一种基于数据驱动优化的酶改造方法
本发明涉及一种基于数据驱动优化的酶改造方法,属于机器学习辅助蛋白质设计领域。
背景技术:
1、得益于酶促反应高效专一、绿色环保等优点,酶不仅在化工、食品、环境等传统领域中具有十分广泛的应用,在基因编辑、干细胞技术、靶向药物等新兴技术与产品中同样发挥着不可替代的作用。大量研究发现,天然蛋白质酶在稳定性、耐受性、选择性等方面往往无法满足实际应用的需求。因此,优化与改造酶分子不仅是蛋白质科学研究的重点,也是工业生产的迫切需求。
2、蛋白质工程领域中,常用的蛋白质改造方法包括:定向进化、半理性设计与理性设计。定向进化通过对蛋白质进行多轮反复地突变、表达与筛选,引导蛋白质不断累计有益突变。但定向进化以随机的方式引入突变,产生了数量庞大地突变体,十分不利于人工筛选。半理性设计则在晶体结构、催化机制等先验知识的基础上选取若干位点作为改造靶点,进而提高改造的效率。但半理性设计的是否成功与先验知识的丰富程度密切相关,从而导致其应用具有相当大的局限性。理性设计试图通过精准调控蛋白质的结构空间获取具有期望性质的酶,但当前仍受限于酶分子空间结构的高精度获取以及对结构-功能关系与催化机理的理性认知,导致理性设计成功改造酶的案例十分有限。
3、氨基酸序列高维与强耦合的特性以及有限的样本给基于机器学习的酶改造方法研究带来巨大挑战。基于机器学习的酶改造包含了蛋白质特征提取、预测模型构建与验证对象筛选三个关键步骤。目前,相关研究通过引入氨基序列的排列信息与氨基酸残基的物化信息提出了多种提取蛋白质特征的编码方法,但这些编码方法都存在维度高、表征能力差以及量化值分布不合理的问题。此外,现有验证对象筛选方法极其依赖训练集的样本质量,且极易陷入局部最优解,从而无法保证酶改造的有效性。因此,想要实现高效、低成本的酶分子改造,除了要设计出表征能力更强的编码方法,还需要引入更加先进的机器学习技术。
技术实现思路
1、本发明的目的在于提供一种基于数据驱动优化的酶改造方法,从而能够在可接受的成本内实现高效的酶分子改造。
2、为达到上述目的,本发明提供一种基于数据驱动优化的酶改造方法,包括:
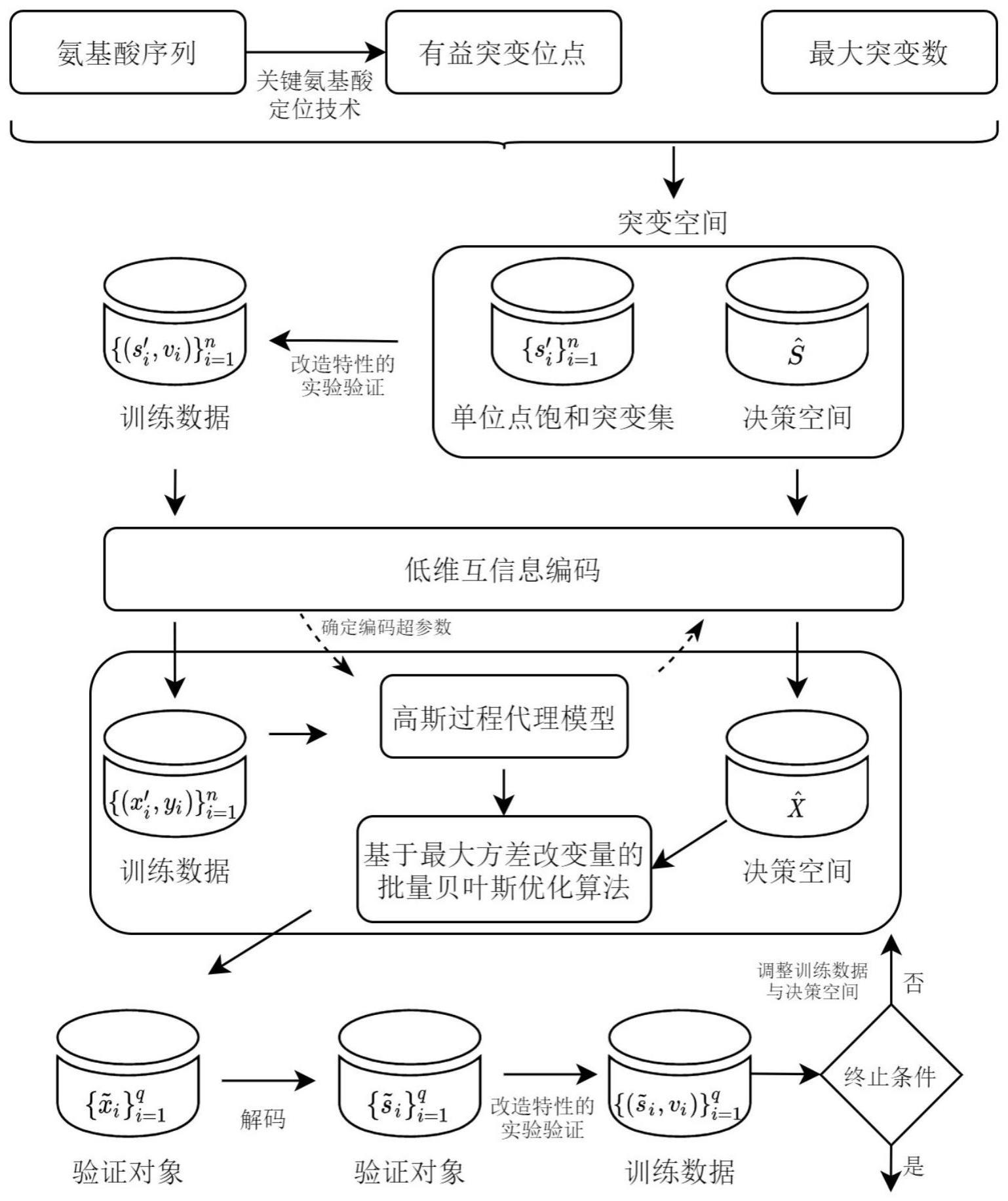
3、步骤s1,采用分子对接和点突变技术确定若干突变热点残基,并根据氨基酸序列与给定的最大突变位点数生成酶改造的突变空间;
4、步骤s2,对每个基于突变热点残基的单位点饱和突变序列进行酶改造特性实验以得到改造特性的量化值,并将单位点饱和突变序列及其对应的量化值作为酶改造实验的初始训练数据;此外,将突变空间与单位点饱和突变序列构成的集合之间的差集作为酶改造实验的决策空间;
5、步骤s3,基于初始训练数据,以交叉验证的方式确定低维互信息编码方法的超参数,随后根据确定的超参数采用低维互信息编码方法分别对决策空间与初始训练数据进行编码,得到经过编码的决策空间和当前训练数据;
6、步骤s4,基于当前训练数据采用高斯过程来构建高斯过程回归模型作为代理模型,并根据代理模型采用基于最大化方差改变量的批量贝叶斯优化算法从经过编码的决策空间中挑选本轮实验的验证对象,随后将验证对象解码为氨基酸序列并对氨基酸序列的改造特性进行实验验证,以得到验证对象的改造特性的量化值;
