一种面向在线问诊的人机协作分层强化学习方法及框架
本发明属于人机协作,具体涉及一种面向在线问诊的人机协作分层强化学习方法及框架。
背景技术:
1、随着互联网的普及和发展,互联网医疗应运而生,成为医疗行业的新兴领域,它有效地应对了我国医疗资源不均等和人们日益增加的健康医疗需求之间的不平衡。在线问诊作为互联网医疗的重要组成部分,提供了一种便捷的方式,使医生和患者能够通过在线咨询平台进行有效的交流。医生可以根据患者的症状描述来进行诊断,并提供治疗建议。随着移动互联网的迅猛发展,远程在线问诊变得越来越受欢迎,导致在线问诊平台的咨询量急剧增加,进一步推动了在线问诊的发展。这一发展趋势有望为更多人提供更方便的医疗服务,缓解了医疗资源不足的问题。
2、根据国民健康洞察报告显示,在线问诊服务在我国受到广泛的欢迎,其中82%的民众表示他们会使用这项便捷的医疗服务。在线问诊的主要用户群体包括个人和他们的父母。这一趋势的兴起主要是满足了用户在特定情境下的便捷需求,比如时间不方便的用户占比为42%,需要快速医疗响应的用户占28%,还有23%的用户会在多位医生之间咨询不同问题。在线问诊目前主要是线下医疗问诊的有益补充,它的主要作用之一是帮助用户降低了医疗咨询的成本。不仅用户,医生也逐渐愿意在在线问诊领域投入更多的时间。然而,目前有超过五分之二的医生每周的在线问诊时间不足3小时,只有15%的医生在线问诊时间超过20小时。实际上,医生有足够的潜力来提供更多的在线问诊服务,因为他们可以更好地安排自己的时间表以开展在线咨询。因此,在线问诊平台可以更充分地利用医生的宝贵资源,以满足不断增长的在线问诊需求,这意味着在线问诊领域仍有巨大的增长潜力。
3、目前,在线问诊可以分为两大类—基于人工和基于机器的两种方式。基于人工的在线问诊指的是利用线上问诊平台,如好大夫、平安健康、teladoc等,这种方法的优势在于医生具备丰富的医疗经验和知识,因此疾病诊断的准确性相对较高。然而,存在一些不足之处,包括医疗资源不足、医生工作负担重、患者等待时间长,以及相对高昂的医疗费用。而基于机器的在线问诊则采用了机器学习方法来培训智能系统,以进行在线问诊,例如左手医生智能自诊等。这种方法的优点在于用户可以随时随地进行健康自测,获取医疗相关信息,同时也能够减轻医疗资源的压力。然而,它也存在一些挑战,特别是在医疗领域对安全性和高风险决策有更高要求的情况下,完全依赖机器诊断可能不够可靠。
4、早期的研究可以追溯到1991年,当时hayashi等研究人员尝试从医学数据和人类知识中提取基于规则的表示,以用于医学诊断。随后的研究中,许多研究者采用了贝叶斯推理和基于决策树的方法来选择症状,例如kononenko等人的工作。然而,由于通常难以获得信息增益的全局最大值,这些方法经常采用贪婪或近似算法,这可能导致准确性较低。janisch等研究者的研究表明,深度强化学习方法在处理医疗对话诊断这种序列特征获取任务时表现优于基于决策树的方法。这一发现为tang等研究人员的工作提供了更具说服力的支持,后者首次使用强化学习来进行症状检查。此外,kachuee等人还进行了对经过训练的预测因子的敏感性分析,以评估在给定背景下每个特征的重要性,提出了一种基于深度q学习(deep q network,dqn)的方法,将模型不确定性的变化视为奖励函数的一部分。这些研究展示了深度强化学习在医学领域的潜力,为改进医疗诊断和症状检查提供了新的方法和视角。
5、在2018年,wei等研究人员开展了一项关于疾病筛查的对话系统的研究,他们使用了深度q学习(dqn)来收集症状信息并进行疾病诊断。然后在2019年,xu等研究人员提出了知识路由关系对话系统(kr-ds),该系统将知识图谱纳入对话管理,以融合额外的信息。需要注意的是,这些实验所使用的数据集仅包括4种疾病和60个症状。当疾病和症状数量增多时,传统的强化学习方法难以应对更大的动作空间,导致难以实现模型的收敛。为了克服这一挑战,2020年,liao等研究人员提出了一个分层强化学习框架。该框架包括一个主控制器(master),负责协调多个子控制器(worker)的工作,其中一些负责查询症状,另一些负责进行疾病筛查。随后,2021年,liu等研究人员通过引入预训练策略对这一框架进行改进,以克服模型训练中的困难。目前,2022年,he等研究人员提出了一个基于多模型融合的演员-评论家(mmf-ac)强化学习框架,进一步推动了这一领域的研究。尽管分层强化学习方法在大型数据集上取得了一些实验进展,但在实际医疗环境中,完全依赖机器难以同时保证准确性和安全性。
