基于多路一维卷积残差网络模型的心血管疾病预测方法
:本发明涉及疾病预测领域,尤其涉及一种基于多路一维卷积残差网络模型的心血管疾病预测方法。
背景技术
0、
背景技术:
1、随着健康管理意识的增强和医学科技的飞速发展,越来越多人逐渐关注自身健康状况,而且希望获得更准确、可靠的健康预警信息。与此同时,心血管疾病等一些慢性疾病也日益引起重视。据统计,每5个死亡病例中就有2个病例是由心血管疾病引起的。此外,随着年龄的增长,男性和女性的心血管疾病越来越常见。因此,通过对一系列相关因素进行分析和建模,可以预测人类患心血管疾病的可能性。预测模型不仅仅可以帮助个体了解自己患病的风险,及时采取预防措施,如改善饮食、增加运动、控制血压等,减少患病的可能性;并且帮助医疗机构预测患者的风险,充分利用医疗资源,提高医疗效率。心血管疾病预测模型对于人类具有重要意义。
2、疾病预测从最开始的基于传统的统计模型,到后来使用机器学习模型,再到现在的深度学习模型,医疗领域的疾病预测模型的研究与发展,为人类健康做出了重要贡献。通过比较不同模型的优缺点,可以更好地理解它们在医疗领域中的作用和效果。这将有助于推动疾病预测模型的进一步发展,并为未来的健康管理提供更准确、可靠的预测工具。现有的心血管疾病预测模型的准确率低,影响误判率。
技术实现思路
0、
技术实现要素:
1、(一)技术方案
2、本发明的目的是在一定程度上解决现有疾病预测模型的误判率高、性能差的问题。为此,本发明的一个目的在于提出一种基于多路一维卷积残差网络模型的心血管疾病预测方法,该方法包括以下步骤:
3、步骤1数据预处理,包括对数据集离散值编码、数据增强等操作,并进行数据集划分;
4、步骤2特征提取阶段使用本发明的方法,使用具有残差链接的不同尺寸的一维卷积核,提取出其特征,然后将不同尺度的特征进行融合;
5、步骤3分类阶段,将提取到的特征作为分类模块的输入,并将分类模块的最后输出作为预测分数。
6、步骤4通过优化器对整体模型进行优化,得到性能最佳模型。
