一种基于混合采样策略的中文电子病历命名实体识别方法
1.本发明属于文本处理领域,具体涉及一种基于混合采样策略的中文电子病历命名实体识别方法。
背景技术:
2.中文临床电子病历(chinese electronic medical records,cemrs)作为重要临床数据,以文本或半结构化的形式记录了患者的症状体征、既往史及诊断等信息。因此,结构化地提取病历文本中的信息对于后续临床数据分析尤其重要,其中命名实体识别(named enity recognition,ner)是关键技术之一。中文临床病历命名实体识别是指利用人工智能、数据挖掘等计算机技术,通过对临床电子病历数据进行训练和学习,构建实体抽取模型。这种模型可以自动地从病历文本中提取患者的表型实体,通常包含症状、疾病诊断、检查、检验指标、解剖部位等医学实体。
3.由于在某些领域无法获取大量标注数据或者获取大量标注数据所需代价成本较高,如何在少量标注数据的应用场景下更快地提升中文命名实体识别任务的性能,是一个在实际应用场景中备受关注的问题。例如经过标注的中文电子病历资源目前十分稀缺,如何获得有效的、高质量的标注数据成为了急需解决的问题。
4.主动学习(active learning)是机器学习的一个子领域,主动学习的思想是通过未标注数据基于某一种筛选策略有选择地选取样本进行人工标注,从而达到减少人工标注工作量,同时最大限度的提升模型表现。现有的广泛使用的主动学习策略大致可分为一下几种:
5.(1)基于不确定性采样(uncertainty sampling)的主动学习策略:是最简单直接也最常用的策略。算法只需要查询最不确定的样本给标注,通常情况下,模型通过学习不确定性强的样本的标签能够迅速提升自己的性能。对于一些能预测概率的模型,例如神经网络,可以直接利用概率来表示不确定性。比如,直接用概率值,概率值排名第一和第二的差值,熵值等等。不确定性采样有以下四种:least confidence、margin of confidence、ratio of confidence、entropy。
6.(2)基于多样性采样(diversity sampling)的主动学习策略:是从数据的分布考虑的常用策略。算法根据数据分布确保查询的样本能够覆盖整个数据分布以保证标注数据的多样性。多样性采样有如下四种:model-based outliers、cluster-based sampling、representative sampling、real-world diversity。
7.迁移学习(transfer learning)就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
8.然而,基于不确定性采样的主动学习策略有一个非常强的假设就是所有样本独立同分布,现实世界中并不总是如此。基于多样性采样的主动学习策略相比于基于不确定性
采样的主动学习策略能够更有效的选择具有不同特征的样本,但是却并不能有效识别对于模型来说信息量最丰富的样本。同时主动学习有一个弱点,就是零标记样本冷启动问题。并且传统的主动学习方法无法满足对于句子级准确率有着相当高的要求的中文电子病历命名实体识别这一场景下。
技术实现要素:
9.本发明的目的在于提供一种基于混合采样策略的中文电子病历命名实体识别方法,从而使中文电子病历中信息实现最大化的利用,缓解零标记样本冷启动问题,减少单位样本标注成本以及减少人工标注数据量,提高命名实体识别准确度,为临床分析提供准确的联合混合采样策略主动学习与迁移学习的命名实体识别方法,已解决上述背景技术中存在的至少一项技术问题。
10.本发明提供了一种基于混合采样策略的中文电子病历命名实体识别方法,包括:
11.获取中文电子病历命名数据集样本,并将其划分为源领域数据集样本和目标领域数据集样本;
12.将源领域数据集样本输入到命名实体识别模型中,对其进行预训练;
13.将第一部分的目标领域数据集样本输入到预训练后的命名实体识别模型中,得到第一实体识别结果;
14.采用混合采样策略从所述第一实体识别结果中选择出对应的最优价值的目标领域数据集样本;
15.对选择出的目标领域数据集样本进行标签处理,将处理后的目标领域数据集样本输入到预训练后的命名实体识别模型,对其进行重训练;
16.将第二部分的目标领域数据集样本输入到重训练后的命名实体识别模型中,得到第二实体识别结果。
17.本发明的有益效果:
18.本发明的一种基于混合采样策略的中文电子病历命名实体识别方法,能够使中文电子病历中信息实现最大化的利用,通过迁移学习的方式,将源领域数据集样本训练的模型迁移到目标领域数据集中,能够缓解零标记样本冷启动问题;利用混合采样策略的筛选出更为优选的目标领域数据集样本,对这些样本进行打标后,对模型进行重训练,能够减少单位样本标注成本并减少人工标注数据量,提高命名实体识别准确度。
附图说明
19.为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
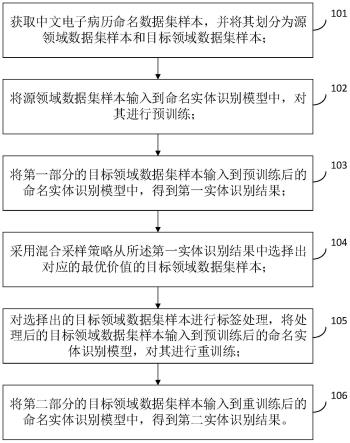
20.图1为本发明实施例所述的中文电子病历命名实体识别方法流程框架图;
