即与y
*
对应的隐函数值
[0053][0054]
对x
*
的边缘化会产生非高斯完全依赖的多元密度,但基于平方指数核,是可以分析处理的,在本发明中本发明用到了的均值和协方差,均值可以为本发明提供缺失值的估计,方差则可以量化与均值估计相关的不确定性。通过bgplvm模型,在训练集学习得到的隐空间和模型超参数,通过分布得到对于每个包含缺失值的特征的平均估计。
[0055]
在本实施例中,为便于数据处理,进一步优选地,还包括编码装置,用于对原始围术期特征数据进行编码处理,将编码处理后的数据输入缺失填补装置。编码装置优选但不限于采用现有的one-hot编码规则进行编码。
[0056]
在本实施例中,为便于数据处理,进一步优选地,还包括归一化装置,用于对编码处理后的原始围术期特征数据进行归一化处理,并将归一化处理后的数据输入缺失填补装置。归一化装置优选但不限于采用标准差归一化方法进行归一化处理。
[0057]
实施例3
[0058]
本实施例提供一种围术期患者的样本数据集均衡方法,如图3所示,该样本数据集均衡方法包括:
[0059]
步骤s1,对围术期患者的样本数据集中的少数类标签样本进行过采样获得合成样本,为合成样本生成对应的合成标签集,样本数据集包括多个样本以及与样本对应的分类标签集;每个样本代表一个患者的围术期特征数据集,可以是原始围术期特征数据或者实
施例1中原始围术期特征数据降维后获得的围术期特征数据,样本的分类标签关联过程已在实施例1中详细阐述,在此不再赘述。
[0060]
步骤s2,将合成样本和合成标签集加入样本数据集获得临时样本数据集;
[0061]
步骤s3,对临时样本数据集中的样本进行清洗获得均衡样本数据集。
[0062]
在本实施例中,可通过smote或svm smote或borderlinesmote或k-means smote或smote-nc对围术期患者的样本数据集中的少数类标签样本进行过采样获得合成样本以及为合成样本生成对应的合成标签集。优选地,为提升平衡效果,采用mlsmote算法对围术期患者的样本数据集中的少数类标签样本进行过采样获得合成样本以及为合成样本生成对应的合成标签集。mlsmote算法即多标签合成少数类过采样技术(multi label synthetic minority over-sampling technique,mlsmote),常用于处理多标签分类任务中数据不平衡问题,其生成过程包括:采用不平衡率imbalance rate(ir)选择少数类标签;最近邻居搜索:一旦属于少数标签的样本被选中为种子样本,就要搜索它的最近邻居;特征集生成:选择一个邻域后,通过插值获得合成样本;合成标签集的产生:对于产生的合成样本需要合成标签集。
[0063]
在本实施例中,由于mlsmote等过采样合成少数类样本算法在合成少类标签样本的过程中会产生一些噪声样本,对于这些噪声样本的清洗十分必要,因此设置步骤s3以提升样本数据集质量。
[0064]
在本实施例中,优选地,为快速判断出样本数据集中的少数类标签,计算每个分类标签相应的样本数量与样本数据集的总样本数量的比值,将比值小于比值阈值的分类标签作为少数类分类标签,大于等于比值阈值的分类标签作为多数类分类标签,比值阈值优选但不限于小于0.2。
[0065]
在本实施例中,每个少数类分类标签需要生成的样本数量为该少数类分类标签的过采样率。为更好地确定每个少数类分类标签的过采样率,使得获得的均衡样本数据集应用于后续分类时表现效果更好,优选地,在步骤s1中,基于遗传算法为每个少数类标签设置过采样率,具体包括:
[0066]
步骤s11,设样本数据集中包括w个少数类标签,将w个少数类标签的样本的过采样率作为个体的w个基因,w为正整数;每个基因代表一个少数类分类标签的过采样率,利用多个个体构建初始种群,初始种群包括多个初始个体,每个初始个体的w个基因数值大小为通过随机选取获得,优选地,可为每个少数类分类标签的过采样率设置数值范围,当构建初始种群时在该数值范围类随机选取数值作为基因数值,数值范围可根据需要设置;
[0067]
步骤s12,重复执行以下进化迭代过程直到达到终止条件:获取本代种群中每个个体的适应度;从本代种群中基于个体的适应度选取部分个体作为下一代种群的个体;对下一代种群的个体进行交叉运算和变异运算;
