基于机器学习算法的华法林抗凝质量和不良反应预测模型的构建方法及其应用装置与流程
本发明属于生物医学检测技术、药物治疗学领域,具体涉及一种基于机器学习算法的华法林不良反应预测模型的构建方法及其应用。
背景技术:
1、华法林等维生素k拮抗剂是目前临床上应用最广泛的抗凝药物,不同个体的华法林有效剂量差异较大。
2、华法林(苄丙酮香豆素,warfarin)是一种口服抗凝药物,它通过抑制依赖维生素k的凝血因子活化,抑制血栓形成。华法林已被广泛用于治疗和预防血栓栓塞事件,包括房颤(af)和缺血性中风。华法林的剂量因个体和人群而异,不同个体的华法林有效剂量差异较大,个体化差异往往导致抗凝不足或过量。这些原因,再加上缺乏最佳的华法林剂量建议,导致中国抗凝血药物的使用率非常低。抗凝质量以“治疗范围时间”(ttr)来衡量,抗凝治疗不足的患者更容易发生不良心血管事件。
3、相关研究表明,vkorc1和cyp2c9基因的多态性会影响华法林的剂量,华法林的个体差异与cyp2c9和vkorc1等遗传因素密切相关,但这些遗传因素的影响因种族而异。cyp2c9*2在白种人中的突变率超过10%;白种人的cyp2c9*3和亚洲人的突变率约为7.5~10%和3%。cyp2c9*2突变在亚洲人中非常罕见。既往观察性研究表明,cyp2c9 rs1057910和vkorc1 rs9923231与中国人群中的华法林剂量和出血风险相关。随着华法林的药物基因组学研究的进一步深入,华法林个体化用药逐渐成为可能,但目前基因指导华法林用药的有效性仍有争议。而且尽管有大量的研究,但华法林的不良反应及其与基因多态性的关系仍然是一个尚未解决的问题,还需要进一步的研究来验证基因型指导下的用药是否可以减少华法林不良反应的发生。
4、而机器学习作为人工智能领域的一个重要分支,在医学研究、药物不良反应预测方面的应用前景广阔,机器学习可以从庞大的数据集中挖掘隐藏的模式、关系和趋势,为医学研究提供有力的支持,可以通过分析药物与基因多态性、环境等因素之间的关系,提高预测药物不良反应的准确性,进一步提高用药效果,减少不良反应的发生。
技术实现思路
1、本发明的目的为针对上述现有技术的不足,提供一种预测模型的构建方法,本方法通过检测两个可能影响华法林药物反应的基因(cyp2c9*3和vkorc1c.1639g>a),评估基因型引导下的华法林剂量在中国非瓣膜性房颤患者中是否优于常规临床使用,并进一步收集整理临床资料和基因型信息,基于机器学习算法结合遗传数据和环境因素,提供一种华法林抗凝质量和不良反应的预测模型及其应用。
2、本发明的目的可以通过以下措施达到:
3、一种基于机器学习算法的华法林抗凝质量和不良反应预测模型的构建方法,包括以下步骤:
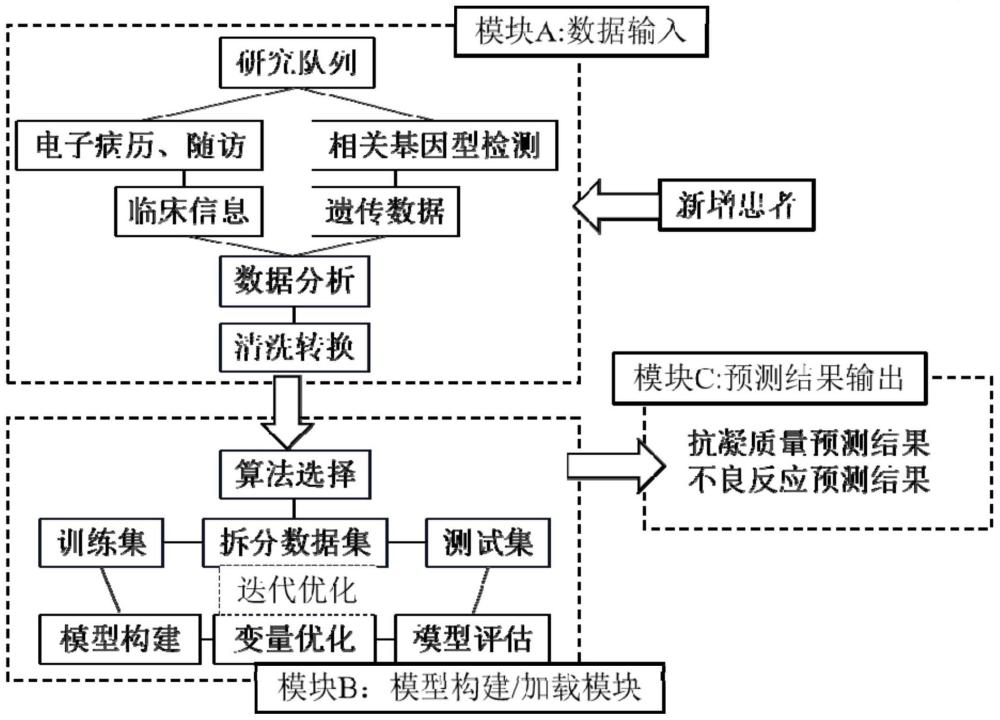
4、(1)数据获取:首先获取患者的临床数据,然后进行基因型检测和数据分析;其中数据分析包括华法林抗凝质量的评估、不良反应的评估及基因型对华法林抗凝质量和不良反应的影响,在所述基因型对华法林抗凝质量和不良反应的影响中设置精准治疗组和常规治疗组对比分析华法林基因检测指导用药对抗凝质量和不良反应的作用评估;
5、(2)模型构建:汇总步骤(1)的信息,进行数据清洗和转换,算法选择,拆分数据集,变量筛选和测试集模型评估;
6、(3)结果输出:依据步骤(2)所构建的模型输出抗凝质量预测结果和不良反应预测结果。
7、本发明在模型构建的过程中,充分考虑到患者后天因素作为混杂因素对基因多态性效应的影响,在数据获取中充分纳入患者基线期临床特征和评分进行矫正,以增强预测效果,其次本模型的构建针对不同预测目的,抗凝效果和药物不良反应设计了自动的模型优化模块,并不局限于某一中算法和单一的基因型检测变量,而是根据预测的目的识别加载最优的算法提高预测准确性。
