一种复杂河网区微塑料通量计算方法
1.本发明属于微塑料通量算法技术领域,尤其涉及一种复杂河网区微塑料通量计算方法。
背景技术:
2.微塑料几乎在各种环境介质中都有检出,微塑料环境污染问题受到人们的关注,我国也将微塑料列为四类新污染物之一。河流系统作为微塑料由源(陆地)向汇(海洋)迁移的主要通路,准确计算微塑料在该系统内的通量有助于识别生态环境中微塑料污染负载和特征,帮助决策者及时做出应对措施。
3.其中,复杂河网区的微塑料污染问题比较复杂,因为复杂河网区受到人类生产生活活动的影响强烈,造成微塑料来源不明;复杂河网区内往往有各种水利工程,水文情势复杂,造成微塑料迁移规律不明;复杂河网区内的微塑料分布还会受到季节气候的影响,造成微塑料时空分布不均匀;通过直接在河道断面采集微塑料来计算其通量,需要的工作量大,时间经济成本高,不利于长时间监测和大范围实施。
4.因此,针对以上现状,迫切需要开发一种复杂河网区微塑料通量计算方法,以克服当前实际应用中的不足。
技术实现要素:
5.针对现有技术存在的不足,本发明实施例的目的在于提供一种复杂河网区微塑料通量计算方法,以解决上述背景技术中的问题。
6.为实现上述目的,本发明提供如下技术方案:
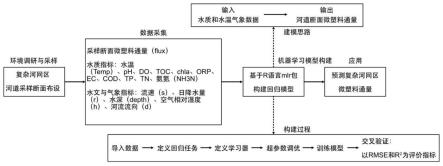
7.一种复杂河网区微塑料通量计算方法,方法步骤如下:
8.步骤一、在复杂河网区布设采样断面;
9.步骤二、采样与获取微塑料数据;
10.步骤三、同步获取水质水文气象数据;
11.步骤四、构建河道断面微塑料通量机器学习模型,计算复杂河网区微塑料通量。
12.作为本发明进一步的技术方案,在步骤一中,采样断面可设定为复杂河网区内干流、一级支流、二级支流的上中下游以及商业居住区、工业园区、污水处理厂排口和农业耕作区等河网区内代表性区域附近河道。
13.作为本发明进一步的技术方案,在步骤二中,采集并提取采样断面水体中的微塑料,计算微塑料丰度,单位为个/l或个/m3,测定断面流量,计算出断面微塑料瞬时通量flux,单位为个/(m3·
s)。
14.作为本发明进一步的技术方案,在步骤三中,水质水文气象数据是指水质因子和水文气象因子、水质备选因子和水文气象备选因子,水质因子包括水温(记为temp,单位℃)、ph、浊度(记为turb,单位ntu)、溶解氧(记为do,单位mg/l)和总有机碳(记为toc,单位mg/l);
15.水质备选因子为:叶绿素a(记为chla,单位μg/l)、氧化还原电位(记为orp,单位mv)、电导率(记为ec,单位μs/cm)、化学需氧量(记为cod,单位mg/l)、总磷(记为tp,单位mg/l)、总氮(记为tn,单位mg/l)和氨氮(记为nh3n,单位mg/l);
16.水文气象因子包括流速(记为s,单位m/s)和日降水量(记为r,单位mm);
17.水文气象备选因子包括水深(记为depth,单位m)、空气相对湿度(记为h)和河流流向(记为d)。
18.作为本发明进一步的技术方案,在步骤四中,河道断面微塑料通量机器模型的构建方法具体步骤如下:
19.步骤(1)将微塑料和水质水文气象数据整理为excel表格形式,文件名设为data;
20.步骤(2)安装和加载r语言相关包,导入数据集data;
21.步骤(3)定义回归任务,模拟目标为微塑料通量flux;
22.步骤(4)定义knn和随机森林两种机器学习模型学习器。
23.作为本发明进一步的技术方案,步骤(2)的具体运行代码如下:
24.install.packages(“mlr”)#安装mlr包
25.install.packages(“parallel”)#安装parallel包
26.install.packages(“parallelmap”)#安装parallelmap包
27.library(mlr)#加载mlr包
28.library(parallel)#加载parallel包
29.library(parallelmap)#加载parallelmap包
30.parallelstartsocket(cpus=detectcores())#打开计算机多核并行计算,加快模型运算速度
31.#导入数据集data。
32.作为本发明进一步的技术方案,步骤(3)的具体运行代码为task《-makeregrtask(data=data,target="flux")#定义回归任务。
33.作为本发明进一步的技术方案,所述knn机器学习模型定义的具体运行代码如下:
34.#1定义knn回归学习器
35.knn《-makelearner("regr.kknn")
36.#2定义knn模型的超参数空间
37.knnparamspace《-makeparamset(makediscreteparam("k",values=1:16))
38.#3定义超参数空间的搜索模式,此处设置为网格搜索
39.gridsearch《-maketunecontrolgrid()
40.#4定义交叉验证(cv)模式,此处设置为10次重复的10折交叉验证
41.kfold《-makeresampledesc(method="repcv",folds=10,reps=10)
