基于机器学习算法预测HIFU消融子宫肌瘤疗效的方法
基于机器学习算法预测hifu消融子宫肌瘤疗效的方法
技术领域
1.本发明属于消融子宫肌瘤疗效预测技术领域,尤其涉及一种基于机器学习算法预测hifu消融子宫肌瘤疗效的方法。
背景技术:
2.子宫肌瘤是女性最常见的一种良性肿瘤,但严重时会引起子宫出血、肾盂积水、腹坠胀感、腰背酸痛、不孕、流产等危害。目前常用于消除子宫肌瘤的一种方法是通过高强度聚焦超声(简称超声聚焦刀、hifu)在病灶范围内形成一个高能治疗点,在不损伤周围正常组织的情况下,使肌瘤组织产生不可逆的凝固性坏死,从而消融肌瘤。
3.但由于子宫肌瘤的多样性和复杂性,并不是所有的肌瘤患者都适合用超声聚焦刀治疗,确定合适的子宫肌瘤患者是超声刀消融临床应用的主要挑战之一。据研究数据可知,超声聚焦刀治疗的效果与手术后的消融率值的大小有关,一般当术后消融率大于80%,就认为使用超声聚焦刀治疗的效果比较理想。若能在手术前就预测出患者的肌瘤经过hifu治疗后的消融率是大于80%还是小于80%,就能判断出该患者是否适合使用hifu进行治疗。
4.目前预测消融率的研究主要集中在子宫肌瘤的临床特征和血流灌注参数方面。有不少学者根据临床参数建立了预测模型,但预测性能较差,并且有的学者在研究中纳入了一些在手术过程中才能获得的参数,这不符合我们想在手术前就预测得到消融率的初衷。还有的学者根据血流灌注参数来预测消融率,但血流灌注参数的计算、后处理复杂,并且步骤缺乏标准化,使得基于血流灌注参数预测消融率的这类研究临床实施相对困难。
技术实现要素:
5.为能够在手术前预测出患者经过超声聚焦刀治疗后的消融效果,为患者选择更适合的治疗方式,本发明提供一种基于机器学习算法预测hifu消融子宫肌瘤疗效的方法。
6.本发明的一种基于机器学习算法预测hifu消融子宫肌瘤疗效的方法,包括以下步骤:
7.步骤1:特征提取:从子宫肌瘤患者的基本信息和mri图像中提取出所需的特征数据。
8.步骤2:数据预处理:通过standard标准化方法将特征数据的分布调整成标准正态分布,使得数据的均值为0,方差为1。
9.步骤3:特征选择:通过方差阈值法计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征,去掉那些取值变化小的特征。
10.步骤4:特征降维:通过线性判别法lda进一步减小特征维度,使相同类别数据之间的距离缩小,不同类别数据之间的距离变大。
11.步骤5:分类模型:将数据按消融率大于80%和小于80%分为两类,分别表示hifu消融效果好与不好,并按照7:3分成训练集和测试集,把训练集送入随机森林rf算法进行训练,再将测试集放入训练好的模型中进行测试,并对模型进行评估。
12.步骤1中的特征数据包括从患者基本信息中采集的年龄、月经量、痛经、尿频、便秘、贫血、血红蛋白数据,以及从mri图像中提取出肌瘤种类、肌瘤位置、肌瘤大小、腹直肌厚度、皮下脂肪厚度、肌瘤深面距骶尾部距离、t2信号强度、子宫位置、子宫大小特征。
13.步骤4中线性判别法lda具体流程如下:
14.s41:计算每个类样本的均值向量所有样本的均值向量式中表示第i个类的第j个样本,mi,i=1,2,
…
,c表示第i类训练样本的数目,表示训练样本的总数目。
15.s42:计算类内散度矩阵类间散度矩阵和全局散度矩阵式中p(i)表示第i类的出现概率,p(i,j)表示的出现概率。
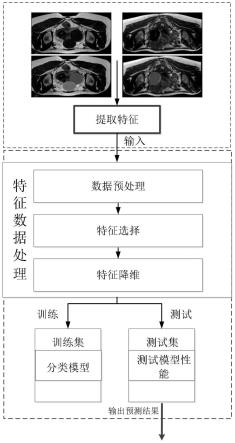
16.s43:计算的特征向量w(w1,w2,...,wd)和对应的特征值λ(λ1,λ2,...,λd)。
17.s44:选择d个最大特征值对应的矩阵w
m*d
。
18.s45:对数据集x进行降维,得到对应的降维数据集y=w
t
x。
19.本发明的有益技术效果为:
20.本发明能在手术前,无创地对患者经过hifu的治疗效果进行预测。本发明首先从患者基本信息和mri图像中提取特征,再通过特征选择算法将没有用的特征筛选掉,利用特征降维算法降低特征维度,然后将训练集和验证集通过分类算法进行分类训练,最终选择分类效果最好的算法组成模型。
21.相较于传统的依靠医生的双眼及经验对患者术后效果进行预测,本发明是依靠大数据技术和医学影像辅助诊断而产生的新方法,其通过从医学影像中提取海量特征来量化肿瘤等重大疾病,将它与临床生理指标组合用于子宫肌瘤术后消融效果的预测,可以实现多模态信息互补,挖掘更深层次的语义信息,达到更准确的预测,也为医生节约出更多的时间。
