核苷酸测序数据的检测方法、模型训练方法及装置
本公开涉及大数据以及液体活检分析,尤其涉及核苷酸测序数据的检测方法模型的训练方法及装置。
背景技术:
1、目前癌症统计数据显示,癌症发病率和死亡率增长迅速。尽管在癌症治疗和预防方面已经取得了一些进展,但仍面临着癌症患者数量增加、治疗成本上升等挑战。癌症的检出阶段是最重要的生存预测指标之一。与原发性疾病患者相比,晚期患者的5年生存率将会大幅下降。以全球最常见的癌症肺癌为例,其局部、区域和远处转移阶段的5年生存率分别为59%、32%、6%。因此,在癌症更容易治愈的早期阶段识别患者对于癌症的总体存活率至关重要。
2、目前的筛查方式仅对一小部分癌症有效,例如推荐使用低剂量ct,结直肠镜检查,乳腺x光检查和宫颈细胞学联合人乳头状瘤病毒检测用于肺癌,结直肠癌,乳腺癌和宫颈癌的筛查。但是这些方法由于灵敏度和特异性不理想、高侵入性和依从性差而导致临床的适用性受到了很大的限制。更重要的是,还有很大比例的恶性肿瘤例如胰腺导管腺癌,卵巢癌和脑胶质瘤等没有推荐的筛查方法,导致大多数患者被诊断为晚期肿瘤,预后较差。因此,开发一个简单,准确和无创的癌症早期检测方法是至关重要的。
技术实现思路
1、鉴于上述问题,本公开提供了一种核苷酸测序数据的检测方法、模型训练方法及装置。
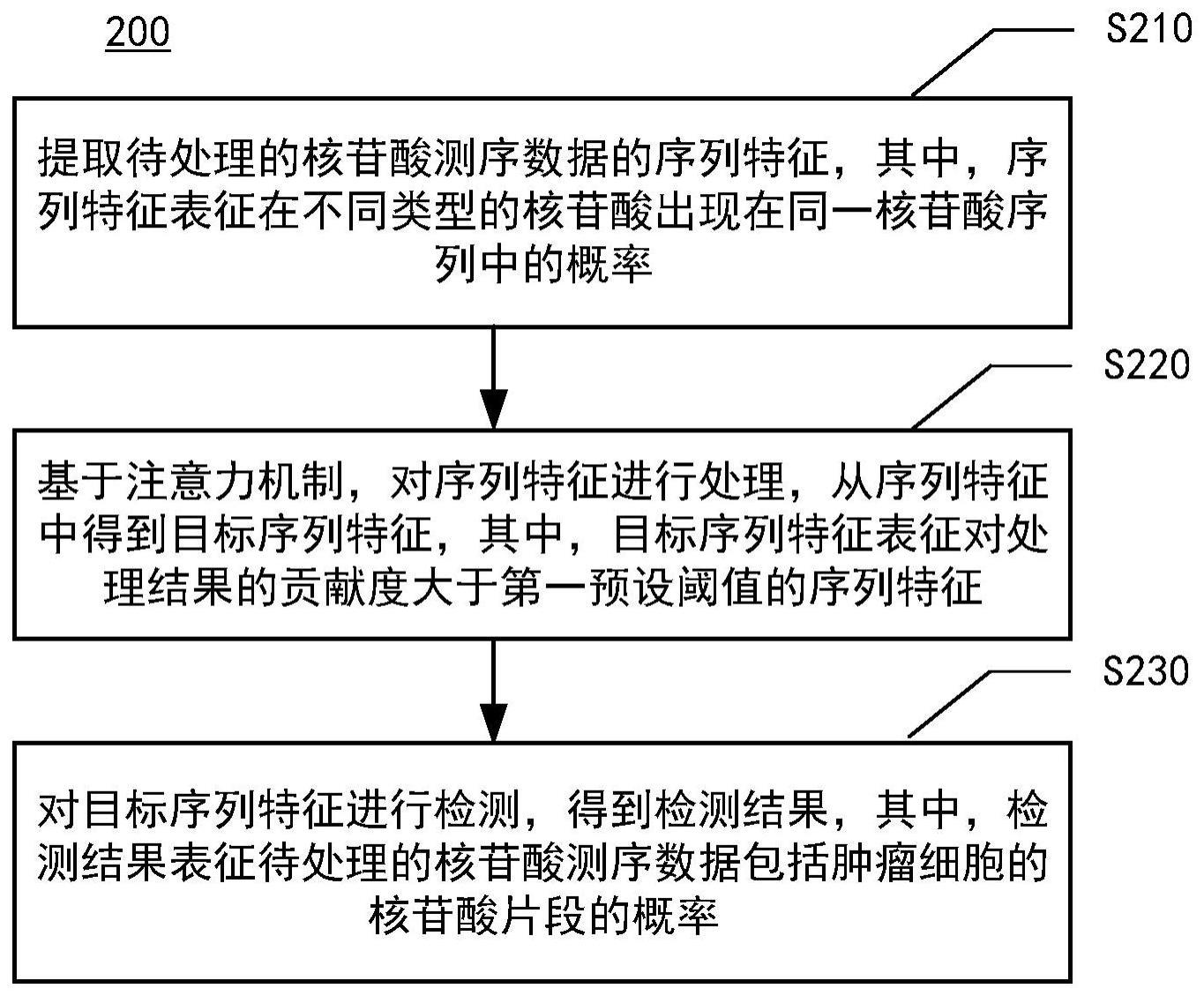
2、根据本公开的第一个方面,提供了一种核苷酸测序数据的检测方法,包括:
3、提取待处理的核苷酸测序数据的序列特征,其中,序列特征表征在不同类型的核苷酸出现在同一核苷酸序列中的概率;
4、基于注意力机制,对序列特征进行处理,从序列特征中得到目标序列特征,其中,目标序列特征表征对处理结果的贡献度大于第一预设阈值的序列特征;以及
5、对目标序列特征进行检测,得到检测结果,其中,检测结果表征待处理的核苷酸测序数据包括肿瘤细胞的核苷酸片段的概率。
6、根据本公开的实施例,待处理的核苷酸测序数据包括多个核苷酸片段,提取待处理的核苷酸测序数据的序列特征,包括:
7、根据多个核苷酸片段的质量分数和多个核苷酸片段的类型,从多个核苷酸片段中得到目标核苷酸片段;以及
8、对目标核苷酸片段进行处理,得到序列特征。
9、根据本公开的实施例,目标核苷酸片段包括m个,其中,m为大于1的整数;对目标核苷酸片段进行处理,得到序列特征,包括:
10、对第1~m个目标核苷酸片段进行处理,得到第m+1个目标核苷酸片段的类型分布概率,其中,m为大于1且小于等于m一1的整数;
11、在确定m小于m一1的情况下,返回执行对第1~m个目标核苷酸片段的处理操作,并递增m;以及
