一种基于Transformer模型的时序心跳信号预测方法
一种基于transformer模型的时序心跳信号预测方法
技术领域
1.本发明属于心跳信号预测领域,涉及深度学习技术,具体涉及一种基于transformer模型的时序心跳预测方法。
背景技术:
2.近年来,随着人们对于生命健康的不断重视,以及人工智能技术的不断发展,通过大数据进行人体心跳等生命体征分析具有重要的研究价值。人体的心跳信号是非线性限号,且不是随机信号也不是简单的完全周期信号,故而利用深度学习神经网络技术对于心跳预测有着明显优势。例如,文献“song y t.physiological signal analysis based on big data and deep learning[d].[master thesis].nanjing university of posts and telecommunications,2018.”阐述了利用大数据技术和深度学习技术,对于心跳信号分析的可行性。文献“bello g a,dawes t,duan j,et al.deep-learning cardiac motion analysis for human survival prediction[j].nature machine intelligence,2019,1(2):95-104.”通过完全卷积网络学习分割任务,再用去噪自编码器预测网络,学习生存预测的潜在表征来进行生命体征的预测。通过训练找到心脏运动和患者结果之间的对应关系,展示了深度学习算法的有效性,从而有效地预测人类的生存。文献“faust o,hagiwara y,hong t j,et al.deep learning for healthcare applications based on physiological signals[j].computer methods&programs in biomedicine,2018,161:1-13”分析了利用深度学习分析生物信号(包括心电信号)的53篇文章后发现,利用深度学习技术在分析生物信号上有着明显的优势。
[0003]
传统的时序预测模型如长短期记忆神经网络(lstm)在时序预测方面,是通过循环递归的方式来发掘数据间的依赖性,不断训练模型,进行预测。但如果数据集较长,往往会造成信息的损失,对于预测的准确率也有一定影响的缺点。
[0004]
所以,需要一个新的技术方案来解决这些问题。
技术实现要素:
[0005]
发明目的:为了解决传统lstm(长短期记忆神经网络)模型,在心跳信号预测中,由于序列长而造成的信息损失,以及预测准确度不高的问题,提供了一种基于transformer模型的时序心跳预测方法,基于注意力机制和编码器提高了信息融合度,降低信息损失的同时,有效提高了预测准确度。
[0006]
技术方案:为实现上述目的,本发明提供一种基于transformer模型的时序心跳信号的预测方法,包括如下步骤:
[0007]
s1:通过毫米波雷达采集人体心跳信号;
[0008]
s2:对采集的人体心跳信号进行归一化处理;
[0009]
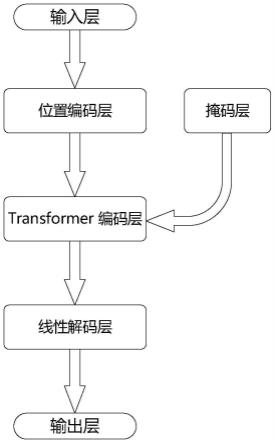
s3:搭建包括输入层,位置编码层(positional encoding)、掩码层(mask),编码层(transformer encoding)、线性解码层(linear decoder)、输出层的transformer模型;
[0010]
s4:利用步骤s2处理好的人体心跳信号数据,对搭建好的transformer模型进行训练;
[0011]
s5:利用训练好的transformer模型对测试信号进行预测,输出预测结果。
[0012]
进一步地,所述步骤s1中人体心跳信号的采集方式为:
[0013]
提取人体心跳信号相位差,按时域结构进行处理,并按标签分类构建共60000帧心跳数据集。
[0014]
进一步地,所述步骤s2中归一化处理的方法为:
[0015]
通过[-1,1]的归一化算法,对采集的人体心跳信号进行处理,具体公式如下:
[0016][0017]
其中,x
sca
为存放归一化处理后的列表,x
sca
为均值,x
max
为最大值,为了不损失值负数的信号数据,采用的归一化的范围为[-1,1]。
[0018]
进一步地,所述步骤s3中位置编码层的搭建方法为:
[0019]
