基于策略梯度和结构信息的抗癌肽生成模型及其训练方法
本发明属于计算机人工智能与抗癌肽设计的交叉,更具体地,涉及一种基于策略梯度和结构信息的抗癌肽生成模型的训练方法。
背景技术:
1、多肽具有高特异性、高选择性、安全、易获取和免疫原性低等特点,且优于以往药物设计上研究主要关注的小分子或蛋白质,所以多肽是一种在生物技术应用中的治疗和诊断等领域有前景的药物候选物。对于多肽的设计,尤其是抗癌肽的设计,已经从以往的湿实验到机器学习转到了现在的深度生成模型。
2、现有的抗癌肽生成方法都是基于抗癌肽序列数据的学习,主要通过以下三种方法实现,第一种是用传统机器学习模型,首先设计特征提取器来处理数据,然后通过机器学习算法生成抗癌肽,接着用预测器来预测生成抗癌肽的活性;第二种是简单地用多肽深度生成模型直接拟合抗癌肽数据或者加上有药物所需性质的多肽数据的分布,然后用预测器来预测生成抗癌肽的活性;第三种是通过一些约束训练性质可控的抗癌肽生成模型,约束可以是强化学习或者拒绝采样等方法。
3、然而,现有的抗癌肽生成方法存在一些不可忽略的缺陷:第一、传统的机器学习技术需要大量的领域专业知识来设计特征提取器,在处理数据方面受到限制,使得多肽的生成过程繁琐;第二、现有的多肽深度生成模型一般只考虑到某种特定的活性或者少量属性,在生成后还需要通过预测模型作为辅助筛选,最后通过实验来筛选更符合药物所需性质的多肽序列,这样的多肽设计框架没有达到理想的速度;第三、现有的抗癌肽生成模型只考虑了序列信息,而没有考虑到对多肽的物理与化学性质有决定性关系的结构信息,这会导致模型不能学习到对多肽的物理与化学性质有决定性关系的结构信息。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种基于策略梯度和结构信息的抗癌肽生成模型及其训练方法,其目的在于,解决传统的机器学习技术需要大量的领域专业知识来设计特征提取器,在处理数据方面受到限制,使得多肽的生成过程繁琐的技术问题,以及现有多肽深度生成模型无法达到理想速度的技术问题,以及现有的抗癌肽生成模型由于没有考虑到结构信息,导致模型不能学习到对多肽的物理与化学性质有决定性关系的结构信息的技术问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种抗癌肽生成模型,包括生成模块和预测模块两个部分。其中生成模块是序列生成对抗网络seqgan,且包括2个具有相同结构的生成器和1个判别器,生成器的结构如下:
3、第1层为嵌入层,输入大小为20的多肽序列索引向量,输出一个20*32的嵌入矩阵;
4、第2层为基于门控循环单元gru的循环神经网络rnn层,在每个时间步,输入为20*32维矩阵,输出1*32的隐藏单元向量,最后输出20个1*32的隐藏单元向量;
5、第3层为softmax输出层,输入为1*32的每个时间步的输出的隐藏单元向量,通过线性映射和softmax激活函数,输出1*20的向量,最后输出20*20的矩阵;
6、另一个生成器是推出策略需要的生成器,和第一个生成器具有同样的结构。
7、判别器的结构如下:
8、第1层为嵌入层,输入20*20的多肽序列独热编码,利用一个20*64的矩阵,输出一个20*64的嵌入矩阵;