42.#5执行超参数调优
43.tunedknnparams《-tuneparams("regr.kknn",
44.task=task,
45.resampling=kfold,
46.par.set=knnparamspace,
47.control=gridsearch)
48.#6手动设定最优超参数
49.tunedknn《-sethyperpars(knn,par.vals=tunedknnparams$x)
50.#7训练最终模型
51.tunedknnmodel《-train(tunedknn,task)
52.#8交叉验证训练效果,评价指标为均方根误差rmse和拟合优度r2
53.knncv《-resample(learner=tunedknn,
54.task=task,
55.resampling=kfold,
56.measures=list(rmse,rsq))
57.#9输出交叉验证结果
58.knncv$aggr
59.#10对新数据(newdata)进行预测
60.knnpred《-predict(tunedknnmodel,newdata=newdata)
61.performance(knnpred,measures=list(rmse,rsq))。
62.作为本发明进一步的技术方案,所述随机森林机器学习模型定义的具体运行代码如下:
63.#1定义随机森林学习器
64.rf《-makelearner("regr.randomforest")#定义随机森林回归学习器
65.#2定义随机森林模型的超参数空间
66.rfparamspace
67.《-makeparamset(makeintegerparam("ntree",lower=20,upper=500),
68.makeintegerparam("mtry",lower=2,upper=16),
69.makeintegerparam("nodesize",lower=1,upper=10),
70.makeintegerparam("maxnodes",lower=5,upper=30))
71.#3定义超参数空间的搜索模式,此处设置为100次迭代的随机搜索
72.randsearch《-maketunecontrolrandom(maxit=100)
73.#4定义交叉验证(cv)模式,此处设置为10次重复的10折交叉验证
74.kfold《-makeresampledesc(method="repcv",folds=10,reps=10)
75.#5执行超参数调优
76.tunedrfparams《-tuneparams(rf,
77.task=task,
78.resampling=kfold,
79.par.set=rfparamspace,
80.control=randsearch)
81.#6手动设定最优超参数
82.tunedrf《-sethyperpars(rf,par.vals=tunedrfparams$x)
83.#7训练最终模型
84.tunedrfmodel《-train(tunedrf,task)
85.#8交叉验证训练效果,评价指标为均方根误差rmse和拟合优度r2
86.rfcv《-resample(learner=tunedrf,
87.task=task,
88.resampling=kfold,
89.measures=list(rmse,rsq))
90.#9输出交叉验证结果
91.rfcv$aggr
92.#10对新数据(newdata)进行预测
93.rfpred《-predict(tunedrfmodel,newdata=newdata)
94.performance(rfpred,measures=list(rmse,rsq))。
95.与现有技术相比,本发明的有益效果是:
96.通过构建基于机器学习的复杂河网区微塑料通量计算方法,可以实现通过监测复杂河网区水质和水文气象数据来模拟和预测水体微塑料通量,在建模过程中,以交叉验证的均方根误差rmse和决定系数r2作为模型性能评价指标,rmse越接近0,r2越接近1,表明模拟精度越高;尽可能多的获取水质和水文气象数据,当某些因子数据无法获取时,也可以适当舍去;在建模完成后,即可对新数据进行预测;输入数据应为复杂河网区内某断面的水质和水文气象因子数据,输出数据为该断面预测的微塑料通量;使用r语言mlr包的优势在于,该包将多种机器学习方法集成为统一的过程,即:定义任务
→
定义学习器
→
超参数调优
→
训练模型
→
交叉验证
→
预测新数据;在复杂河网区微塑料通量计算方法中,使用者可根据计算机运算速度和个人要求选择不同的学习器,常用的有:knn和随机森林,此外还有支持向量机(svm)和极限梯度提升(xgboost)等等;此外,不同学习器下的超参数调优方法和交叉验证方法也可以根据个人需求自定义。
97.本发明提出一种基于机器学习方法的利用水质和水文气象因子模拟复杂河网区微塑料通量的计算方法,可以实现快速计算复杂河网区内的微塑料通量,并且揭示微塑料污染与环境因子之间的潜在联系。在模拟模型建立后,后续可依托水文水质监测站常规监测数据即可预测河道断面微塑料通量,有利于节约环境监测成本,提高环境监测质量。
