可变剪切事件预测的机器学习模型的训练方法和预测方法及应用与流程
本发明涉及生物信息,更为具体地说,涉及一种用于可变剪切事件预测的机器学习模型的训练方法和可变剪切事件的预测方法及其应用。
背景技术:
1、可变剪切(alternative splicing)是一种后转录生物学过程,对细胞活动和疾病过程具有重要的且广泛的影响,研究表明人的基因组中有超过90-95%的多外显子基因存在可变剪切。可变剪切能够产生多种类型的mrna,因此一个基因就可以产生多种不同的蛋白,这个过程极大的增加了mrna和蛋白质的多样性。
2、可变剪切事件目前主要被分为5种主要的类型,包括:外显子跳跃(skippedexons,se),内含子滞留(retained introns,ri),5'端可变剪切(alternative 5'(donor)splice sites,a5ss),3'端可变剪切(alternative 3'(acceptor)splice sites,a3ss)以及互斥外显子跳跃(mutually exclusive exon,mxe)。
3、目前对二代的可变剪切预测的软件种类繁多,标准不一,各有优劣,而对三代可变剪切预测的软件并不多。有文献比较各软件检出的差异可变基因相似度很低,差异显著,且二三代各软件检测的准确性也并不明确。例如,有各种对可变剪切事件进行预测的软件的预测结果的相关性的比较显示,相同软件不同版本间的相似性较高能达到90%以上,但是不同软件的相似性较低,例如仅为45%。
4、虽然有多种软件可以对可变剪切事件的类型进行预测,但是,不同软件对不同类型的可变剪切事件各有优势,结果置信度有待提高。因此,期望提供一种结合各种软件对可变剪切事件的类型的预测结果的优化的可变剪切事件的预测方法。
技术实现思路
1、目前各种预测可变剪切事件的软件各有优劣,但是目前的可变剪切事件的预测方法普遍存在置信度较低的问题。本发明提供了一种用于可变剪切事件预测的机器学习模型的训练方法和可变剪切事件的预测方法,采用本发明的方法能够显著提高预测结果的置信度,可以达到更加准确的可变剪切事件的预测效果,能够为疾病研究和生长发育过程的研究奠定基础。
2、具体内容如下:
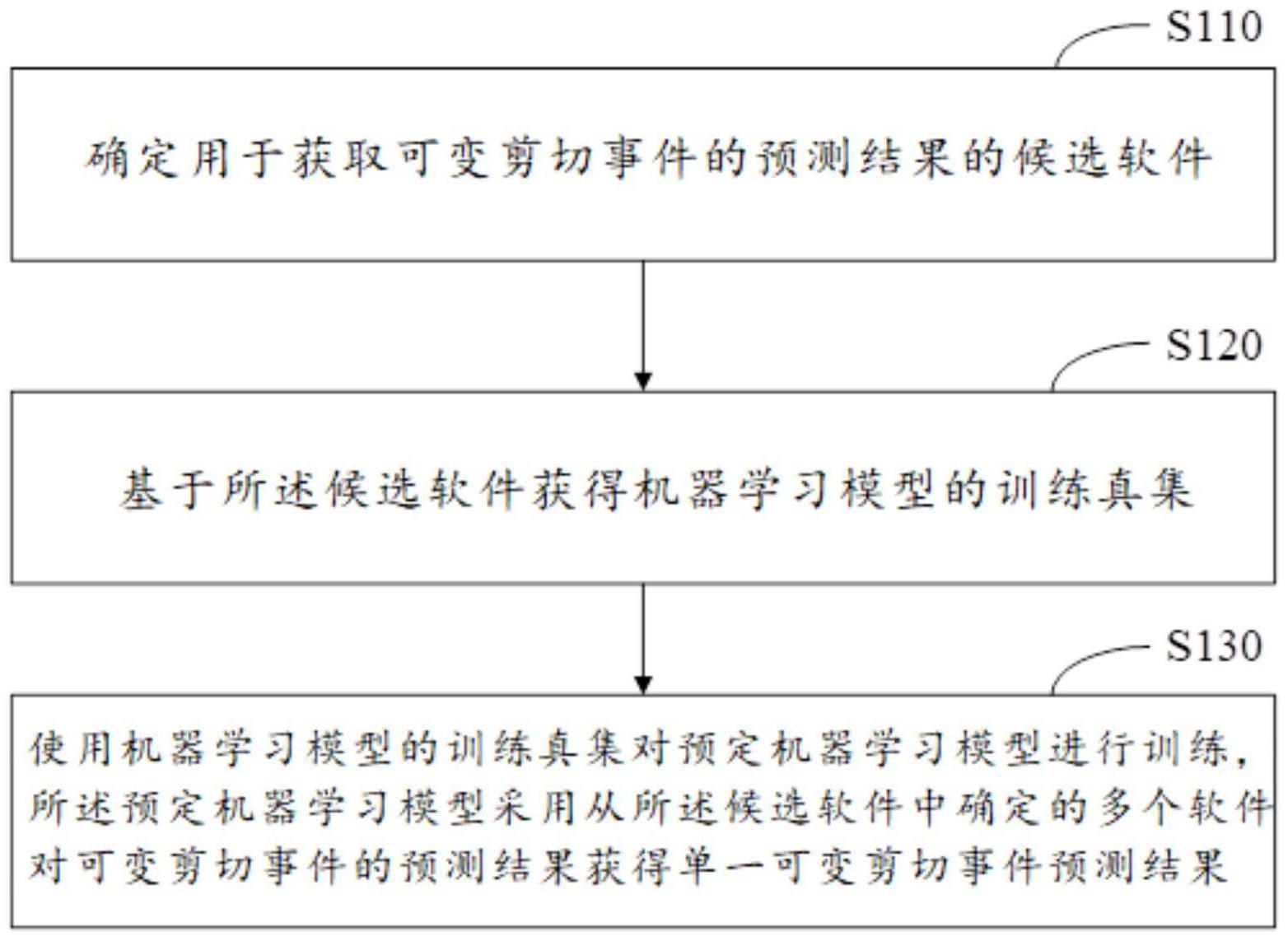
3、1.一种用于可变剪切事件预测的机器学习模型的训练方法,包括:
4、确定用于获取可变剪切事件的预测结果的候选软件;
5、基于所述候选软件获得机器学习模型的训练真集;以及
6、使用所述机器学习模型的训练真集对预定机器学习模型进行训练,所述预定机器学习模型采用从所述候选软件中确定的多个软件对可变剪切事件的预测结果获得单一可变剪切事件预测结果。
7、2.根据上述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述候选软件的确定标准包括以下的至少其中之一:
8、所述候选软件能够检测出可变剪切事件;
9、所述候选软件能够进行单样本可变剪切预测;和,
10、所述候选软件至少支持预定数目的类型的可变剪切事件。
