一种基于图卷积神经网络的药物靶标预测方法
1.本发明涉及计算机辅助药物设计技术领域,尤其是涉及一种基于图卷积神经网络的药物靶标预测方法。
背景技术:
2.药物靶点是药物与人体作用的结合位点,药物靶点包括受体、基因、酶、离子通道、核酸、转运体等,药物通过与位点的结合影响生物学事件的改变,从而实现药物的治疗效果。药物-靶点相互作用(drug-target interactions,dti)的鉴定是现代药物发现和开发的基础,对药物发现、药物副作用预测、药物重定位,以及发现与现有药物相互作用的新靶点的过程有重要的作用,然而传统的生物化学实验方式进行药物靶点发现存在耗费时间长、设备昂贵开销极大等问题。
3.大规模的生物医学数据集的出现为利用计算机辅助进行dti预测提供了数据基础,包括phid、therapeutic target database(ttd)、drugbank、binding db、pharmgkb、chembl等,结合计算机技术可以快速低成本地识别潜在的dti。
4.公开号为cn113053457a的中国专利“一种基于多通路图卷积神经网络药物靶标预测方法”提出采用多通路图卷积神经网络,基于随机游走获得概率共现矩阵计算ppmi矩阵,以ppmi矩阵和带自环的药物-药物作为卷积核,其余子网矩阵作为特征进行图卷积,分别从全局和局部捕获图网络特征。
5.论文“neodti:neural integration of neighbor information from a heterogeneous network for discovering new drug
–
target interactions bioinformatics”利用药物多源生物医学数据库中的数据构造异构网络,基于异构图卷积神经网络聚合邻域信息,聚合过程按类别处理不同边,同一类型的边在聚合过程中通过边权映射函数赋予权值以差异化学习不同的特征。
6.上述的药物靶标预测方法取得一定进展,但仍存在以下问题:
7.1、采用随机游走算法难以差异化处理异构网络中的不同类型节点。
8.2、采用邻域信息聚合难以捕获更高阶的拓扑结构特征。
9.3、按边类型进行邻域聚合,但边类型间融合采用求和方式进行,不能差异化融合不同类型节点的特征。
技术实现要素:
10.针对上述问题,本发明提出一种基于图神经网络的药物靶标预测方法,从节点融合、类型融合、距离融合三个层次进行特征提取,充分提取药物属性特征、疾病属性特征以及药物疾病关联的空间拓扑特征,提高药物靶标预测准确度。
11.本发明的技术方案为:
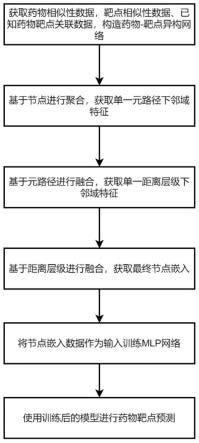
12.一种基于图卷积神经网络的药物靶标预测方法,包括以下步骤:
13.s1、基于已知的数据构建数据集,包括:
14.药物-药物属性相似度矩阵其中nd为药物的数量,药物-药物属性相似度是指药物之间在化学结构上的相似度;
15.药物属性矩阵其中g代表药物属性向量维度,每一行都是一个药物节点的属性向量;
16.靶点-靶点属性相似度矩阵其中n
t
为靶点的数量,靶点-靶点属性相似度是通过归一化smith
–
waterman分数计算得出;
17.靶点属性矩阵h代表靶点属性向量维度,每一行都是一个靶点节点的属性向量;
18.药物-靶点关联定义为当第i个药物和第j个靶点之间存在相互作用关系,y(i,j)=1;当第i个药物和第j个靶点之间不存在相互作用关系,y(i,j)=0;
19.s2、基于s1中的数据集构造异构网络g(e,v,xd,x
t
),其中v是顶点集,顶点集包括药物和靶点两种类型的节点,e是边集,边集基于sd、s
t
、y构造,包括药物-药物、药物-靶点、靶点-靶点三种类型;
20.在异构网络g中,两个节点之间通过不同元路径连接,一条元路径φ定义为由组成的路径,r
l
表示节点a
l
和a
l+1
之间的关系;
21.s3、基于图卷积神经网络学习节点嵌入,具体为:
22.s31、对异构网络g中的药物节点i,将药物节点i通过k距离的元路径φ连接到的所有邻居节点的集合表示为n
iφ
,以i为根节点生成平衡树,将平衡树根到叶子节点的路径记录,作为备选元路径,则定义药物节点i的元路径邻域节点集合为m表示元路径编号,采用k层元路径筛选方法,则进一步定义药物节点i的元路径邻域节点集合为采用k层元路径筛选方法,则进一步定义药物节点i的元路径邻域节点集合为表示距离为k的第m条元路径,1≤k≤k,从而得到药物节点i基于元路径的邻域特征聚合为:
[0023][0024]