98.为更清楚地阐述本发明的结构特征和功效,下面结合附图与具体实施例来对本发明进行详细说明。
附图说明
99.图1为本发明实施例提供的复杂河网区微塑料通量计算方法的流程框图。
具体实施方式
100.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
101.以下结合具体实施例对本发明的具体实现进行详细描述。
102.如图1所示,作为本发明一个实施例提供的一种复杂河网区微塑料通量计算方法,方法步骤如下:
103.步骤一、在复杂河网区布设采样断面;
104.步骤二、采样与获取微塑料数据;
105.步骤三、同步获取水质水文气象数据;
106.步骤四、构建河道断面微塑料通量机器学习模型,计算复杂河网区微塑料通量。
107.在本实施例中,随着计算机性能的提高和机器学习技术的普及,通过查找大量数据之间的潜在联系来发掘环境问题中的自然规律;在复杂河网区微塑料通量计算问题里,微塑料与环境因子之间本质上也存在潜在联系。
108.例如:微塑料是指粒径小于5mm的塑料颗粒,塑料即含碳有机高分子聚合物,这说明,当微塑料进入到河流水体时,其本身会成为水中总有机碳(toc)的一部分;微塑料是固态颗粒,进入水体时会影响水体的浊度和透明度;微塑料在水中的悬浮沉降以及迁移运动会受到水温、ph等水质因子以及流速、流向、降雨和空气湿度等水文和气象因子的影响;
109.本发明提出一种基于机器学习方法的利用水质和水文气象因子模拟复杂河网区微塑料通量的计算方法,可以实现快速计算复杂河网区内的微塑料通量,并且揭示微塑料污染与环境因子之间的潜在联系。在模拟模型建立后,后续可依托水文水质监测站常规监测数据即可预测河道断面微塑料通量,有利于节约环境监测成本,提高环境监测质量。
110.作为本发明的一种优选实施例,在步骤一中,采样断面可设定为复杂河网区内干流、一级支流、二级支流的上中下游以及商业居住区、工业园区、污水处理厂排口和农业耕作区等河网区内代表性区域附近河道。
111.作为本发明的一种优选实施例,在步骤二中,采集并提取采样断面水体中的微塑料,计算微塑料丰度,单位为个/l或个/m3,测定断面流量,计算出断面微塑料瞬时通量flux,单位为个/(m3·
s)。
112.作为本发明的一种优选实施例,在步骤三中,水质水文气象数据是指水质因子和水文气象因子、水质备选因子和水文气象备选因子,水质因子包括水温(记为temp,单位℃)、ph、浊度(记为turb,单位ntu)、溶解氧(记为do,单位mg/l)和总有机碳(记为toc,单位mg/l);
113.水质备选因子为:叶绿素a(记为chla,单位μg/l)、氧化还原电位(记为orp,单位mv)、电导率(记为ec,单位μs/cm)、化学需氧量(记为cod,单位mg/l)、总磷(记为tp,单位mg/l)、总氮(记为tn,单位mg/l)和氨氮(记为nh3n,单位mg/l);
114.水文气象因子包括流速(记为s,单位m/s)和日降水量(记为r,单位mm);
115.水文气象备选因子包括水深(记为depth,单位m)、空气相对湿度(记为h)和河流流向(记为d)。
116.作为本发明的一种优选实施例,在步骤四中,河道断面微塑料通量机器模型的构建方法具体步骤如下:
117.步骤(1)将微塑料和水质水文气象数据整理为excel表格形式,文件名设为data;
118.步骤(2)安装和加载r语言相关包,导入数据集data;
119.步骤(3)定义回归任务,模拟目标为微塑料通量flux;
120.步骤(4)定义学习器,以knn和随机森林2种常见机器学习模型为例。
121.在本实施例中,excel表格样式如下:
[0122][0123][0124]
作为本发明的一种优选实施例,安装和加载r语言相关包,导入数据集data的具体运行代码如下:
[0125]
install.packages(“mlr”)#安装mlr包
[0126]
install.packages(“parallel”)#安装parallel包
[0127]
install.packages(“parallelmap”)#安装parallelmap包
[0128]
library(mlr)#加载mlr包
[0129]
library(parallel)#加载parallel包
[0130]
library(parallelmap)#加载parallelmap包
[0131]
parallelstartsocket(cpus=detectcores())#打开计算机多核并行计算,加快模型运算速度
[0132]
#导入数据集data。
[0133]
作为本发明的一种优选实施例,定义回归任务,模拟目标为微塑料通量flux的具体运行代码为task《-makeregrtask(data=data,target="flux")#定义回归任务。
[0134]
作为本发明的一种优选实施例,所述knn机器学习模型定义的具体运行代码如下:
[0135]
#1定义knn回归学习器
[0136]
