基于特征选择的热轧带钢力学性能预测模型的建立方法
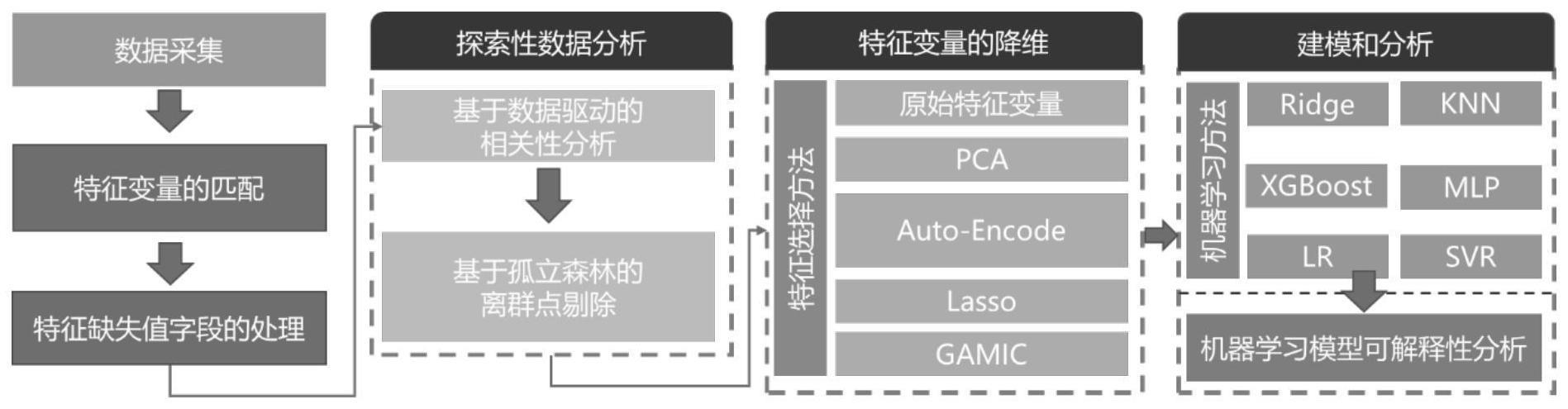
本发明涉及热轧材料力学性能的预测模型,特别是涉及基于特征选择的热轧带钢力学性能预测模型的建立方法。
背景技术:
1、热轧带钢具有质量稳定、强度高、韧性优越等特点,因其优异的机械性能而广泛应用于各种工业。热轧带钢的力学性能作为定量指标,对产品质量的评价具有重要意义。建立热轧带钢高精度力学性能预测模型,对产品开发、工艺优化、生产效率提高、降低油耗具有重要的现实意义,可使材料的研发速度大大加快。大量研究表明,热轧钢板的强度受化学成分、轧制参数和工业生产条件的影响显著,现有的简化机理模型难以描述生产工艺变化之间的复杂耦合关系。因此,在不确定条件下建立热轧带钢力学性能的预测模型是一个巨大的挑战。
2、目前,关于热轧带钢力学性能预测模型开发的专利较多。如公开号cn114386196a的中国专利公开了一种板带力学性能预测准确性评估方法,该方法能够为基于数据驱动的热轧板带力学性能预测提供一种力学性能预测结果准确性评估指标,从而为现场取样提供指导,大幅降低质量异议的风险。公开号cn114219175a的中国专利公开了一种集装箱卷板的力学性能预测方法,该方法通过改进型bp神经网络模型建立力学性能预测模型,对集装箱卷板的七个钢种力学性能进行预测,输出预测值。预测模型模型可自监测、自更新,当预测精度不满足要求时,预测模型进行自动更新。公开号cn110569566a的中国专利公开了一种板带力学性能预测方法,该方法可以解决现有技术所存在的预测模型其预测精度不稳定、泛化能力差,缺少对预测结果的准确性评价的问题。
3、以上所有专利提到的方法,普遍采用机器学习算法建立热轧钢种力学性能预测模型,并根据所建立的模型预测力学性能。虽然上述机器学习算法可以实现对机械性能的高精度预测。但是,在构建模型的过程中,模型输入的特征子集通常是人为确定的,或者根据传统经验确定的。因此,如何利用数据驱动的方法选择合适的特征子集,目前还缺乏深入研究,也是本领域亟待解决的技术难点之一。
技术实现思路
1、本发明的目的是提供一种基于特征选择的热轧带钢力学性能预测模型的建立方法,提出一种新的特征选择方法gamic,通过嵌入mic相关分析方法消除特征数据集中的低相关性特征,降低了模型输入参数的维度,提高了模型预测精度、减少模型预测所需要的时间。
2、为实现上述目的,本发明提供了基于特征选择的热轧带钢力学性能预测模型的建立方法,包括以下步骤:
3、s1、数据样本的采集:热轧带钢数据的采集及关键性参数计算;
4、s2、非线性相关性分析:基于采集的热轧数据,分析各特征参数之间的非线性相关性;
5、s3、数据清洗:利用孤立森林算法对热轧带钢力学性能预测的异常数据进行清理;
6、s4、特征选择:将遗传算法和最大互信息系数进行耦合得到gamic特征选择算法;
7、s5、热轧带钢力学性能预测模型的建立和模型参数优化:结合xgboost集成机器学习算法,并利用步骤s4的gamic特征选择方法选择后的特征子集建立热轧带钢力学性能预测模型,采用五折交叉验证和网格搜索方法对热轧带钢力学性能预测模型参数进行自动优化,然后利用测试数据对力学性能预测;
8、s6、xgboost模型可解释性分析:利用基于博弈论的shap可解释模型对热轧带钢力学性能预测模型进行分析,展示特征变量对力学性能的影响。
9、优选的,在步骤s1中,热轧带钢数据包括c、si、mn、p、s、n、nb、ti、al、cu、ni、加热时间(heat_time)、固溶温度(ss_temp)、固溶时间(ss_time)、出炉温度(dtf)、精轧入口厚度(feh)、精轧入口温度(fet)、f7轧制速度(frs)、精轧出口温度(fdt)、卷取温度(ct)、成分厚度(h)、冷却速率(cr)、有效ti含量(cp_ti)、析出体积分数(vfp)。