11、3.根据上述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述多个软件为至少两个软件;优选地,所述多个软件为至少三个软件;更优选地,所述候选软件选自:asprofile、suppa、astalavista、rmats、tapis、ast、cufflinks、sqanti3、leafcutter、lr2rmats、sqanti、cash、majiq、ballgrown、dexseq。
12、4.根据上述的用于可变剪切事件预测的机器学习模型的训练方法,其中,基于所述候选软件获得机器学习模型的训练真集的方法包括:
13、在准备所述机器学习模型的训练数据时,基于所述候选软件确定所述训练数据的不同数据类型;
14、基于所述候选软件确定分别与所述不同数据类型对应的测序平台;
15、确定每个所述测序平台与所述每个候选软件的对应关系;以及,
16、确定所述候选软件支持的可变剪切事件的真实预测类型,并基于所述可变剪切事件的真实预测类型确定所述训练真集的类型预测标签;
17、优选地,所述不同数据类型包括二代测序数据类型ngs和三代测序数据类型tgs;
18、优选地,与所述不同数据类型对应的测序平台选自illumina、pb、ont、iontorrent、bgi/mgi中的至少一种;
19、优选地,基于所述可变剪切事件的真实预测类型确定所述训练真集的类型预测标签的方法包括:将所述可变剪切事件的真实预测类型se、ri、a5ss、a3ss和mxe确定为所述训练真集的三种类型预测标签se、ri和ae。
20、5.根据上述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述预定机器学习模型为线性回归模型h(x)=w(x1,x2,x3,...,xn)+b=w1x1+w2x2+w3x3+…+wnxn+b,所述线性回归模型具有权重向量w和偏置值b,且(x1,x2,x3,...,xn)表示所述候选软件中的多个软件对可变剪切事件的预测结果。
21、6.根据上述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述预测方法还包括确定所述线性回归模型的训练超参数,所述训练超参数包括迭代周期数目、学习率和批次大小中的一种或多种;和/或,
22、在所述线性回归模型的训练过程中,在每次迭代时通过k折交叉验证的方式来将所述训练真集划分为验证集和测试集。
23、7.根据上述的可变剪切事件的预测方法,其中,所述预测方法还包括通过预定的评估指标来确定所述机器学习模型的性能,其中,所述评估指标包括准确度、召回度和f1分数中的一种或多种;和/或,
24、所述预测方法还包括基于训练数据计算训练值,并基于训练值与真实值之间的损失函数来通过梯度下降的方式迭代地更新模型参数。
25、8.根据上述的用于可变剪切事件预测的机器学习模型的训练方法得到的机器学习模型。
26、9.一种可变剪切事件的预测方法,包括:
27、获取待预测可变剪切事件的样本数据;以及
28、使用上述的用于可变剪切事件预测的机器学习模型的训练方法所训练的机器学习模型或上述的机器学习模型,获得所述样本数据的可变剪切事件预测结果。
29、10.上述的用于可变剪切事件预测的机器学习模型的训练方法、上述的机器学习模型或上述的可变剪切事件的预测方法在生物信息技术中的应用。