8、在步骤(1)中,患者临床数据获取的方法包括:
9、s1.患者基线信息收集,两组患者用药前均记录患者的年龄、性别、体重、合并用药情况、伴随疾病、初始inr值、cha2ds2-vasc评分和hasbled评分等基线情况;
10、s2.根据国际华法林药物基因组学联盟(the international warfarinpharmaeogenetics consortium,iwpc)制订的华法林剂量预测算法计算华法林推荐剂量,随访中根据inr目标范围调整用药剂量,同时记录患者华法林稳态剂量(连续2次inr监测值在目标范围内,每次间隔天数>3天,定为稳态,稳态剂量为在稳态期内的平均剂量);
11、s3.统计两组患者治疗期间内发生的过度抗凝事件和其它不良反应发生事件。
12、在步骤(1)中,华法林基因检测方法包括:dna抽提/pcr扩增/基因测序,对cyp2c9*3(i359l,a>c)rs1057910和vkorc1(g-1639a)rs9923231位点信息进行检测分型。
13、在步骤(1)中,数据分析包括,华法林抗凝质量和不良反应的评估及基因型对华法林抗凝质量和不良反应的影响。
14、华法林抗凝质量的评估方法包括,接受抗凝治疗的患者的目标inr为1.8-3.0。患者的华法林抗凝质量均采用ttr(time in therapeutic range,治疗范围内时间)评估,ttr的测定方法为达标随访百分比,即在总随访次数中,达到目标inr次数所占百分比,患者于门诊定期进行inr指标监测,患者服药一周内进行第一次inr监测,根据监测的inr数值及随访情况调整随访次数,计算前1个月,前3个月,前6个月的ttr。
15、进一步地,华法林不良反应的定义为,患者治疗期间内发生的过度抗凝事件和其它不良反应发生事件,过度抗凝事件包括isth(international thrombosis andhemostasis association,国际血栓和止血协会)定义的大出血事件、小出血事件和inr>3.5事件,并记录发生时间,如患者多次出现出血或inr>3.5,以第一次发生时间为主,记录事件为1例;isth对大出血的定义为符合以下任意一条:1.血红蛋白下降≥2g/dl;2.输全血或浓缩红细胞成分血≥2个单位;3.关键部位出血:颅内,椎管内,眼内,心包内,关节腔内,筋膜室综合征的肌肉内出血,腹膜后;4.死亡。小出血事件为包括牙龈出血、非创伤性皮肤粘膜瘀斑、鼻出血、隐性的泌尿系出血、月经过多等以及其它任何未达到大出血标准的临床出血。其它不良事件包括肝和肾功能不全,过敏反应,皮疹,消化不良和发热。
16、基因型对华法林抗凝质量和不良反应的影响,即设置精准治疗组和常规治疗组对比分析华法林基因检测指导用药对抗凝质量和不良反应的作用评估,它包括:精准治疗组以基因检测推荐剂量为初始剂量,根据国际华法林药物基因组学联盟(the internationalwarfarin pharmaeogenetics consortium,iwpc)制订的华法林剂量预测算法计算华法林推荐剂量,随访中根据inr目标范围调整用药剂量。常规治疗组根据临床医师经验给予初始剂量,详细记录患者随访期间inr值,根据inr数值(≥75岁的患者目标inr范围控制在1.6~2.5之间,<75岁的患者目标inr范围控制在2.0~3.0之间)调整用药剂量。
17、本发明创新性设置基因指导用药的精准治疗组和经验用药组的常规治疗患者两组病例对照研究,分析基因检测与不良反应间的关系,明确非遗传因素对预测模型的影响,并通过boruta算法自动识别可能被临床遗漏的关键非遗传因素修正模型,进一步地不断动态修正,减少这些因素对基因型预测华法林抗凝和不良反应模型的影响。
18、本方法的步骤(2)中,模型构建包括:数据清洗和转换,拆分数据集,算法选择,变量筛选,训练集构建优化模型和测试集模型评估。