9、第2层为卷积层,输入20*64的嵌入矩阵,其中有2种卷积核,大小分别为2和3,步长为1,数量分别为100个和200个,输出大小分别为19*100和18*200的特征矩阵;
10、第3层为线性整流函数relu层,利用relu非线性激活函数,输入和输出19*100和18*200的特征矩阵;
11、第4层为池化层,输入19*100和18*200的特征矩阵,利用最大池化选取每个特征向量中的最大值,然后将得到的1*100和1*200的矩阵拼接,输出1*300的多肽序列特征向量;
12、第5层为highway层,输入和输出1*300的特征向量;
13、第6层为丢弃层,输入和输出1*300的特征向量;
14、第7层为softmax输出层,输入1*300的特征向量,利用一个300*2的矩阵,通过线性映射和softmax激活函数,得到1*2的向量,最后经过argmax函数输出1个数值。
15、预测模块是基于图神经网络gnn的抗癌肽预测器,其具体结构为:
16、第1层为嵌入层,输入大小为n的分子指纹向量,输出n*50的嵌入矩阵,其中n是分子指纹的长度,即原子数量;
17、第2层为gnn层,输入n*50的嵌入矩阵和n*n的邻接矩阵,利用线性映射和relu激活函数、特征矩阵更新函数和对每个特征维度的均值求解,输出1*50的向量;
18、第3、4和5层均为和第2层相同的gnn层,输入和输出也与第2层相同;
19、第6层为relu激活层,将2-5层输出的向量进行连接,以得到1*200的向量,经过线性映射和relu激活函数,输出1*800向量;
20、第7层为全连接层,输入1*800的向量,输出1*2的向量。
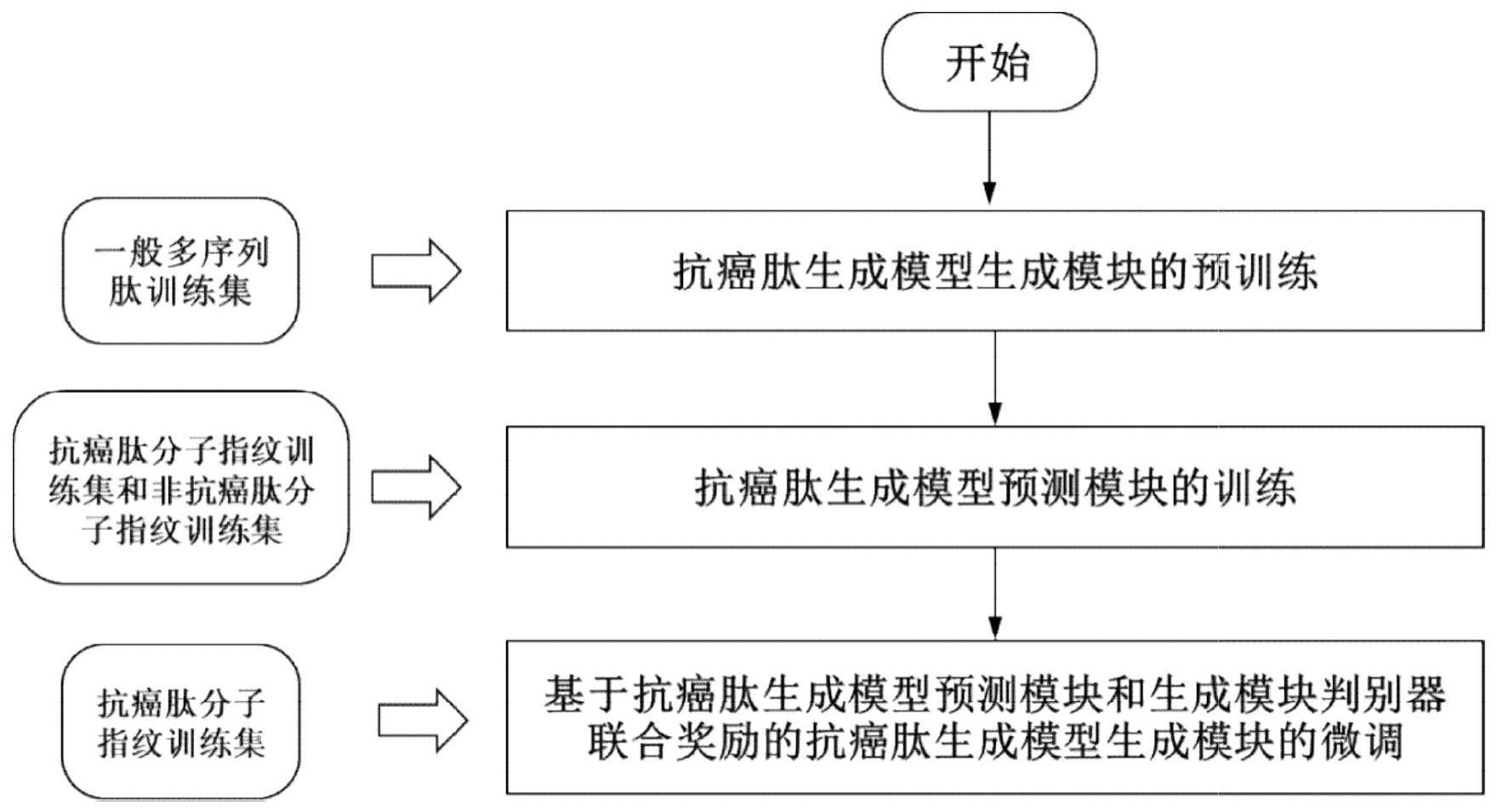
21、按照本发明的另一方面,提供了一种抗癌肽生成模型的训练方法,包括以下步骤:
22、(1)获取一般多肽序列数据、抗癌肽序列数据和非抗癌肽序列数据,并根据氨基酸词表对一般多肽序列数据、抗癌肽序列数据和非抗癌肽序列数据进行数字编码,以得到一般多肽序列数据集、抗癌肽序列数据集和非抗癌肽序列数据集。
23、(2)将步骤(1)得到的一般多肽序列数据集、抗癌肽序列数据集和非抗癌肽序列数据集分别按照训练集和测试集8:2的比例进行划分,以得到一般多肽序列训练集和测试集、抗癌肽序列训练集和测试集和非抗癌肽序列训练集和测试集。
24、(3)将步骤(2)得到的一般多肽序列训练集输入抗癌肽生成模型的生成模块中,并使用反向传播算法对生成模块中每层的权重参数和偏置参数进行更新和优化,以得到预训练好的生成模块;
25、(4)使用rdkit工具包分别将步骤(1)得到的抗癌肽序列数据和非抗癌肽序列数据中的氨基酸序列格式分别转换成抗癌肽分子图数据和和非抗癌肽分子图数据;
26、(5)利用一维魏斯菲勒雷曼1-wl算法编码步骤(4)得到的抗癌肽分子图数据和和非抗癌肽分子图数据并设置标签,以得到抗癌肽分子指纹数据和非抗癌肽分子指纹数据,其均用数值向量表示,且分别包含分子指纹和邻接矩阵;
27、(6)将步骤(5)得到的抗癌肽分子指纹数据和非抗癌肽分子指纹数据按照训练集和测试集8:2的比例进行划分,以得到抗癌肽分子指纹训练集和测试集,非抗癌肽分子指纹训练集和测试集。
