一种集成多种强学习器的OHSS预测方法
本发明涉及机器学习医疗健康领域,具体是涉及一种集成多种强学习器的ohss预测方法。
背景技术:
1、卵巢过度刺激综合征(ovarian hyperstimulation syndrome,ohss)是辅助生殖技术中使用促排卵药物后产生过度反应引起的一种医源性疾病,为体外受孕辅助生育的主要并发症之一。目前其发病机制尚未完全明确,临床上主要以预防为主,治疗为辅。ohss严重时可出现凝血功能障碍、肾功能损害、急性呼吸窘迫综合征(ards),多器官功能障碍综合征(mods)、甚至危及患者生命,造成重大的经济和精神负担,因此及早预估病人是否会发生ohss以及判断病人发生ohss的严重程度,从而及时设计或调整对应的治疗方案,尽可能降低病人发生ohss的概率,显得尤为重要。
2、目前医生可凭借经验,可以预测一部分ohss高风险的患者,密切随访,进而针对性的选择更安全的用药/辅生治疗方案。还可以通过超声检查、全血细胞、盆腹腔积液分析等检测手段,可以在ohss发生之后较准确的判断发病。但依旧缺乏能够更早更精确的ohss风险预判方法来对ohss患者进行干预。
3、国内外已有部分报道针对ohss的预测方法,但由于患者自身情况复杂多变,治疗方案无统一标准,预测误差较大,不能有效的辅助临床医生尽快识别、提前预防和诊疗ohss。
技术实现思路
1、针对上述问题,本发明提出了一种集成多种强学习器的ohss预测方法,旨在早期识别有ohss高危倾向的患者并采取干预措施,完善超促排卵治疗过程中人为临床诊疗经验不足、预判能力有限的局限性,降低ohss对于辅助生殖患者的危害性。
2、为了实现上述目的,本发明提供一种集成多种强学习器的ohss预测方法,包括以下步骤:
3、s1、收集患者临床样本数据并进行数据清洗和预处理;
4、s2、将预处理好的数据划分为训练数据和测试数据,并根据数据分布对训练数据进一步划分为子训练数据集群;
5、s3、根据所述子训练数据集群构建基础预测模型;
6、s4、利用所述子训练数据集群对所述基础预测模型进行训练并记录训练权重;
7、s5、对所述训练权重进行缩放,构建预测模型,模型输出结果为患者患有ohss的预测概率。
8、优选的,所述步骤s1具体包括以下步骤:
9、s11、收集患者临床数据,所述患者临床数据包括患者基础身体信息、基础激素信息、历史用药、现阶段用药及体内相关激素水平;
10、s12、对收集的患者临床数据进行数据清洗,去除乱码字符,修改格式错乱、超出正常指标范围等异常值,最后使用缺失值填充算法填充缺失值;
