一种针对地聚物混凝土强度进行预测方法与流程
:本发明涉及混凝土力学性能判断领域,尤其涉及一种地聚物混凝土强度预测方法。
背景技术
0、
背景技术:
1、地聚物混凝土的抗压强度(cs)是指示混凝土力学性能的重要指标,是在其生产和使用过程中需要准确测量的重要参数。以粉煤灰-矿渣基地聚物混凝土为例,其抗压强度受到了包括原料种类、碱激活剂种类和含量,以及混合材料的液固比等多种参数的影响。地聚物混凝土的抗压强度通常是对经标准养护后的混凝土试件进行压力试验来获取测量数据,这种通过试验获取数据的方法涉及试件制作、养护以及压力试验等步骤,等待周期长,且需投入更多的人力、物力和财力,效率较低。因此,找到一种基于深度学习算法的地聚物混凝土强度预测方法来替代传统的试验方法,能够实现降本增效的目的,对保障地聚物混凝土的施工进度和质量具有非常重要的理论价值和工程经济效应。
2、近年来,基于人工智能方法的混凝土配合比设计和性能预测应用越来越受到重视。一些学者利用支持向量机(svm)、人工神经网络(ann)和极限学习机(elm)等机器学习(ml)方法来预测地聚物混凝土的28天强度。然而,对于粉煤灰-矿渣基地聚物混凝土抗压强度的预测,以上机器学习方法预测结果的准确性受模型输入变量选择和模型元参数设置影响显著。并且,传统的机器学习模型架构简单、有限,应用范围、效果较深度学习有较大的局限。
3、深度学习(dl)方法通过特征提取和模式识别的结合,能够创建精细的学习模型,通过在更高级别的学习来更有效地管理非结构化数据,这使得dl模型能够执行高精度的复杂任务。因此,它们能够比传统的ml模型更好地破译混凝土原料的混合参数和最终力学性能之间的复杂关系。在众多深度学习方法中,基于卷积神经网络(cnn)的方法广泛运用于混凝土材料研究领域。结果表明,优化cnn模型的元参数至关重要。
4、为了保障cnn模型对地聚物混凝土抗压强度预测结果的准确性,需要对模型元参数进行优化。元参数优化的目标是通过减小均方根误差和最大化模型预测值与真实值之间的决定系数来找到全局最优解。蝙蝠算法(ba)已经成功应用于许多优化问题,具有快速收敛的优点,可以在cnn模型训练过程中优化网络模型的元参数,但相关研究证明,ba与其他群体智能算法一样存在寻优精度不足、效率低、容易陷入局部最优等缺点。
技术实现思路