knn《-makelearner("regr.kknn")
[0137]
#2定义knn模型的超参数空间
[0138]
knnparamspace《-makeparamset(makediscreteparam("k",values=1:16))
[0139]
#3定义超参数空间的搜索模式,此处设置为网格搜索
[0140]
gridsearch《-maketunecontrolgrid()
[0141]
#4定义交叉验证(cv)模式,此处设置为10次重复的10折交叉验证
[0142]
kfold《-makeresampledesc(method="repcv",folds=10,reps=10)
[0143]
#5执行超参数调优
[0144]
tunedknnparams《-tuneparams("regr.kknn",
[0145]
task=task,
[0146]
resampling=kfold,
[0147]
par.set=knnparamspace,
[0148]
control=gridsearch)
[0149]
#6手动设定最优超参数
[0150]
tunedknn《-sethyperpars(knn,par.vals=tunedknnparams$x)
[0151]
#7训练最终模型
[0152]
tunedknnmodel《-train(tunedknn,task)
[0153]
#8交叉验证训练效果,评价指标为均方根误差rmse和拟合优度r2
[0154]
knncv《-resample(learner=tunedknn,
[0155]
task=task,
[0156]
resampling=kfold,
[0157]
measures=list(rmse,rsq))
[0158]
#9输出交叉验证结果
[0159]
knncv$aggr
[0160]
#10对新数据(newdata)进行预测
[0161]
knnpred《-predict(tunedknnmodel,newdata=newdata)
[0162]
performance(knnpred,measures=list(rmse,rsq))。
[0163]
作为本发明的一种优选实施例,所述随机森林机器学习模型定义的具体运行代码如下:
[0164]
#1定义随机森林学习器
[0165]
rf《-makelearner("regr.randomforest")#定义随机森林回归学习器
[0166]
#2定义随机森林模型的超参数空间
[0167]
rfparamspace
[0168]
《-makeparamset(makeintegerparam("ntree",lower=20,upper=500),
[0169]
makeintegerparam("mtry",lower=2,upper=16),
[0170]
makeintegerparam("nodesize",lower=1,upper=10),
[0171]
makeintegerparam("maxnodes",lower=5,upper=30))
[0172]
#3定义超参数空间的搜索模式,此处设置为100次迭代的随机搜索
[0173]
randsearch《-maketunecontrolrandom(maxit=100)
[0174]
#4定义交叉验证(cv)模式,此处设置为10次重复的10折交叉验证
[0175]
kfold《-makeresampledesc(method="repcv",folds=10,reps=10)
[0176]
#5执行超参数调优
[0177]
tunedrfparams《-tuneparams(rf,
[0178]
task=task,
[0179]
resampling=kfold,
[0180]
par.set=rfparamspace,
[0181]
control=randsearch)
[0182]
#6手动设定最优超参数
[0183]
tunedrf《-sethyperpars(rf,par.vals=tunedrfparams$x)
[0184]
#7训练最终模型
[0185]
tunedrfmodel《-train(tunedrf,task)
[0186]
#8交叉验证训练效果,评价指标为均方根误差rmse和拟合优度r2
[0187]
rfcv《-resample(learner=tunedrf,
[0188]
task=task,
[0189]
resampling=kfold,
[0190]
measures=list(rmse,rsq))
[0191]
#9输出交叉验证结果
[0192]
rfcv$aggr
[0193]
#10对新数据(newdata)进行预测
[0194]
rfpred《-predict(tunedrfmodel,newdata=newdata)
[0195]
performance(rfpred,measures=list(rmse,rsq))。
[0196]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1