一种基于医疗场景的模糊高效用模式挖掘方法与流程
1.本发明是属于数据挖掘方向,具体是一种基于医疗场景的模糊高效用模式挖掘方法。
背景技术:
2.随着第一台计算机的问世,数据也随之产生。超大规模数据库的出现,如商业数据仓库和计算机自动收集数据记录手段的普及使得人类数据量成指数增长。统计方法在数据处理领域应用的不断深入,为人们挖掘数据库提供了方法。先进的计算机技术,如更快和更大的计算能力和并行体系结构使得人们有能力在超大规模数据库中挖掘知识。在这样的背景下,数据挖掘技术也就随之产生.数据挖掘技术有着广泛的应用,例如,关联规则挖掘、序列模式挖掘、文本分类、web日志分析和协同过滤。随着这些年的发展,高效用模式挖掘技术也飞速发展,但高效用模式挖掘主要还是应用于挖掘具有利润信息的数据库,只考虑这些项的数值信息,可解释性较差。
3.数据挖掘是指人们通过仔细研究分析数据来发现蕴藏在其中的有意义的关系,趋势以及模式的过程。agrawal等于1994年提出的apriori算法以及han等于2000年提出的fp-growth算法为频繁模式挖掘算法(frequent itemset mining,fim)的代表方法,经常用来挖掘事务之间的关系。之后人们在此基础上研究出许多fim挖掘算法并应用于各种场景中。但是fim仅考虑项集是否出现,忽略了项集本身的价值。因此liu等于2005年提出的two-phase算法为高效用模式挖掘(high-utility itemset mining,huim)的经典方法。huim能够通过外部效用表以及内部效用表充分考虑项集出现的频次以及项集本身所蕴含的价值这两个因素,相较于fim更加具有实际的导向性。但现阶段的高效用模式挖掘算法,绝大部分都基于一阶段挖掘模型或二阶段挖掘模型设计,这两类挖掘算法在处理同一数据集时,时间复杂度与空间复杂度差别较大。因此往往需要技术人员具有丰富的经验,能够根据数据集的特点选择合适的挖掘算法,这无形中加大了学习成本。
4.模糊(fuzzy)方法是数据挖掘中的常用方法方一。美国控制论专家,数学家查德(zadeh)于1965年发表的论文《模糊集合》(fuzzy sets)中提出隶属度函数作为模糊集合的特征函数,是模糊集合的核心。而随着模糊集应用范围不断扩大,一些扩充模糊集逐渐被使用在各个领域中,这些扩充模糊集包括区间值模糊集,直觉模糊集,vague集,ii型模糊集等。生活中有许多的概念是无法准确定义的,往往是一个模糊的概念。
5.在医疗场景中,基于规则的分类器中采用模糊集理论可以有效的模糊掉阈值以及边界,从而解决尖锐点的问题。由于传统医疗场景中我们获取的各项指标数据常为浮点型数据,而经典的fim算法以及huim算法擅长处理布尔型,二元型以及其他类别型数据。它们可以挖掘出不同数据特征之间蕴藏的关系,所以在疾病的预测以及诊断中具有一定的优势,对于未来诊断的发展具有独特的意义。在传统医疗场景中我们获取的各项指标数据常为浮点型数据,为此,我们在处理完脏数据之后,根据人类各项指标的参考值,将不同数据特征进行模糊化处理,将其转化为布尔型,二元型,或者类别型数据,在利用高效用模式挖
掘算法进行数据挖掘。
6.将体检的浮点型数据转为布尔型数据常用直接划分间隔法和模糊划分间隔法,前者比较简单直接,但是在某些特定的场景下会产生边界尖锐化的问题。以糖尿病体检中常见的空腹血糖值举例。假设某人去医院进行体检,体检内容包括空腹血糖值。空腹血糖值的参考标准为3.2-6.5mmol/l,如果空腹血糖值超过7.0mmol/l,则考虑此人患有糖尿病,从而再进一步的检测。如果此人空腹血糖为8.0mmol/l,那么大概率认为是糖尿病,应该进行仔细检查,这没有什么异议。但如果此人空腹血糖值为6.4mmol/l,那我们该如何划分,是认为没有超过6.5mmol/l,所以不认定为糖尿病患者,还是认为空腹血糖值也挺高,应该进行进一步的检查。那这样看来6.5mmol/l的划分就有些鸡肋。
技术实现要素:
7.针对上述技术问题,本发明提出了一种基于医疗场景的模糊高效用模式挖掘方法,该方法通过引入模糊集理论,使用模糊函数并与高效用模式挖掘算法相结合,从而拓展高效用模式挖掘算法的应用领域,以及增强挖掘结果可解释的方法。并且一阶段与两阶段高效用模式挖掘算法的特点。在大量的实验下,该方法在面对具有不同特征的数据集时,模糊过程对于时间和空间的消耗较为稳定,挖掘过程中时间与空间的平均复杂度相较于传统的一阶段与两阶段挖掘算法有较好的性能。采用本方法使得在面对不同情况下的数据集,依然有着较好的表现。
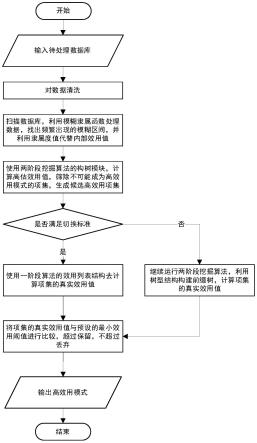
8.为了实现上述技术目的,本发明采用如下具体技术方案:一种基于医疗场景的模糊高效用模式挖掘方法,包括以下步骤:s1、收集医疗场景下患者的各项体检数据并对其进行预处理,所述预处理是:参考医学标准的人类各项指标区间以及标准值,将超出区间范围的值,用边界值进行填补后得到原始数据库数据;s2、该步骤s1得到的原始数据库数据通过模糊函数后,得到区间的隶属度值,将其作为内部效用值,人为指定外部效用表,从而获得可被高效用模式挖掘算法所挖掘的模糊数据库;s3、将步骤s2得到的模糊数据库,使用两阶段挖掘算法进行挖掘,周期性调用切换模块,判断是否满足切换条件,若满足则切换使用一阶段挖掘算法处理,挖掘模糊高效用模式。
9.步骤s1中数据的预处理采用医学上人体属性标准值进行填充,之后进行归一化处理,使得数据全部落在由模糊函数所确定的区间内。
10.所述步骤s2中,选择i型模糊函数或ii型模糊函数,数据经过模糊模块后,分别计算出低、中、高区间的隶属度值;经过第一遍扫描后,得到主区间,继而得到主区间的隶属度值,该值用于高效用模式挖掘算法中的内部效用值,之后将体检数据中各种属性的外部效用值设定为相同值。
11.步骤s3具体包括以下子步骤:s3.1、根据模糊数据库内容构建头表,并计算得到相关参数,根据头表,找到每个叶子结点到根结点的路径,从而获得条件模式基,当遍历完成后,得到所有一项集的模糊高效用模式;
s3.2、设计切换模块,将高效用模式挖掘算法中的,一阶段挖掘算法以及二阶段挖掘算法的特点结合在一起,设计切换模块使得算法以自适应于各类场景,之后筛选出候选高效用项集,在计算真实效用值的时候采用基于列表的算法,从而筛选出高效用项集;s3.3、使用utility-list挖掘高效用模式,在数据库的第一次扫描中,算法找出twu高于最低效用阈值的一项集并进行升序排列,第二次扫描数据库时,按照一项集排列顺序重组数据库,同时生成对于一项集的效用列表,在生成一项集效用列表之后,不断通过组合,{k-1}-length项集的效用列表生成{k}-length项集的效用列表。
12.步骤s3.2中,设计切换模块使得算法以自适应于各类场景中的算法包括:只用两阶段挖掘算法,计算出高估效用值后进行初筛,再计算真实效用值来进行挖掘得到高效用模式;或只采用一阶段挖掘算法直接计算真实效用值,并挖掘模糊高效用模式;或使用树结构去构建效用树,计算高估效用值。
13.本发明的有益效果是:本发明提出了一种基于医疗场景的模糊高效用模式挖掘方法,通过引入模糊集理论与模糊函数模型,使得高效用模式挖掘算法不仅可以适用于交易数据库场景中,同时也可以适用于医疗数据场景中,并且能够增强挖掘结果的可解释性。该方法结合一阶段高效用挖掘算法与两阶段高效用模式挖掘算法的特点,在面对不同特点的数据集时,模糊过程中对时间以及空间的消耗相对比较稳定,挖掘过程中相对于传统的单一算法具有较好的性能。从而使得在面对不同的数据时,该方法整体上有着较好的表现,下面进行具体的说明。
14.参考医学专家给出的指导意见以及利用模糊聚类算法处理数据,得到不同属性的模糊隶属度函数模型。再创新的使用这些模型去处理医疗数据库使其具备效用值,从而可以使用高效用模式挖掘算法进行挖掘。
15.采用混合框架的概念,同时使用一阶段挖掘算法和二阶段挖掘算法挖掘数据库,使得模糊高效用挖掘算法能够适应各种医疗场景下具备不同特点的数据集。并在时空复杂度上有着良好的表现。
16.将模糊集理论引入挖掘的过程中,使得挖掘后的结果不再是冷冰冰的数字,而是转换成更容易理解的语义性的结果,继而增加其结果的可解释性,解决高效用模式挖掘算法中可理解和可解释性差的问题。
