一种基于孟德尔随机化的多因素大规模数据整合分析方法
本发明涉及生命医学与数据分析领域,特别涉及一种基于孟德尔随机化的多因素大规模数据整合分析方法。
背景技术:
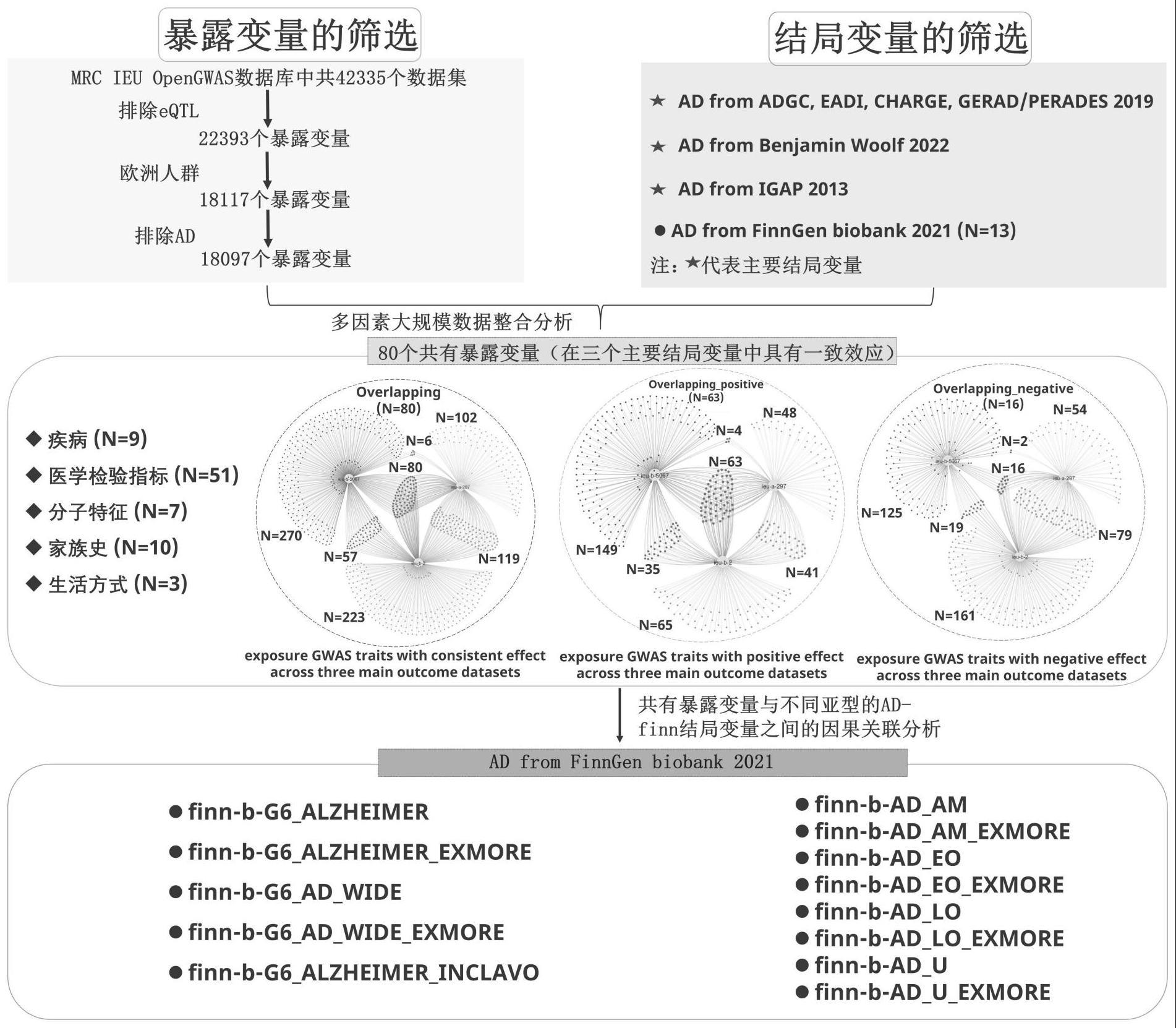
1、阿尔茨海默病(alzheimer's disease,ad)是一种中枢神经系统渐进性退行性疾病,以认知功能障碍、日常生活功能减退和行为改变为特征。可分为早发型(early-onsetad,eoad,起病年龄≤65岁)和晚发型(late-onset ad,load,起病年龄>65岁),在ad患者中,load的比例大约在95%左右,且晚发型ad(load)比早发型ad具有更强的遗传倾向。根据世界卫生组织(who)的最新数据,目前全球ad患者超5000万,预计到2050年将上升到1.15亿人。随着人口老龄化趋势加重,ad发病率持续升高,已成为全球第五大死因。由于ad是涉及多种病理生理变化的慢性复杂疾病,可能是由多种因素共同参与,多种途径所导致的慢性的、复杂的病理过程,导致当前阿尔茨海默病诊治存在就诊率低、首诊漏诊率高、长期规范治疗率低的情况。因此作为医学界最大的谜团之一,审视ad的发病机制,明确其风险因素,进行及时有效的早期筛查和诊断是至关重要的。
2、传统的流行病学研究报道了ad的常见风险因素,一些代谢性共病与ad高度相关,如心血管病、肥胖、糖尿病等。c反应蛋白、血脂、维生素水平等血清学参数曾被报道为ad潜在的生物标志物。此外,一些生活方式、家族史、受教育程度、经济水平、环境因素等也与ad具有相关性。然而,由于易发生反向因果关系和混淆偏倚,大多数流行病学研究不足以对因果关系得出明确的结论。
3、孟德尔随机化(mr)分析作为一种新兴的方法,其研究类似于随机对照试验(randomized controlled trial,rct),但又可避免rct在某些情况下(研究经费及周期限制、伦理道德、干预目标是否可随机等等)的不足之处,因此也被称为自然随机实验。mr是利用单核苷酸多态性(single nucleotide polymorphisms,snps)探究风险因素(暴露)与疾病(结局)之间因果关系的研究方法。snps作为工具变量的主要依据为:①根据孟德尔遗传定律,等位基因在配子形成过程中随机分离,在人群中实现了随机化的过程,因而从理论上避免了混杂因素的影响;②遗传变异的形成先于暴露、混杂及疾病结局,从而排除了逆向因果的干扰;③对遗传变异的测量通常具有很高的精度,将其作为暴露因素的代理变量可以在很大程度上避免由于暴露因素测量误差而引入的偏倚。因此综合上述优势,mr作为一个有价值的工具,可以更好地了解ad的潜在风险因素。
