一种基于多任务学习的异质图卷积网络的药物重定位模型
1.本发明涉及药物研发的技术领域,特别是涉及一种基于多任务学习的异质图卷积网络的药物重定位模型。
背景技术:
2.传统的药物研发过程通常需要十年以上的时间,每种新药得到获批并应用于临床的平均成本超过10-20亿美元,而且,新药发现的成功率不到10%,这远达不到治疗疾病的需求,更不用说治疗罕见和复杂疾病的药物。药物重定位,通常预测药物和疾病的关联来为现有药物寻找新的适应症,与传统药物研发相比,药物重定位可以降低药物研发的成本和时间,提高药物发现的成功率。因此,药物重定位是一个具有应用前景、可行的、重要研究意义的课题。
3.一般来说,现有的重定位计算方法大致可以分为三类:一是基于传统机器学习的方法,将药物重定位作为一个分类问题。从已知的关联数据中提取或学习药物和疾病的特征,接着应用经典的分类算法进行分类,如:svt,rls,rf等;二是基于矩阵分解的方法,将药物-疾病关联矩阵分解为低维的药物特征矩阵和疾病特征矩阵,并推断潜在的药物-疾病关联;三是基于网络的方法,将与药物,疾病相关的数据及关联建模为网络,并从网络中学习到药物,疾病的表示以计算潜在的关联,如gcn,gat等。
4.尽管已经提出了许多用于药物重定位任务的方法,但是现有方法存在以下共同缺点,首先药物-疾病关联数据库中的阳性样本非常稀疏,这对训练有效的药物重定位模型是一个挑战,使得药物重定位的性能较低,而且这些方法,并没有使用特定的过程来处理稀疏问题;其次,尽管存在药物相关的多源数据集,但是这些数据并未在现有方法中得到利用,来自不同生物实验的数据集是从不同的角度描述了药物和疾病的特征。例如,药物可以利用蛋白质/mirnas作为靶点来调节蛋白质/mirnas的表达水平,而蛋白质/mirnas的不适当表达水平可能与某些疾病密切相关。因此针对药物重定位任务,这些方法的性能比较低,其原因是,不能很好的处理药物-疾病关联数据库中的阳性样本非常稀疏的问题,而且也不能从不同生物实验的数据集中获得药物和疾病的多角度的特征。
技术实现要素:
5.为解决上述技术问题,本发明提供一种可以提高药物重定位的性能,解决预测药物-疾病关联任务中阳性样本的稀疏性问题,能够从不同生物实验的数据集中获得药物和疾病的多角度的特征的基于多任务学习的异质图卷积网络的药物重定位模型。
6.本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,包括以下模块:
7.输入模块:通过结合药物、mirna、蛋白质和疾病之间的复杂关联来构建异质信息网络(hin);
8.图表示学习模块:通过堆叠带有残差连接和层级注意力机制的图卷积网络层来学
习hin中节点的表示;
9.多任务预测模块:利用四个预测任务,包括两个与药物相关的预测任务,即药物-mirna关联预测,药物-蛋白质关联预测;两个与疾病相关的预测任务,即mirna-疾病关联预测,蛋白质-疾病关联预测,来作为辅助任务,来帮助药物-疾病关联预测任务的学习,以获得更高质量的节点的表示。
10.本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,其中构建异质信息网络模块:结合药物、疾病相关的多源数据集,构建一个异质信息网络g=(v,e)。
11.v表示节点的集合:分别包括药物集vd,mirna集vm,蛋白质集v
p
,疾病集ve,即v={vd,vm,v
p
,ve},药物,mirna,蛋白质,疾病的数量分别是nd,nm,n
p
,ne;
12.e表示节点之间关联,hin中包含九种类型的边集e,边集e中由以下关联组成:药物-疾病关联药物-mirna关联药物-蛋白质关联mirna-疾病关联蛋白质-疾病关联药物-药物相互作用mirna-mirna相似性蛋白质-蛋白质相互作用以及疾病-疾病相似性使用独热编码表示异质图hin的初始特征,如下:
[0013][0014]
其中,分别是药物、mirna、蛋白质、疾病的初始特征,sd、sm、s
p
、se分别表示nd、nm、n
p