通过生成不同频率的正弦和余弦数据,作为位置编码添加到输入序列中,使模型能够捕捉到输入变量的相对位置关系,即在偶数位置添加正弦变量,奇数位置添加余弦变量再放进pe矩阵中,以此来引入位置编码,公式如下:
[0020]
pe(pos,2i)=sin(pos*e
2i*(-log 1 000/d mod e l)
)
[0021]
pe(pos,2i+1)=cos(pos*e
2i*(-log 1 000/d mod e l)
)
[0022]
其中,pe为一个二维矩阵,pos为当前的词语在整个句子中的位置,i表示词向量的位置,dmodel表示词向量的维度。
[0023]
进一步地,所述步骤s3中掩码层的搭建方法为:
[0024]
通过生成未知字符(-inf)来遮挡未来信息,预防信息泄露,避免了模型在训练时由于读取到未来信息,以至于效果优异,但在实际测试时效果不好的情况。
[0025]
进一步地,所述步骤s3中编码层的搭建方法为:
[0026]
通过使用多头注意力机制(multi-head attention)、add&norm层以及feed forward层组成的编码层,来实现对于输入信号的时序特征的提取;
[0027]
在多头注意力机制中通过将输入序列每个单元的q(query)、k(key)、v(value)通过scaled dot-product attention机制从而进行注意力的分配;在每层scaled dot-product attention中将输入的矩阵与wq,wk,wv分别进行矩阵相乘,进而得到q,k,v三个矩阵,在每个注意力层中,如果相似度最高的q与k将会匹配到一起,即向权重最接近的分配注意力,再通过softmax进行归一化处理后与矩阵v相乘,进行注意力池化,进而得到此层的结果h,将每一层的结果h拼接在一起,再通过简单的linear层进行,就可以得到多头注意力,公式如下:
[0028][0029]hi
=attention(qw
iq
,kw
ik
,vw
iv
)
[0030]
通过相加层(add)和便准化层(norm),组成add&norm层,通过残差连接,让网络只关注当前的差异部分,提高编码效果,公式如下:
[0031]
layernorm(x+multiheadattention(x))
[0032]
layernorm(x+feed forward(x))
[0033]
其中x分别为multi-head attention层和feed forward的输入;
[0034]
通过一层线性激活函数和一层relu激活函数构成前馈层(feed forward)加强特征中数值大的部分,抑制数值小的部分,进而强化特征的表达能力,公式如下:
[0035]
max(0,xw1+b1)w2+b2。
[0036]
进一步地,所述步骤s3中线性编码层的搭建方法为:
[0037]
通过一个线性全连接层的解码器,构成一个回归模型回归,将结果映射到输出层,得到预测值,公式如下:
[0038]
y=wdx
t
+bd[0039]
其中x
t
为编码层得到的连续值,y为回归后的预测输出。
[0040]
进一步地,所述步骤s4中对transformer模型进行训练的方式为:
[0041]
通过adamw优化算法,以及mseloss(均方误差),不断更新学习率,保存每10次迭代的模型,并进行测试;
[0042]
具体过程包括如下步骤:
[0043]
a1:选取66.67%的数据集(约40000个)作为训练集,并以40000*1的矩阵存储下来,其余的数据作为测试集以同样的形式存储下来;
[0044]
a2:将训练集不断放入模型训练,并设定epoch(迭代周期)为100,batch_size(批次大小)为100。
[0045]
a3:保存每迭代10个周期的训练模型,以及其的均方误差(mseloss)。
[0046]
进一步地,所述步骤s5具体为:
[0047]
b1:提取测试集数据,将其分别输入保存好的10个模型中,进行预测测试;
[0048]
b2:分别输出其预测波形以及其的均方误差(mseloss);
[0049]
b3:通过比较均方误差以及预测图,找到最好的预测结果,通过图像输出。
[0050]
有益效果:本发明与现有技术相比,其建立的用于预测心跳信号的transformer模型就是通过深度神经网络搭建而成,其是通过毫米波雷达测得心跳数据,将处理后的数据进行位置编码,依靠注意力机制和掩码层,放入本transformer模型进行训练,最后保存训练好的网络模型,用来预测测试集,达到预测人体心跳信号的目的;实现了一种基于transformer模型的时序心跳信号的预测方法,解决了传统时序心跳预测模型的信息损失大,预测准确度较低的问题,保证了良好的预测效果。
