一种基于预训练模型的微生物遗传序列表型预测方法
本发明涉及一种计算机处理微生物遗传序列,具体涉及一种基于预训练模型的微生物遗传序列表型预测方法。
背景技术:
1、微生物的遗传序列记录了微生物的生长发育的信息,其通过转录和翻译后合成蛋白质来控制生物的生长与发育。随着高通量测序技术的不断发展,微生物遗传学研究已经成为一门热门的研究领域。微生物遗传序列的分析可以帮助我们深入了解微生物群落的多样性、组成以及在不同环境中的功能。然而,微生物遗传序列因其具有高度复杂性、多样性和多变性,导致解读微生物遗传序列对于研究人员来说并不是一项容易的工作。
2、目前,微生物遗传序列预测方法主要有两种:基于组装的方法和基于序列比对的方法。然而,这两种方法都存在一些缺点。基于组装的方法需要大量的计算资源和时间,且结果不可避免地受到组装算法的影响。基于序列比对的方法需要对序列进行比对,这种方法适用于亲缘关系密切的序列,但对于差异较大的序列,比对的准确性会受到影响。
3、遗传序列是一种高度序列化的,有前后顺序的序列文本数据,这些特征与人类自然语言十分相似。预训练模型技术是近年来自然语言处理领域的重大突破之一,这种技术通过在大规模数据集上训练模型,可以使模型具有在新任务上表现优异的能力。目前,基于预训练模型的相关技术已经成功应用于自然语言处理、计算机视觉等领域。同样的,基于预训练模型的序列预测技术也可以应用到微生物遗传序列表型预测领域上来。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种基于预训练模型的微生物遗传序列表型预测方法,本发明提出的方法能够通过大量的微生物遗传序列信息训练一个大规模预训练模型,在预训练过程中模型能够从大量微生物遗传序列中学习遗传序列内隐含的特征,不需要进行序列组装和比对,在后续任务中,只需要采用少量数据对模型进行微调,就可以实现高精度的微生物遗传序列表型预测。
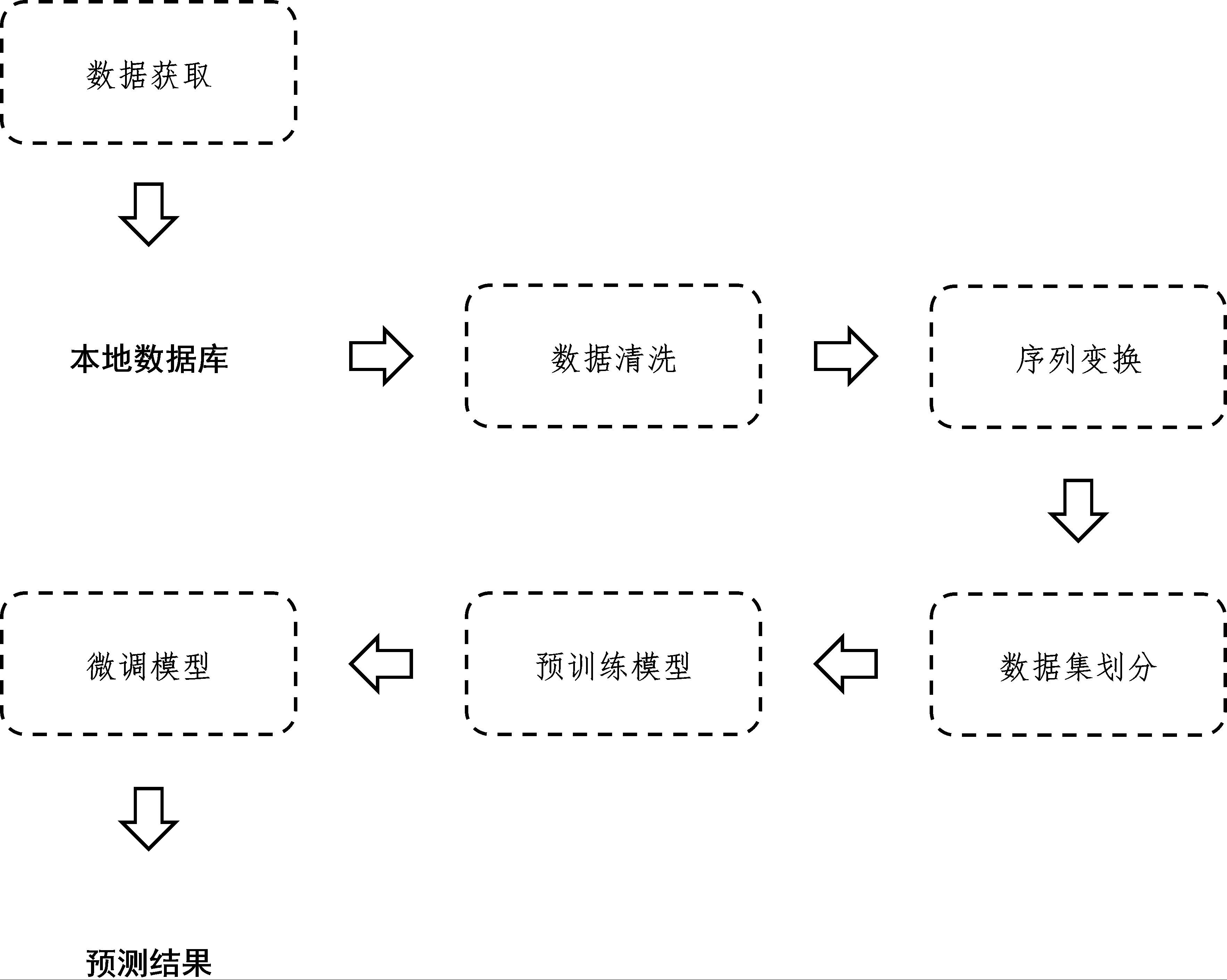
2、本发明克服其技术问题所采用的技术方案是:本发明提出的一种基于预训练模型的微生物遗传序列表型预测方法,包括以下步骤:s1,获取所需微生物遗传序列数据并对其进行存储,以及对存储的数据进行处理从而得到包括所有所需微生物遗传序列数据的数据库;s2,遍历数据库中的微生物遗传序列数据,并基于预设规则对数据库中的微生物遗传序列数据进行分析和预处理;s3,采用多碱基单元表示数据库中预处理后的微生物遗传序列;s4,基于多碱基单元构建分别用于预训练任务的预训练数据集和用于分类任务的分类数据集;s5,构建深度学习模型,并将预训练数据集向量化后输入至深度学习模型进行训练从而得到预训练模型;s6,调整预训练模型结构,将分类数据集向量化后输入至调整后的预训练模型进行训练从而得到预测模型;s7,将待预测微生物遗传序列输入至预测模型,从而得到待预测微生物遗传序列的表型的预测结果。
3、进一步的,所述对存储的数据进行处理从而得到包括所有所需微生物遗传序列数据的数据库,具体包括:s11、读取存储微生物遗传序列数据的fasta文件,将fasta文件中包括的全部微生物遗传序列信息按照预设格式存储到同一个表格中;s12、若同样的微生物遗传序列信息出现若干次,则仅保留一次微生物遗传序列信息,从而得到包括全部所需微生物遗传序列数据的数据库;s13、将数据库保存为csv格式的文件。
