一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法及系统
本发明属于数据检测领域,具体涉及一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法及系统。
背景技术:
1、甲状腺疾病是一类常见的内分泌系统疾病,包括甲状腺功能亢进、甲状腺功能减退等,如未能及时准确地进行诊断和治疗,将对患者的生活质量和健康状况造成长期的严重影响。
2、由于疾病具有复杂性和多样性,相关影响因素具有多元性,传统的医学检查和诊断方法涉及多种生化实验检测,过程非常复杂,在时间和设备材料成本很高的同时,还存在人为错误影响诊断准确性的问题。因此,自动化的机器学习算法在医学诊断方面有着巨大的应用潜力。
3、目前市面上的机器学习算法大多是为平衡数据集涉及的,而在甲状腺疾病检测中,正常样本通常远多于异常样本,造成了数据不平衡,这种不平衡会导致算法对于多数类(正常样本)过度敏感,而对少数类(异常样本)不够敏感,从而影响了分类模型的准确性。目前在甲状腺疾病检测中常用的不平衡检测方法,大多是黑盒性质的输出,缺乏良好的语言可解释性。
技术实现思路
1、发明目的:本发明的目的是提供一种高准确度、高可解释性的基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法及系统。
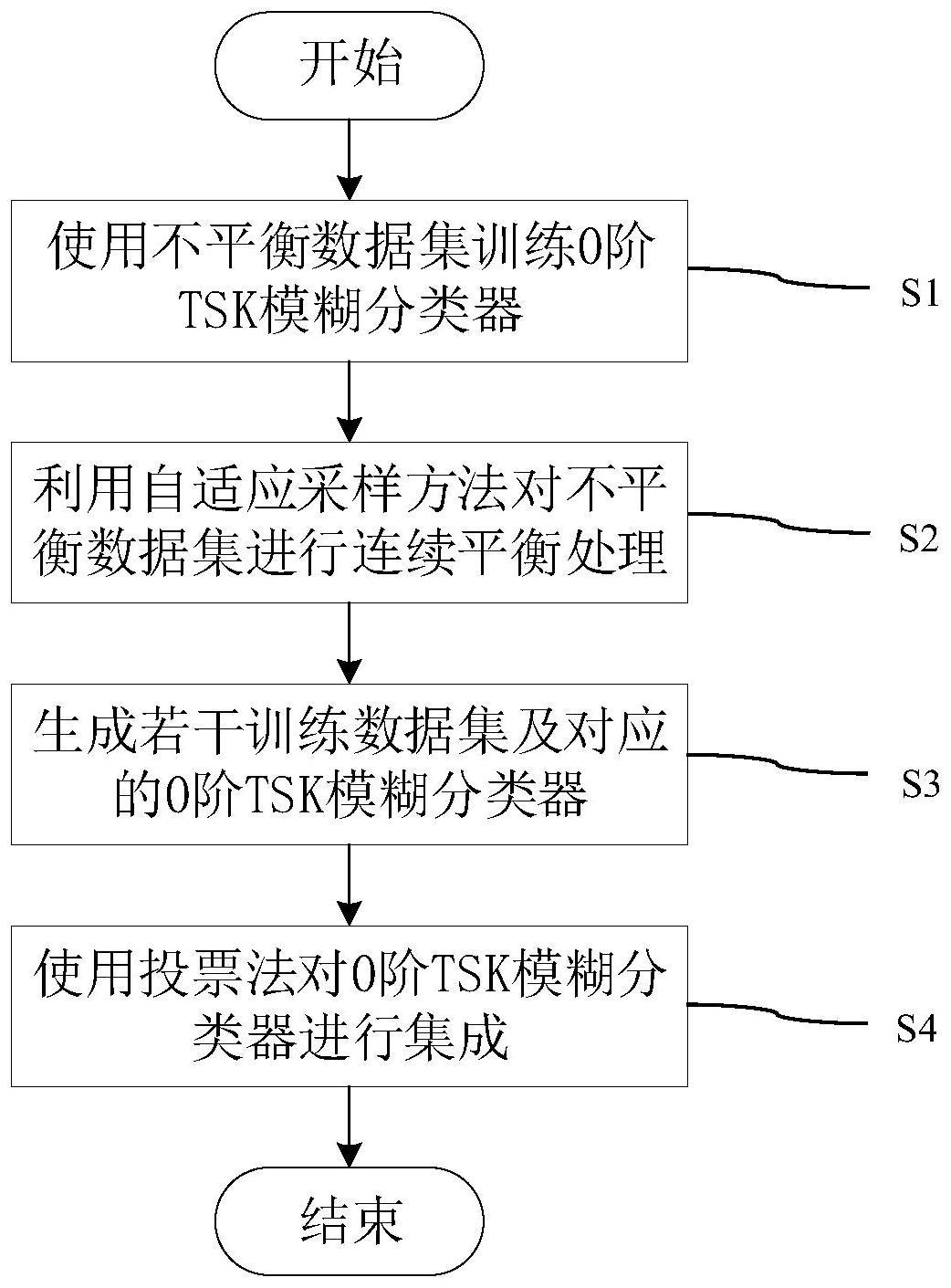
2、技术方案:本发明所述的一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法,包括以下步骤:
3、s1、使用甲状腺疾病类别不平衡数据集对0阶tsk模糊分类器进行训练;
4、s2、采用自适应采样策略,利用s1中训练后的0阶tsk模糊分类器对甲状腺疾病类别不平衡数据集进行连续平衡处理,将0阶tsk模糊分类器分类错误的样本加入下一轮平衡的数据集,使甲状腺疾病数据的分布不断平衡化;
5、s3、采用s2中自适应采样策略,产生若干相对平衡的甲状腺疾病类别不平衡训练数据集,同时生成若干0阶tsk模糊分类器,每个0阶tsk模糊分类器分别对应一个甲状腺疾病类别不平衡训练数据集;
6、s4、使用投票法对s3中的若干0阶tsk模糊分类器进行集成。
7、具体的,步骤s1包括以下子步骤:
8、s101、定义第t个0阶tsk模糊分类器的甲状腺疾病类别不平衡训练数据集为dt,包括数据特征集合x=[x1,x2,…,xn]、与该数据特征集合x对应的类标签集合y=[y1,y2,…,yn];
9、式中:集合x中任意一个元素xn∈rd,n=1,2,…,n;n表示甲状腺疾病类别不平衡训练数据集的样本数量,rd表示d维的样本数据,d是样本的维度;y中任意一个元素yn与x中元素xn相对应,为该元素xn的类标签;