6、交互式机器学习侧重于机器学习中的训练过程和模型优化,以便人类可以引导机器学习方法以获得期望的结果。在这方面,chen等人提出了一种基于人机协作的医疗诊断系统,该系统通过深度强化学习(dqn)使机器能够向患者提出问题以了解症状,然后机器进行初步诊断。在机器问诊结束后,人类医学专家进行后续的复诊。然而,上述研究中存在一些限制,其中之一是人类专家的参与度相对较低。此外,人类专家的交互仅限于优化机器的输入或输出,而没有动态参与到模型的学习过程中。这可能导致了人类参与者的利用效率相对较低,因为他们的经验和知识未被充分整合到模型的训练和决策过程中。
7、目前现有技术中存在以下不足:
8、(1)基于人工的在线问诊需要医疗专业人员的全程参与,这不仅会消耗大量的医疗资源,而且也会导致人力劳动成本的上升。此外,还存在患者咨询数量过多和医生回答不及时的问题。
9、(2)基于机器的在线问诊致力于自动化疾病诊断,但是由于医学领域的人工智能仍处于发展早期阶段,因此可能存在诊断准确率低和可靠性差等问题,难以满足高风险问诊的需求。
10、(3)已有基于单一dqn算法实现的人机协作方法只能用于少数疾病的对话诊断。此外,在许多情况下,机器只能提供预诊断结果,仍需要医学专家进行复诊。这不仅增加了医生的工作负担,还降低了工作效率。
技术实现思路
1、本发明所要解决的技术问题是:
2、为了平衡基于人工和基于机器的两种问诊方式,本发明提供一种面向在线问诊的人机协作分层强化学习方法及框架。
3、为了解决上述技术问题,本发明采用的技术方案为:
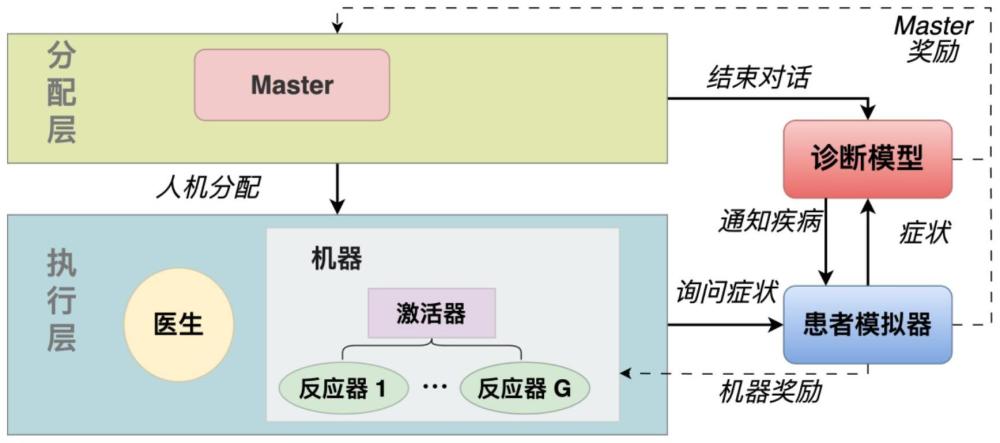
4、一种面向在线问诊的人机协作分层强化学习框架,其特征在于,包括:分配层、执行层、诊断模型和患者模拟器,所述分配层由master智能体组成;所述执行层由人类医生、激活器以及多个反应器组成;
5、所述master智能体:master智能体负责人机分配以及结束对话,其作用是合理分配人类资源和适时终止问诊;
6、所述人类医生:专家级的人类医生负责与患者对话询问症状;
7、所述激活器与反应器:激活器负责激活特定的反应器,每个反应器负责询问特定疾病组相应的症状;
8、所述患者模拟器:在深度强化学习训练和评估时,患者模拟器将问诊记录中症状的向量表示作为环境的初始状态,master智能体会据此状态选择动作;如果master智能体不结束对话,患者模拟器会根据患者问诊记录中的症状与人/机进行对话交互;具体而言,当人/机向患者模拟器询问某个症状,若此症状属于记录中的,患者模拟器反馈确定性回复“true”/“false”;若此症状不存在于结构化样本症状中,患者模拟器反馈未知回复“unk”;
9、所述诊断模型:如果master智能体选择停止对话,诊断模型将以患者确定性症状为输入,输出预测疾病类别。
10、一种面向在线问诊的人机协作分层强化学习方法,其特征在于,包括使用分配层进行人机分配和使用执行层进行症状询问;
11、所述使用分配层进行人机分配:将master智能体的分配过程定义为马尔可夫决策过程,表示为五元组<s,a,p,r,γ>,其中状态s为(症状,状态)二元组集合的向量表示;动作空间a不仅包括分配动作,还包括结束对话;当前状态st采取动作at后得到的奖励r(st,at)旨在协调人类投入率与诊断成功率;状态转移函数p(st+1|st,at)是未知的;折扣因子γ∈[0,1]用来计算未来总回报gt;
12、分配任务使用的强化学习方法不断更新策略π,最优的目标策略会最大化每个状态的价值函数:
13、
14、将问诊过程中症状询问这一间接目标分解为多个子任务,master智能体负责将这些子任务分配给人/机完成;子任务定义为人/机在ts对话轮次内向患者询问一个症状,若问到患者确定性症状,子任务成功结束,否则对话轮次超出ts则以失败结束。从患者的角度看,人类医生或机器会连续向患者询问若干症状,当患者确有/否定症状或连续次数超过一定限度,此人/机退出对话,重新分配的人/机将与患者进行交互,以此类推,直至对话结束;
