多临床分期疾病的辅助分类方法、设备及存储介质与流程
1.本技术涉及智能医疗领域,尤其涉及一种多临床分期疾病的辅助分类方法、设备及存储介质。
背景技术:
2.疾病分期最初仅停留在纯临床层面,如,症状轻微vs.严重,此后在尸检、影像学及生物标志物领域进展的指导下逐渐进化为更先进的临床病理学视角。疾病分期适用于那些可能迁延不愈、功能进行性恶化和/或可能早亡的疾病,对大多数疾病来说,早期病情相对稳定,临床治愈率也较高,晚期病情发展快,治愈率较低。如果患者在疾病发展早期能够发现并诊治,在病情恶化前未雨绸缪,将大大提高患者临床治愈率,因此如何准确诊断疾病的分期是临床医学的重要问题之一。伴随机器学习的发展和电子病历的完善,数据驱动的智能医疗诊疗方法成为主流。智能医疗是近几年学术界研究的热点,也是计算机和医疗领域结合的热门关注点,因此如何通过智能医疗帮助疾病分期诊断,是要解决的问题。
技术实现要素:
3.有鉴于此,本技术提出一种多临床分期疾病的辅助分类方法、设备及存储介质,以解决通过智能医疗帮助疾病分期诊断的问题。
4.本技术的技术方案实现方法包括:
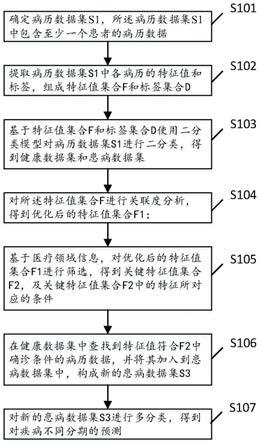
5.一种多临床分期疾病的辅助分类方法,包括:
6.确定病历数据集s1,所述病历数据集s1中包含至少一个患者的病历数据;
7.提取病历数据集s1中各病历的特征值和标签,组成特征值集合f和标签集合d,所述特征值集合f包括各患者病历数据中的体查数据及检查结果数据,所述标签集合d包括基于医生诊断结果确定的患病或健康两类标签;
8.基于特征值集合f和标签集合d使用二分类模型对病历数据集s1进行二分类,得到健康数据集和患病数据集;
9.对所述特征值集合f进行关联度分析,得到优化后的特征值集合f1;
10.基于医疗领域信息,对优化后的特征值集合f1进行筛选,得到关键特征值集合f2,及关键特征值集合f2中的特征所对应的条件;
11.在健康数据集中查找到特征值符合f2中确诊条件的病历数据,并将其加入到患病数据集中,构成新的患病数据集s3;
12.对新的患病数据集s3进行多分类,得到对疾病不同分期的预测。
13.所述的方法中,所述体查数据至少包括:身高、体重、疼痛程度、吸烟史、饮酒史、病史;
14.所述检查结果数据至少包括:血尿生化检测结果、影像学检查结果。
15.所述的方法中,所述基于特征值集合f和标签集合d使用二分类模型对病历数据集s1进行二分类,包括:
16.建立候选二分类模型库,所述候选二分类模型库中包括多个二分类模型;
17.同时执行多个二分类模型,得到多个二分类模型的准确率、召回率、f1score值,综合考虑以上三种分类评价指标,选择评价指标效果最好的,一个二分类模型对病历数据集s1进行二分类。
18.所述的方法中,所述对所述特征值集合f进行关联度分析,得到优化后的特征值集合f1,包括:
19.通过卡方检验,或样本方差值,或离散类别交互信息,对所述特征值集合f中的特征值进行关联度分析,并删除关联度较低的特征值,得到优化后的特征值集合f1。
20.所述的方法中,所述基于医疗领域信息,对优化后的特征值集合f1进行筛选,得到关键特征值集合f2,其中关键特征值集合为对确诊疾病有决定性影响的特征值集合。
21.所述的方法中,所述对新的患病数据集s3进行多分类之前,还包括:
22.对新的患病数据集s3中缺失的特征项,根据对应的医疗含义以特定值,或平均值,或众数进行缺失值填充;
23.对填充后的患病数据集s3中的数据进行标准化,构成数据集s4。
24.所述的方法中,所述对新的患病数据集s3进行多分类,具体为:
25.根据疾病种类,确定新的标签集合d’,所述新的标签集合d’为所述疾病对应的分期诊断集合;
26.基于深度神经网络模型,对s4进行多分类;其中,
27.输入层的神经元个数对应特征集合f1中的特征值个数;
28.输出层的神经元个数对应疾病分期个数,即标签集合d’中数值个数;
29.使用relu函数作为各隐藏层的激活函数,并创建softmax函数,确定疾病分期预测。
30.本发明还提出一种多临床分期疾病的辅助分类设备,包括:处理器及存储器;