19、优选地,华法林抗凝质量和不良反应的预测模型的构建方法中机器学习构建算法包括随机森林(random forest),逻辑回归(logistic regression),线性判别式(lineardiscrimant),支持向量机(svm_radial)和人工神经网络(neuralnetwork)。自变量的选择包括:cyp2c9,vkorc1两个基因型,性别,年龄,身高,体重,华法林剂量,合并用药情况,吸烟史和饮酒史。因变量包括量化的华法林抗凝质量和不良反应。
20、模型的构建基于以下软件:r 4.2.3,r studio,ibm spss statistics 26,wpsoffice excel。
21、步骤(2)中,数据清洗和转换可包括以下具体步骤:首先,对自变量和因变量进行重编码,分析连续变量的数据分布类型,对不符合正态分布的数据进行转换便于逻辑回归模型构建,将字符型分类变量转换为数值型分类变量,结果变量统一转换为二分类变量;字符型分类变量编码的规则为:性别/gender:0=女,1=男;合并用药/concomitant_medication:0=无,1=有;高血压/hypertension:0=无,1=有;糖尿病/dm:0=无,1=有;吸烟史/smoke:0=无,1=有;饮酒史/drink:0=无,1=有;华法林有效性/effective:0=无效,1=有效;华法林药物不良反应/adr:0=未发生不良反应,1=发生不良反应。进一步地,重编码后构建的数据集释义字典如下表1所示。
22、表1重编码后构建的数据集释义字典
23、
24、步骤(2)中,进一步地进行数据格式化与清洗包括:将重编码后数据使用excel保存为utf-8编码的逗号分隔的csv文件,并导入spss统计分析软件中进行数据清洗,导入方法为:第一行包含变量名称,值之间的分隔符为逗号,小数符号为句点,文本限定符为双引号。在spss变量视图中检查变量测量类型和数据类型,是否与上一步字典中预设相同,如有不同进行改正,保存为sav格式文件,并重新输出csv格式文件,命名为emrs_raw.csv。
25、进一步地将数据导入到r中,使用在r studio软件使用read.csv加载“emrs_raw.csv”数据集,同时保存数据集为.rdata格式方便读取,使用as.factor在r中定义数据集中分类变量,以防报错。
26、进一步地进行变量单因素分析,包括变量地相关性分析,具体为:使用corrgram r包中的corrgram函数计算数据集中各个变量的相关性,并绘制相关性图,如图2所示,观察各变量之间的相关性,相关性计算的计算方法为spearman法。
27、进一步地进行缺失值的检查及数据插补,具体为:使用vim r包中的aggr函数统计数据集中的缺失值及缺失程度,如附图3所示,发现数据集中数据缺失比例少于30%,属于可插补范围,因此采用missforest r包中的missforest函数进行数据插补,使用set.seed函数固定随机种子数,使数据插补过程可以重复,并再次使用as.factor定义插补数据集中的分类变量。
28、步骤(2)中,进一步地,拆分数据集包括:在使用r studio在r语言中加载caret包,使用caret包中的createdatapartition函数,设置输出变量,将数据集以输出变量为准按7:3的比例随机划分训练集和测试集。进一步以指定的输出变量和输入变量构建模型的表达式。
29、进一步设置交叉验证参数,具体为:使用caret包中的traincontrol函数,设置重采样方法为“repeatedcv”,5折交叉重复10次进行验证。
30、进一步通过caret包中的train函数控制参数,分别基于5中算法构建模型,并计算敏感性、特异性、auc、准确度和kappa值。
