基于代谢组学的抑郁症判别模型的构建方法
本发明属于医疗模型构建,具体涉及基于代谢组学的抑郁症判别模型的构建方法。
背景技术:
1、抑郁症是最常见的抑郁障碍,以显著而持久的心境低落为主要临床特征,是心境障碍的主要类型。每次发作持续至少2周以上、长者甚或数年,多数病例有反复发作的倾向,每次发作大多数可以缓解,部分可有残留症状或转为慢性。
2、目前,临床上对于抑郁症的诊断方法主要依赖于精神科医生的主观评估,通过icd-10(国际疾病分类)或dsm-iv(精神疾病的诊断和统计手册)列出的诊断标准,对患者进行访谈、询问,同时结合phq-9等自评量表的结果进行综合评估。然而,临床上的这种主观评估方法太过依赖于医生的主观经验,同时存在检查效率低,耗时耗力等问题。
3、如公告号为cn116110567a的发明所公开的一种基于多模态信息的抑郁症的预测方法及相关装置,方法包括将所述语音数据输入所述预测网络模型中的语音特征提取模块,通过所述语音特征提取模块确定所述语音数据对应的语音特征;将所述文本数据输入所述预测网络模型中的文本特征提取模块,通过所述文本特征提取模块确定所述文本数据对应的文本特征;将所述语音特征及所述文本特征输入所述预测网络模型中的预测模块,通过所述预测模块确定所述抑郁数据的抑郁类别。上述申请采用包括语音特征提取模块和文件识别模块的多模态融合网络模型确定抑郁数据对应的抑郁类型,提高了抑郁症预测的准确性以及预测效率。
4、上述技术方案通过对患者的语音以及文本特征进行提取,并对患者的抑郁症类型进行判别,由于患者具有自主意识,语音特征以及文本特征作为判断的标准,其抑郁症判断的精确不足,不能精确判断患者的抑郁症类型,无法对患者后续的治疗进行调整,影响后续患者的治疗,为此我们提出基于代谢组学的抑郁症判别模型的构建方法。
技术实现思路
1、本发明的目的在于提供基于代谢组学的抑郁症判别模型的构建方法,以解决上述背景技术中提出的通过对患者的语音以及文本特征进行提取,并对患者的抑郁症类型进行判别,由于患者具有自主意识,语音特征以及文本特征作为判断的标准,其抑郁症判断的精确不足,不能精确判断患者的抑郁症类型,无法对患者后续的治疗进行调整,影响后续患者的治疗问题。
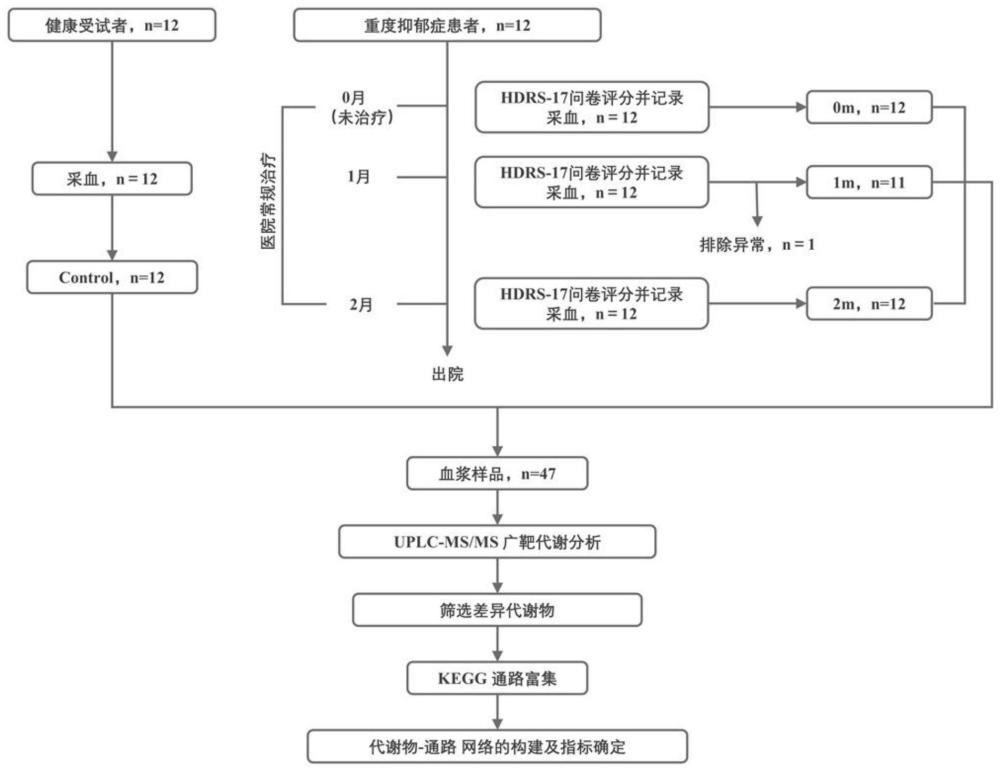
2、为实现上述目的,本发明提供如下技术方案:基于代谢组学的抑郁症判别模型的构建方法,包括如下具体步骤:
3、步骤一、对患者残留样本进行处理分析;
4、步骤二、对步骤一中分析的样本进行血浆代谢组分析;
5、步骤三、对血浆代谢组中的数据进行处理分析;
6、步骤四、对血浆代谢组的差异代谢物进行分析,并建立opls-da模型;
7、步骤五、根据opls-da模型,建立代谢物-通路网络;
8、步骤六,根据代谢物-通路网络确定指标信息。
9、优选的,所述步骤一中残留样本处理分析,具体如下:
10、采集的血样立即以3000r/min离心10min,分离血浆,在-80℃保存分析,将样品在冰上解冻,涡旋10秒,将300μl纯甲醇加入50μl血浆中,将混合物旋转3分钟,并在4℃下以12,000rpm离心10分钟。然后收集上清液并在4℃下以12000rpm离心5分钟,在-20℃的冰箱中放置30分钟,在4℃下以12000rpm离心3分钟,并在相应注射瓶的衬里中取150μl上清液进行机载分析。
11、优选的,所述采集的血样为在住院两个月期间,对具有正常医疗行为的mdd患者的常规月度样本中的残留血液样本。
12、优选的,所述步骤二中的血浆代谢组分析,分析过程如下:
13、使用uplc-ms系统分析样品提取物,液相条件:色谱柱为acquity uplc hss t3c18(1.8μm粒径,2.1mm内径,100mm长);柱温40℃;流动相a为超纯水(0.1%的甲酸),流动相b为乙腈(0.1%的甲酸);洗脱梯度:0分钟时为95:5v/v,10分钟时为10:90v/v,11分钟时为10:90v/v,11.1分钟时为95:5v/v,14分钟时为95:5v/v;质谱条件:电喷雾离子源温度设置为500℃,对于ms,在三重四极杆线性离子阱质谱仪(qtrap)上获取线性离子阱(lit)和三重四极杆(qqq)扫描,uplc-ms系统配备电喷雾电离(esi)涡轮离子喷雾接口,在正离子和负离子模式下运行,esi运行参数如下:电喷雾离子源温度500℃;电压5500v(正离子模式),-4500v(负离子模式),离子源气体i设置为55psi,气体ii设置为60psi,气帘气(curtain gas,cur)25psi,碰撞诱导电离(collision-activated dissociation,cad)参数设置为高;
14、分别在qqq和lit模式下使用10和100μmol/l聚丙二醇溶液进行仪器调谐和质量校准,根据该周期内洗脱的代谢物,监测多反应监测(mrm)通道。
15、优选的,所述步骤三具体为:基于自建的本地数据库,由analyst 1.6.3(ab sciexllc,美国马萨诸塞州弗雷明汉)对每个样品的提取离子色谱图(xic)进行初步处理,以获得样品中可检测物质的基本信息,包括rt和特征离子信号强度,使用multiquant软件对色谱峰进行积分和校正,峰面积代表相应物质的相对含量。
16、优选的,所述步骤四具体为:
17、采用主成分分析(pca)和正交偏最小二乘判别分析(opls-da)对原始数据进行初步分析。pca是一种用于无监督模式识别的多维统计分析方法,有助于初步了解组内样本之间的总代谢差异和变异程度。opls-da是一种结合偏最小二乘判别分析(pls-da)和正交信号校正(osc)的监督分析方法,可以消除不相关的差异,从而更好地筛选微分变量。分别利用r软件的base package和metaboanalyst进行主成分分析(principal componentanalysis,pca)和正交偏最小二乘判别分析(orthogonal partial least squares-discriminate analysis,opls-da)。分析opls-da模型的预测变量重要性(vip),结合单因素分析的p值或倍数变化,选择两组间差异代谢产物。接下来,使用京都基因和基因组百科全书(kegg,https://www.kegg.jp/)数据库对差异代谢物进行注释,以分析潜在的代谢物相关途径。
18、优选的,所述步骤五具体为:对sdms相对含量进行标准化和归一化,采用k均值聚类分析各组血浆中差异代谢物相对含量的变化趋势,找出可能与mdd发生发展相关的差异代谢物变异规律。最后,通过spearman关联分析探讨这些显著差异代谢物(sdms)与mdd严重程度之间的关系,并将相关代谢物和kegg通路整合到新的mdd相关代谢机制网络中。
19、优选的,所述步骤六具体为:complexheatmap(r)(版本2.2.0)用于生成热图。metaboanalystr(r)(版本1.0.1)用于opls-da分析。
20、统计分析使用spss(5.0版,ibm,armonk,ny,usa)进行。受试者的特征参数表示为平均值±sd,p值<0.05被认为具有统计学意义。
21、graphpad(版本8.3.0.)用于直方图绘制。cytoscape(版本3.7.2)用于关系网络图。
22、多元回归分析:f2(预期效应大小)=0.15,α(双尾)=0.05,功效水平=0.8,预测至少4或14种具有显着不同特征的代谢物。
23、与现有技术相比,本发明的有益效果是:
24、本技术对抑郁症患者机体代谢进行研究,确定抑郁症患者机体代谢异常,通过对患者机体异常代谢数据进行分析,能够客观以及准确的判断患者是否有抑郁症,改变了原有通过患者进行汉密尔顿抑郁量表评分或者语言特征以及文本特征判断抑郁症的方式,同时医生能够为患者制定相应的治疗方案。
- 还没有人留言评论。精彩留言会获得点赞!