[0068]
步骤s13,输出达到终止条件时适应度最大的个体。
[0069]
在本实施例中,终止条件优选但不限于为进化迭代次数达到了预设的最大进化迭代次数,或者,进化迭代中个体的适应度最大值不再增加,或者进化迭代中个体的适应度最大值增加幅度低于增幅阈值。每次迭代中,对本代种群中的个体的适应度进行从高到低排序,选取排名靠前的部分个体作为下一代种群的个体。
[0070]
在本实施例中,为使得获得的均衡样本数据集应用于后续分类时表现效果更好,
优选地,获取个体的适应度的过程:
[0071]
基于个体基因信息得到少数类标签过采样率组合;过采样率组合包括所有少数类标签的过采样率;
[0072]
基于少数类标签过采样率组合对围术期患者的样本数据集中的少数类标签样本进行过采样获得合成样本以及合成样本的合成标签集,将合成样本和合成标签集加入样本数据集获得均衡样本集,将均衡样本集划分为均衡训练样本集和均衡测试样本集;
[0073]
构建均衡多层感知神经网络,利用均衡训练样本集训练均衡多层感知神经网络获得均衡预测分类模型,利用均衡测试样本集测试均衡预测分类模型获得均衡预测分类模型的准确率,将该准确率作为个体的适应度。
[0074]
在本实施例中,为有效地去除噪声样本,提升样本集的质量,优选地,步骤s3为对临时样本数据集中每个样本进行清洗处理,清洗处理过程包括:
[0075]
步骤s31,从临时样本数据集中选取种子样本,选择种子样本的k个近邻样本,k个近邻样本的分类标签组成近邻分类标签集,k为正整数;可依次选取临时样本数据集中的每个样本作为种子样本;
[0076]
步骤s32,基于近邻分类标签集通过贝叶斯条件概率预测种子样本的分类标签集,获得种子样本的预测分类标签集;
[0077]
步骤s33,判断种子样本的预测分类标签集与其在临时样本数据集中的分类标签集是否相同,若相同,保留该种子样本,若不相同,删除该种子样本,认为该种子样本为噪声样本。
[0078]
上述清洗过程直接基于种子样本近邻分类标签集通过贝叶斯条件概率预测种子样本的分类标签集,将获得的预测分类标签集与该种子样本在临时样本数据集中的真实分类标签集进行比较判断,不会依赖于分类器判定,仅依赖数据本身判定,减少运算量,提高判断效率和准确率。
[0079]
在本实施例中,进一步优选地,在步骤s31中,选择种子样本的k个近邻样本的具体过程包括:
[0080]
获取种子样本分别与临时样本数据集中全部或部分样本的异类值差度量hvdm;hvdm为heterogeneous value difference metric的缩写;
[0081]
利用临时样本数据集中样本的全局不平衡权重对异类值差度量hvdm进行修正获得修正异类值差度量;
[0082]
对临时样本数据集中所有样本与种子样本的修正异类值差度量进行排序,选取前k个修正异类值差度量较大的样本作为种子样本的k个近邻样本。优选地,可对修正异类值差度量进行从高到底排序,选取前k个修正异类值差度量值较大的样本作为种子样本的k个近邻样本。
[0083]
上述选择种子样本的k个近邻样本的过程中采用加权knn(weighted knn,wknn)的方法来提升合成样本质量。假如样本数据集中真实的少数类标签样本分布非常分散,即空间稀疏,那么在mlsmote等算法执行过程中合成的少数类样本还是会分散稀疏,在局部角度来说依旧没有平衡。若直接使用knn清洗时,会大几率将稀疏的少数类样本和mlsmote合成的新少数类样本剔除掉,这样不能建立恰当的分类边界,因此,需要引入距离加权的思想来协调knn清洗,也就是达到面对稀疏的分布样本时,不盲目地直接删掉,而是将局部空间密
度(即异类值差度量hvdm和样本的全局不平衡权重)考虑进来,尽可能的保留小样本。knn的清洗主要依靠近邻样本的标签集,所以对于近邻的距离计算在数据分布稀疏时显得尤为重要,这也是加入距离加权(即利用临时样本数据集中样本的全局不平衡权重对异类值差度量hvdm进行修正)的主要原因。wknn来清洗噪声样本,改变计算近邻样本的距离(对修正异类值差度量进行了修正),也就是考虑了局部密度影响,以样本异类值差度量表示样本之间的距离。
[0084]