31.所述处理器用于存储计算机程序,用于实现所述的多临床分期疾病的辅助分类方法。
32.本发明还提出一种存储介质,用于至少存储一组指令集;
33.所述指令集用于被调用并至少执行所述的多临床分期疾病的辅助分类方法。
34.本发明的优势在于,本发明所提出的方法,适用于多分期的疾病诊断。首先使用机器学习二分类模型对是否确诊疾病进行二分类,再应用医疗领域专业知识确定特征值集合,将二分类的结果中确诊数据采用深度学习多分类模型实现疾病分期诊断。
附图说明
35.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
36.图1为本发明一种多临床分期疾病的辅助分类方法实施例流程图;
37.图2为本发明一种多临床分期疾病的辅助分类设备结构示意图。
具体实施方式
38.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
39.有鉴于此,本技术提出一种多临床分期疾病的辅助分类方法、设备及存储介质,以解决通过智能医疗帮助疾病分期诊断的问题。
40.伴随机器学习的发展和电子病历的完善,数据驱动的智能医疗诊疗方法成为主流。大量电子病历的产生为智能医疗提供了充足的数据源。另一方面,如何准确的进行疾病分期一直是临床医生进行疾病诊断的重难点之一,对大多数疾病来说,早期病情相对稳定,临床治愈率也较高,晚期病情发展快,治愈率较低。能够及时准确的进行疾病分期将大大提高患者的生存率和愈后质量。鉴于此现实问题,本发明提出了一种多临床分期疾病的辅助分类方法,该方法适用于具有多临床分期的疾病的预测,辅助临床医生进行疾病诊断。
41.本技术的技术方案实现方法包括:
42.本发明实施例给出一种多临床分期疾病的辅助分类方法,如图1所示,包括:
43.s101:确定病历数据集s1,所述病历数据集s1中包含至少一个患者的病历数据;所述的病历数据集s1中,可包含医院病历库中多个患者的电子病历作为数据集;
44.s102:提取病历数据集s1中各病历的特征值和标签,组成特征值集合f和标签集合d,所述特征值集合f包括各患者病历数据中的体查数据及检查结果数据,所述标签集合d包括基于医生诊断结果确定的患病或健康两类标签;
45.患者在就诊时,医生会通过医院的电子病历信息系统录入患者病历。电子病历数据中包括患者个人信息、患者症状数据、查体、生化检测数据、医生的诊断医嘱和用药数据。然后我们从电子病历信息系统中导出患者的电子病历数据,我们将病历数据集中的所有疾病特征如身高、体重、疼痛程度、吸烟史、饮酒史、病史等查体数据和血尿生化检测结果、影像学检查等结果作为特征值,将医生诊断的多级患病情况简化为患病或健康两类作为标签。
46.s103:基于特征值集合f和标签集合d使用二分类模型对病历数据集s1进行二分类,得到健康数据集和患病数据集;
47.根据对电子病历的初步观察和统计,我们发现诊断结果总体可分为两大类,即根据该疾病是否患病可分为“健康”和“患病”两类。然后我们对病历数据s1中的标签进行初步筛选,剔除对疾病诊断无影响的患者个人信息部分和用药医嘱部分,将剩余的特征值例如疼痛程度、身高体重的查体数据、血尿的生化检测结果作为特征集,用f表示,f={f1,f2,
…
,fn}。我们令d表示患病情况的集合作为标签集,则d={1,0},1表示患病,0表示健康。在此基础上对s1进行二分类;
48.由于在此处尚未引入医学领域知识,为了更好的支持不同类型的多临床分期疾病的二分类诊断,提出了“候选二分类模型库”的概念,用户可以根据具体的场景(即,具体某一种多临床分期疾病的电子病历),同时执行多个二分类模型,然后根据实际的测试效果,选择最合适的一种二分类模型。常用的二分类算法包括逻辑回归,k最近邻(knn),支持向量机(svm)等等。除了主流的二分类算法,随机森林和xgboost模型也在分类问题中有较好的
表现。以svm和xgboost这两种分类模型用于“候选二分类模型库”为例:
49.支持向量机(svm)是一种典型的二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;svm还包括核技巧,这使它成为实质上的非线性分类器。它的基本思想是求解能够正确划分数据集并且具有几何上最大间隔的超平面。在样本空间中,超平面(ω,b)由法向量ω和位移项b确定,样本空间中任意点x到超平面的距离可写为:
[0050][0051]
在分割两类样本的众多超平面中,间隔最大的划分超平面需要满足的约束为:
[0052][0053]
s.t.yi(ωtxi+b)≥1,i=1,2,
…
,m
[0054]
xgboost是一个优化的分布式梯度增强库。它在gradient boosting框架下实现机器学习算法,可高效、灵活和轻便的处理大规模训练样本。xgboost的目标函数为:
[0055][0056]
其中,n为病历样本个数,yi为第i个病历的真正诊断,为模型对第i个样本的预测诊断。k表示回归树的个数,fk表示第k棵树,ω为正则化项也是回归树的复杂度,具体表达为:
[0057][0058]
其中t为叶子结点的个数,ω通过γ在叶子结点过多时进行剪枝,λ控制过大时出现的过拟合的问题。
[0059]
我们的优化目标即为其中为最优情况下样本落到第i棵回归树的叶子节点值。
[0060]
s104:对所述特征值集合f进行关联度分析,得到优化后的特征值集合f1;
[0061]
为了提高模型预测的准确率,我们综合考虑卡方检验、样本方差值和离散类别交互信息三方面对f中的特征值进行关联度分析。以卡方检验和离散类别交互信息为例,特征值fi和是否患病d之间的卡方统计量为:
[0062][0063]
其中a为f在d上的实际值,t为理论值。x为实际值与理论值偏差的绝对大小,x越大表示fi对是否患病的影响越大。
[0064]
离散类别交互信息简称“互信息”,是特征工程中用于筛选特征值的一种方法。对于离散型随机变量x,y,互信息的计算公式如下:
[0065]
[0066]
如果x,y是相互独立的变量p(x,y)=p(x)p(y),上述i(x;y)为0,因此i(x;y)的值越大,表示这两个变量的相关性越大。
[0067]
在此基础上我们删除关联度较低的特征值,得到初步优化后的特征集f1。
[0068]
s105:基于医疗领域信息,对优化后的特征值集合f1进行筛选,得到关键特征值集合f2,及关键特征值集合f2中的特征所对应的条件;
[0069]
在此基础上引入医疗领域知识,从特征值集合f1中筛选对预测结果有决定性影响的特征值集合f2={fn,
…
fm}及其条件;
[0070]
该过程基于医疗领域的疾病诊断知识,筛选对确诊疾病有决定性影响的特征值,例如针对痛风病来说通风量化赋分的分值对是否确诊通风具有决定性影响;
[0071]
s106:在健康数据集中查找到特征值符合f2中确诊条件的病历数据,并将其加入到患病数据集中,构成新的患病数据集s3;
[0072]
在此基础上引入医疗领域知识,从特征值集合f1中筛选对预测结果有决定性影响的特征值集合f2={fn,
…
fm}及其条件,查找上述二分类后d=0的健康数据集s2,筛选出f2满足确诊条件的数据s2’,再将s2’加入到d=1的数据集中,构成用于多分类的数据集s3。
[0073]
s107:对新的患病数据集s3进行多分类,得到对疾病不同分期的预测。
[0074]
所述的方法中,所述体查数据至少包括:身高、体重、疼痛程度、吸烟史、饮酒史、病史;
[0075]
所述检查结果数据至少包括:血尿生化检测结果、影像学检查结果。
[0076]
所述的方法中,所述基于特征值集合f和标签集合d使用二分类模型对病历数据集s1进行二分类,包括:
[0077]
建立候选二分类模型库,所述候选二分类模型库中包括多个二分类模型;
[0078]
同时执行多个二分类模型,得到多个二分类模型的准确率、召回率、f1score值,综合考虑以上三种分类评价指标,选择评价指标效果最好的,一个二分类模型对病历数据集s1进行二分类。
[0079]
所述的方法中,所述对所述特征值集合f进行关联度分析,得到优化后的特征值集合f1,包括:
[0080]