31、测试集模型评估包括,使用predict函数分别评估五种算法使用训练集数据训练的模型在测试集中的性能,并使用proc包中的roc函数分别计算5种算法构建模型的roc曲线下面积,并绘制roc曲线,使用resamples函数对五个模型的敏感性、特异性、auc、准确度和kappa值进行综合比较,绘制包含95%置信区间的点图,选择出最优算法用于下一步模型构建。在一种方案中,可根据roc曲线下面积和准确度,kappa值最高,优选地在具体实施例中根据不同任务目的确定最优算法和最优变量,例如在实施例2中,基于最优算法和变量集构建的模型表达式为formula model_rf=adr~cyp2c9+vkorc1+cha2ds2_vasc+hasbled+hypertension+drink+dose+height+age+smoke,进一步在r中使用randomforest函数,使用训练集数据,设置参数importance=t输出权重,迭代次数iter=5,随机森林数量ntree=2000,进行模型构建。
32、步骤(2)中,优选的,变量筛选使用boruta包中的boruta函数进行变量筛选,使用getselectedattributes函数获取被boruta函数确认的输入变量,并使用经测试集评估的最优算法构建新的优化模型,例如在实施例2中,基于最优算法和变量集构建的模型表达式为formula model_rf=adr~cyp2c9+vkorc1+cha2ds2_vasc+hasbled+hypertension+drink+dose+height+age+smoke,进一步在r中使用randomforest函数,使用训练集数据,设置参数importance=t输出权重,迭代次数iter=5,随机森林数量ntree=2000,进行模型构建。并进一步评价最优模型的性能。
33、进一步地,使用在r studio中使用shiny将最优算法构建的模型部署在在线网站上,形成面向患者和医护人员的应用界面,便于输出模型的预测结果。
34、一种基于机器学习算法的华法林抗凝质量和不良反应预测方法的应用装置,它包括按本发明的方法依次设置的患者个人临床数据和基因检测数据的输入模块,模型加载与后台数据传递模块,结果输出模块包括抗凝质量预测结果和不良反应预测结果的输出模块。
35、本发明的有益效果包括:
36、按本发明的方法所构建的预测模型,可以根据预测目的和纳入的患者数据动态判断最优算法和包括遗传和非遗传因素在内的多元变量集合,基于在线网站迅速部署最优模型,快速、有效、高效地预测华法林临床抗凝效果和药物不良反应,提高临床医护人员和患者用药前和用药后的警惕,提高用药效果,减少药物不良反应的发生。当前研究表明,cyp2c9和vkorc1的基因多态性与华法林的用量相关,而现有技术手段仅有通过检测华法林抗凝治疗的患者cyp2c9和vkorc1基因型,给予计算的推荐剂量,手段单一,易受混杂因素影响,本发明突破性的结合boruta算法和caret r包中的resamples函数,动态选择适用于预测目的(如:华法林抗凝效果和药物不良反应)的最优算法和最优变量,构建函数表达式,排除混杂因素影响,弥补临床缺少对对华法林药物应用之后的有效性和不良反应的针对性的动态预测模型,本发明通过建立一种基于机器学习算法的华法林抗凝质量和不良反应预测模型及其应用装置,便于患者和医护人员预测华法林抗凝效果和药物不良反应,提高用药效果,减少不良反应发生本发明使用多算法比较、非遗传因素变量筛选和模型优化等多个过程,具有较高的准确性和预测效能,可以从一定程度上填补现有技术不足。此外本发明还开发一种面向用户的应用装置,便于患者和医护人员在使用华法林之前进行华法林抗凝效果和药物不良反应的评估。
- 还没有人留言评论。精彩留言会获得点赞!