附图说明
[0051]
图1是本发明模型结构图;
[0052]
图2是处理后的原始心跳信号图;
[0053]
图3是mask层工作效果图;
[0054]
图4是transformer encoder层结构图;
[0055]
图5是本发明训练损失图;
[0056]
图6是本发明测试损失图;
[0057]
图7是lstm模型的训练损失图;
[0058]
图8是lstm模型的训练测试图;
[0059]
图9是lstm最好模型测试结果图;
[0060]
图10是本发明最好模型测试结果图;
[0061]
图11是本发明模型与lstm模型的测试结果对比图。
具体实施方式
[0062]
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0063]
一、本发明提供一种基于transformer模型的时序心跳信号的预测方法,包括如下步骤:
[0064]
s1:通过毫米波雷达采集人体心跳信号;
[0065]
s2:对采集的人体心跳信号进行归一化处理;
[0066]
s3:搭建包括输入层,位置编码层(positional encoding)、掩码层(mask),编码层(transformer encoding)、线性解码层(linear decoder)、输出层的transformer模型;
[0067]
s4:利用处理好的人体心跳信号数据,对搭建好的transformer模型进行训练;
[0068]
s5:利用训练好的transformer模型对测试信号进行预测,输出预测结果。
[0069]
二、基于上述技术方案,为了验证本发明方法的效果,本实施例进行实验验证,具体如下:
[0070]
下面将给出一个仿真实例验证本实验的有效性。本实例是通过ti公司的awr1443毫米波雷达传感器采集心跳信号数据,并在pytorch 1.12.0的深度学习框架,通过在配置为intel i7-10875h的cpu和nvidia rtx2060的gpu上完成。
[0071]
步骤1:心跳信号数据采集
[0072]
利用毫米波雷达提取人体心跳信号相位差,按时域结构进行处理,并按标签分类构建共60000帧心跳数据集。用于采集的雷达传感器参数如表1,提取处理后的原始心跳信号如图2所示。
[0073]
表1雷达传感器参数
[0074]
参数数量发射天线数量(个)3接收天线数量(个)4采集帧数(帧)32帧时间(ms)40chirp数(个)32带宽(mhz)1798.92采样点数64采样率(mhz)10
[0075]
步骤2:
[0076]
心跳数据预处理
[0077]
心跳信号处理的方法为:通过[-1,1]的归一化算法,对采集的人体心跳信号进行
处理,具体公式如下:
[0078][0079]
其中的x
sca
存放归一化处理后的列表,x
sca
为均值,x
max
为最大值,为了不损失值负数的信号数据,本实施例采用的归一化的范围为[-1,1]。
[0080]
步骤3:搭建transformer网络模型
[0081]
如图1所示,本网络模型的结构可以如下表示:
[0082]
位置编码层(positional encoding)):
[0083]
通过生成不同频率的正弦和余弦数据,作为位置编码添加到输入序列中,使模型能够捕捉到输入变量的相对位置关系,即在偶数位置添加正弦变量,奇数位置添加余弦变量再放进pe矩阵中,以此来引入位置编码,公式如下:
[0084]
pe(pos,2i)=sin(pos*e
2i*(-log 1 000/dmod e l)
)
[0085]
pe(pos,2i+1)=cos(pos*e
2i*(-log 1 000/d mod e l)
)
[0086]
其中pe为一个二维矩阵,pos为当前的词语在整个句子中的位置,i表示词向量的位置,dmodel表示词向量的维度。
[0087]
掩码层(mask):
[0088]
通过生成未知字符(-inf)来遮挡未来信息,预防信息泄露。避免了模型在训练时由于读取到未来信息,以至于效果优异,但在实际测试时效果不好的情况。其工作效果,如图3所示
[0089]
编码层(transformer encoding):
[0090]