在本实施例中,进一步优选地,种子样本与临时样本数据集中样本的异类值差度量hvdm的计算公式为:
[0085][0086]
其中,f1表示种子样本的特征向量;f2表示临时样本数据集中除种子样本之外的任一样本的特征向量;hvdm(f1,f2)表示特征向量f1与f2的异类值差度量;d(f1,f2)表示特征向量f1和f2之间的距离;n表示临时样本数据集中样本的特征维数;x表示特征索引;d
x
(f1,f2)表示特征向量f1和特征向量f2在特征x上的距离,d
x
(f1,f2)通过如下公式获取:c表示当特征x为类别特征时该特征的类别数,c表示特征x的类别索引,表示临时样本数据集中特征x属于特征向量f1且特征x的类别特征为c的样本数;表示临时样本数据集中特征x属于特征向量f2且特征x的类别特征为c的样本数;表示临时样本数据集中特征x属于特征向量f1的样本数;表示临时样本数据集中特征x属于特征向量f2的样本数;|f
1-f2|表示特征向量f1与f2差值的绝对值;σ
x
表示临时样本数据集中特征x的标准差。
[0087]
在本实施例中,进一步优选地,种子样本与临时样本数据集中样本的修正异类值差度量的计算公式为:
[0088][0089]
其中,f1表示种子样本的特征向量;f2表示临时样本数据集中除种子样本之外的任一样本的特征向量;hvdm(f1,f2)表示特征向量f1与f2的异类值差度量;dw(f1,f2)表示特征向量f1与f2的修正异类值差度量;n表示临时样本数据集中样本的特征维数;iw表示特征向量为f2的样本的全局不平衡权重,iw=ir
nn
/(ir
+
+ir-),ir
+
表示临时样本数据集中所有少数类分类标签总不平衡率,ir-表示临时样本数据集中所有多数类分类标签总不平衡率,ir
nn
为特征向量为f2的样本的分类标签集中所有分类标签的总不平衡率。
[0090]
上述清除噪声样本过程中,wknn计算距离时使用heterogeneous value difference metric(hvdm)进行距离度量,并以样本的全局不平衡权重iw为权重系数对hvdm进行修正。对于临时样本数据集中,当分类标签集包含的少数类标签越多,ir
nn
越大iw会越大;对于少数类标签样本分布稀疏,不平衡率大的临时样本数据集,将iw引入hvdm距离
来能提高少数类样本密度。
[0091]
从公式可以看到,加权系数的值可以缩放hvdm(f1,f2),近邻样本分类标签集中的少数类标签越多则加权系数会越小。在种子样本的近邻样本集的iw越大时,即近邻样本标签集包含的少数类标签越多时,对应的近邻样本的加权系数就越小,这样呈现单调递减的形式,可以维持:在特征维度固定的情况下,近邻样本的加权系数会因为其标签集中包含的多数类和少数类标签的情况而不同程度的放缩;当特征维度增多时,也就是样本分布逐渐稀疏时,放缩系数也跟着变小。
[0092]
可以看出wknn可以帮助为标签集包含少数类标签较多的样本筛选近邻样本时,考虑进去近邻样本标签集中标签的分布情况,让标签集中少数类标签更多的样本向种子样本靠拢,增大局部少数类标签密度,同时减少多数类标签密度。整体流程为:首先运用mlsmote对少数类标签的样本进行上采样,与原始样本组成较为平衡的临时新样本集,在此新样本集上,给每一个样本进行wknn过程,也就是基于加权的hvdm排序出k近邻个样本,然后根据近邻样本预测出种子样本的标签集,若预测标签集和种子标签集情况一样,则保留样本,否则删除
[0093]
实施例4
[0094]
本实施例公开了一种围术期患者的样本数据集均衡装置,如图4所示,该样本数据集均衡装置包括:
[0095]
样本合成模块,对围术期患者的样本数据集中的少数类标签样本进行过采样获得合成样本,为合成样本生成对应的合成标签集,样本数据集包括多个样本以及样本对应的分类标签集;
[0096]
临时样本数据集获取模块,将合成样本和合成标签集加入样本数据集获得临时样本数据集;
[0097]
清洗模块,对临时样本数据集中的样本进行清洗获得均衡样本数据集。
[0098]
在本实施例中,优选地,清洗模块包括:
[0099]
近邻样本获取单元,从临时样本数据集中选取种子样本,选择种子样本的k个近邻样本,k个近邻样本的分类标签组成近邻分类标签集,k为正整数;