10、优选的,在步骤s2中,非线性相关性采用spearman相关性分析方法量化特征变量的非线性程度,计算公式为:
11、
12、其中,ρ为非线性相关性系数,x,y均为属性变量,r(x)和r(y)分别是x和y的位次,和分别是平均位次。
13、优选的,在步骤s3中,异常数据清理方法是采用孤立森林算法剔除异常数据样本,具体包括:
14、步骤3.1:利用s1中的数据样本集构建孤立森林预测模型;
15、步骤3.2:将测试样本带入预测模型中,计算样本数据的异常分数score,剔除异常分数小于0的样本数据,score计算公式为:
16、
17、其中,x为数据样本,ψ为x所在叶子节点中样本的个数,e(h(x))为数据x在孤立森林中各孤立树路径长度h(x)和的平均值;c(ψ)为用ψ条数据记录建立的孤立树的平均路径长度。
18、优选的,在步骤s4中,特征选择方法是在遗传算法特征选择方法的基础上与最大互信息系数进行耦合,具体包括:
19、步骤4.1:采用二进制编码方式,对每个样本的特征进行编码,二进制代码每个位的值“0”表示未选择该特征,“1”表示已选择要素;
20、步骤4.2:随机生成种群数量为50的初始种群;
21、步骤4.3:评价适应度函数设定为均方根误差;
22、步骤4.4:群中最好的个体作为父代复制到下一代新种群中,然后对父代种群进行选择、交叉和变异等遗传算子运算,从而繁殖出下一代新种群;
23、步骤4.5:利用mic算法检测变量间的非线性相关性,计算每个特征与因变量之间的mic,选择对因变量影响较大的特征,剔除信息较少的特征;
24、步骤4.6:当达到最大迭代次数或达到设置的收敛条件时,迭代停止。
25、优选的,热轧带钢力学性能预测模型的建立和模型参数优化具体的包括:
26、步骤5.1:通过随机抽样的方式将特征选择后的特征子集按照4:1的比例分为训练数据集和预测数据集;
27、步骤5.2:采用五折交叉验证和网格搜索方法对xgboost模型参数进行自动优化,模型参数为:'objective'='reg:squarederror','eta'=0.1,'gamma'=15,'lambda'=12,'alpha'=0.2,'max_depth'=4,num_round=50,然后利用测试数据对力学性能预测。
28、优选的,在步骤s6中,热轧带钢力学性能预测模型可解释性分析是利用shap算法分析特征变量的重要性,具体包括:
29、步骤6.1:通过计算每个输入特征值的绝对shap值的算术平均值来评估特征变量的影响;
30、步骤6.2:分析每个特征对机械性能的影响的重要性,并对每个特征的影响程度进行了排名。
31、本发明的有益效果:
32、1)、在遗传算法特征选择方法的基础上与最大互信息系数进行耦合构建gamic特征选择方法,通过gamic特征选择方法选择合适的特征子集,模型的输入特征维数从原来的27个减少了13个,减少了模型的训练时间。
33、2)、gamic特征选择方法与3种常用的fs方法和原始数据集相比,gamic选择的特征子集分别提高了ys和ts模型的预测精度。
34、3)、利用shap分析力学性能预测模型的可解释性,不仅降低了输入维数,而且特征重要性的顺序与物理冶金规律一致,提高了预测模型的可靠性。
35、4)、本发明的热轧带钢力学性能预测模型,先消除了信息较少的特征,减少了输入特征参数的数量,然后,利用特征选择后的低维数据和xgboost集成学习算法,建立了热轧微合金钢力学性能预测模型,结合xgboost模型,并结合shap的强大解释方法,进一步揭示了特征对力学性能的影响。
36、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!