技术特征:
1.一种用于可变剪切事件预测的机器学习模型的训练方法,包括:
2.根据权利要求1所述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述候选软件的确定标准包括以下的至少其中之一:
3.根据权利要求1所述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述多个软件为至少两个软件;优选地,所述多个软件为至少三个软件;更优选地,所述候选软件选自:asprofile、suppa、astalavista、rmats、tapis、ast、cufflinks、sqanti3、leafcutter、lr2rmats、sqanti、cash、majiq、ballgrown、dexseq。
4.根据权利要求1所述的用于可变剪切事件预测的机器学习模型的训练方法,其中,基于所述候选软件获得机器学习模型的训练真集的方法包括:
5.根据权利要求1-4中任一项所述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述预定机器学习模型为线性回归模型h(x)=w(x1,x2,x3,...,xn)+b=w1x1+w2x2+w3x3+…+wnxn+b,所述线性回归模型具有权重向量w和偏置值b,且(x1,x2,x3,...,xn)表示所述候选软件中的多个软件对可变剪切事件的预测结果。
6.根据权利要求5所述的用于可变剪切事件预测的机器学习模型的训练方法,其中,所述预测方法还包括确定所述线性回归模型的训练超参数,所述训练超参数包括迭代周期数目、学习率和批次大小中的一种或多种;和/或,
7.根据权利要求5所述的可变剪切事件的预测方法,其中,所述预测方法还包括通过预定的评估指标来确定所述机器学习模型的性能,其中,所述评估指标包括准确度、召回度和f1分数中的一种或多种;和/或,
8.根据权利要求1-7中任一项所述的用于可变剪切事件预测的机器学习模型的训练方法得到的机器学习模型。
9.一种可变剪切事件的预测方法,包括:
10.权利要求1-7中任一项所述的用于可变剪切事件预测的机器学习模型的训练方法、权利要求8所述的机器学习模型或权利要求9所述的可变剪切事件的预测方法在生物信息技术中的应用。
技术总结
本发明涉及一种用于可变剪切事件预测的机器学习模型的训练方法和可变剪切事件的预测方法及应用。该用于可变剪切事件预测的机器学习模型的训练方法包括:确定用于获取可变剪切事件的预测结果的候选软件;基于所述候选软件获得机器学习模型的训练真集;以及,使用所述机器学习模型的训练真集对预定机器学习模型进行训练,所述预定机器学习模型采用从所述候选软件中确定的多个软件对可变剪切事件的预测结果获得单一可变剪切事件预测结果。本发明的方法能够显著提高预测结果的置信度,可以达到更加准确的可变剪切事件的预测效果。
技术研发人员:涂成芳,刘涛,李志民,李华云,韩少怀,任雪,权慧,王娟
受保护的技术使用者:浙江安诺优达生物科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!