7、本发明实施的基于一维卷积的疾病预测方法,首先通过不同尺寸的由一维卷积组成的残差块,对数据特征提取。由于尺寸的不同,每个残差块所提取到的特征信息的层次也不相同。其次提取完特征之后,拼接这些所得到的特征,作为融合特征,最后将该特征输入到全连接层中进行分类预测。
8、其包括以下具体步骤:
9、1数据预处理
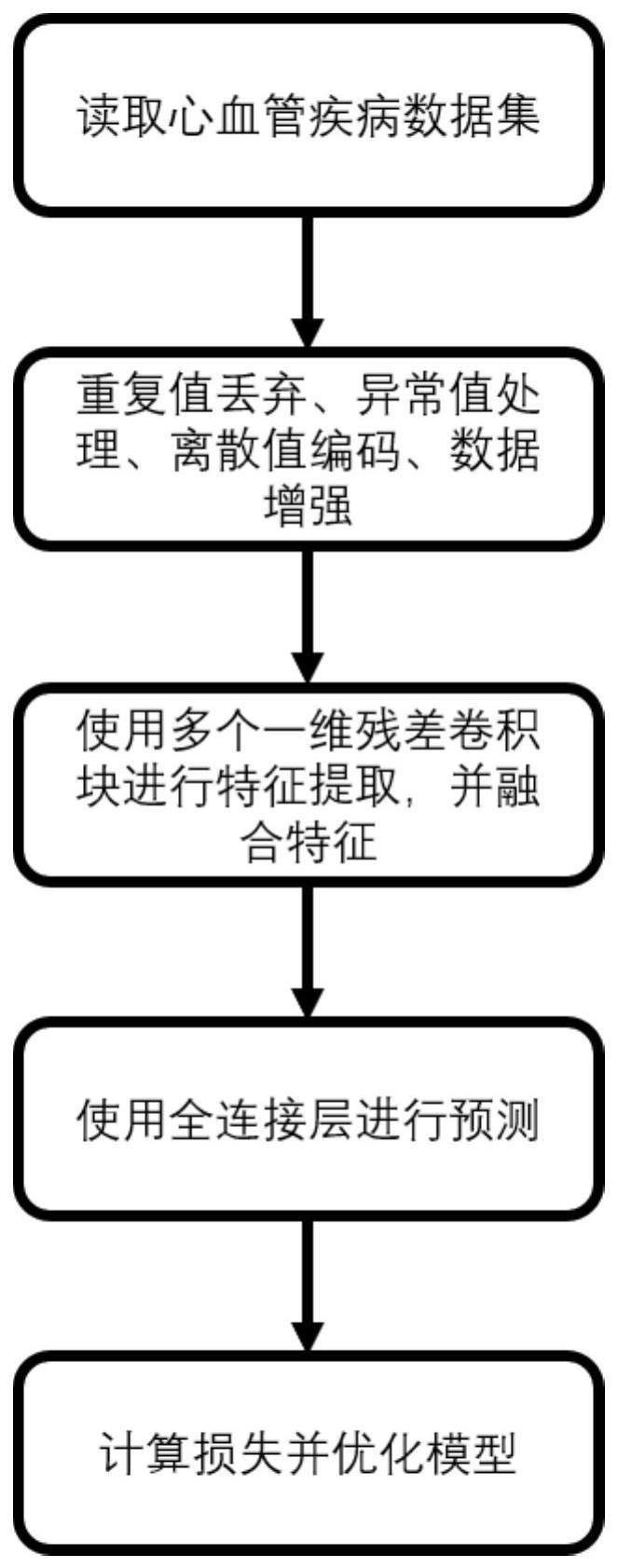
10、方法流程图如图1所示,该方法首步是输入原始数据,并对其进行预处理。数据预处理的过程主要是对数据集进行包括离散值编码、丢弃重复值、数据增强等预处理,并进行数据集划分
11、步骤1-1加载数据,得到特征和标签信息;
12、步骤1-2为了保证不影响整体训练过程,将数据中存在的重复数据丢弃;
13、步骤1-3对数据进行异常值处理,设置波动范围,范围外的被视为异常数据进行丢弃;
14、步骤1-4数据中的离散值,并不适用于模型训练,使用one-hot编码对这些离散值进行处理;
15、步骤1-5数据增强阶段,增加了三种新的特征向量,包括身体健康指数(bmi)、平均动脉压(map)和脉冲压力(pp),这三种特征向量的计算公式如下:
16、
17、
18、pp=aphi-aplo
19、步骤1-6将整体数据归一化,避免因为数据量级的不平衡性,导致在模型训练的过程中,数值较小的特征被忽略,而数值较大的特征会对模型训练结果产生更大的影响;
20、步骤1-7按照8:2的比例划分数据集和测试集。
21、2特征提取阶段
22、步骤2-1使用两个一维卷积核对原始特征进行特征提取,其计算公式为:
23、
24、步骤2-2每个一维卷积核提取特征之后都使用batchnorml1d对数据进行标准化来防止梯度消失或梯度爆炸,非线性变换使用relu函数;
25、步骤2-3将步骤2-1的输入数据输入到一个一维卷积核中,目的是与其输出数据的尺寸对齐并相加,从而形成一个具有残差连接的一维卷积块,如图1的一维残差卷积块图;
26、步骤2-4使用不同尺寸的一维残差卷积块,对原始数据进行特征提取,得到不同层次的特征数据;
27、步骤2-5将这些不同层次的特征进行拼接,从而得到融合特征,,公式如下:
28、xf=[x1x2x3...xm]
29、xm=[xm1,xm2,xm3,...]