0、
技术实现要素:
1、针对现有技术存在的技术问题,本发明提出了一种地聚物混凝土强度预测方法;该方法通过改进的蝙蝠算法,在蝙蝠速度迭代更新公式中引入了新的自适应惯性权重系数和随机扰动,提高了的局部搜索能力和全局搜索能力;进而能更准确地提取和识别地聚物混凝土多种参数与其强度之间的非线性特征,提高地聚物混凝土抗压强度预测结果的准确性;同时,本发明提出改进型蝙蝠算法能够解决传统蝙蝠算法面对高度非线性问题存在失效风险的问题。
2、为了解决现有技术问题,本发明采用如下技术方案:
3、一种针对地聚物混凝土强度预测方法,所述方法包括以下步骤:
4、步骤1:采集地聚物混凝土强度实验训练样本数据对卷积神经网络进行训练,构建地聚物混凝土强度预测初始模型;
5、步骤2:通过蝙蝠算法对所述地聚物混凝土强度预测初始模型中的初始元参数进行优化获得元参数最优值;
6、步骤3:根据元参数最优值对初始预测模型进行更新,构建优化后的地聚物混凝土强度预测模型;
7、步骤4:根据聚物混凝土强度预测模型输出预测混凝土的抗压强度预测值;其中:
8、通过蝙蝠算法对所述地聚物混凝土模型中元参数进行优化获得元参数最优值过程,包括如下步骤:
9、构建地聚物混凝土模型的蝙蝠参数初始值;
10、采用随机初始化种群中的单个蝙蝠方式对地聚物混凝土模型中元参数定位;
11、根据定位后的地聚物混凝土模型中元参数进行单个蝙蝠适应度运算获得最优元参数;
12、按照如下公式对地聚物混凝土模型中最优元参数进行速度和位置更新;
13、
14、其中:表示第i只蝙蝠在t时刻的速度;表示第i个蝙蝠在时刻t的位置减去当前迭代中所有个体的最优解;x*表示是当前迭代中所有个体的最优解;fi表示第i只蝙蝠的脉冲频率;表示随机项;xr表示随机选择的蝙蝠的位置;lc是学习因子;τ为自适应惯性权重系数;即:
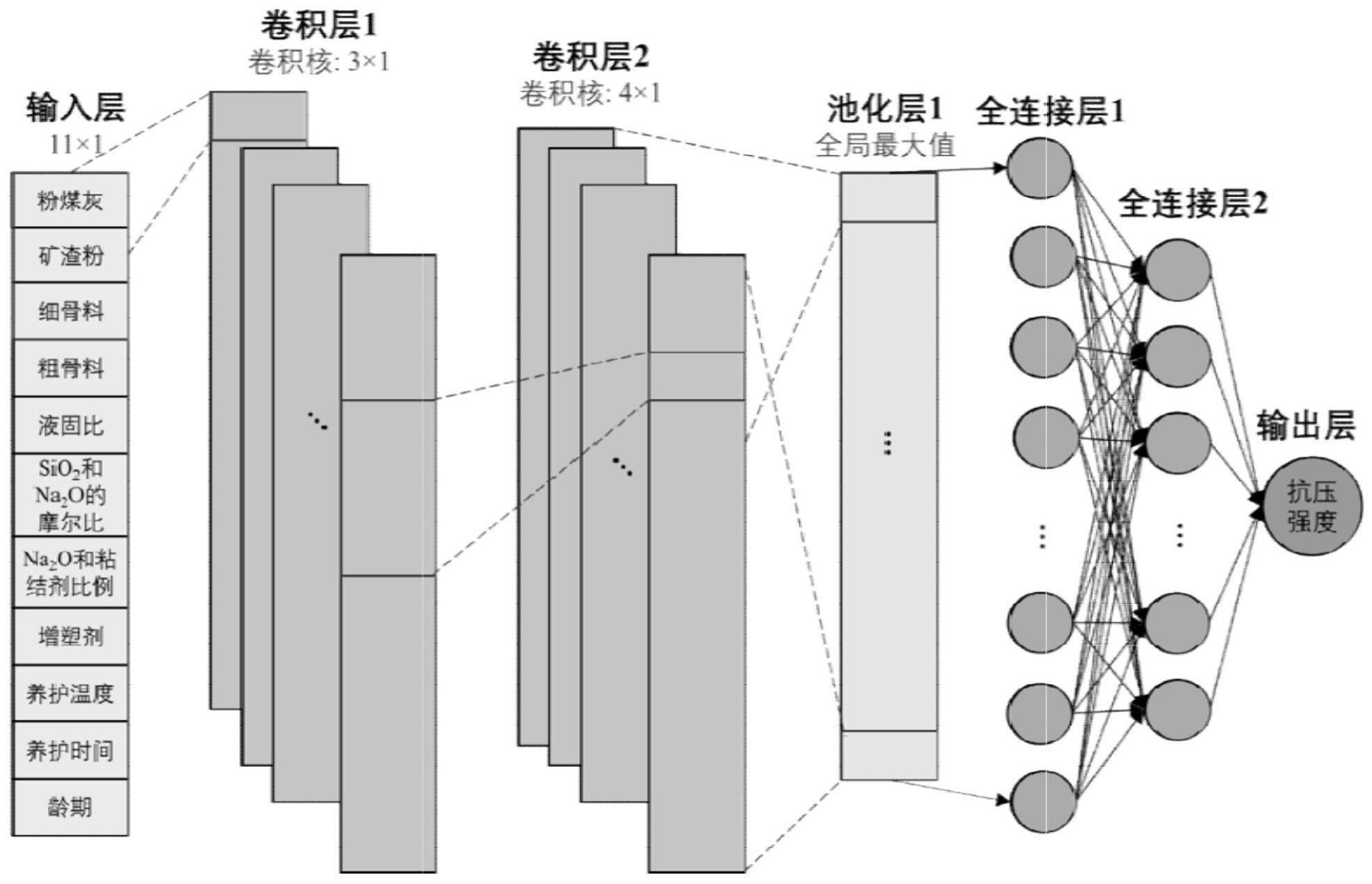
15、
16、其中:it表示当前迭代次数;τmin和τmax分别表示最小和最大惯性权重;ω是调节曲线扩散面积的常数,取值为10;nts为总迭代次数;
17、利用随机游走模型对地聚物混凝土模型进行局部搜索更新当前每个最优元参数的位置;
18、对地聚物混凝土模型进行迭代搜索更新每个最优元参数响度和脉冲发射率;