其中表示学到的嵌入特征,di是药物节点i对应的特征向量,是节点级注意力向量,表示在元路径下邻居节点l和药物节点i之间的重要性:
[0025][0026]
其中σ表示激活函数,是一个权重向量,||表示拼接操作;
[0027]
在第k层,给定元路径集合后,1≤m≤m,m为总的元路径数量,对于药物节点i,在异构网络g中,药物节点i的元路径包括连接药物节点-药物节点的元路
径、连接药物节点-靶点节点的元路径两类,将连接药物节点-药物节点的元路径用表示,将连接药物节点-靶点节点的元路径用表示,在每一个元路径下对药物节点i进行嵌入,得到节点i在不同元路径下的两类特征,分别为和
[0028]
s32、对获得的两类特征,采用平均池化的方式进行融合:
[0029][0030][0031]
其中表示第k层连接药物节点-药物节点的元路径数量,表示第k层连接药物节点-靶点节点的元路径数量;
[0032]
再采用拼接的方式融合得到第k层的最终特征:
[0033][0034]
最终获得药物节点i所有层次基于距离的特征集合
[0035]
s33、采用注意力机制对基于距离的特征集合进行融合,获得药物节点i的最终嵌入向量为:
[0036][0037]
其中βk是注意力参数,通过对每一层的重要性ωk归一化得到:
[0038][0039]
重要性ωk是通过对层次嵌入使用单层mlp转化度量得到:
[0040][0041]
其中q表示映射向量,tanh是非线性激活函数,w是单层mlp的权重参数,b是偏置;
[0042]
s34、采用如s31-s33的方法,获得靶点节点j对应的嵌入向量pj;
[0043]
s4、采用基于置信的mlp网络进行二分类,基于置信的mlp网络的输入为s3中获得的hi和pj、以及置信因子,根据s1中获得的y,将y中为1的已知药物靶标关联作为正例,随机等量选取未知的药物靶标关联作为负例,对于药物i和靶点j,计算它们之间的置信向量,将嵌入向量hi和pj以及置信向量c拼接作为mlp网络的输入,预测结果表示为:
[0044]
pro
ji
=g(hi,pj,c,θ)
[0045]
其中pro
ji
表示靶点j为药物i的靶标的概率,θ表示mlp网络的参数;
[0046]
置信向量c包括类间转换置信、路径置信、度置信,其中类间转换置信根据不同类
别药物与不同类别靶点间存在的已知药靶关联获得,路径置信通过药物i和靶点j间的最短路与元路径对比计算获得,度置信通过药物i和靶点j在图中的度计算获得;
[0047]
利用获得的数据对基于置信的mlp网络进行训练,损失函数使用交叉熵损失:
[0048][0049]yij
表示药物i和靶点j之间是否存在关联,正类为1,负类为0,n表示已知药物靶标关联对的数量,λ是用于控制正则化项强度的超参;
[0050]
最终得到训练好的网络模型;
[0051]
s5、利用训练好的网络模型进行药物靶标预测。
[0052]
上述方案中,本发明的关键点在于:本发明提出了基于平衡生成树的元路径选择方法,能根据不同路径距离自适应选择合适元路径,使得选择的元路径能涵盖更多的有效消息;采用注意力机制对不同元路径下获取的邻域特征进行融合,差异化融合了不同类型节点的特征;基于距离分层次获取不同远近邻域的特征,能更好地捕获高阶的拓扑结构特征;通过考虑类间置信度、路径置信度和度置信度的mlp网络进行最终药物靶标预测,进一步融合图中的信息。
[0053]
本发明的有益效果为:
[0054]
(1)本发明采用基于置信的mlp网络进行药物靶点关联预测,引入了路径置信、度置信、类间置信等概念,进一步提升模型预测效果。
[0055]
(2)本发明通过平衡生成树的方式进行元路径筛选,节省计算资源的同时能保障获取的元路径是蕴含较多潜藏信息的关键元路径,既降低了模型的计算复杂度又提升了模型的效果。
[0056]
(3)本发明基于距离层级分别提取不同距离下元路径特征,能更好地捕获高阶药物靶点拓扑结构特征,提高卷积神经网络所学嵌入的有效性,提升最终的预测效果。
附图说明
[0057]
图1为本发明的处理过程方法流程图。
[0058]
图2为本发明的网络模型图。
[0059]
图3为元路径筛选示例示意图。
具体实施方式
[0060]
下面结合附图和实施例对本发明进行详细描述。
[0061]
实施例
[0062]
本例中使用的数据来自cdataset数据集,包括2353条已知的药物疾病关联,涉及663个经美国食品药物监管局fda批准药物,409个已经注册的疾病,药物的化学结构、pfam蛋白结构域标注、基因语义注释信息由drugbank数据库中获取,疾病表型数据由omim数据库获取。