28、(7)将步骤(6)得到的抗癌肽分子指纹训练集和非抗癌肽分子指纹训练集输入到抗癌肽生成模型的预测模块中,并使用反向传播算法对预测模块中每层的权重参数和偏置参数进行更新和优化,以得到更新后的抗癌肽生成模型的预测模块;
29、(8)将步骤(2)得到的抗癌肽序列训练集输入到步骤(3)得到的抗癌肽生成模型的生成模块中,并使用反向传播算法对抗癌肽生成模型的生成模块中每层的权重参数和偏置参数进行更新和优化,以得到微调好的抗癌肽生成模型的生成模块,从而得到训练好的抗癌肽生成模型。
30、优选地,步骤(3)包括以下子步骤:
31、(3-1)将步骤(2)得到的一般多肽序列训练集的数值编码向量输入到抗癌肽生成模型中生成模块的生成器的嵌入层,以得到嵌入矩阵x={x1,...,xn},其中n表示多肽序列长度,x1表示在一条多肽序列里第一个氨基酸的嵌入向量,xn表示在一条多肽序列里第n个氨基酸的嵌入向量;
32、(3-2)将步骤(3-1)得到的嵌入矩阵x={x1,...,xn}输入到生成模块中生成器的基于gru的rnn层,以得到n个隐藏向量{h1,...,hn};
33、其中n个隐藏向量{h1,...,hn}是通过按顺序对n个嵌入向量{x1,...,xn}使用更新函数g得到的,在生成n个隐藏向量的过程中,第t个时间步的隐藏向量ht由嵌入向量xt和第t-1个时间步的隐藏向量ht-1决定,其计算公式为:
34、ht=g(xt,ht-1)
35、其中t∈[1,n],xt是第t个时间步的嵌入向量,ht是第t个时间步的隐藏向量,g为更新函数;
36、(3-3)将步骤(3-2)得到的n个隐藏向量{h1,...,hn}输入到生成模块中生成器的softmax层,以得到生成多肽序列,其包括n个时间步的生成器输出令牌;
37、其中每个时间步的生成器输出令牌的计算方式为:
38、yt=softmax(wht+b)
39、其中t∈[1,n],w是权重矩阵,b是偏置向量,ht是第t个时间步的隐藏向量,yt表示第t个时间步的生成器输出令牌,softmax()表示softmax激活函数;
40、(3-4)使用步骤(3-3)得到的生成多肽序列与步骤(2)得到的一般多肽序列训练集的交叉熵损失对生成模块的生成器进行梯度更新,并对更新后的生成器进行迭代训练,直到损失函数最小为止,从而得到预训练好的生成模块的生成器gθ;
41、其中第t个时间步的交叉熵损失的计算方式为:
42、lt=-ytlog^t
43、其中,yt是第t个时间步的生成器输出令牌,是训练集中多肽序列第t个位置的令牌,lt是第t个时间步的交叉熵损失;
44、(3-5)利用步骤(3-4)得到的生成模块的生成器采样到固定长度的多肽序列;
45、(3-6)将步骤(2)得到的一般多肽序列训练集和步骤(3-5)得到的多肽序列依次输入到生成模块中判别器的嵌入层、卷积层、relu层、池化层、highway层和丢弃层,以得到特征矩阵;
46、(3-7)将步骤(3-6)得到的特征矩阵输入到生成模块中判别器的softmax层,以得到判别分数;
47、(3-8)利用步骤(3-7)得到的判别分数的交叉熵损失对生成模块的判别器进行梯度更新,并对更新后的判别器进行迭代训练,直到损失函数最小为止,从而得到预训练好的生成模块的判别器d;
48、其中判别器的损失计算方式如下:
49、