21.图2为本发明实施例所述的模型网络结构示意图。
具体实施方式
22.下面详细叙述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
23.本技术领域技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。
24.还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
25.为便于理解本发明,下面结合附图以具体实施例对本发明作进一步解释说明,且具体实施例并不构成对本发明实施例的限定。
26.本领域技术人员应该理解,附图只是实施例的示意图,附图中的部件并不一定是实施本发明所必须的。
27.实施例
28.图1为本发明实施例所述的中文电子病历命名实体识别方法流程框架图,如图1所示,本实施例中,提供一种基于混合采样策略的中文电子病历命名实体识别方法,所述方法包括包括:
29.101、获取中文电子病历命名数据集样本,并将其划分为源领域数据集样本和目标领域数据集样本;
30.在本发明实施例中,所述中文电子病历命名数据集样本指的是使用电子设备(计算机、健康卡等)保存、管理、传输和重现的数字化的医疗记录,用以取代手写纸张病例的所有信息。电子病历包括疾病案首页、术后病程、检查结果、医嘱、手术记录、入院记录等等各种不同类型的中文文书,不同类型的中文文书所包括的章节类型也有所不同(例如入院记录中包括主诉、现病史、家族史等章节)。
31.在本发明实施例中,考虑到中文电子病历需要花费大量的时间和成本进行打标,为了解决这个问题,本发明采用迁移学习的方式,将采集到的中文电子病历命名数据集样本分为有标签的源领域数据集样本,少量标记实体甚至无标记实体的目标领域数据集样本,由于源领域数据集样本和目标域数据集样本同属于中文电子病历,其数据分布是相似的,因此可以采用迁移学习的方式将源领域数据集样本学习到的分布特征迁移到目标领域数据样本中,减少对目标领域数据集样本的打标次数。
32.102、将源领域数据集样本输入到命名实体识别模型中,对其进行预训练;
33.在本发明实施例,如图2所示,所述命名实体识别模型包括bert层、bilstm层和crf层;所述bert层用于对中文电子病历文本中的各个单词生成词嵌入向量;所述bilstm层用于中文电子病历文本的词嵌入向量和序列特征进行整合并进行特征编码,得到标签;所述crf层使用维特比算法得到最优的标签序列,所述标签序列即为对中文电子病历文本的实体识别结果。
34.可以理解的是,源领域数据集样本所采用的命名实体识别模型与目标领域数据集样本所采用的命名实体识别模型的结构是一样,源领域网络结构和目标领域网络结构共享模型参数,这就实现了迁移的目的。
35.在本发明实施例中,对命名实体识别模型进行预训练的过程可以包括如下内容:
36.将源领域数据集样本按4:1划分为训练集和验证集,对训练集的文本输入网络中的bert层进行划分,将划分后的文本通过bilstm层进行编码处理,得到文本中每个单词的编码向量,将文本中每个单词的编码向量输入crf层,得到文本中所有单词的预测标签,并计算文本中所有单词的预测标签得分,根据预测标签可以定义损失函数,在训练的过程中对模型参数进行更新以不断减少损失,当所述损失函数收敛时,完成预训练,确定出预训练后的命名实体识别模型。
37.在本发明实施例中,所述损失函数可以表示为:
[0038][0039]
其中,y(h)中共有n个可能的标注序列,si表示第i个标注序列的分数;h
i,yi
对应于从bilstm层获得的标注为yi的第i个字符;t是转移矩阵,t
p,q
表示从标签p转移到标签q的分数。
[0040]
103、将第一部分的目标领域数据集样本输入到预训练后的命名实体识别模型中,得到第一实体识别结果;
[0041]
在本发明实施例中,可以将目标领域数据集样本进行划分,一部分用来进行训练,另一部分可以用来测试,实现对无标签的目标领域数据集样本的标签识别。
[0042]
在本发明实施例中,将第一部分的目标领域数据集样本输入到预训练后的命名实体识别模型中,由于源领域数据集样本与目标领域数据集样本类似,这里就可以缓解无标记的目标领域数据集样本的冷启动问题,就可以得到第一部分的目标领域数据集样本对应的第一实体识别结果。
[0043]
在本发明的优选实施例中,所述步骤103还可以具体包括如下过程:
[0044]
步骤一:将目标领域数据集进行文本划分,得到文本长度小于等于256,若文本长度小于256的序列用padding的方式补齐;
[0045]
步骤二:将划分好的单词进行编码,包括词编码(token embedding)、句子编码(sentence embedding)、位置编码(position embedding);
[0046]
步骤三:更改模型标签为目标领域实体标签,将编码后的文本输入到命名实体识别模型中输出,通过维特比解码,得到最终的第一识别结果。
[0047]
104、采用混合采样策略从所述第一实体识别结果中选择出对应的最优价值的目标领域数据集样本;
[0048]
