病种多分型标准诊疗方案自动构建系统的制作方法
1.本发明涉及一种病种多分型标准诊疗方案自动构建系统,用于为欺诈骗保案例的审核提供参考依据。
背景技术:
2.目前,医疗就诊单据审核主要分为人工审核和智能审核。
3.人工审核是通过临床人员根据医学知识人工判断就诊是否存在欺诈,审核的准确性依赖于临床人员的知识水平,因此可能存在一些遗漏的情况。人工审核的过程繁琐且耗时较长,对于临床人员的知识要求性也比较高。
4.智能审核,依赖于提前建立的知识库和规则库。当前知识库构建主要为人工摘录各类权威资料,效率和广度有限。而自动化构建知识库又分为基于书籍文本语料的知识图谱构建技术和基于医疗大数据的挖掘构建,相关技术均处于探索研究阶段。
5.其中数据挖掘方向,直接进行使用频率统计,或纯数据驱动的lda主题模型归纳等方式,存在模型结果的解释性低和准确性不足的问题。必要的知识结构和复合的数据挖掘方法成为必然选择。
6.从临床医学知识角度,对病案数据进行分组和归纳的常用方式如drg/dip分组,drg分组对病例的分组较粗,且仅考虑了样本的费用相似性,没有考虑其他因素对于诊疗方案的影响,组内诊疗相似性难以满足要求;dip的分组方式则过于细致,每个细分组在诊疗方案下的差别并不大,知识可用性价值不足,在诊疗方案的临床含义角度解释性不足。
7.因此,需要构建一种新的算法模型,同时结合业内广泛认可的分类知识和自动高效分组的大数据模型。
技术实现要素:
8.本发明的目的是:为医疗就诊单据审核构建一种新的算法模型,同时结合业内广泛认可的分类知识和自动高效分组的大数据模型。
9.为了达到上述目的,本发明的技术方案是提供了一种病种多分型标准诊疗方案自动构建系统,其特征在于,包括:
10.数据预处理模块,用于获取输入病案数据,并对输入病案数据进行预处理;
11.adrg分组模块,进一步包括mdc分组单元以及adrg分组单元,其中:
12.mdc分组单元通过病案首页中的主要诊断的疾病编码与对应的mdc组表格,匹配得到各病案数据所属的mdc组;
13.adrg分组单元在各mdc组下,再根据治疗方式将病例分为“手术”、“非手术”和“操作”三小类,并在各小类下将主要诊断和/或主要操作相同的病例合并成adrg组;
14.核心项目自动识别模块,用于识别adrg组中的核心项目,进一步包括预检测单元以及核心项目识别单元,其中:
15.预检测单元,用于判断病种能否用某几个项目来代表就诊的主要治疗方案,即进
行核心项目代表诊疗方案的可行性检测,对于能用某几个项目来代表就诊的主要治疗方案的病种,则激活核心项目识别单元;
16.核心项目识别单元,用于基于筛选规则筛选出当前病种的核心项目作为重要的分组特征;
17.回归树分组模块:以核心项目自动识别模块识别得到的adrg组中的核心项目和病案数据特征作为输入特征进行回归树的树生成,回归树分组模块基于所生成的回归树做以下判断:基于回归树的分组的节点作为当前病种下的诊疗方案;基于回归树的分组结果,对组内的样本的其他维度的特征进行计算,得到各诊疗方案下的不同特征的数值范围,为判断新入组的样本是否存在欺诈嫌疑提供参考。
18.优选地,所述输入病案数据包括就诊信息、医嘱信息、病案首页信息以及adrg信息。
19.优选地,所述对输入病案数据进行预处理包括筛选出年龄为介于0-110之间的整数、性别为男性或者女性、医疗机构等级为二级或者三级、医疗类别为住院的数据,并:将原始数据中的疾病诊断映射至icd10编码细目层级,并基于icd10层级目录表,关联icd10亚目、类目、章节信息,作为疾病诊断的补充信息输入模型;将项目名称标准化映射至医保三大目录,剔除金额为负的项目;剔除普遍使用的项目。
20.优选地,所述普遍使用的项目包括入院常规检查项目、对于诊断特异性不大的项目、意味不明确的项目。
21.优选地,在所述mdc组表格中,以病案首页的主要诊断为依据,参考国家医疗保障疾病诊断相关分组的主要诊断大类,设定26个mdc组。
22.优选地,所述预检测单元的实现包括以下步骤:
23.选取固定时间段内全部病案数据,将各就诊的处方明细中的项目进行过滤,再对项目按照项目费用由大至小排列,并且计算累计top_n个项目的总费用占该次就诊总费用的比重,从而得到在一个病种下,每次就诊top1,top2,
…
,topn的累计项目费用占比;分别设置累计项目费用占比阈值a和top_n中的n的阈值b,若病种下的累计项目费用占比值大于a且n值小于阈值b,则认为病种能用某几个项目来代表就诊的主要治疗方案;
24.通过计算病种下的不同top_n值对应的平均累计费用占比分布,得到样例病种的累计项目费用占比值大于设定的阈值,且n值小于设定的阈值,说明该病种能够通过top_n项目代表诊疗方案。
25.优选地,所述筛选规则包括:
26.项目的总金额绝对值:大于c元;
27.项目具有特异性:项目在当前adrg组的使用率高于其他adrg组的平均使用率d%以上;
28.项目具有高频高值性:项目次数和项目金额的联合排名在n名内,n《=21。
29.优选地,在所述回归树分组模块中,生成回归树后,先对回归树进行剪枝操作,再基于剪枝后的回归树进行判断,其中,剪枝原则包括:剪枝后,组内cv小于阈值;剪枝后,总体riv下降幅度最小。
30.本发明技术结合临床医学知识和机器学习方法,识别病种下多分型的标准治疗方案,形成病种知识库,从而为欺诈骗保案例的审核提供参考依据。本发明在运用adrg的医学
知识的前提下,对就诊数据运用一些逻辑判断筛选出病种下的核心项目,运用回归树对重要特征进行分组。使得分组结果和分组的特征的临床解释性强,准确性也较高。分组的过程中既考虑到诊疗方案涉及的项目,又能运用模型实现高效的分组。
31.与现有技术相比,本发明具有如下有益效果:1)提供自动生成的各病种下的多分型的诊疗方案;2)核心项目的识别基于动态的topn,更加智能合理;3)诊疗方案的生成效率高;4)诊疗方案的临床可解释性高。
附图说明
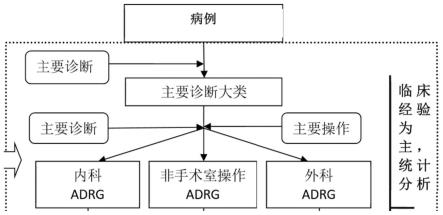
32.图1示意了adrg分组的主要分组流程;
33.图2示意了回归树分组的任务1;
34.图3示意了回归树分组的任务2;
35.图4示意了以白内障病种为例的回归树生成的初步结果;
36.图5示意了以白内障病种为例所获得的最终的结果样例数据。
具体实施方式
37.下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本技术所附权利要求书所限定的范围。
38.本实施例公开的一种病种多分型标准诊疗方案自动构建系统包括:
39.一)数据预处理模块
40.用于获取输入病案数据后,对输入病案数据进行预处理。
41.本实施例中,输入数据包括:
42.(1)就诊信息,进一步包括医疗机构名称、医疗机构等级、出/入院时间、疾病诊断、住院天数、医疗总费用;
43.(2)医嘱信息,进一步包括项目类别、项目名称、开具时间、使用数量、单价、使用金额;
44.(3)病案首页信息,进一步包括出院主要诊断编码、其他诊断编码、手术及操作编码、年龄、不足一周岁年龄、新生儿出生体重、性别;
45.(4)adrg信息,进一步包括:
46.《chs-drg主要诊断大类(mdc)》:包含主诊断疾病编码和对应的mdc编码;
47.《adrg-入组条件配置-诊断》:包含诊断编码和对应的adrg组;
48.《adrg-入组条件配置-手术》:包含手术编码和对应的adrg组。
49.本实施例中,数据预处理模块对输入病案数据的预处理包括从输入病案数据中筛选出符合以下条件的数据,并对数据做相关处理:
50.(1)年龄:介于0-110之间的整数;
51.(2)性别:男性、女性;
52.(3)医疗机构等级:二级、三级;
53.(4)医疗类别:住院;
54.(5)疾病诊断:将原始数据中的疾病诊断映射至icd10编码细目层级,并基于icd10层级目录表,关联icd10亚目、类目、章节信息,作为疾病诊断的补充信息输入模型;
55.(6)项目名称:标准化映射至医保三大目录,剔除金额为负的项目;