50、其中,yi是一般多肽序列训练集中的第i个多肽序列,是生成的多肽序列集中的一个多肽序列,d()是判别器d的判别分数,bce()表示计算判别分数和真实标签0或1的交叉熵,n表示一般多肽序列训练集中多肽序列的数量,ld是判别器损失;
51、(3-9)将步骤(3-4)得到的生成模块的生成器gθ作为roll-out生成器gβ使用;
52、(3-10)利用步骤(3-4)得到的生成模块的生成器gθ生成多肽序列段,利用步骤(3-9)得到的roll-out生成器gβ对多肽序列段生成后续的令牌,以得到完整多肽序列,并将生成的完整多肽序列输入到步骤(3-8)得到的生成模块的判别器d,以得到生成的完整多肽序列的序列奖励。
53、(3-11)根据步骤(3-10)得到的生成的完整多肽序列的序列奖励获取期望奖励,通过最大化该期望奖励对步骤(3-4)得到的生成器gθ的参数进行梯度更新,以得到更新后的生成模块的生成器gθ;
54、(3-12)利用步骤(3-11)更新后的生成模块的生成器gθ进行采样,以得到多个多肽序列样本;
55、(3-13)将步骤(2)得到的一般多肽序列训练集和步骤(3-12)采样的多肽序列样本输入到步骤(3-8)得到的生成模块的判别器,并重复执行一次步骤(3-6)-(3-8),以得到更新的生成模块判别器;
56、(3-14)将步骤(3-11)得到的生成模块的生成器gθ作为roll-out生成器gβ使用,利用步骤(3-11)得到的生成模块的生成器gθ生成多肽序列段,利用roll-out生成器gβ对多肽序列段生成后续的令牌,以得到完整多肽序列,并将生成的完整多肽序列输入到步骤(3-13)得到的生成模块的判别器d,以得到生成的完整多肽序列的序列奖励;
57、(3-15)根据步骤(3-15)得到的生成的完整多肽序列的序列奖励获取期望奖励,通过最大化该期望奖励对步骤(3-11)得到的生成器gθ的参数进行梯度更新,以得到更新后的生成模块的生成器gθ;
58、(3-16)重复执行步骤(3-12)至步骤(3-15),直到生成模块中的生成器和判别器收敛为止,从而得到预训练好的抗癌肽生成模型的生成模块。
59、优选地,最大化期望奖励的计算方式如下:
60、
61、其中,j()为目标函数,是期望,θ是生成模块的生成器gθ的参数,gθ(st|s1:t-1)生成一个多肽序列段,是序列奖励,s是gθ生成的多肽序列;希望得到生成模型的参数θ,使得生成模型能在s1:t-1处做出最佳选择,以在生成第t个(最后一个)多肽序列时获得大回报rt,如何得到最佳选择取决于序列奖励
62、序列奖励的计算方式如下:
63、
64、其中,st是gθ生成的第t个令牌,t表示完整多肽序列的长度,s1:t是生成器gθ生成的第t个多肽序列段,表示在gθ生成多肽序列段s1:t时,利用蒙特卡洛采样,在多肽序列段的基础上,利用roll-out生成器gβ生成n个长度为t的完整多肽序列;t<t时,表示判别器d对gβ生成的完整多肽序列的判别分数,t=t时,表示判别器d对gθ生成的完整多肽序列的判别分数;
65、利用梯度上升,生成模块的生成器gθ目标函数的梯度即梯度更新计算方式如下:
66、
67、θ←θ+αj(θ)
68、其中,α是学习率,t是完整多肽序列的长度,s1:t-1是生成模块的生成器gθ生成的第t-1个多肽序列段,是序列奖励,为期望,可以近似为蒙特卡洛采样方法,表示对生成器gθ求导,是目标函数梯度。