[0063]
如图1所示,本例具体步骤如下:
[0064]
1、模型输入与网络构造
[0065]
药物-药物化学结构相似性:使用simcomp工具从yamanishi数据集中获取药物-药
物属性相似度数据。给定两个药物di和dj,分别表示药物列表中第i和第j个药物的化学结构,由原子作为顶点和共价键作为边缘的2d图形,使用jaccard相似度进行计算两个药物的相似度:
[0066][0067]
|di∩dj|表示di和dj之间的最大公共子图中原子的数量,|di∪dj|表示di和dj数量之和减去di和dj之间的最大公共子图中原子的数量,即di和dj的并集。为了便于计算机输入,将nd个药物之间的相似度全部计算出来,使用药物-药物属性相似度矩阵表示,sd(i,j)∈[0,1)表示第o个药物和第j个药物之间的结构属性相似度,其值越高,表示两个药物之间的相似程度越大。
[0068]
药物属性矩阵nd表示不同药物的数量,g代表药物属性向量维度,每一行都是一个药物节点的属性向量,药物属性包括smiles、分子量、脂水分配系数、h键供体数量、h键受体数量、半衰期、熔点、沸点、水溶性、通路、适应症。
[0069]
靶点-靶点序列相似性:从yamanishi数据集中获取靶点-靶点属性相似度数据,使用归一化smith
–
waterman分数计算两个靶点之间的相似度,计算如下:
[0070][0071]
其中,ti和tj表示靶点列表中第i个和第j个靶点,sw(
·
,
·
)表示原始的smith
–
waterman分数。为了便于计算机输入,将n
t
个靶点之间的相似度全部计算出来,使用靶点-靶点属性相似度矩阵表示,s
t
(i,j)表示第i个靶点和第j个靶点之间的序列属性相似度。
[0072]
靶点属性矩阵n
t
表示不同药物的数量,h代表靶点属性向量维度,每一行都是一个靶点节点的属性向量,靶点属性包括种类、来源、蛋白质组、作用类、分子式、分子量、功能、催化活性、活动调节、go分子功能、go生物过程。
[0073]
已知药物-靶点关联nd表示药物的总数,n
t
表示靶点的总数。y(i,j)表示第i个药物和第j个靶点之间的相互作用关系。当第i个药物和第j个靶点之间存在相互作用关系,y(i,j)=1;当第i个药物和第j个靶点之间不存在相互作用关系,y(i,j)=0。
[0074]
利用药物-药物属性相似度矩阵sd、靶点-靶点属性相似度矩阵s
t
、药物-靶点关联矩阵y构造异构网络g(e,v,xd,x
t
),其中e是异构网络的边集,包含药物-药物、药物-靶点、靶点-靶点三种类型的边,v是异构网络的顶点集,包含药物、靶点两种类型的节点,xd表示药物属性矩阵,x
t
靶点属性矩阵。
[0075]
2、基于图卷积神经网络学习节点嵌入
[0076]
2.1节点特征提取
[0077]
在异构图g中,两个节点可以通过不同的语义路径连接,称为元路径,一条元路径φ定义为一条由组成的路径,r
l
表示节点a
l
和a
l+1
之间的关系。节点i基于元路径的邻居节点集n
iφ
由从节点i开始,通过元路径φ连接的所有邻居节点的集合,其中包括节点i自身。
[0078]
基于平衡生成树的元路径筛选方法进行k层元路径筛选:对于第k层,选择筛选出的距离等于k的元路径进行节点特征提取。以第2层为例,对于图中任意节点u,获取其2跳邻域,以u为根节点生成平衡树,将平衡树根到叶子节点的路径记录,作为备选元路径;所有备选元路径根据其出现频次进行排序,选取前
∝
个作为选定的元路径进行后续嵌入学习,
∝
是控制每层元路径数目的超参。
[0079]
药物节点i基于元路径的邻域特征聚合如下:
[0080][0081]
其中表示节点i在距离为k的元路径下学到的嵌入特征,m表示元路径编号,di是节点i对应的特征向量,是节点级注意力向量,表示在元路径下邻居节点l和中心节点i之间的重要性,计算方式如下:
[0082][0083]
其中σ表示激活函数,这里选用relu,是一个权重向量,||表示拼接操作,表示节点i在元路径的邻域节点集合。
[0084]
在第k层,给定元路径集合在每一个元路径下对药物节点i进行嵌入后,可以得到该节点的不同元路径下特征
[0085]
2.2元路径特征融合
[0086]
得到第k层基于不同元路径提取到的特征后,对这些不同类型的特征进行融合。首先将元路径进行分类,对于药物节点i,将所有元路径分为两类,一类是连接药物节点-药物节点的元路径,用表示,一类是连接药物节点-靶点节点的元路径,用表示,对于同一类元路径提取到的特征,采取平均池化的方式进行融合。