4、但早先年代由于缺乏足够数量和多样性的数据资源,mr受到的关注相对较少,而近些年来得益于高通量基因组技术的进步,通过测序积累了大量的全基因组关联研究(gwas)数据和临床信息,这些海量的数据中必然蕴含着重要的生物学规律,将为ad的mr研究开辟新的篇章,然而当前mr的研究仅仅是针对单一常见的因素进行分析,并没有进行横向比较,比如:c反应蛋白与ad、溃疡性结肠炎与ad、载脂蛋白与ad,导致海量的gwas数据大多尚未通过mr挖掘得到有效的利用,一些隐秘的ad潜在风险因素将被遗漏。因此,对多个因素进行大规模整合分析势必能提高阿尔茨海默病mr挖掘的效率,并拓宽其挖掘的深度,这将成为系统表征ad风险因素的独特方法,从而对ad的早期识别、诊断、预防、治疗具有极为重要的临床价值和社会意义。
技术实现思路
1、本发明的目的在于提供一种基于孟德尔随机化的多因素大规模数据整合分析方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于孟德尔随机化的多因素大规模数据整合分析方法,包括以下步骤:
3、步骤一:首先收集数据,在mrc ieu opengwas数据库中分别筛选出暴露变量和结局变量的gwas数据集;
4、步骤二:对工具变量进行选取,在gwas数据中分别筛选出暴露变量的snps用于mr研究;
5、步骤三:使用随机效应的逆方差加权模型作为分析方法挖掘ad潜在的风险因素。
6、优选的,在步骤一中,暴露变量的选取标准是population为european的数据集;结局变量的选取标准是具有完整资料且数据来源明确的ad患者,并同时满足population为european的数据集。
7、优选的,在步骤二中,单核苷酸多态性作为mr研究的工具变量是执行mr研究的基础。
8、优选的,snps的筛选标准是以欧洲千人基因组项目的全基因信息为参照,snps与风险因素在全基因组水平显著相关(p<5×10-8),为避免分析中可能由snps之间强连锁不平衡而带来偏倚,筛选相互独立snps,物理距离在10000kb范围内连锁不平衡r2<0.001。
9、优选的,在步骤三中,保证所有工具变量都是有效的前提下,将每一个工具变量方差的倒数作为权重进行加权计算,回归时不考虑截距项,最终结果是所有工具变量效应值的加权平均值。