、ne阶单位矩阵,通过初始化hin的特征并利用图表示学习模块来捕获复杂的语义关联,以获得更好的药物和疾病的表示。
[0015]
本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,所述图表示学习模块由聚合邻居节点信息、残差连接和层注意力机制三部分组成。
[0016]
聚合邻居节点信息:hin中不同类型的边集表示节点之间不同的语义,根据hin的拓扑结构,给定药物节点di,有四种与di相邻的边集,包括药物-药物关联、药物-mirna关联、药物-疾病关联和药物-蛋白质关联,用t表示与药物节点相邻的所有类型的边集,在hin中给定类型t∈t,药物节点di的邻居集合用表示,中各节点特征的聚合表示t类型中的邻居对药物di的贡献,通过各类型边获得邻居节点的信息,得到药物di的信息聚合表示。其中每一层gcn对每个节点的信息聚合形式化如下:
[0017][0018]
其中是药物节点di与邻居节点的关联类型为t,在第l层的参数矩阵,b
l
是非线性激活函数relu在第l层的偏置,使用对边缘类型为t的邻居集进行平均,用以解决不同类型邻居集之间存在的数量不平衡问题;
[0019]
残差连接:在每个gcn层中使用残差连接机制,经过形式化后,第l层表示如下:
[0020]
[0021]
其中,是经过第l层gcn信息聚合后的节点表示,h
(1-1)
为第l-l层gcn最后得到的节点表示,换句话说,在经过gcn对各节点信息聚合后得到的表示,并不直接作为下一层gcn的输入;
[0022]
层注意力机制:在图表示模块部分,考虑到不同gcn层获得的表示包含hin中不同的语义信息,通过堆叠四层gcn来获得各节点的最终表示,设计一种层注意力机制对每一层设置不同的权重,用于获得各节点最终的表示,给定各层得到的表示{h
(1)
,
…
,h
(l)
,
…
,h
(l)
},经过层注意力机制得到各层的归一化注意力权重,对于第l层表示,归一化注意力权重用α
l
表示,图表示学习模块学习到各节点的最终表示形式化如下:
[0023][0024]
其中hd、hm、h
p
和he分别表示药物、mirna、蛋白质和疾病的最终表示。
[0025]
本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,多任务预测模块中设计了两类辅助任务,第一种类型的辅助任务包括两个与药物相关的任务,即药物-mirna关联预测和药物-蛋白质关联预测;第二种类型的辅助任务包括两个与疾病相关的任务,即mirna-疾病关联预测和蛋白质-疾病关联预测,接着将药物-疾病关联预测作为目标任务,基于图表示学习模块得到各节点的表示,每项任务由一个具有sigmoid函数的全连接神经网络完成预测,输出被视为两个生物实体之间关联的预测概率,给定药物di和疾病ej的表示其关联概率得分形式化如下:
[0026][0027]
其中,表示两个向量的串联,w
de
和b
de
是用于药物-疾病关联预测任务的sigmoid(
·
)函数的训练参数,类似,分别通过以下公式得到药物-mirna关联预测、药物-蛋白质关联预测、mirna-疾病关联预测和蛋白质-疾病关联预测的预测概率:
[0028][0029][0030][0031][0032]
接着为每个预测任务设计一个交叉熵损失函数,然后将五个损失函数集成到最终的损失函数中,并对整个框架进行训练,以药物-疾病关联预测为例,给出损失函数的形式化定义:
[0033][0034]
其中和分别表示批训练数据的正样本集和负样本集,y
de
(i,j)表示训练样本的真实标签,同理,分别用loss
dm
、loss
dp
、loss
me
和loss
mp
表示四个辅助任务的损失函数,不同类型的辅助任务对目标任务的辅助作用不同,使用超参数α来调整两类辅助任务在最终损失函数中的影响,在形式上,整个框架的最终损失函数定义如下:
[0035]
loss=loss
de
+α(loss
dm
+loss
dp
)+(1-α)(loss
me
+loss
mp
)。
[0036]