19、重新评估地聚物混凝土模型中最优元参数适应度获得元参数最优解;
20、判断是否满足停止准则,当迭代次数超过预设的最大迭代次数后输出最优解;否则,返回步骤3重新进行计算。
21、进一步,所述步骤1中采集地聚物混凝土训练样本数据对卷积神经网络进行训练构建地聚物混凝土模型过程;包括如下步骤:
22、将训练样本数据集中强度影响因素的实验数据输入到地聚物混凝土强度预测模型的输入层中;
23、在初始地聚物混凝土强度预测模型连接权值和偏置条件下通过所述步骤4正向输出混凝土强度预测值;
24、将预测的强度值与实际测量值之间的误差从输出层反向传播到输入层;在反向传播过程中,不断更新地聚物混凝土强度预测模型,使预测的强度值接近相应的真实值;
25、重复上述步骤,直到误差达到一定的阈值,结束地聚物混凝土强度预测模型训练。进一步,所述聚物混凝土强度模型包括输入层、卷积层、池化层、全连接层和输出层组成;其中:
26、所述输入层包含11个神经元,对应于地聚物混凝土抗压强度的11个影响因素;
27、所述输入层之后为2层卷积层,分别用于强度敏感特征的提取及深层表征;
28、所述池化层对学习到的深度特征进行缩减取样,形成特征图谱;
29、所述全连接层将特征图谱输入到2层全连接层,进行冗余特征消除和模式识别;
30、所述输出层输出地聚物混凝土抗压强度预测值。
31、进一步,所述地聚物混凝土训练样本数据包括粉煤灰和矿渣在单位体积混合料中的质量、细骨料及粗骨料与粘结剂的比例、水和固体间的液固比、二氧化硅与氧化钠的摩尔比(ms)、氧化钠与粘合剂的比例(nm)、增塑剂比例(sp)、养护温度(ct)、烘箱养护时间(ch)、混凝土龄期(ca)。
32、有益效果
33、第一:本发明通过在蝙蝠速度更新公式中引入了自适应惯性权重系数,增强了求解多维复杂问题时的局部优化能力;并加入一个随机项,提高蝙蝠群的多样性,提高了算法的寻优精度、效率,避免了传统方法的局限性;
34、第二:本发明利用蝙蝠算法对深度学习模型元参数进行优化,提出了改进型蝙蝠算法优化地聚物混凝土抗压强度预测模型,建立地聚物混合料各原料含量、配比与抗压强度之间复杂的映射关系,实现地聚物混凝土抗压强度预测值评估。
35、第三:本发明有利于工业生产中准确地对地聚物混凝土抗压强度值进行预测评估,促进生产。
- 还没有人留言评论。精彩留言会获得点赞!