69、优选地,节点标签和边标签的计算方式如下:
70、
71、
72、其中,表示在第t次迭代更新节点v的标签,表示在第t-1次迭代更新节点u的标签,表示在第t次迭代更新节点u和v之间的边的标签,n(v)表示节点v的邻居节点集合,hash()表示运用哈希单射函数可以将公式中得到的所有数据组映射成独一无二的整数。
73、优选地,步骤(7)包括以下子步骤:
74、(7-1)将步骤(6)得到的抗癌肽分子指纹训练集和非抗癌肽分子指纹训练集输入到预测模块的嵌入层,以得到分子指纹的嵌入矩阵h;
75、(7-2)将步骤(7-1)得到的嵌入矩阵h和相应的邻接矩阵a输入到预测模块的gnn层,以得到特征向量;
76、(7-3)将步骤(7-2)得到的i个特征向量拼接起来,输入到relu线性层和全连接层,再经过softmax层,以得到预测向量;
77、(7-4)将步骤(7-3)得到的预测向量和相应的步骤(5)得到数据标签的交叉熵损失来进行梯度更新,对更新的预测模块进行迭代训练,直到损失函数最小为止,从而得到预训练好的抗癌肽生成模型的预测模块。
78、优选地,步骤(7-2)中,经过i层gnn层的特征向量hi的更新公式如下:
79、hi=hi-1+a·relu(wgnnhi-1)
80、其中,i为第i个gnn层,relu(rectified linear unit)是一个非线性激活函数;wgnn为gnn层的权重矩阵,a是特征向量相应的邻居矩阵;
81、在每个gnn层中,输出为所有特征向量的在n个特征维度的每个相同维度上的均值,计算方式如下:
82、
83、其中表示第i个gnn层中特征向量的第k个原子的数值表示,n是维度特征数,hi表示在第i个gnn层的特征向量。
84、优选地,步骤(8)包括以下子步骤:
85、(8-1)将步骤(2)得到的抗癌肽序列训练集的数值编码向量输入到抗癌肽生成模型中生成模块的生成器的嵌入层,以得到嵌入矩阵x={x1,...,xn},其中n表示多肽序列长度,x1表示在一条多肽序列里第一个氨基酸的嵌入向量,xn表示在一条多肽序列里第n个氨基酸的嵌入向量;
86、(8-2)将步骤(8-1)得到的嵌入矩阵x={x1,...,xn}输入到生成模块中生成器的基于gru的rnn层,以得到n个隐藏向量{h1,...,hn};
87、(8-3)将步骤(8-2)得到的n个隐藏向量{h1,...,hn}输入到生成模块中生成器的softmax层,以得到生成多肽序列,其包括n个时间步的生成器输出令牌;
88、(8-4)对步骤(8-3)得到的生成多肽序列与步骤(2)得到的抗癌肽序列训练集的交叉熵损失对生成模块的生成器进行梯度更新,并对更新后的生成器进行迭代训练,直到损失函数最小为止,从而得到预训练好的生成模块的生成器gθ;
89、(8-5)利用步骤(8-4)得到的生成模块的生成器采样到固定长度的多肽序列;
90、(8-6)将步骤(2)得到的抗癌肽序列训练集和步骤(8-5)得到的多肽序列依次输入到生成模块中判别器的嵌入层、卷积层、relu层、池化层、highway层和丢弃层,以得到特征矩阵;
91、(8-7)将步骤(8-6)得到的特征矩阵输入到生成模块中判别器的softmax层,以得到判别分数;