11、s13、对清洗之后的数据进行预处理,使用独热编码对类别数据进行编码,然后对整个数据集进行离群点检测筛掉部分异常值,最后对整体数据进行统一标准化处理。
12、优选的,所述缺失值填充算法为通过聚类算法填充相关缺失的值,具体为在数据集的多维特征空间中寻找离缺失值最近的点,用该点的数据来填充缺失值;所述独热编码为一种针对类别数据而设计的编码方式,即将分类值映射到整数值,分类标签数即为编码后新增加的特征数,若样本数据属于该特征,则标记为1,其它标记为0;所述离群点检测为局部异常因子算法-local outlier factor(lof),一种典型的基于密度的高精度离群点检测方法,通过给每个数据点都分配一个依赖于邻域密度的离群因子,进而判断该数据点是否为离群点,非离群点对象周围的密度与其邻域周围的密度类似,而离群点对象周围的密度显著不同于其邻域周围的密度;所述标准化处理为z-score标准化方法,经过z-score标准化后,数据将符合标准正态分布,具体为x为样本值,为样本均值,sd为样本标准差。
13、优选的,所述步骤s2中的数据划分具体为从整个样本数据划分一部分出来作为最后的测试样本,其余数据作为训练数据s1,训练数据按照阳性y1和非阳性y2划分为两个集合,根据两个集合数量差异以及自身数量,对自身集合再次抽样:即把阳性和非阳性各自再平均划分成更小的子数据样本,最终使得阳性集合里面的任意一个子样本数据集{yi|yi∈y1,i∈n}和非阳性集合里面的任意一个子样本数据集{yj|yj∈y2,j∈n}在数量上的近似比为1:1,使阳性集合里面的任意一个子样本数据集和非阳性里面的子样本数据集依次组合,组合成为一个新的包含阳性和非阳性近似比为1:1的小数据集si=yi+yj,从而形成一个总的数据集群s={s1,s2,s3…,sn},n为数据集群子数据集个数,其中的任何一个子数据集在阳性和非阳性的近似比都为1:1。
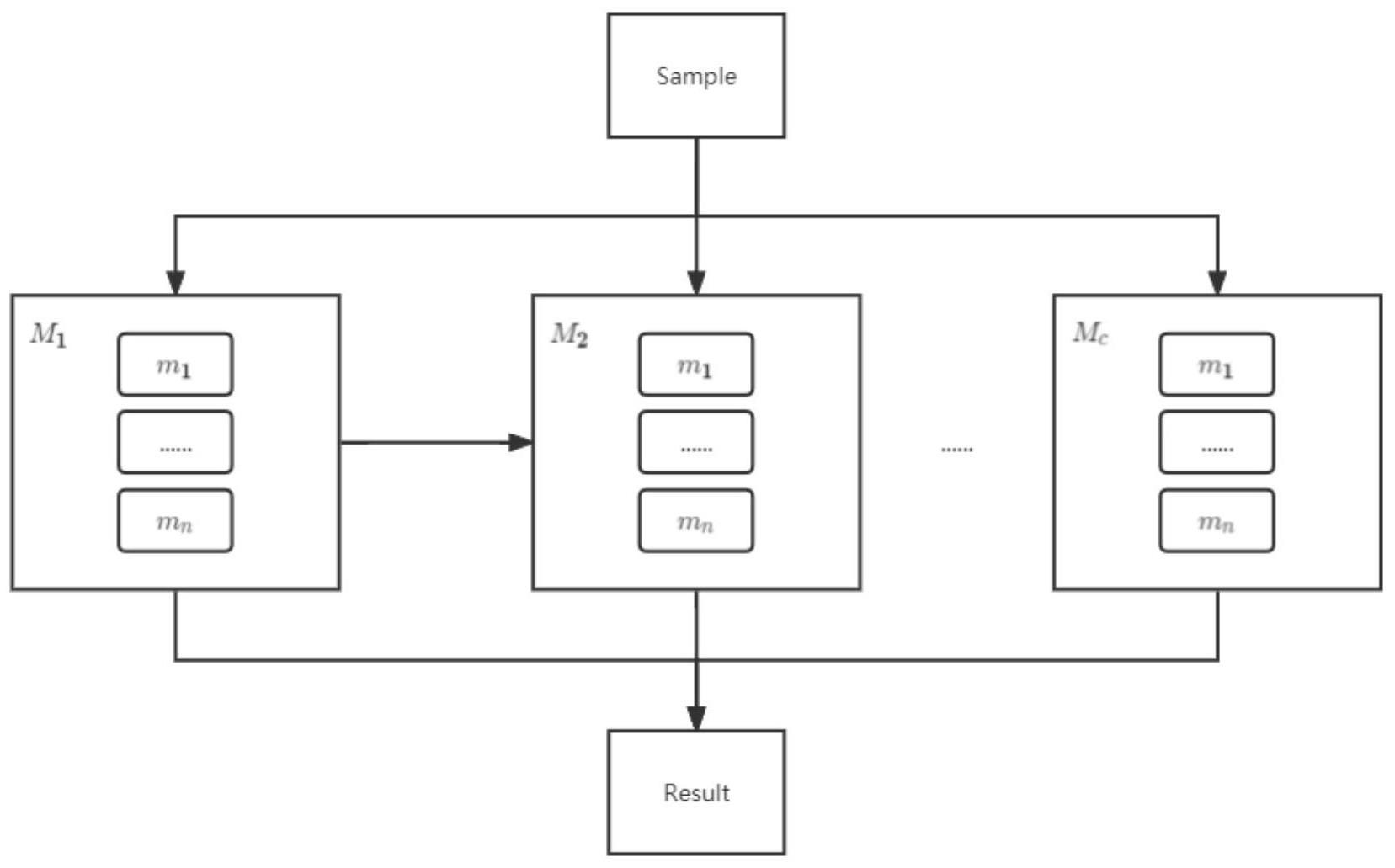
14、优选的,所述步骤s3中基础预测模型为集成多种强类型学习器,每种强类型学习器都会对应数据集群里面的每一个子样本数据集,因此一种类型的强学习器便会有n个模型,集成c种不同强学习器的c*n个模型得到基础预测模型,c为强学习器种类数,n为数据集群子数据个数。
15、优选的,所述强类型学习器包括多层感知机、朴素贝叶斯、梯度提升树。