在本发明实施例中,考虑到本发明的目标领域数据集样本都是无标签的,而对大量的目标领域数据集样本打标则会使用大量的时间和成本,因此,本发明利用混合采样策略选择部分目标领域数据集样本进行打标,减少单位样本标注成本以及减少人工标注数据量。
[0049]
在本发明实施例中,所述采用混合采样策略从所述第一实体识别结果中选择出对应的最优价值的目标领域数据集样本包括采用不确定采样策略结合代表性采样策略从第一部分的目标领域数据集样本筛选出最优价值的目标领域数据集样本,即利用不确定采样策略选择序列置信度高的序列样本,利用代表性采用策略选择信息密度大的序列样本。
[0050]
可以理解的是,序列置信度的高低程度以及信息密度的大小程度可由本领域技术人员根据实际情况进行选择,例如选择置信度排名为前10%的序列样本;选择信息密度排名为前10%的序列样本;本发明对此不作具体的限定。
[0051]
对于利用不确定采样策略选择序列置信度高的序列样本:
[0052]
本实施例是通过计算样本的序列置信度来衡量样本的不确定性,基于最低置信度原则进行样本选择:
[0053][0054]
其中,φ
le
(x
ij
)表示第j个序列样本在第i个分词x
ij
处置信度,是第i个分词xi对应的最可能的标签序列,j={1,2,...,m},m表示序列样本个数,i={1,2,...,n},n表示每个序列样本中的分词数量。
[0055]
可以理解的是,在本发明实施例中,可以针对每个分词和每个序列样本分别求取置信度,如果求取第i个分词x
ij
处置信度时,就需要采用第j个序列样本在第i个分词x
ij
和第i个分词的最可能序列如果求取第j个序列样本的置信度时,就需要采用第j个序列样本最可能的序列和第j个序列样本xj。
[0056]
基于上述分析,在本发明的优选实施例中,本发明还提出了归一化样本采样策略:
[0057][0058]
其中,φ
lc
(xj)表示第j个序列样本xj的归一化置信度。
[0059]
通过所述归一化样本采样策略能够选择出序列置信度高的序列样本。
[0060]
对于利用代表性采用策略选择信息密度大的序列样本:
[0061]
基于不确定性的样本选择策略可能带来孤立点对模型的影响,本实施例中通过衡量信息密度来避免该问题。利用模型的预测标签的后验概率来计算序列样本x的信息熵:
[0062][0063]
其中,φ
se
(xj)表示第j个序列样本xj的信息熵,i={1,2,...,n},n表示每个序列样本中的分词数量,l为标签个数;p(yi=l)表示当前预测结果l时,序列样本中分词位置为i的字符的边缘概率。
[0064]
得到样本x的信息熵后,计算其信息密度:
[0065][0066]
其中,φ
sr
(xj)为序列样本xj的代表性,,通过计算样本x与未标记样本池中的其他样本的平均相似度衡量样本得到;u为未标注样本池中的其他序列样本数量,xu表示未标注
样本池中的第u个序列样本,sim(xj,xu)为序列样本xj与序列样本x
(u)
的相似度。
[0067]
为了计算两个样本句子的相似度,首先需要将每个句子转换成向量表示,即:
[0068][0069]
其中,x1,x2,
…
,x
len(x)
表示句子中每个字符对应的字向量。
[0070]
采用基于百度百科语料使用负采样的skip-gram预训练的中文词向量,筛选其中长度为1的单词即可得到中文字符向量,利用向量计算句子之间的余弦相似度,即:
[0071][0072]
因此,利用代表性采用策略选择信息密度大的序列样本所采用的公式就可以表示为:
[0073]
φ
id
(xj)=φ
se
(xj)
×
φ
sr
(xj)
[0074]
其中,φ
id
(xj)表示目标领域数据集样本xj的信息密度,φ
se
(xj)表示目标领域数据集样本xj的信息熵,φ
sr
(xj)表示目标领域数据集样本xj的代表性。
[0075]
通过模型对未标注样本池中序列样本预测的后验概率,批量选择φ
lc
(x)值高的序列样本,并从中选择信息密度φ
id
(x)大的样本,即可实现混合采样,从而保证选择出的数据具有代表性。
[0076]
105、对选择出的目标领域数据集样本进行标签处理,将处理后的目标领域数据集样本输入到预训练后的命名实体识别模型,对其进行重训练;
[0077]
在本发明实施例中,将步骤104采样选择出的目标域数据集样本进行打标,将打标后的目标领域数据集样本输入到预训练后的命名实体识别模型,对该模型进行重训练,提升模型的识别能力。
[0078]
106、将第二部分的目标领域数据集样本输入到重训练后的命名实体识别模型中,得到第二实体识别结果。
[0079]
在本发明实施例中,可以将实现对无标签的目标领域数据集样本的标签识别。
[0080]
在本发明的优选实施例中,在得到第二部分的目标领域数据集样本的第二实体识别结果后,本发明还可以继续对命名实体识别模型进行重训练,即步骤104~步骤106可以进行循环处理,保证识别模型的准确性。
[0081]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
[0082]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1