15、master模块是人机协作问诊框架的核心部分,它直接控制人类投入与疾病诊断的平衡,其目标为在低人类投入下询问更多的确定性症状,并且使得系统接近疾病诊断的准确率上限;master智能体通过近端策略优化裁剪算法实现,演员策略的损失函数lclip通过对采样数据的平均值进行计算得出的,即对每个时间步t的损失取平均值,其具体表达式如下:
16、
17、其中,表示在单个时间步t上所有采样轨迹的损失期望估计值;rt(θ)表示在状态st时,新策略θ采取动作at与旧策略θold采取动作at的概率比值裁剪函数clip(·)将rt(θ)值限制在[1-∈,1+∈]之间,它与最小化函数min(·)目的是让当前策略的更新尽可能小,以避免带来过于剧烈的策略变化,从而保证算法的稳定性。优势函数at是一种衡量当前状态和动作相对于平均水平的优劣程度的函数,本发明使用广义优势估计来计算优势估计值
18、
19、其中,δt=rt+γv(st+1)-v(st)表示时刻t的时间步的td误差;γ是一个0至1之间的折扣因子,用于考虑未来奖励的价值,λ是一个0至1之间的参数,用于平衡高阶和低阶项的权重;t表示终止的时间步,t∈[0,t]为当前的时间步。状态s由所有症状的三维向量拼接而成,三维向量包括(1,0,0),(0,1,0),(0,0,1),分别表示症状“true”,“false”和“unk”的状态;动作a分为三种:调用激活器,调用人类医生与结束对话,前两者负责进一步询问症状,后者调用诊断模型做出最终的诊断结果;
20、复杂的奖励函数r旨在使得master智能体进行合理高效的人机分配,其奖励值为:
21、
22、其中,er表示人机在与环境交互过程中返回的外在奖励,ir表示用于策略探索的内在奖励,ph表示人类惩罚;当master调用人类医生时,增加的ph奖励用于平衡人类资源投入比;
23、所述使用执行层进行症状询问:将机器负责在对话过程中询问症状定义为马尔可夫决策过程,表示为五元组<s,a,p,r,γ>,其中状态s同样是症状sym的向量表示;动作空间a为来自symdia的全部症状;奖励函数r旨在鼓励向患者问到有效的确定性症状;与分配任务不同,这里使用的强化学习方法显式地学习q函数:
24、
25、当得到最优的状态动作函数后,智能体进入某一状态采取的最优动作为
26、使用两级的分层强化学习来实现完整的机器询问,两级强化学习框架的第一级为激活器,第二级为多个反应器,激活器和反应器均由dqn算法实现。
27、一种计算机系统,其特征在于包括:一个或多个处理器,计算机可读存储介质,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的方法。
28、一种计算机可读存储介质,其特征在于存储有计算机可执行指令,所述指令在被执行时用于实现上述的方法。
29、本发明的有益效果在于:
30、本发明提供的一种面向在线问诊的人机协作分层强化学习方法及框架,具有以下优点:
31、(1)本发明构建了一种基于人机协作的问诊框架,其中反应器负责执行大多数的简单任务,而专家医生负责执行小部分困难的任务,也就是说,在机器辅助问诊流程的基础上,专家医生可以高效灵活地与患者进行对话交互。本发明的总目标是在最小的人力资源消耗下,确保医疗疾病诊断的高准确率。
32、(2)当处理的疾病和症状增多时,单层的强化学习方法会因为动作空间增大而难以收敛。因此,为了实现高性能机器,本发明采用了分层强化学习方法。经典的分层强化学习方法没有考虑任务相关的先验信息,而本发明则将疾病的相似度作为先验知识,并将疾病分为不同的疾病组。在分层强化学习框架中,高层智能体负责激活正确的疾病组以调用低层智能体。
33、(3)本发明提出一种采用强化学习方法的分配策略,可让人类医生更高效地与患者交互,共同促进疾病诊断。为了提高人力资源利用效率,本发明设计的适应性奖励函数,以更好地引导人力劳动。此外,本发明还提出了一种早停策略,即当诊断模型认为症状信息已充足时就尽早结束对话,从而减少患者的不适。
- 还没有人留言评论。精彩留言会获得点赞!