[0100]
预测分类标签集获取单元,基于近邻分类标签集通过贝叶斯条件概率预测种子样本的分类标签集,获得种子样本的预测分类标签集;
[0101]
清洗单元,判断种子样本的预测分类标签集与其在临时样本数据集中的分类标签集是否相同,若相同,保留该种子样本,若不相同,删除该种子样本。
[0102]
在本实施例中,进一步优选地,近邻样本获取单元选择种子样本的k个近邻样本的具体过程包括:
[0103]
获取种子样本分别与临时样本数据集中全部或部分样本的异类值差度量hvdm;
[0104]
利用临时样本数据集中样本的全局不平衡权重对异类值差度量hvdm进行修正获得修正异类值差度量;
[0105]
对临时样本数据集中所有样本与种子样本的修正异类值差度量进行排序,选取前k个修正异类值差度量较大的样本作为种子样本的k个近邻样本。
[0106]
对本实施例提供的样本数据集均衡装置的均衡效果进行试验验证,结果如下:
[0107][0108][0109]
ir表示样本集的不平衡率imbalance rate,ir越大表示样本集越不均衡,从上表实验结果可以看出,本实施例提供的均衡装置的最大ir、平均ir是最小的,并且ir的最大值和均值之间的间隔被拉近,说明样本集的均衡性更好。
[0110]
实施例5
[0111]
本实施例也公开了一种围术期患者样本数据集获取系统,相比实施例2本实施例增加了样本数据集均衡装置,即对实施例2中获得的降维后获得样本数据集进行样本均衡处理,该装置的结构示意图如图5所示,包括:
[0112]
数据获取模块,用于获取多个患者的原始围术期特征数据和病例;
[0113]
分类标签集获取模块,基于多个病例获取分类标签集合,分类标签表征围术期患者风险事件;
[0114]
分类标签关联模块,用于将患者的原始围术期特征数据与分类标签集中至少一个分类标签关联对应;
[0115]
围术期患者数据降维装置,对所有患者的原始围术期特征数据进行降维处理获得对应的围术期特征数据;
[0116]
样本数据集获取模块,以患者的围术期特征数据作为样本,为样本关联相应的原始围术期特征数据对应的分类标签集,获得围术期患者的样本数据集;
[0117]
还包括实施例4提供的围术期患者的样本数据集均衡装置,用于对样本数据集进行均衡处理。
[0118]
在本实施例中,优选地,还包括缺失填补装置,用于对患者的原始围术期特征数据中的缺失值进行填补处理,并将填补处理后的原始围术期特征数据输入围术期患者数据降维装置进行降维处理。
[0119]
实施例6
[0120]
本实施例6公开了一种围术期患者数据多标签分类方法,如图6所示,该多标签分类方法包括:
[0121]
步骤a,获取待分类患者特征数据;待分类患者特征数据为围术期患者的特征数据,可包括多维特征。为提高待分类患者特征数据的可处理性、降低维度,提升质量,可依次对待分类患者特征数据进行编码处理、归一化处理,以及按照实施例1提供的围术期患者数据降维装置输出的样本的特征维度进行降维处理,将降维处理后的待分类患者特征数据输入训练好的分类模型。
[0122]
步骤b,将待分类患者特征数据输入训练好的分类模型,分类模型输出分类结果,
分类结果包括一个以上分类标签以及每个分类标签的分类置信度;分类标签的分类置信度表示待分类患者特征数据属于该分类标签的概率。分类模型包括基于stacking的分类集成模型、标签关联规则获取模块和融合模块,融合模块用于融合分类集成模型输出的分类矩阵和标签关联规则获取模块输出的关联规则矩阵以获得分类结果,融合的方式优选但不限于将分类矩阵和关联规则矩阵相乘。
[0123]
在实施例中,优选地,分类模型的结构示意图如图7所示,分类集成模型包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;第一多分类模型、第二多分类模型、第三多分类模型分别对待分类患者特征数据进行多标签分类处理获得第一初级分类结果、第二初级分类结果、第三初级分类结果;逻辑回归模型对第一初级分类结果、第二初级分类结果、第三初级分类结果进行处理获得分类矩阵。
[0124]