16、优选的,所述多层感知机为一种基于神经网络的有分类算法,由多层神经元组成,每一层与它的上一层相连,同时每一层也与它的下一层相连,影响当前层的神经元,多层感知机遵循人类神经系统原理,学习并进行数据预测;所述朴素贝叶斯为一种基于贝叶斯定义和特征条件独立假设的分类算法,具体是通过考虑特征概率来预测分类,对于既定待分类样本,解出此样本出现的条件下各个类别出现的条件概率,最大概率的类别即被认为是待分类样本的预测类别;所述梯度提升树为一种基于多个弱学习器的集成式分类算法,通过相关策略将若干个弱学习器组合成强学习器来完成同一检测任务。
17、优选的,所述步骤s4具体包括以下步骤:
18、s41、对每种强学习器都依次训练数据集群s中的所有子样本数据集si,每一个子样本数据集si便能训练得出一个子模型mci以及训练权重wci,c为强学习器种类数,i为对应的子样本数据集si,训练权重为该算法模型经过训练后对该子训练数据集进行测试得出的准确率,最终模型m={{m11,m12,……,m1n},{m21,m22,……,m2n},……,{mc1,mc2,……,mcn}},n为数据集群子数据个数;
19、s42、在每个子数据集的训练过程中都使用遗传算法对每个子模型mci进行超参数搜索。
20、优选的,所述遗传算法为一种模拟自然界生物进化、淘汰机制而发展起来的一种随机搜索和优化方法,遗传算法能在搜索过程中自动获取和积累有关搜索空间的参数,并通过迭代进化求得最优解。
21、优选的,所述步骤s5具体包括以下步骤:
22、s51、所述步骤s41中的每一个训练权重wci都将经过softmax进行缩放,其中xi为第i个节点的输出值,c为输出节点的个数,即分类的类别个数,通过softmax函数将多分类的输出值转换为范围在[0,1]和为1的概率分布;
23、s52、即w={{w11,,w12,……,w1n},{w21,
24、w22,……,w2n},……,{wc1,wc2,……,wcn}},c为强学习器种类数,n为数据集群子数据个数,当进行预测时,预测样本输入mj得到n个预测概率,n个预测概率分别与对应强学习器下的n个权重wj相乘累加得到pj,即因此最终ohss预测输出概率
25、与现有技术相比,本发明的有益效果是:
26、本发明提供的一种集成多种强学习器的ohss预测方法,基于多种机器学习算法,能够对患者自身情况复杂多变,治疗方案无统一标准,ohss预测误差较大等情况提供更为精准的预测,从而辅助临床医生更早的对高风险患者进行干预治疗。
- 还没有人留言评论。精彩留言会获得点赞!