通过卡方检验,或样本方差值,或离散类别交互信息,对所述特征值集合f中的特征值进行关联度分析,并删除关联度较低的特征值,得到优化后的特征值集合f1。
[0081]
所述的方法中,所述基于医疗领域信息,对优化后的特征值集合f1进行筛选,得到关键特征值集合f2,其中关键特征值集合为对确诊疾病有决定性影响的特征值集合。
[0082]
所述的方法中,所述对新的患病数据集s3进行多分类之前,还包括:
[0083]
对新的患病数据集s3中缺失的特征项,根据对应的医疗含义以特定值,或平均值,或众数进行缺失值填充;
[0084]
对于s3中数据缺失的特征项,根据该项的医疗含义以特定值,平均值或者众数进行缺失值填充。例如疼痛关节数目,属性缺失则表示患者并未出现关节疼痛症状,则用0填充默认并无疼痛关节。再如饮酒史中饮酒类型缺失,则取值为最常出现的“啤酒”类型。
[0085]
对填充后的患病数据集s3中的数据进行标准化,构成数据集s4。
[0086]
又因为不同评价指标往往具有不同的量纲和量纲单位,为了弥补该问题对数据分析带来的影响,采用z-score方法进行标准化将数据按比例缩放,使之落入一个特定区间。
[0087][0088]
其中x为f1中某一特征值的实际值,μ为平均数,σ为标准差。z-score方法将不同量级的数据转化为统一量度,提高数据的可比性。经过缺失值填充和标准化后的数据s4可作为多分类模型的输入进行疾病分期预测。
[0089]
所述的方法中,所述对新的患病数据集s3进行多分类,具体为:
[0090]
根据疾病种类,确定新的标签集合d’,所述新的标签集合d’为所述疾病对应的分期诊断集合;
[0091]
基于深度神经网络模型,对s4进行多分类;其中,
[0092]
输入层的神经元个数对应特征集合f1中的特征值个数;
[0093]
输出层的神经元个数对应疾病分期个数,即标签集合d’中数值个数;
[0094]
使用relu函数作为各隐藏层的激活函数,并创建softmax函数,确定疾病分期预测。
[0095]
我们采用深度神经网络模型(dnn模型)对s4进行多分类。dnn是包含多个隐藏层的神经网络,它内部的神经网络层可以分为三类:输入层、隐藏层和输出层。输入层的神经元个数对应特征集合f1中的特征值个数,输出层的神经元个数对应疾病分期的个数,即标签d’={d1,d2,
…
,dn|di∈n+},其中d1至dn均为已确诊疾病分期。并使用relu函数作为各隐藏层的激活函数,并创建softmax函数,用于输出层的激活函数以解决多分类问题。其中softmax函数的定义如下:
[0096][0097]
其中zi为第i个节点的输出值,也就是某一类疾病分期的输出值;c为输出节点的个数,就是疾病分期的个数。并根据疾病种类的不同使用多分类问题中表现较好的分类交叉熵作为损失函数。以进一步提高对不同疾病分期预测的准确度。
[0098]
另一实施例,本发明还提出一种多临床分期疾病的辅助分类设备,包括:处理器201及存储器202;
[0099]
所述处理器用于存储计算机程序,用于实现所述的多临床分期疾病的辅助分类方法。
[0100]
再一实施例,本发明还提出一种存储介质,用于至少存储一组指令集;
[0101]
所述指令集用于被调用并至少执行所述的多临床分期疾病的辅助分类方法。
[0102]
本发明的优势在于,本发明所提出的方法,适用于多分期的疾病诊断。首先使用机器学习二分类模型对是否确诊疾病进行二分类,再应用医疗领域专业知识确定特征值集合,将二分类的结果中确诊数据采用深度学习多分类模型实现疾病分期诊断。在医院收集的复杂繁多的电子病历数据上结合医疗领域专业知识对疾病特征进行分割筛选,用于具有多临床分期的疾病的预测,辅助临床医生进行疾病诊断。
[0103]
以上所述的实例,对本技术的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本技术的实施例而已,并不用于限定本技术的保护范围,凡在本技术的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1