4、进一步的,所述基于预设规则对数据库中的微生物遗传序列数据进行分析和预处理,具体包括:s21、分析微生物遗传序列数据是否包括单个混合碱基n;s22、若任意一条微生物遗传序列数据包括单个混合碱基n,且单个混合碱基n的前后碱基都是正常碱基,则用碱基a、t、c、g中的任意一个随机替代混合碱基n;s23,若任意一条微生物遗传序列数据包括的连续混合碱基n的个数大于等于2,则在数据库中删除对应的连续混合碱基n。
5、进一步的,所述采用多碱基单元表示数据库中预处理后的微生物遗传序列,具体包括:s31,确定多碱基单元长度的上限值和下限值;s32,基于多碱基单元长度的上限值和下限值构建可变长的滑动窗口;s33,基于可变长的滑动窗口依次截取数据库中预处理后的微生物遗传序列数据的碱基片段,从而得到长度在上限值和下限值之间的多个碱基单元。
6、进一步的,所述深度学习模型的网络结构至少包括多层transformer编码器,每层编码器至少包括多头自注意力机制和前向神经网络。
7、进一步的,所述预训练数据集向量化后输入至深度学习模型进行训练从而得到预训练模型,具体包括:s51,将预训练数据集的所有多碱基单元进行独热码向量化;s52,将独热码向量化后的多碱基单元构建训练dna子序列;s53,将训练dna子序列输入至深度学习模型进行预训练任务,从而得到预训练模型。
8、进一步的,所述预训练任务包括掩码语言模型和下一句预测,其中,所述掩码语言模型具体包括:s531,对预训练数据集中的预训练训练集中的数据随机选择若干位置;s532,将若干位置对应的碱基替换为预设符号进行掩码;s533,通过深度学习模型预测被掩码的碱基。
9、进一步的,所述下一句预测包括通过深度学习模型随机选择预训练数据集中的预训练训练集的两个dna序列,并判断两个dna序列是否是相邻的两个句子,从而得到两个dna序列的关系。
10、进一步的,所述深度学习模型还包括卷积层,所述子序列输入至卷积层学习局部的dna子序列的序列特征,再经过多头自注意力机制和前向神经网络进行编码学习全局dna子序列的序列特征。
11、进一步的,所述调整预训练模型结构,将分类数据集向量化后输入至调整后的预训练模型进行训练从而得到预测模型,具体包括:s61,将分类数据集的所有多碱基单元进行独热码向量化并构建分类子序列;s62,调整预训练模型网络结构;s63,将分类子序列输入至调整后的预训练模型中,并基于交叉熵损失函数进行训练,从而得到预测模型。
12、本发明的有益效果是:
13、1、直接对微生物遗传序列进行编码和表示,从而避免了序列组装和比对过程中可能产生的错误和偏差。
14、2、提出的预训练模型可以捕捉微生物遗传序列的特征,如基因组成、编码方式等,从而可以快速准确地预测微生物遗传序列的表型。
15、3、预训练模型可以通过大规模的训练数据来学习微生物遗传序列的特征,从而提高了模型的适应性和可迁移性,因此可以应用于不同的微生物群体和不同的预测任务,从而更好地满足实际的预测需求。
16、4、对单个混合碱基n的微生物遗传序列进行数据调整,对包括连续混合碱基n的微生物遗传序列进行数据清洗,从而使训练模型的数据集更加准确。
17、5、采用多碱基单元表示微生物遗传序列,选择合适的多碱基单元长度的取值,从而使本地数据库中全部病毒基因用多碱基单元表示。
18、6、根据训练模型数据长度的不同以及训练模型使用的深度学习网络中隐藏层结点数量不同,灵活地调整参数并训练不同的模型。
19、7、通过预训练得到通用的训练模型,针对更专业的细分预测的对训练模型进行微调训练。使用微调训练后的模型进行分型预测,准确度更高。
- 还没有人留言评论。精彩留言会获得点赞!