7、步骤s5,将所有本轮实验的验证对象和其改造特性的量化值添加到当前训练数据中,以更新当前训练数据,通过删除本轮实验的验证对象来更新经过编码的决策空间,随后转到步骤s4;直到满足批量贝叶斯优化算法的终止条件或达到最大迭代次数,将此时的验证对象的改造特性的量化值的最优结果所对应的氨基酸序列作为酶改造的最终结果。
8、优选地,所述步骤s1具体包括:
9、步骤s11,基于蛋白质的结构,通过酶与底物的分子对接确定底物结合口袋,再通过对底物结合口袋周围的氨基酸残基的定点突变及对应的突变体的催化活性测定,确定所有与催化活性相关的突变热点残基;
10、步骤s12,根据氨基酸序列与给定的最大突变位点数,通过突变热点残基来生成酶改造的突变空间,突变空间是酶的突变序列si的集合,酶的突变序列si是由酶的序列至少突变一个突变热点残基得到的,并且,突变序列si的突变位点的数量至多为所述的最大突变位点数。
11、优选地,所述步骤s2具体包括:
12、步骤s21,对每个基于突变热点残基的单位点饱和突变序列进行酶改造特性实验以得到改造特性的量化值,并将单位点饱和突变序列的序列值及其对应的量化值作为酶改造实验的初始训练数据;
13、步骤s22,将突变空间与单位点饱和突变序列构成的集合之间的差集作为酶改造的决策空间
14、优选地,步骤s3中,低维互信息编码方法包括:
15、步骤s31,使用氨基酸t-scale拓扑描述符逐一替换突变空间s中的每条氨基酸序列,从而得到每条氨基酸序列的描述符矩阵m;
16、步骤s32,采用如下公式计算每条氨基酸序列的自协方差矩阵c:
17、
18、其中,b表示氨基酸残基之间的距离,其取值为{1,2,…,l},cb,j与mi,j分别表示自协方差矩阵c的第b行的第j个元素与描述符矩阵m的第i行的第j个元素,i表示描述符矩阵m中的行位置,j为描述符矩阵m的组别,m代表描述符矩阵m的行数,即为氨基酸序列长度;
19、步骤s33,对于突变空间中的每一条氨基酸序列,将其自协方差矩阵c的各列串联在一起,并根据降维维数d采用主成分分析算法对串联结果进行降维,降维结果为突变空间s的编码结果,突变空间s的编码结果包括经过编码的决策空间和初始训练数据的序列值的编码结果;
20、步骤s34,在突变空间s的编码结果中找到初始训练数据的序列值的编码结果作为样本输入xi’,根据初始训练数据的改造特性的量化值得到样本输出yi,每一个样本输入和样本输出作为一个训练样本,从而形成当前训练数据。
21、优选地,根据初始训练数据的改造特性的量化值得到样本输出yi,具体包括:对初始训练数据的改造特性的量化值的分布进行优化,得到初始训练数据的改造特性的量化值的分布优化结果,将初始训练数据的改造特性的量化值的分布优化结果作为样本输出yi。
22、优选地,采用如下公式对初始训练数据的改造特性的量化值的分布进行优化:
23、y=aln(v),
24、式中,y表示量化值的分布优化结果,a∈[1,+∞)是样本输出的缩放系数,v表示改造特性的量化值。
25、优选地,在所述步骤s4中,基于当前训练数据采用高斯过程来构建高斯过程回归模型作为代理模型,并根据代理模型采用基于最大化方差改变量的批量贝叶斯优化算法从经过编码的决策空间中挑选本轮实验的验证对象,具体包括:
26、步骤s41,基于当前训练数据构建和训练高斯过程回归模型,并从训练好的高斯过程回归模型中获取协方差函数的核参数θ与噪声方差