17.附图说明
18.图1是本发明提出的方法设计流程图;图2是模糊隶属度函数;图3是模糊化前的数据库形式;图4是模糊处理后的数据库形式;图5是ufh算法框架图;图6-图12是ufh算法构树过程;图13是数据库的eucs结构图。
19.具体实施方案
20.下面结合说明书附图以及实施例对本发明技术方案作进一步详细说明。
21.针对医疗场景下的原始数据集,对其进行边界值处理,空值利用人类各项指标参考值的标准值进行填充后得到原始数据库,该数据库数据通过模糊函数后,得到区间的隶属度值,将其作为内部效用值,人为指定外部效用表。从而获得可被高效用模式挖掘算法所挖掘的模糊数据库。使用两阶段挖掘算法进行挖掘,周期性调用切换模块,判断是否满足切换条件,若满足则切换使用一阶段挖掘算法处理。本发明提出的方法设计流程图如图1所示。
22.一. 体系结构本发明所提的改进ufh算法与传统的ufh算法类似,同样由一种一阶段高效用模式挖掘算法与另一种两阶段高效用模式挖掘算法组成。而本发明的不同之处在于重新设计修改了传统ufh算法中一阶段高效用模式挖掘算法与两阶段模式挖掘算法的相关结构体,使得他们可以存储并处理模糊后的数据。此外,在算法中添加利用模糊集理论模糊原始数据库以及对挖掘结果处理并生成可解释性强的语义性结果的功能代码模块。最终使得改进后的算法可以挖掘模糊高效用模式。
23.二. 方法流程1. 数据预处理在传统的医疗数据场景下,获取到患者的原始体检数据后,参考医学标准的人类各项指标区间以及标准值,将超出区间范围的值,用边界值进行填补,由于之后利用模糊隶属函数处理时,超出区间范围的值与边界值对该区间的隶属度都为1,所以不影响最终结果。对于空白值,采用人类各项指标标准值进行填充,对于某条数据有较多缺失值时,则直接做删除处理。由于不同属性值的所属范围不同,需要对其进行归一化处理。在本发明方法中,采用如图2所示的模糊隶属度函数,所以针对人体不同属性值,归一化处理后,使得所有数据值全部落在0-11之间,从而得到预处理后的原始数据库。
24.模糊化处理由于传统医疗场景中我们获取的各项指标数据常为浮点型数据,而经典的fim算法以及huim算法擅长处理布尔型,二元型以及其他类别型数据。它们可以挖掘出不同数据特征之间蕴藏的关系,所以在疾病的预测以及诊断中具有一定的优势,对于未来诊断的发展具有独特的意义。在传统医疗场景中我们获取的各项指标数据常为浮点型数据,为此,我们在处理完脏数据之后,根据人类各项指标的参考值,将不同数据特征进行模糊化处理,将其转化为布尔型,二元型,或者其他类别型数据,再利用高效用模式挖掘算法进行数据挖掘。
25.将体检的浮点型数据转为布尔型数据常用直接划分间隔法和模糊划分间隔法,前者比较简单直接,但是在某些特定的场景下会产生边界尖锐化的问题。以糖尿病体检中常见的空腹血糖值举例。假设某人去医院进行体检,体检内容包括空腹血糖值。空腹血糖值的参考标准为3.2-6.5mmol/l,如果空腹血糖值超过7.0mmol/l,则考虑此人患有糖尿病,从而再进一步的检测。如果此人空腹血糖为8.0mmol/l,那么大概率认为是糖尿病,应该进行仔
细检查,这没有什么异议。但如果此人空腹血糖值为6.4mmol/l,那我们该如何划分,是认为没有超过6.5mmol/l,所以不认定为糖尿病患者,还是认为空腹血糖值也挺高,应该进行进一步的检查。那这样看来6.5mmol/l的划分就有些鸡肋。而采用模糊划分间隔法,就可以有效的避免尖锐化带来的问题。它将数据空间拓展到模糊空间,分为低、中、高三个区间,用[0,1]区间内的浮点数作为划分后的数据在不同区间的隶属度。经过第一遍扫描后,得到主区间,继而得到主区间的隶属度值,该值用于高效用模式挖掘算法中的内部效用值,之后将体检数据中各种属性的外部效用值设定为相同值。而病症的外部效用值可以增至超过其他属性的外部效用值,继而增加高效用模式集合中病症出现的概率;如空腹血糖值6.4mmol/l可以认为是高血糖,隶属度为0.99,正常血糖,隶属度为0.05,低血糖隶属度为0。模糊处理前的数据库形式如图3所示,处理后的模糊数据库形式如图4所示。
[0026]