在本实施例中,优选地,第一多分类模型、第二多分类模型、第三多分类模型分别为ranking-svm模型、分类多层感知神经网络模型、binary relevance模型。ranking-svm模型和binary relevance模型是stacking集成中比较常规的基础模型,用在这里进行模型集成可靠性较高。分类多层感知神经网络模型采用多层感知神经网络结构(即mlp网络结构),能够避免过拟合问题,并且复杂度较低。
[0125]
在本实施例中,优选地,还包括构建围术期患者的样本数据集的步骤,如图8所示,构建围术期患者的样本数据集的步骤优选但不限于采用实施例2或实施例5的系统进行构建。
[0126]
在实施例中,如图7所示,分类集成模型的训练过程为:
[0127]
构建围术期患者的样本数据集,样本数据集中每个样本关联一个以上分类标签,将样本数据集划分为分类训练集和分类测试集,分类标签的关联可采用人工方式进行;
[0128]
构建分类集成模型,即上述的基于stacking集成模型,其包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;
[0129]
利用分类训练集对分类集成模型进行训练,利用分类测试集对训练后的分类集成模型进行测试验证。在验证中,使用randomizedsearchcv和gridsearchcv在训练集上进行交叉验证,通过f1_micro得分进行超参数的选择。
[0130]
在本实施例中,如图7所示,优选地,关联规则获取模块执行以下步骤:
[0131]
获取围术期患者的样本数据集,样本数据集中每个样本关联一个以上分类标签;样本数据集优选但不限于为实施例2或实施例5中获取的围术期患者样本数据集,即为标准患者数据集。
[0132]
对样本数据集中的分类标签进行关联规则挖掘获得关联规则矩阵。关联规则矩阵包括所有分类标签中任意两个分类标签之间的关联置信度。
[0133]
在本实施例中,如图7所示,进一步优选地,当样本数据集中分类标签的数量较少,具体的当少于数量阈值时,直接通过fp-growth算法对样本数据集中的分类标签进行关联规则挖掘。首先,建立如图7所示的分类标签矩阵,该分类标签矩阵中首行为各标签,首列为患者编号;之后,利用fp-growth算法对分类标签矩阵进行关联规则分析处理,输出任意两个分类标签之间的关联置信度,关联置信度取值范围为0到1。基于这些关联置信度建立如图7所示的关联规则矩阵,在关联规则矩阵中,首行和首列均为分类标签,矩阵内的元素代表该元素所在行和列的分类标签之间的关联置信度,如图7中,a(n-1)表示分类标签n与分
类标签1之间的关联置信度。
[0134]
在本实施例中,优选地,当样本数据集中分类标签数量较多时,分类标签之间的相关性模式会存在不同,直接进行关联分析会造成频繁项集寻找过程复杂等,影响关联分析准确性,具体的,当分类标签数量大于等于数量阈值时,数量阈值优选但不限于为3或4或5。对样本数据集中的分类标签进行关联规则挖掘获得关联规则矩阵的步骤,具体包括:
[0135]
对样本数据集中的分类标签进行聚类获得一个以上聚类簇;优选但不限于采用k-means++算法进行聚类处理;对每个聚类簇中的分类标签进行关联规则挖掘获得关联规则子矩阵。在融合时,将分类矩阵按照聚类结果划分为一个以上子分类矩阵,一个聚类簇对应一个子分类矩阵,将子分类矩阵与该聚类簇对应的关联规则子矩阵相乘获得该聚类簇的分类子结果,所有分类子结果组成分类结果。
[0136]
在本实施例中,进一步优选地,通过fp-growth算法对每个分类簇中的分类标签进行关联规则挖掘获得关联规则子矩阵,其获取过程图7中过程一致,已在上述优选方案中详细说明,在此不再赘述。
[0137]
实施例7
[0138]
本实施例公开了一种围术期患者数据多标签分类装置,如图9所示,包括:
[0139]
数据获取模块,用于获取待分类患者特征数据;
[0140]
分类模块,用于将待分类患者特征数据输入训练好的分类模型,分类模型输出分类结果,分类结果包括一个以上分类标签以及每个分类标签的分类置信度;分类模型包括基于stacking的分类集成模型、标签关联规则获取模块和融合模块,融合模块用于融合分类集成模型输出的分类矩阵和标签关联规则获取模块输出的关联规则矩阵以获得分类结果。
[0141]