10、s102、计算样本在每一个维度下的高斯隶属度函数,第k条模糊规则在样本第j维输入特征下的高斯隶属度函数为:
11、
12、式中:φ是隶属度函数;t表示第t个0阶tsk模糊分类器;j=1,2,…,d;k=1,2,…,k,k是模糊规则的初始化数量;xnj表示在n个甲状腺疾病类别不平衡训练样本中第n个训练样本xn的第j维数据;为隶属度函数中心参数,且从{0,0.25,0.5,0.75,1}中随机选取;σ为手动输入的高斯函数的宽度;
13、s103、计算所有模糊规则下的样本xn归一化后的隶属度函数值:
14、
15、s104、得到模糊分类器的φt矩阵:
16、
17、s105、引入单位矩阵ik×k,对下式使用最小二乘法求解,得到模糊规则的后件参数:
18、
19、式中:at为后件参数;λ为正则化常量参数;i为单位矩阵;
20、s106、得到模糊分类器的输出:
21、y=φtat
22、式中:y是甲状腺疾病类别不平衡数据的标签集合;φt是在甲状腺疾病类别不平衡数据集基础上求得的隶属度函数值。
23、具体的,步骤s2包括以下子步骤:
24、s201、定义rt为训练集,re为错误集,利用初始的不平衡训练集rt1训练首个0阶tsk模糊分类器tsk1,然后利用tsk1对所有属于rt1的训练样本分类;
25、s202、将被误分类的训练样本组成误分类训练样本集re1,将rt1与re1合并得rt2,即rt2=rt1∪re1,用于训练第二个0阶tsk模糊分类器tsk2;
26、s203、重复步骤s201、s202;
27、s204、采用g-mean(几何均值指标)作为评价指标,对每轮训练后的0阶tsk模糊分类器进行测试,当所训练的0阶tsk模糊分类器在甲状腺疾病类别不平衡数据检测中取得最高的g-mean值时,选取该轮次的0阶tsk模糊分类器,同时完成连续平衡处理,得到相对平衡的甲状腺疾病类别不平衡训练数据集。
28、具体的,所述相对平衡的甲状腺疾病类别不平衡训练数据集为各类甲状腺疾病样例的数量差距可忽略不计的训练数据集。
29、具体的,步骤s3中所述若干0阶tsk模糊分类器是在若干个相对平衡的甲状腺疾病类别不平衡训练数据集基础上,使用s1中0阶tsk模糊分类器的训练方法,得到对应的若干个0阶tsk模糊分类器。
30、具体的,步骤s4包括以下子步骤:
31、s401、将每个0阶tsk模糊分类器t的输出记为yt,yt∈{1,...,n},对应第1~n种甲状腺疾病类别;
32、s402、记录预测对应类别的0阶tsk模糊分类器数量
33、vi=count(yt=i)
34、式中:vi为预测第i种类别的0阶tsk模糊分类器数量,count为计数函数,记录在t个0阶tsk模糊分类器输出中yt值为i的总次数;i=1,2,…,n;
