基于甲基化序列的深度学习癌症风险预测方法及系统与流程
本发明涉及生物信息,尤其是一种基于甲基化序列的深度学习癌症风险预测方法及系统。
背景技术:
1、近年来出现了许多新型的癌症早筛技术,例如液体活检,这是一种非侵入性的新型辅助检测方法,在肿瘤的早期筛查诊断、疗效检测以及预后评估监测方面应用正越发广泛,具有较好的可接受性和实时检测能力。目前的液体活检对象主要包括:游离肿瘤细胞(ctc)、循环肿瘤dna(ctdna)、外泌体、循环rna、肿瘤相关血小板等。其中ctc和ctdna的检测是近年来发展最迅速的两个研究领域,显现出了较好的应用前景。其中ctdna是一部分特殊的细胞游离dna(cfdna),cfdna是指存在于外周血液的胞外游离dna,通过识别cfdna中的ctdna,即可进行识别肿瘤的特征信息。cfdna的检测便捷,不需要进行组织取样和其他创伤性检查,且方便通过定期检测实时监测肿瘤的变化和进展,具有高灵敏度,在肿瘤早筛领域的具有巨大的应用前景。基因组上的甲基化修饰是一种重要的表观修饰机制,它调控着基因的表达,因而,通过分析基因组dna甲基化修饰的特征,能够识别肿瘤的发生与发展。甲基化测序数据为癌症早筛提供了一种可靠的依据。
2、深度学习已经被广泛应用于基因组序列与癌症的研究。利用深度学习技术,可以处理复杂的基因组数据,从而进行癌症识别、癌症分类、预后预测等任务。被广泛使用的深度学习模型包括卷积神经网络(cnn)、递归神经网络(rnn)、长短期记忆(lstm)等,这些模型也会被交叉结合使用。但是传统模型的性能受限于注释数据的数量和质量,只能识别监督标签中包含的任务特异性信息,而难以学习基因组序列中包含的一般性深层语义,这就会限制他们在读段水平上检测肿瘤的性能。
技术实现思路
1、针对现有技术的不足,本发明提供一种基于甲基化序列的深度学习癌症风险预测方法及系统,目的是提高模型的预测精度。
2、本发明采用的技术方案如下:
3、本发明提供一种基于甲基化序列的深度学习癌症风险预测方法,包括:
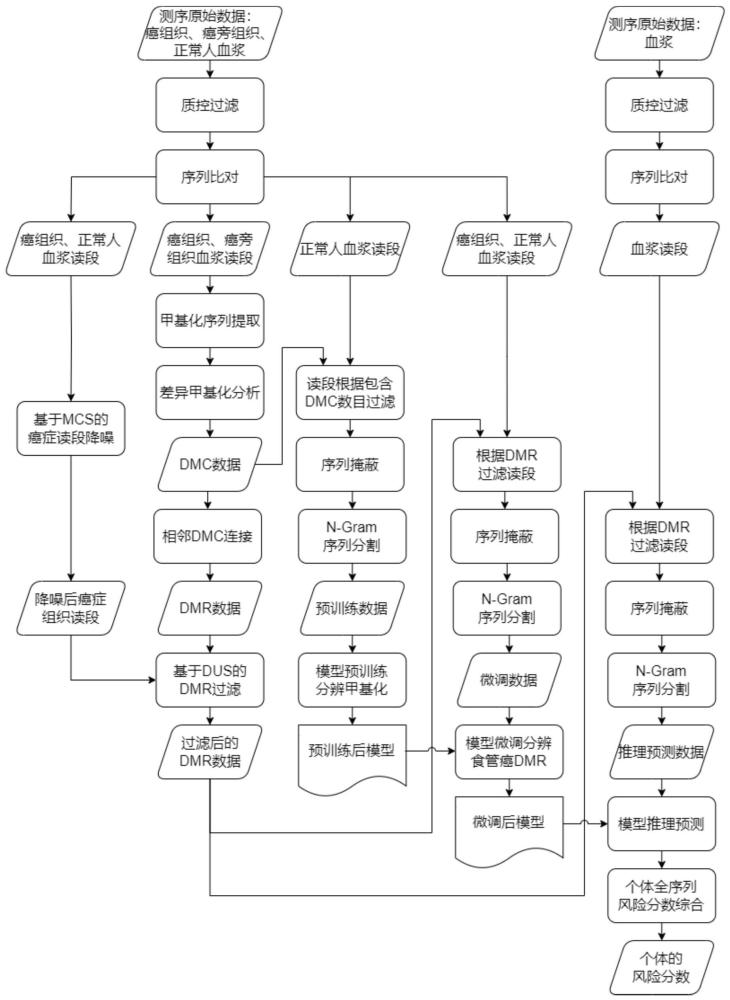
4、s1、对样本进行高通量全基因组甲基化测序,获取原始数据,通过质控、过滤和比对,获得样本的读段,基于所述读段进行甲基化序列提取,对不同样本的甲基化序列数据进行归一化;基于癌症组织和癌旁组织样本的甲基化序列数据进行差异甲基化分析,识别出差异甲基化cpg位点,筛选出所有的差异甲基化区域;所述样本包括癌症组织、癌旁组织和正常人血浆;
5、s2、对所述差异甲基化区域进行过滤,包括:
6、s21、使用滑动窗口法对所述癌症组织的读段进行降噪:对于每个所述差异甲基化区域,分别计算其在癌症组织读段中的甲基化连续性分数mcs、以及对应在正常人血浆读段中的最大和最小甲基化连续性分数smax和smin;如果一个差异甲基化区域在癌症组织中相对于癌旁组织是低甲基化的,那么剔除癌症组织读段中mcs大于等于smin的读段,得到保留读段;反之,如果该差异甲基化区域在癌症组织中相对于癌旁组织是高甲基化的,那么剔除癌症组织读段中mcs小于等于smax的部分,得到保留读段;
7、s22、选择过滤后覆盖足够多保留读段的差异甲基化区域,针对每个差异甲基化区域,计算dus指标:
8、n是样本个体总数,ti是个体i中过滤后的保留读段与过滤前总读段的比例,d是ti>0的个体占个体总数的比例;