30、其中xf是特征提取模块所提取到的全部特征,其中xm表示第m条路径所提取到的特征,将每一条路径提取到的特征拼接起来作为一种融合特征。
31、3分类阶段
32、步骤3-1将步骤2-5提取的融合特征输入到由全连接神经网络组成的分类模块中,进行分类,计算公式如下:
33、outputl=σ(outputl-1wl-1+bl-1)
34、其中outputl,outputl-1,wl-1和bl-1是分别是第l层分类器的输出,输入,分类器第l-1层的可训练权重和偏置矩阵。output0是分类器的初始输入,也就是特征提取器提出到的融合特征。
35、每一层分类器之前都是用leakyrelu来进行非线性变换,公式如下:
36、
37、其中,leak是是斜率,通常取0.01。leaky relu函数可以有效地避免relu函数在输入为负数时出现的“神经元死亡”问题,从而增强模型的稳定性和泛化能力。
38、步骤3-2分类预测结果根据分类器输出的大小来决定,分类器最后的输出数量为2,若第一个输出更大,则将该条数据判定为无病,反之为有病。
39、4优化过程
40、步骤4-1加载训练数据集和测试集
41、步骤4-2将训练集输入到模型中,交叉熵函数计算损失,公式如下:
42、
43、步骤4-3adam优化器不仅能对模型参数进行优化,而且使用指数移动平均来估计梯度的一阶矩(均值)和二阶矩(方差),并结合动量概念来调整参数的更新。
44、步骤4-3测试集输入到已经优化到最优的模型中,得到最终的测试集预测结果以及指标。
45、(二)有益效果
46、1.本发明解决了当前很多预测模型只是改良了神经网络模型的结构,然而却没有结合原始数据自身的特点进行有效的预处理的问题,而且还弥补了很多方法没有根据数据的固有属性来选择更符合逻辑的模型结构的问题;
47、2.本发明与现有的疾病预测方法相比,进行了更加有效的数据预处理方式、包括异常值处理、离散值编码等,再使用不同尺寸的一维卷积块提取不同层次的特征,在可以保证提取的特征更为全面,从而提升整体模型的预测性能。
技术特征:
1.一种基于多路一维卷积残差网络模型的心血管疾病预测方法,其特征在于该方法包括以下步骤:
2.根据权利要求1所述的基于多路一维卷积残差网络模型的心血管疾病预测方法,其特征在于,所述步骤1中的数据预处理过程,具体步骤为:
3.根据权利要求1所述的基于多路一维卷积残差网络模型的心血管疾病预测方法,其特征在于,所述步骤2中的特征提取阶段,具体步骤为:
4.根据权利要求1所述的基于多路一维卷积残差网络模型的心血管疾病预测方法,其特征在于,所述步骤3中的分类模块,具体步骤为:
5.根据权利要求1所述的基于多路一维卷积残差网络模型的心血管疾病预测方法,其特征在于,所述步骤4中的优化过程,具体步骤为:
技术总结
本发明提出一种基于一维卷积与残差连接的疾病预测方法,属于疾病预测领域。该方法包括:从互联网获取数据集;进行数据预处理,并划分数据集;使用多个尺寸不同的一维残差卷积块进行特征提取,并对提到的不同特征进行特征融合;使用全连接层对融合特征进行分类预测;计算损失并且通过优化器对模型进行优化。该方法针对现有方法没有结合原始数据自身的特点进行有效的预处理并且没有根据数据的固有属性来选择更符合逻辑的模型结构的问题进行设计,极大的提高了心血管疾病的预测性能。实验结果验证了所提出的方法的优势和有效性。
技术研发人员:陈海龙,张秀霞,周信澎,魏海月,徐欣瑶
受保护的技术使用者:哈尔滨理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!