35、s403、集成总输出
36、yensemble=max (vi)
37、式中:yensemble为最终输出值;max为求最大值函数,比较得出数值最大的vi,并输出对应的第i种甲状腺疾病类别。
38、本发明还提供一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测系统,其特征在于,所述系统包括:
39、0阶tsk模糊分类器训练模块,用于对作为基础分类器的0阶tsk模糊分类器进行训练;
40、自适应采样模块,用于对甲状腺疾病类别不平衡数据集进行连续平衡处理;
41、0阶tsk模糊分类器生成模块,用于产生若干相对平衡的甲状腺疾病类别不平衡训练数据集,同时生成若干0阶tsk模糊分类器;
42、0阶tsk模糊分类器集成模块,用于对若干0阶tsk模糊分类器进行集成。
43、具体的,所述0阶tsk模糊分类器集成模块包括:
44、0阶tsk模糊分类器输出记录模块,用于记录每个0阶tsk模糊分类器输出值;
45、0阶tsk模糊分类器输出计数模块,用于记录每个甲状腺疾病类别对应的0阶tsk模糊分类器数量;
46、集成总输出模块,用于比较得出数值最大的0阶tsk模糊分类器数量,并输出该数值对应的甲状腺疾病类别。
47、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法的步骤。
48、本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种基于自适应采样驱动的类别不平衡甲状腺疾病数据检测方法的步骤。
49、有益效果:与现有技术相比,本发明的显著效果是:
50、首先,本发明提出了一种有效的数据级别的类别不平衡甲状腺疾病检测集成学习方法,与传统方法中基于减少部分多数类样本的欠采样检测技术可能导致数据中重要信息丢失不同,本方法训练样本的数量增加,不会造成数据信息的丢失;与基于增加样本的过采样检测方法对比,传统的过采样往往只是片面地增加少数类样本的数量,忽略了样本中某些难以学习的多数类,这部分多数类信息页需要在学习中得到重视,简单的过采样也容易造成过拟合的问题;而本发明的自适应采样是基于错误集的,经过tsk模糊分类器分类筛选出来的错误集,不仅包含容易被分类错误的少数类样本,也包含了分类器难以学习的多数类样本,在基于错误集新合成的训练集中,这些样本都得到了一定的重视,在每次迭代学习后,对于分类器的训练也更充分。
51、其次,本发明集成了所有的tsk子分类器,这在提高疾病分类检测器稳定性和泛化性能的同时,也减少了数据过拟合的风险,采用集成学习技术有效地减缓了tsk模糊系统规则爆炸和规则增多带来的可解释性降低的问题,最终输出的结果简单直观,数据也具有高可解释性。
- 还没有人留言评论。精彩留言会获得点赞!