9、将这些差异甲基化区域按dus值从大到小排序,按照排序结果选择出过滤后的差异甲基化区域;
10、s3、建立预测模型:
11、s31、模型预训练:对步骤s1获得的正常人血浆的读段进行过滤、合并,选出包含三个及以上差异甲基化cpg位点的序列,并对每个甲基化cpg位点的“cg”,使用“ml”进行替换标记,然后掩码处理后作为深度学习网络模型的输入序列,使用掩码语言模型任务来预测掩码标记,输出去除掩码标记的序列,获得学习甲基化序列上下文信息的预训练模型;
12、s32、对预训练模型进行微调训练:在s1获得的所有样本读段中提取所述过滤后的差异甲基化区域上的所有读段,并对高甲基化cpg位点中“cg”使用“ml”进行替换标记,将其中对应于癌症组织的序列标记为“1”,对应于自正常人血浆的序列标记为“0”,使用标记后的序列进行微调训练,获得预测模型;
13、s4、利用所述预测模型进行肿瘤风险预测,将待预测的甲基化序列数据输入所述预测模型中,获得预测风险值:
14、
15、其中,pi是预测到的第i个待预测甲基化序列来自癌症组织的概率,t是定义的概率阈值。
16、进一步技术方案为:
17、所述过滤后的差异甲基化区域包括dus值排名靠前的若干低甲基化差异甲基化区域和所有高甲基化差异甲基化区域。
18、步骤s21中,所述甲基化连续性分数的计算公式为:
19、
20、其中,l是读段中的差异甲基化cpg位点的数量,连续i个差异甲基化cpg位点组成一个区块,ni是读段上包含i个差异甲基化cpg位点的区块的数量。
21、所述深度学习网络模型的结构为基于transformer的双向编码器表示模型,包括一个嵌入层、多层transformer编码器;
22、所述嵌入层学习嵌入矩阵,将每个词映射到一个固定长度的实值向量,这些向量捕捉词的语义和上下文信息,并在连续向量空间中表示词之间的关系;
23、每个transformer编码器层由多头自注意机制和前馈神经网络组成,所述多头自注意机制允许同时考虑输入序列中的所有位置,捕捉上下文关系,同时并行学习多个注意力特征,捕捉不同粒度的语义信息。
24、所述深度学习网络模型的输入序列,采用n-gram方法被分词为包含上下文信息的多个连续碱基,并添加标记符[cls]作为输入序列的第一个标记符,用于表示整个序列的起始信息。
25、所述深度学习网络模型的每个输入序列掩盖包含“ml”的80%的词。
26、步骤s1中,将fdr多重假设检验校正后p值小于0.01,且甲基化差异大于25%的cpg位点定义为差异甲基化cpg位点;将包含至少五个所述差异甲基化cpg位点,且相邻差异甲基化cpg位点之间的距离不超过设定值的区域定义为一个所述差异甲基化区域。
27、本发明还提供一种基于甲基化序列的深度学习癌症风险预测系统,包括:
28、筛选模块,对样本进行高通量全基因组甲基化测序,获取原始数据,通过质控、过滤和比对,获得样本的读段,基于所述读段进行甲基化序列提取,对不同样本的甲基化序列数据进行归一化;基于癌症组织和癌旁组织样本的甲基化序列数据进行差异甲基化分析,识别出差异甲基化cpg位点,筛选出所有的差异甲基化区域;所述样本包括癌症组织、癌旁组织和正常人血浆;
29、过滤模块,对所述差异甲基化区域进行过滤,包括:
30、使用滑动窗口法对所述癌症组织的读段进行降噪:对于每个所述差异甲基化区域,分别计算其在癌症组织读段中的甲基化连续性分数mcs、以及对应在正常人血浆读段中的最大和最小甲基化连续性分数smax和smin;如果一个差异甲基化区域在癌症组织中相对于癌旁组织是低甲基化的,那么剔除癌症组织读段中mcs大于等于smin的读段,得到保留读段;反之,如果该差异甲基化区域在癌症组织中相对于癌旁组织是高甲基化的,那么剔除癌症组织读段中mcs小于等于smax的部分,得到保留读段;
31、选择过滤后覆盖足够多保留读段的差异甲基化区域,针对每个差异甲基化区域,计算dus指标:
32、n是样本个体总数,ti是个体i中过滤后的保留读段与过滤前总读段的比例,d是ti>0的个体占个体总数的比例;
33、将这些差异甲基化区域按dus值从大到小排序,按照排序结果选择出过滤后的差异甲基化区域;
34、建模模块,建立预测模型:
35、模型预训练:对步骤s1获得的正常人血浆的读段进行过滤、合并,选出包含三个及上差异甲基化cpg位点的序列,并对每个甲基化cpg位点的“cg”,使用“ml”进行替换标记,然后掩码处理后作为深度学习网络模型的输入序列,使用掩码语言模型任务来预测掩码标记,输出去除掩码标记的序列,获得学习甲基化序列上下文信息的预训练模型;
36、对预训练模型进行微调训练:在s1获得的所有样本读段中提取所述过滤后的差异甲基化区域上的所有读段,并对高甲基化cpg位点中“cg”使用“ml”进行替换标记,将其中对应于癌症组织的序列标记为“1”,对应于自正常人血浆的序列标记为“0”,使用标记后的序列进行微调训练,获得预测模型;
37、预测模块,利用所述预测模型进行肿瘤风险预测,将待预测的甲基化序列数据输入所述预测模型中,获得预测风险值:
38、
39、其中,pi是预测到的第i个待预测甲基化序列来自癌症组织的概率,t是定义的概率阈值。
40、本发明的有益效果如下:
41、本发明使用甲基化序列数据作为预测癌症风险的依据,为个体化精准医疗提供了基础。通过分析个体的基因组甲基化序列的独特特征,能够针对性地识别肿瘤的发生、发展,为患者提供个性化的治疗方案。
42、本发明通过统计学方法,分析不同来源的基因组序列中甲基化水平有明显差异的“差异甲基化cpg位点(dmc)”,继而得到“差异甲基化区域(dmr)”。在此基础上通过原始读段降噪,根据dus评分进一步对dmr进行过滤获得优化的dmr,通过将优化的dmr作为输入特征,深度学习模型可以更精确地学习到癌症相关的特征模式,模型可以在学习甲基化语义特征的基础上,利用优化的dmr序列数据微调,从而具备较高的预测准确性和泛化能力。使用传统统计学方法与深度学习模型结合,充分利用了两者的优势,能够更好地解决癌症基因组分析中的复杂问题。
43、本发明对甲基化序列上下文的特征提取,更符合甲基化修饰的生物学作用,能够提高准确度。甲基化序列与自然语言有着很高的相似性,序列之间存在上下游相互作用,正如自然语言存在上下文相互关系,其中蕴含了关键的序列特征信息。不同于常用的cnn、rnn、lstm等深度学习模型,本发明从大量未标记的数据中学习通用的理解,即预训练,而后再根据具体的特定任务数据,来进行推理预测的应用,即微调训练。这样的方法不仅具有更高的准确度,能学习到更加复杂抽象的特征,而且容易适配不同的特定任务,例如在预训练学习了甲基化序列语义特征后,只需经过特定癌症类型的较少量数据的微调训练,即可依据甲基化序列对该类癌症进行风险预测。
44、本发明的其它特征和优点将在随后的说明书中阐述,或者通过实施本发明而了解。
- 还没有人留言评论。精彩留言会获得点赞!