12、在确定m等于m-1的情况下,生成序列特征。
13、根据本公开的实施例,基于注意力机制,对序列特征进行处理,从序列特征中得到目标序列特征,包括:
14、对序列特征进行编码,得到编码特征;
15、基于自注意力机制对编码特征进行处理,得到序列特征对检测结果的贡献度;
16、根据贡献度,从编码特征得到目标编码特征;以及
17、对目标编码特征进行解码处理,得到目标序列特征。
18、根据本公开的实施例,对目标序列特征进行检测,得到检测结果,包括:
19、对目标序列特征进行检测,得到待处理的核苷酸测序数据包括肿瘤细胞的核苷酸片段的概率;以及
20、在确定概率大于第二预设阈值的情况下,确定检测结果为待处理的核苷酸测序数据包括肿瘤细胞的核苷酸片段。
21、本公开的第二方面提供了一种深度学习模型的训练方法,包括:
22、提取样本核苷酸测序数据的样本序列特征,其中,样本序列特征表征在不同类型的核苷酸出现在同一核苷酸序列中的概率;
23、基于注意力机制,对样本序列特征进行处理,从样本序列特征中得到目标样本序列特征,其中,目标样本序列特征表征对检测结果的贡献度大于第一预设阈值的样本序列特征;
24、对目标样本序列特征进行检测,得到样本检测结果,其中,样本检测结果表征样本核苷酸测序数据包括肿瘤细胞的核苷酸片段的概率;
25、基于第一目标损失函数,根据样本检测结果和样本标签得到第一损失值;以及
26、基于第一损失值调整深度学习模型的模型参数,得到经训练的深度学习模型。
27、根据本公开的实施例,样本核苷酸测序数据包括多个样本核苷酸片段,提取样本核苷酸测序数据的样本序列特征,包括:
28、根据多个样本核苷酸片段的质量分数和多个样本核苷酸片段的类型,从多个样本核苷酸片段中得到目标样本核苷酸片段;以及
29、利用预训练模型对目标样本核苷酸片段进行处理,得到样本序列特征。
30、根据本公开的实施例,目标样本核苷酸片段包括n个,其中,n为大于1的整数;预训练模型的训练方法包括:
31、在目标样本核苷酸片段中嵌入核苷酸类型信息和核苷酸位置信息;
32、对第1~n个目标核苷酸片段进行处理,得到第n+1个目标核苷酸片段的类型分布概率,其中,n为大于1且小于等于n-1的整数;
33、在确定n小于n-1的情况下,返回执行对第1~n个目标核苷酸片段的处理操作,并递增n;
34、在确定n等于n-1的情况下,生成样本序列特征;
35、基于第二目标损失函数,根据样本序列特征和目标样本核苷酸片段的核苷酸类型标签和核苷酸位置标签,得到第二损失值;以及
36、基于第二损失值调整初始模型的模型参数,得到经训练的预训练模型。
37、本公开的第三方面提供了一种核苷酸测序数据的检测装置,包括:
38、第一提取模块,用于提取待处理的核苷酸测序数据的序列特征,其中,序列特征表征在不同类型的核苷酸出现在同一核苷酸序列中的概率;
39、第一注意力模块,用于基于注意力机制,对序列特征进行处理,从序列特征中得到目标序列特征,其中,目标序列特征表征对检测结果的贡献度大于第一预设阈值的序列特征;以及
40、第一检测模块,用于对目标序列特征进行检测,得到检测结果,其中,检测结果表征待处理的核苷酸测序数据包括肿瘤细胞的核苷酸片段的概率。
41、本公开的第四方面提供了一种深度学习模型的训练装置,包括:
42、第二提取模块,用于提取样本核苷酸测序数据的样本序列特征,其中,样本序列特征表征在不同类型的核苷酸出现在同一核苷酸序列中的概率;
43、第二注意力模块,用于基于注意力机制,对样本序列特征进行处理,从样本序列特征中得到目标样本序列特征,其中,目标样本序列特征表征对检测结果的贡献度大于第一预设阈值的样本序列特征;以及
44、第二检测模块,用于对目标样本序列特征进行检测,得到样本检测结果,其中,样本检测结果表征样本核苷酸测序数据包括肿瘤细胞的核苷酸片段的概率;
45、损失模块,用于基于第一目标损失函数,根据样本检测结果和样本标签得到第一损失值;以及
46、调整模块,用于基于第一损失值调整深度学习模型的模型参数,得到经训练的深度学习模型。
47、本公开的第五方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述核苷酸测序数据的检测方法和深度学习模型的训练方法。
48、本公开的第六方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述核苷酸测序数据的检测方法和深度学习模型的训练方法。
49、本公开的第七方面还提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述核苷酸测序数据的检测方法和深度学习模型的训练方法。
50、根据本公开的实施例,通过提取待处理的核苷酸测序数据的序列特征;基于注意力机制,筛选出对肿瘤细胞检测影响较大的片段;再对特征片段进行检测,得到待处理的核苷酸测序数据中包括肿瘤细胞的核苷酸片段的概率。直接以待处理的核苷酸测序数据作为研究对象,避免了碱基转换和序列比对等一系列生物信息学处理,从而降低了下游数据分析负担,能够更为准确、快速地得到检测结果,为癌症早期诊断提供新的方向。并且待处理的核苷酸测序数据作为一种新的液体检材,其获取较为便捷,在无创肿瘤诊断领域具有巨大的潜力。
- 还没有人留言评论。精彩留言会获得点赞!