与现有技术相比本发明的有益效果为:基于药物和疾病相关的生物实体及其复杂的语义关联构建一个与药物-疾病关联相关的异质信息网络(hin),通过这些数据集,能够获得药物和疾病的多角度的特征。针对异质信息网络中阳性样本稀疏性问题,采用多任务学习机制,设置两类辅助任务来帮助目标任务的学习。其中辅助任务分别是药物-mirna关联预测,药物-蛋白质关联预测,mirna-疾病关联预测,蛋白质-疾病关联预测任务;目标任务是药物-疾病关联预测,将有助于学习更好的药物和疾病表示,以提高模型的性能。
附图说明
[0037]
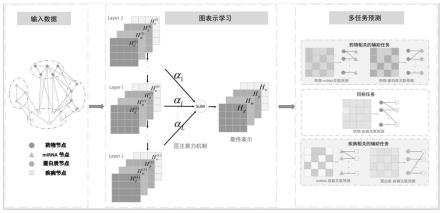
图1是本发明的整体框架示意图;
[0038]
图2是本发明中输入模块的框架示意图;
[0039]
图3是本发明中图表示学习模块的框架示意图;
[0040]
图4是本发明中多任务预测的框架示意图;
具体实施方式
[0041]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0042]
如图1所示,本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,包括以下模块:
[0043]
输入模块:通过药物、mirna、蛋白质和疾病之间的复杂关联来构建异质信息网络(hin);
[0044]
图表示学习模块:通过堆叠带有残差连接和层级注意力机制的图卷积网络层来学习hin中节点的表示;
[0045]
多任务预测模块:利用四个预测任务,包括两个与药物相关的预测任务,即药物-mirna关联预测,药物-蛋白质关联预测;两个与疾病相关的预测任务,即mirna-疾病关联预测,蛋白质-疾病关联预测,来作为辅助任务,帮助学习更高质量的药物和疾病的表示。
[0046]
基于药物和疾病相关的生物实体及其复杂的语义关联构建一个与药物-疾病关联相关的异质信息网络(hin),通过这些数据集,能够获得药物和疾病的多角度的特征。针对异质信息网络中阳性样本稀疏性问题,采用多任务学习机制,设置两类辅助任务来帮助目标任务的学习。其中辅助任务分别是药物-mirna关联预测,药物-蛋白质关联预测,mirna-疾病关联预测,蛋白质-疾病关联预测任务;目标任务是药物-疾病关联预测,将有助于学习更好的药物和疾病表示,以提高模型的性能。
[0047]
本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,构建异构信息网络:结合药物、疾病相关的多源数据集,构建一个异质信息网络g=(v,e)。
[0048]
v表示节点的集合:分别包括药物集vd,mirna集vm,蛋白质集v
p
,疾病集ve,即v={vd,vm,v
p
,ve},药物,mirna,蛋白质,疾病的数量分别是nd,nm,n
p
,ne;
[0049]
e表示节点之间关联,hin中包含九种类型的边集e,边集e中由以下关联组成:药物-疾病关联药物-mirna关联药物-蛋白质关联
mirna-疾病关联蛋白质-疾病关联药物-药物相互作用mirna-mirna相似性蛋白质-蛋白质相互作用以及疾病-疾病相似性使用独热编码表示异质图hin的初始特征,如下:
[0050][0051]
其中,分别是药物、mirna、蛋白质、疾病的初始特征,sd、sm、s
p
、se分别表示nd、nm、n
p
、ne阶单位矩阵,通过初始化hin的特征并利用图表示学习模块来捕获复杂的语义关联,以获得更好的药物和疾病的表示。
[0052]
本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,所述图表示学习模块由聚合邻居节点信息、残差连接和层注意力机制三部分组成。
[0053]
聚合邻居节点信息:hin中不同类型的边集表示节点之间不同的语义,根据hin的拓扑结构,给定药物节点di,有四种与di相邻的边集,包括药物-药物关联、药物-mirna关联、药物-疾病关联和药物-蛋白质关联,用t表示与药物节点相邻的所有类型的边集,在hin中给定类型t∈t,药物节点di的邻居集合用表示,中各节点特征的聚合表示t类型中的邻居对药物di的贡献,通过各类型边获得邻居节点的信息,得到药物di的信息聚合表示。其中每一层gcn对每个节点的信息聚合形式化如下:
[0054][0055]
其中是药物节点di与邻居节点的关联类型为t,在第l层的参数矩阵,b
l
是非线性激活函数relu在第l层的偏置,使用对边缘类型为t的邻居集进行平均,用以解决不同类型邻居集之间存在的数量不平衡问题;
[0056]
残差连接:在每个gcn层中使用残差连接机制,经过形式化后,第一层表示如下:
[0057][0058]
其中,是经过第l层gcn信息聚合后的节点表示,h
(l-1)
为第l-l层gcn最后得到的节点表示,换句话说,在经过本层gcn对各节点信息聚合后得到的表示,并不直接作为下一层gcn的输入。
[0059]
层注意力机制:在图表示模块部分,考虑到不同gcn层获得的表示包含hin中不同的语义信息,通过堆叠四层gcn来获得各节点的最终表示,设计一种层注意力机制对每一层设置不同的权重,用于获得各节点最终的表示,给定各层得到的表示{h
(1)
,
…
,h
(l)
,
…
,h
(l)
},经过层注意力机制得到各层的归一化注意力权重,对于第l层表示,归一化注意力权重用α
l
表示,图表示学习模块学习到各节点的最终表示形式化如下:
[0060][0061]
其中hd、hm、h
p
和he分别表示药物、mirna、蛋白质和疾病的最终表示;通过基于gcn来捕获不同语义的边集进行信息聚合,通过残差连接避免因叠加多层gcn导致梯度消失问题,通过层注意力机制用于获得更加丰富的节点表示。
[0062]
本发明的一种基于多任务学习的异质图卷积网络的药物重定位模型,多任务预测模块中设计了两类辅助任务,第一种类型的辅助任务包括两个与药物相关的任务,即药物-mirna关联预测和药物-蛋白质关联预测;第二种类型的辅助任务包括两个与疾病相关的任务,即mirna-疾病关联预测和蛋白质-疾病关联预测,接着将药物-疾病关联预测作为目标任务,基于图表示学习模块得到各节点的表示,每项任务由一个具有sigmoid函数的全连接神经网络完成预测,输出被视为两个生物实体之间关联的预测概率,给定药物di和疾病ej的表示其关联概率得分形式化如下:
[0063][0064]
其中,表示两个向量的串联,w
de
和b
de
是用于药物-疾病关联预测任务的sigmoid(
·
)函数的训练参数,类似,分别通过以下公式得到药物-mirna关联预测、药物-蛋白质关联预测、mirna-疾病关联预测和蛋白质-疾病关联预测的预测概率:
[0065][0066][0067][0068][0069]
接着为每个预测任务设计一个交叉熵损失函数,然后将五个损失函数集成到最终的损失函数中,并对整个框架进行训练,以药物-疾病关联预测为例,给出损失函数的形式化定义:
[0070][0071]
其中和分别表示批训练数据的正样本集和负样本集,y
de
(i,j)表示训练样本的真实标签,同理,分别用loss
dm
、loss
dp
、loss
me
和loss
mp
表示四个辅助任务的损失函数,不同类型的辅助任务对目标任务的辅助作用不同,使用超参数α来调整两类辅助任务在最终损失函数中的影响,在形式上,整个框架的最终损失函数定义如下:
[0072]
loss=loss
de
+α(loss
dm
+loss
dp
)+(1-α)(loss
me
+loss
mp
);
[0073]
通过最小化损失函数loss,模型中的所有参数通过adam优化器和反向传播以端到端的方式进行优化。通过公式可以发现,辅助任务的损失函数作为目标任务的正则项,在一定程度上解决了目标任务中正样本稀疏性的问题,从而得到更好的药物和疾病的表示。
[0074]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型
也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1