[0087][0088][0089]
其中表示第k层连接药物节点-药物节点的元路径数量,表示第k层连接药物节点-靶点节点的元路径数量。
[0090]
对于池化后的不同类型特征,采用拼接的方式融合得到该层的最终特征:
[0091]
[0092]
对每一层进行上述处理后,得到了药物节点i不同层次基于距离的特征集合
[0093]
2.3距离层级特征融合
[0094]
采用注意力机制对上一步得到的基于不同距离提取到的空间特征进行融合,以获取药物节点i的最终嵌入向量表示:
[0095][0096]
其中βk是注意力参数,通过对每一层的重要性ωk归一化得到:
[0097][0098]
而重要性ωk通过对层次嵌入使用单层mlp转化度量得到:
[0099][0100]
其中q表示映射向量,tanh是非线性激活函数,w是单层mlp的权重参数,b是偏置。
[0101]
最终为每一个药物节点i获得了其对应的嵌入向量hi,类似地,为每一个靶点节点j获得对应的嵌入向量pi。
[0102]
3、基于置信mlp网络的药物靶标预测模型
[0103]
将药物靶点预测视为二分类任务,为了提高准确率并引入更多的外部知识,采用基于置信的mlp网络进行二分类,在获得了药物、靶点的嵌入向量后,药物靶点的嵌入向量将作为输入,同时包含外部知识的置信因子也将作为输入,从而训练置信mlp网络作为二分类器g进行药物靶标预测。
[0104]
将y中为1的已知药物靶标关联作为正例,随机等量选取未知的药物靶标关联作为负例,对于药物i和靶点j,计算它们之间的置信向量,将嵌入向量hi和pj以及置信向量c拼接作为mlp网络的输入,预测结果表示为:
[0105]
pro
ji
=g(hi,pj,c,θ)
[0106]
其中pro
ji
表示靶点j为药物i的靶标的概率,θ表示mlp网络的参数。
[0107]
置信向量c由三个部分组成,包括类间转换置信、路径置信、度置信。
[0108]
类间转换置信根据不同类别药物与不同类别靶点间存在的已知药靶关联计算,药物根据类别排序,按照atc(解剖学、治疗学及化学分类系统)分类编码分为14个类别,顺序如下:
[0109]
1.消化道和新陈代谢(a);2.血液和血液形成器官(b);3.心血管系统(c);4.皮肤病(d);5.生殖泌尿系统和性激素(g);6.全身性激素制剂(h);7.全身性抗感染药(j);8.抗肿瘤和免疫调节剂(l);9.肌肉骨骼系统(m);10.神经系统(m);11.抗寄生虫类药物(p);12.呼吸系统(r);13.感觉器官(s);14.其他药物(v)。少量药物对应两个或两个以上的atc编码,则以drugbank网站中的第一个为准。
[0110]
蛋白质采用四种不同的分类标准,包括按组成成分分类(分为简单蛋白质、结合蛋白质、衍生蛋白质)、按分子形状分类(球状蛋白质、叶纤维状蛋白质)、按结构分类(单体蛋
白、寡聚蛋白、多聚蛋白)和按功能分类(结构蛋白、调节蛋白、收缩蛋白、抗体蛋白),分别计算类间转换置信。靶点按对应的蛋白质进行分类。
[0111]
以靶点按功能分类计算类间转换置信为例,类间转换置信计算包含如下过程:按atc分类标准将药物分为14个类别,根据功能将靶点分为4个类别,根据已存在的药物靶点关联,建立类间边计数矩阵t,t∈r
14
×4,t
ij
代表i类药品与j类靶点之间已存在的关联数目,对每一行如下处理得到类间相关性矩阵t
′
:
[0112][0113]
该矩阵中每一项即是基于功能分类的药物靶点类间转换置信值,类似的,可以得到基于组成成分、基于分子形状、基于结构分类的药物靶点类间转换置信值,将这四个值拼接得到类间转换置信向量。
[0114]
路径置信通过药物i和靶点j间的最短路与元路径对比计算得到,计算最短路中包含的元路径数量,对包含的元路径通过注意力值加权求和得到路径置信值,若有多条最短路径,则全部选取并进行加权平均。
[0115]
度置信通过药物i和靶点j在图中的度计算获得,节点存在的边越多,其信息越完整,因此度置信被选择作为置信向量的组成部分之一。
[0116]
将获得的节点嵌入数据作为训练数据对mlp网络进行训练,损失函数使用交叉熵损失:
[0117][0118]yij
表示药物i和靶点j之间是否存在关联,正类为1,负类为0,n表示已知药物靶标关联对的数量,λ是用于控制正则化项强度的超参。
[0119]
从而得到训练好的网络模型,然后使用训练好的模型进行药物靶点预测。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1