10、本发明的技术效果和优点:通过mr模型可实现有效、快速、准确地挖掘新型ad潜在风险因素,并且可以得到相关风险因素与不同亚型ad之间的因果关联,该结果可以应用于临床生物标志物检查,为全世界生命科学家及临床专家提供ad研究的新思路,同时通过本发明得到的阿尔茨海默病风险因素筛查模型可以在其他疾病中应用推广。
技术特征:
1.一种基于孟德尔随机化的多因素大规模数据整合分析方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于孟德尔随机化的多因素大规模数据整合分析方法,其特征在于,在步骤一中,选取暴露变量的标准是population为european的数据集;选取结局变量的标准是具有完整资料且数据来源明确的ad患者,并同时满足population为european的数据集。
3.根据权利要求1所述的一种基于孟德尔随机化的多因素大规模数据整合分析方法,其特征在于,在步骤二中,单核苷酸多态性作为mr研究的工具变量是执行mr研究的基础。
4.根据权利要求3所述的一种基于孟德尔随机化的多因素大规模数据整合分析方法,其特征在于,snps的筛选标准为以欧洲千人基因组项目的全基因信息为参照,snps与风险因素在全基因组水平显著相关(p<5×10-8),为避免分析中可能由snps之间强连锁不平衡而带来偏倚,筛选相互独立snps,物理距离在10000kb范围内连锁不平衡r2<0.001。
5.根据权利要求1所述的一种基于孟德尔随机化的多因素大规模数据整合分析方法,其特征在于,在步骤三中,保证所有工具变量都是有效的前提下,将每一个工具变量方差的倒数作为权重进行加权计算,回归时不考虑截距项,最终结果是所有工具变量效应值的加权平均值。
技术总结
本发明公开了一种基于孟德尔随机化的多因素大规模数据整合分析方法,首先收集数据,在MRCIEUOpenGWAS数据库中分别筛选出暴露变量及结局变量的GWAS数据集,其次在暴露变量的GWAS数据集中分别筛选出对应的SNPs作为工具变量用于MR研究,最后使用随机效应的逆方差加权模型作为分析方法挖掘AD潜在的风险因素。本发明通过MR模型可实现有效、快速、准确地挖掘新型AD潜在风险因素,并且可以得到相关风险因素与不同亚型AD之间的因果关联,该结果可以应用于临床生物标志物检查,为全世界生命科学家及临床专家提供AD研究的新思路,同时通过本发明得到的阿尔茨海默病风险因素筛查模型可以在其他疾病中应用推广。
技术研发人员:赵天毓,陈立,张明,李慧
受保护的技术使用者:吉林大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!