56.(7)常规使用项目:剔除普遍使用的项目(20%~35%)剔除,本实施例中:
57.刨除入院常规检查项目,比如血常规,尿常规,肝功和肾功等;
58.刨除对于诊断特异性不大的项目(在所有诊断中都普遍使用);
59.刨除意味不明确的项目,比如诊查费,诊察费,5%西药报销等。
60.二)adrg分组模块,进一步包括mdc分组单元以及adrg分组单元,图1示意了adrg分组的主要分组流程。
61.在mdc分组单元中,以病案首页的主要诊断为依据,参考国家医疗保障疾病诊断相关分组的主要诊断大类,有26个主要诊断大类。通过mdc分组单元得到各病案数据所属的mdc组,具备包括以下步骤:
62.a)地区病案数据编码处理:根据国家医保版《医疗保障疾病诊断分类及代码(icd-10)》和《医疗保障手术操作分类与编码(icd-9cm-3)》对地区数据的疾病的诊断和操作进行编码,实现地区的统一的疾病诊断编码和手术操作编码。
63.b)地区病案数据过滤处理:过滤诊断缺失的就诊记录,过滤掉机构等级不在二级和三级之中的机构和对应的就诊记录。
64.c)mdc预分组:在进行mdc(主要诊断大类)分类之前,首先根据病案首页数据,将器官移植、呼吸机使用超过96小时,年龄小于29天,主要诊断或其他诊断为hiv或者严重创伤进行先期分组,形成mdca、mdcp、mdcy及mdcz。
65.(4)mdc分组:将病案首页的标准化后的诊断编码与《"国家医疗保障疾病诊断相关分组(chs-drg)细分组方案(1.0版)"》(包含mdc编码和医保版icd-10的疾病诊断编码)的诊断编码匹配,从而得到各病案数据所属的mdc组。
66.adrg分组单元根据每个mdc大类中的明细规则对病案数据进行adrg入组,具体包括以下内容:
67.在每个细分的mdc组内,按照一定的匹配优先级和匹配条件进入adrg组(核心疾病诊断相关组),本实施例中,匹配的条件和规则可根据地区医保局的具体需求进行调整。在adrg分组单元中,最终分为376个adrg组,其中外科手术组167个、非手术操作组22个,内科组187个。
68.三)核心项目自动识别模块,进一步包括预检测单元以及核心项目识别单元。
69.预检测单元:
70.选取固定时间段内全部病案数据,将各就诊的处方明细中的项目进行过滤,再对项目按照项目费用由大至小排列,并且计算累计top_n个项目的总费用占该次就诊总费用的比重,从而得到在一个病种下,每次就诊top1,top2,
…
,topn的累计项目费用占比。分别设置累计项目费用占比阈值a和top_n中的n的阈值b,若病种下的累计项目费用占比值大于a且n值小于阈值b,则认为病种能用某几个项目来代表就诊的主要治疗方案。
71.通过计算病种下(icd3)的不同top_n值对应的平均累计费用占比分布,得到样例病种的累计项目费用占比值大于设定的阈值,且n值小于设定的阈值,说明该病种可以通过top_n项目代表诊疗方案。
72.核心项目识别单元:
73.通过预检测单元获取了病种下的top_n的项目后,由核心项目识别单元基于筛选规则对该病种的核心项目进一步提炼。设定筛选规则主要原则包括核心项目需要具有特异性、高值高频性,同时需要刨除常规使用项目。本实施例中,核心项目识别单元识别核心项目具体包括以下步骤:
74.a)在当前adrg组下,筛选大于500元的项目的使用次数占比r1和金额占比r2,计算0.5*r1+0.5*r2得到金额次数重要性指标r。
75.b)在当前adrg组下,对步骤a)中的项目按照的金额次数重要性指标r进行排序。
76.c)对每个项目,对步骤a)中的r1指标计算平均值,得到项目在所有adrg组的平均使用率avg_r1;在当前adrg组下,计算项目使用率r1大于项目平均使用率avg_r1的30%以上且在步骤2中排名在前20名的项目,作为当前adrg组中的核心项目。
77.例如:白内障adrg组的核心项目分别为“人工晶体植入术”和“人工晶体”,这两个项目满足了在白内障adrg组中的项目使用率高于在其他adrg组中的项目平均使用率约30%以上,且这两个项目的金额次数重要性指标r的排名分别为1和2。