27、步骤s42,根据所求解问题的类型,从经过编码的决策空间中划分出值得评估的样本集;
28、步骤s43,若值得评估的样本集x*的样本量m小于等于批次大小q,将值得评估的样本集x*作为本轮迭代所求得的评估样本集并将本轮迭代所求得的评估样本集中的所有验证对象解码为氨基酸序列并对氨基酸序列的改造特性进行实验验证,在得到改造特性的量化值后执行步骤s5。
29、优选地,在步骤s42中,当求解问题是改造特性的量化值的最大值对应的样本时,采用如下公式从决策空间中划分出值得评估的样本集:
30、
31、其中,x表示经过编码的决策空间中的样本,ymax表示当前训练数据中的样本输出的最大值,zα为标准正态分布的下侧α分位数,μ(x)与δn(x)分别表示高斯过程回归模型对样本x的预测均值和预测标准差;
32、当求解问题是改造特性的量化值的最小值对应的样本时,采用如下公式从决策空间中划分出值得评估的样本集:
33、
34、式中,ymin表示当前训练数据中的样本输出的最小值。
35、优选地,所述步骤s4还包括:
36、步骤s44,当值得评估的样本集x*的样本量m超过10000,随机从值得评估的样本集x*中挑选10000个样本组成新的值得评估的样本集x*;
37、步骤s45,当值得评估的样本集x*的样本量m小于等于10000且大于批次大小q时,从值得评估的样本集x*中依次挑选q个能使如下公式最大化的样本作为本轮迭代所求得的评估样本集,并将其从值得评估的样本集x*中删去,随后回到步骤s43:
38、
39、式中,是挑选出的第i个评估样本,是值得评估的样本集x*中的第j个样本,n表示当前训练数据的样本个数,n+i表示新选出的第i个评估样本的下标,xn是当前训练数据的样本输入的集合,ki,j表示与之间的协方差,kn+i,j表示当前训练数据的样本输入的集合与评估样本集中前i个样本的集合的并集与之间的协方差向量,表示与挑选出的第i+1个评估样本之间的协方差向量,an+1为中间参数,kn+i表示的协方差矩阵,是噪声方差,i表示单位矩阵,是根据计算的输出方差。
40、优选地,在所述步骤s5中,批量贝叶斯优化算法的终止条件为:
41、当决策空间大且目标函数复杂时,将连续三次满足如下公式作为批量贝叶斯优化算法的终止条件:
42、|x*|≤0.5%n
43、其中,n表示突变空间的总样本数,|x*|表示值得评估的样本集x*的样本数量;
44、其他场景下,将|x*|=0作为批量贝叶斯优化算法的终止条件。
45、本发明的基于数据驱动优化的酶改造方法将酶改造建模为黑箱函数的组合优化问题,进而引入机器学习中的批量贝叶斯优化技术求解该问题,得益于低维互信息编码的表征能力,可构建出拟合效果好的序列-功能映射关系的代理模型;得益于批量贝叶斯优化的全局优化能力,所提出的酶改造方法可通过迭代筛选过程不断地逼近决策空间中的全局最优突变序列,从而实现酶分子特定功能的改造;得益于基于最大方差改变量的批量贝叶斯优化算法的终止条件,所提供的酶改造方法可依据当前数据采用概率方法判断是否找到决策空间中的全局最优突变序列,避免了因不合理的终止条件而造成的实验资源浪费。因此,本发明提供的基于数据驱动优化的酶改造方法不仅能实现可靠的酶分子改造,还能降低酶分子改造的时间成本与经济投入。
- 还没有人留言评论。精彩留言会获得点赞!