改进ufh算法及挖掘过程一阶段挖掘算法和二阶段挖掘算法没有孰好孰坏之分,只是在不同的场景下两种算法会有不同的表现。因此dawar等人与2017年提出了ufh算法,ufh算法本质上是一个混合框架,它能够将一阶段算法和二阶段算法集成到混合框架中,针对不同的场景,可以动态的选择执行两种算法体系中的一种,或者是执行某一种体系的一部分,在转而执行另一只体系的算法。该做法的难点在于如何定义切换的标准以及如何去切换。其处理过程可以分为以下几种情况:1)只用二阶段挖掘算法。扫描数据集并构树,计算高估效用值,用高估效用值去和最低效用值去比较,从而筛除一部分项集。最后计算真实效用值,与最低效用阈值进行比较,从而选出高效用项集。
[0027]
2)只使用一阶段挖掘算法。扫描数据库使用列表去存储信息。跳过生成候选项集的步骤,直接计算真实效用值,这一过程的原理与apriori生成不同长度的项集类似。与最低效用阈值进行比较,从而选出高效用项集。
[0028]
3)使用树结构去构建效用树,计算高估效用值,先筛选出候选高效用项集。在计算真实效用值的时候采用基于列表的算法。从而筛选出高效用项集。
[0029]
4)先执行基于树的算法,在执行到某一时刻时,切换到基于列表的算法。该切换模块可以定义切换标准,从而帮助选择最佳的切换点,使得整体效率最高。如通过观察数据的分布来确定切换的标准。ufh算法整体框架图如图5所示1) 第一遍扫描数据库时对数据集进行模糊化处理,生成具有内部效用表的模糊数据库。ufh算法会根据其模糊数据库的特点,构建头表,计算高估效用值,初步筛选出一项集的候选高效用项集。其中头表中的每一个节点都由项名item,高估效用值n.nu,支持度n.count,以及指向父节点的指针n.parent和指向其他节点的指针n.hlink组成。根节点是一个指向他孩子节点的空节点。从根节点到树中任意节点的路径形成的项集为前缀项集。同时,我们维护了一个头表,头表内主要有item项集名,twu的值,以及一个指向头表的指针。up树中的节点是按照头表中twu值的降序来排列的。并且将不同交易中的相同项通过链表的方式串联在一起。扫描数据库的过程中,ufh算法会计算所有项的事务加权效用(twu)。twu小于预设的最小效用阈值的条目会被从数据库中删除,并且数据库中事务内的项会按照头表中twu值的降序进行排序。按照新数据库的数据生成头表。示例数据库中的数据所构
建的头表过程如图6至图12所示。
[0030]
2) 通过构树算法找出一项集模糊高效用模式,使用一阶段高效用模式挖掘算法直接计算真实效用值,并与最低效用阈值进行比较,从而找出所有的模糊高效用模式。在该过程中使用utility-list挖掘高效用模式。utility-list是一种紧凑的数据结构,用于存储交易数据库中出现的项集及其效用值。其主要由三列数据组成,分别为tid,iutils以及rutils。tid为交易数据库中每一条交易数据的唯一标识。为项集i在交易中的实际效用值。表示i项集的剩余效用值。将数据库中的每一条交易的内部项按照一项集的twu值升序排列重组,称重组后的数据库为重组数据库。在首次扫描数据库后算法找出twu高于最低效用阈值的一项集并进行升序排列。再次扫描数据库时,会按照一项集排列顺序重组数据库,同时生成对于一项集的效用列表。该算法在生成一项集效用列表之后,不断通过组合{k-1}-length项集的效用列表生成{k}-length项集的效用列表。在该过程中,不产生任何高效用的候选项集,并且为了减少连接操作的数量,使用了eucp修剪策略(estimated utility co-occirrence pruning),该修剪数据策略依赖一种数据结构eucs。该数据结构在第二次扫描数据库时被构造。对于任意的项集i,判断其超集是否为高效用项集。我们就可以根据eucs数据结构直接判断是否存在一个超集的iutils与rutils之和大于最小效用阈值。如果不存在则不会进一步去探索。从而减少连接次数。数据库的eucs结构如图13所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1