附图说明
22.图1为本发明基于机器学习算法预测hifu消融子宫肌瘤疗效的方法流程图。
具体实施方式
23.下面结合附图和具体实施方法对本发明做进一步详细说明。
24.本发明的一种基于机器学习算法预测hifu消融子宫肌瘤疗效的方法如图1所示,上侧虚线框框出的部分主要是从子宫肌瘤患者的基本信息和mri图像中提取所需的临床特征,然后把这些特征作为一个输入,传到下侧虚线框中。在下侧虚线框中,先对特征进行预处理,再通过特征选择算法选择有用的特征,通过特征降维算法降低数据维度。然后随机将数据样本以7:3的比例分为训练集和测试集,将训练集送入分类模型中进行训练,对比多种
分类模型的分类效果,选取最佳算法组合建立消融效果预测模型,最后把测试集放入建立的模型中,测试模型的性能。具体步骤为:
25.步骤1:特征提取:从子宫肌瘤患者的基本信息和mri图像中提取出所需的特征数据。
26.特征数据包括从患者基本信息中采集年龄、月经量、痛经、尿频、便秘、贫血、血红蛋白等数据,以及从mri图像中提取出肌瘤种类(粘膜、浆膜、肌壁)、肌瘤位置、肌瘤大小(长径、左右径、前后径、体积)、腹直肌厚度、皮下脂肪厚度、肌瘤深面距骶尾部距离、t2信号强度、子宫位置、子宫大小(长径、左右径、前后径、体积)等特征。
27.步骤2:数据预处理:通过standard标准化方法将特征数据的分布调整成标准正态分布,使得数据的均值为0,方差为1。
28.步骤3:特征选择:通过方差阈值法(variancethreshold,vt)计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征,去掉那些取值变化小的特征。从而避免出现因为有些特征的方差过大,而使参数估计器无法正确地去学习其它特征。
29.步骤4:特征降维:通过线性判别法(linear discriminantanalysis,lda)进一步减小特征维度,使相同类别数据之间的距离缩小,不同类别数据之间的距离变大。lda算法是一种经典的有监督数据降维方法,其主要思想是将一个高维空间中的数据投影到一个较低维的空间中,且投影后要最大化类间距离和最小化类内距离,这意味着同一类的高维数据投影到低维空间后,相同类别的聚在一起,而不同类别之间相距较远。lda具体流程如下:
30.s41:计算每个类样本的均值向量所有样本的均值向量式中表示第i个类的第j个样本,mi,i=1,2,
…
,c表示第i类训练样本的数目,表示训练样本的总数目。
31.s42:计算类内散度矩阵类间散度矩阵和全局散度矩阵式中p(i)表示第i类的出现概率,p(i,j)表示的出现概率。
32.s43:计算的特征向量w(w1,w2,...,wd)和对应的特征值λ(λ1,λ2,...,λd)。
33.s44:选择d个最大特征值对应的矩阵w
m*d
。
34.s45:对数据集x进行降维,得到对应的降维数据集y=w
t
x。
35.步骤5:分类模型:将数据按消融率大于80%和小于80%分为两类,分别表示hifu消融效果好与不好,并按照7:3分成训练集和测试集,把训练集送入随机森林(random forest,rf)算法进行训练。随机森林(rf)是一个包含多个决策树的分类器,不同决策树之间没有关联。先根据训练数据集,构造出多棵决策树。进行分类任务时,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的分类结果。rf具体流程如下:
36.1)根据“随着树深度增加,树节点的熵迅速地降低,并且熵降低的速度越快越好”的思想,构建决策树。
37.2)在训练集中随机有放回地选择一定比例的样本,在所有特征中随机选择一定比例的特征,按照步骤1中的思想,构建每一棵决策树。
38.3)构建出很多棵决策树,并平均它们的风险,用这些决策树共同进行决策、分类。
39.4)进行分类任务时,每棵树从根节点开始,按照决策树的分类属性逐层往下划分直到叶子节点,获得决策、分类结果。
40.5)每一棵树都能单独进行决策,获得一个分类结果。
41.6)最后根据所有决策树的分类结果中哪一个分类最多,得到最终分类结果。
42.最后将测试集放入训练好的模型中进行测试,并通过准确率、查准率、查全率、auc值、f1分数等多种指标对模型进行评估。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1