通过使用多头注意力机制(multi-head attention)、add&norm层以及feed forward层组成的编码层,来实现对于输入信号的时序特征的提取。
[0091]
如图4所示,为transformer encoding层结构图。
[0092]
在多头注意力机制中通过将输入序列每个单元的q(query)、k(key)、v(value)通过scaled dot-productattention机制从而进行注意力的分配。在每层scaled dot-productattention中将输入的矩阵与wq,wk,wv分别进行矩阵相乘,进而得到q,k,v三个矩阵,在每个注意力层中,如果相似度最高的q与k将会匹配到一起,即向权重最接近的分配注意力。再通过softmax进行归一化处理后与矩阵v相乘,进行注意力池化,进而得到此层的结果h。将每一层的结果h拼接在一起,再通过简单的linear层进行,就可以得到多头注意力,公式如下:
[0093][0094]hi
=attention(qw
iq
,kw
ik
,vw
iv
)
[0095]
通过相加层(add)和便准化层(norm),组成add&norm层,通过残差连接,让网络只关注当前的差异部分,提高编码效果。公式如下:
[0096]
layernorm(x+multiheadattention(x))
[0097]
layernorm(x+feed forward(x))
[0098]
其中x分别为multi-head attention层和feed forward的输入;
[0099]
通过一层线性激活函数和一层relu激活函数构成前馈层(feed forward)加强特征中数值大的部分,抑制数值小的部分,进而强化特征的表达能力。公式如下:
[0100]
max(0,xw1+b1)w2+b2[0101]
线性解码层(linear-decoder):
[0102]
通过一个线性全连接层的解码器,构成一个回归模型回归,将结果映射到输出层,得到我们的预测值。公式如下:
[0103]
y=wdx
t
+bd[0104]
其中x
t
为编码层得到的连续值,y为回归后的预测输出。
[0105]
步骤4:训练模型,并保存每10次迭代的模型以及mseloss(均方误差)。具体过程如下:
[0106]
a1:选取66.67%的数据集(约40000个)作为训练集,并以40000*1的矩阵存储下来,其余的数据作为测试集以同样的形式存储下来。
[0107]
a2:将训练集不断放入模型训练,并设定epoch(迭代周期)为100,batch_size(批次大小)为100。
[0108]
a3:保存每迭代10个周期的训练模型,以及其的均方误差(mseloss)。
[0109]
如图5所示,为迭代100次中,保存的10个模型的训练损失,此处的损失呈现递减趋势,且在约为70后时保持在最低值0.00679.
[0110]
步骤5:利用保存的10个模型对测试信号进行预测,输出预测结果。
[0111]
b1:提取测试集数据,将其分别输入保存好的10个模型中,进行预测测试。
[0112]
b2:分别输出其预测波形以及其的均方误差(mseloss)。
[0113]
b3:通过比较均方误差以及预测图,找到最好的预测结果,通过图像输出。
[0114]
为了体现本发明的实际效果,本实施例中在传统的lstm网络中进行同样的实验,得到的结果与本发明模型相对比,显示本模型在心跳预测方面的有效性。具体的对比结果如下:
[0115]
如图6所示,为本发明保存的10个模型的测试损失,此处的损失呈现递减趋势,且最终达到的最低值为0.00821。
[0116]
如图7所示,为lstm模型保存的10个模型的训练损失,逐渐递减至最低值0.0225。
[0117]
如图8所示,为lstm模型保存的10个模型的训练损失,逐渐递减至最低值0.0252。
[0118]
与传统lstm模型相比,本发明模型的测试损失下降了0.01699,体现了本发明在心跳预测方面有更好的测试效果。
[0119]
如图9所示,为lstm模型保存的10个模型中,最好模型的测试结果。
[0120]
如图10所示,为本发明保存的10个模型中,最好模型的测试结果。
[0121]
如图11所示,为本模型与lstm模型的测试结果对比图。
[0122]
结合图9-图11可见,与lstm模型的测试结果相比,本发明提供的模型具备更好的预测结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1