78.四)回归树分组模块,回归树分组任务包括:任务1——选择回归树分组的特征;任务2——选择特征进行树分支的判断指标,具备包括以下内容:
79.1)回归树的输入特征确定
80.计算年龄、材料费占比、手术费占比、药品费占比、住院天数与总费用的皮尔森相关系数,结合业务理解,确定输入回归树的特征。
81.最终模型的输入指标包括:核心项目的总金额,核心项目数量,手术费占比,药品费占比,年龄,住院天数,机构等级。
82.由于核心项目是根据不同病种的动态top_n项目和一系列规则逻辑获取的,因此不同的病种的核心项目的数量可能会不同。
83.以白内障为例,回归树的特征输入如下表所示:
84.指标中文名称医疗机构等级年龄分段住院天数分段药品费占比分段手术费占比分段人工晶体植入术的次数人工晶体的数量人工晶体植入术的费用人工晶体的费用
85.2)回归树的数据清洗
86.对于连续自变量,从临床角度划分合理区间段,例:对于年龄,划分为0—17、18—60、60以上,方便回归树对数据进行切分。
87.切分训练数据和验证数据:为校验分组模型的准确性,需按4:1的比例对历史数据进行随机切分,以80%作为回归树的训练数据,用于生成回归树;20%作为验证数据,用于
回归树剪枝。
88.3)回归树的生成
89.获取清洗后的输入特征后开始进行回归树的树生成。具体步骤如下:
90.a)对于清洗好后的训练数据,穷举所有分支节点和分割值。每次切分都会将数据切割成两部分。
91.比如高值项目费用大于1000元,高值项目费用小于1000元。
92.b)对于所有分支方式,计算各自对应的riv,从中选取最大riv分支方式作为本次的最终分支方式,此分支方式将最大程度地降低整体数据的费用变异程度。riv计算公式如下:
93.riv=(ssq-∑ssqn)/ssq
[0094][0095]
式中,ssq代表偏差平方和;ssqn代表第n组子组偏差平方和;xi代表单个子组内的第i项费用;代表单个子组内所有项目的费用均值。
[0096]
c)计算步骤b)中分支方式的两个子组内cv,若分组后任意子组内cv值小于未分组前的平均cv值,且入组人数大于阈值,则可形成细分组;若分组后任意子组内cv值大于未分组前的平均cv且入组人数大于阈值,则对该子组重复步骤a)和步骤b)。
[0097]
d)结束:若所有子组内较上一步中未分组前的cv有所下降,且入组人数大于阈值,或子组无法继续细分,则生成回归树模型。
[0098]
以白内障病种为例,回归树生成的初步结果如图4所示。
[0099]
4)人工审核并运用测试数据对回归树剪枝
[0100]
由于回归树容易存在过拟合的情况,因此需对其进行剪枝操作。首先需对组内cv值大于阈值的组进行人工审核,判定其是否有资格自成组。
[0101]
找出组内数据量不饱和的子组,判定其是否有必要归并到上层组别或者废弃。
[0102]
运用获得的回归树对验证数据集进行分组,评估模型在验证数据集上的分组效果,从而实现自下而上的决策树剪枝,剪枝原则如下:剪枝后,组内cv小于阈值;剪枝后,总体riv下降幅度最小。
[0103]
5)模型评估
[0104]
对原数据进行无重复随机抽样,抽取样本量为原数据量80%。运用上述回归树模型对抽样样本进行分组。统计抽样分组后的riv和cv》阈值的组数占比。
[0105]
同时将分组的节点指标和节点指标对应的分组值抽取出来,经临床判断该分组逻辑是否属于较为典型的诊疗方案。
[0106]
6)结果输出
[0107]
最终得到了在adrg分组规则下的回归树的分组结果。将回归树的节点特征和数值抽取出来,经过处理后,将重要性较高的特征组合,作为在该adrg组内的多分型的诊疗方案。同时总结细分组内的其他维度的特征,为反欺诈场景中新入组的病案样本的欺诈可能性判断提供数据参考。
[0108]
以白内障病种为例,最终的结果样例数据如图5所示。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1