在本实施例中,优选地,分类集成模型包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;第一多分类模型、第二多分类模型、第三多分类模型分别对所述待分类患者特征数据进行多标签分类处理获得第一初级分类结果、第二初级分类结果、第三初级分类结果;逻辑回归模型对第一初级分类结果、第二初级分类结果、第三初级分类结果进行处理获得分类矩阵。
[0142]
在本实施例中,优选地,还包括分类集成模型训练模块,分类集成模型训练模块执行以下过程:
[0143]
构建围术期患者的样本数据集,样本数据集中每个样本关联一个以上分类标签,将样本数据集划分为分类训练集和分类测试集;优选但不限于通过实施例2或实施例5提供的系统构建围术期患者的样本数据集;
[0144]
构建分类集成模型;分类集成模型包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;
[0145]
利用分类训练集对分类集成模型进行训练,利用分类测试集对训练后的分类集成模型进行测试验证。
[0146]
在本实施例中,该分类装置搭建结合关联规则分析的围术期术后事件多标签的分类集成模型。术后可能出现多种术后风险事件,针对术后多事件结果进行研究预测,通过集成ranking-svm模型和多层感知神经网络模型与binary relevance模型,搭建多标签预测模型,为进一步提升模型的稳定性、准确率,融合了关联规则到预测模型中进行优化。
[0147]
实施例8
[0148]
本实施例公开了一种围术期患者风险事件预测系统,如图10所示,包括:
[0149]
数据获取模块,用于获取待分类患者特征数据;
[0150]
分类模块,用于将待分类患者特征数据输入训练好的分类模型,分类模型输出分类结果,分类结果包括一个以上分类标签以及每个分类标签的分类置信度,每个分类标签对应一个围术期患者风险事件;
[0151]
分类模型包括基于stacking的分类集成模型、标签关联规则获取模块和融合模块,融合模块用于融合分类集成模型输出的分类矩阵和标签关联规则获取模块输出的关联规则矩阵以获得分类结果;
[0152]
转换模块,将分类结果中的分类标签转换为对应的围术期患者风险事件获得风险预测结果。
[0153]
在本实施例中,优选地,分类集成模型包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;第一多分类模型、第二多分类模型、第三多分类模型分别对所述待分类患者特征数据进行多标签分类处理获得第一初级分类结果、第二初级分类结果、第三初级分类结果;逻辑回归模型对第一初级分类结果、第二初级分类结果、第三初级分类结果进行处理获得分类矩阵。
[0154]
在本实施例中,优选地,还包括分类集成模型训练模块,分类集成模型训练模块执行以下过程:
[0155]
构建围术期患者的样本数据集,样本数据集中每个样本关联一个以上分类标签,将样本数据集划分为分类训练集和分类测试集;优选但不限于通过实施例2或实施例5提供的系统构建围术期患者的样本数据集;
[0156]
构建分类集成模型;分类集成模型包括第一多分类模型、第二多分类模型、第三多分类模型和逻辑回归模型;
[0157]
利用分类训练集对分类集成模型进行训练,利用分类测试集对训练后的分类集成模型进行测试验证。
[0158]
在本实施例中,实施例2或实施例5提供的系统样本数据集获取过程中,针对患者(尤其是老年手术患者)围术期内风险事件进行预测,在改进缺失及不平衡数据集的基础上,融合关联规则分析,搭建术后事件多标签预测模型。基于患者案例文本进行术后事件标签提取,采用word2vec的cbow标签提取模型,收集大量医学相关语料库,训练医学词向量模型,实现术后事件标签集(即分类标签集)提取。接下来,采用基于贝叶斯高斯过程潜变量模型进行缺失数据填补,以及基于mlsmote,加权knn(wknn)和遗传算法进行标签不平衡数据处理,最后结合主成分分析pca模型和遗传算法搭建特征降维模型,为分类集成模型提供相关性更高的输入。
[0159]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1