92、(8-8)利用步骤(8-7)得到的判别分数的交叉熵损失对生成模块的判别器进行梯度更新,并对更新后的判别器进行迭代训练,直到损失函数最小为止,从而得到预训练好的生成模块的判别器d;
93、(8-9)将步骤(8-4)得到的生成模块的生成器gθ同时作为roll-out生成器gβ使用;
94、(8-10)利用步骤(8-4)得到的生成模块的生成器gθ生成多肽序列段,利用步骤(8-9)得到的roll-out生成器gβ对生成的多肽序列段生成后续的令牌,以得到完整的多肽序列,并将生成的完整多肽序列输入到步骤(8-8)得到的生成模块的判别器d,以得到生成的完整多肽序列的序列奖励;
95、(8-11)针对步骤(8-10)得到的完整的多肽序列而言,通过上述步骤(4)和(5)的计算方法得到该多肽序列对应的分子指纹,然后将分子指纹输入到步骤(7)得到的预测模块,以得到生成的完整多肽序列数据的结构奖励;
96、(8-12)将步骤(8-10)得到的完整多肽序列的序列奖励和步骤(8-11)得到的完整多肽序列的结构奖励进行线性组合,以获取线性组合奖励,通过最大化期望线性组合奖励对步骤(8-4)得到的生成器gθ的参数进行梯度更新,以得到更新后的生成模块的生成器gθ。
97、(8-13)利用步骤(8-12)更新后的生成模型的生成器和步骤(8-8)更新后的生成模型的判别器重复执行执行步骤(8-5)至步骤(8-12),直到生成模块收敛为止,从而得到训练好的抗癌肽生成模型。
98、优选地,步骤(8-12)中,
99、线性组合奖励的计算方式如下:
100、
101、其中,st是gθ生成的第t个令牌,s1:t-1是gθ生成的第t-1个多肽序列段,是完整多肽序列的序列奖励,是完整多肽序列的分子指纹的结构奖励,fp(s1:t-1,st)表示完整多肽序列的分子指纹形式,μ是小于1的混合常数;
102、利用梯度上升,gθ目标函数的梯度和梯度更新计算方式如下:
103、
104、θ←θ+αj(θ)
105、其中,θ是生成器gθ的参数,t是完整多肽序列的长度,α是学习率,st是gθ生成的第t个令牌,s1:t-1是gθ生成的第t-1个多肽序列段,gθ(st|s1:t-1)生成一个多肽序列段,是线性组合奖励,为期望,可以近似为蒙特卡洛采样方法,表示对生成器gθ求导,是目标函数梯度。
106、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
107、1、由于本发明采用了步骤(3),其利用深度学习中的序列生成对抗网络和图神经网络,所以不需要人工设计特征处理器,模型可以自动提取数据特征和更新;此外其利用一般多肽数据来预训练抗癌肽生成模型的生成模块,因此可以学习到一般多肽数据的序列性质;
108、2、由于本发明采用了步骤(8),其利用抗癌肽生成模型的生成模块中的判别器和预测模块提供的对抗癌肽生成模型生成多肽的线性组合奖励作为反馈信息,使得生成模块在更加丰富和多样化的信息中学习到多肽的抗癌性质与其他药物相关性质。
109、3、由于本发明采用了步骤(4)到步骤(8),其利用抗癌肽生成模型的预测模块学习抗癌肽的结构信息,并在之后给抗癌肽生成模型提供反馈信息,使得抗癌肽生成模型可以利用强化学习同时将抗癌肽的序列信息和结构信息融入训练中,学习抗癌性质的多肽序列和多肽结构的抗癌肽序列的生成。
- 还没有人留言评论。精彩留言会获得点赞!