一种基于智能手环数据的驾驶员活动状态递进式判别方法
本发明属于智能穿戴设备,人体活动识别,汽车辅助驾驶,尤其涉及一种基于智能手环数据的驾驶员活动状态递进式判别方法。
背景技术:
1、交通安全一直是交通领域不可忽视的问题。特别是客运、货运职业驾驶员,安全大于一切,属于典型的“高承压,强负荷”职业,其安全监测问题一直受到国家和各运输企业的重点关注。近年来,针对驾驶员的安全问题,已逐渐形成了各种安全措施,并集成了车载安全系统,该系统一般包括:车载adas系统、车载dms系统、gps定位系统。
2、但通过大量的事故分析发现,许多事故的发生原因具有隐匿性,即隐性的驾驶嗜睡和精神疲劳,目前针对这方面的监测手段还非常有限,其中包含以智能手环为核心的全天候智能健康监测系统,以及可穿戴式心生理监测系统。但在目前的实际应用中,由于平台流量限制、车载环境限制和设备能耗等问题,许多数据无法做到实时上传和存储,特别是穿戴式设备,其数据的高频性和不稳定性给相关研究带来很大阻碍。
3、以智能手环为例,驾驶员被要求全天候佩戴以全面评估驾驶员的身体健康水平,但从安全的角度出发,驾驶状态下,需要实时传输数据,以配合车载安全系统,实时评估驾驶员在途状态,实现驾驶风险预测和预警;在日常状态下,不需要实时数据传输,但其日常数据应用于构建佩戴者生理画像,完成佩戴者基线标定及个性化模型生成;在睡眠状态下,智能手环用于佩戴者的睡眠监测,通过光电容积描记技术获取脉搏波,进而进行睡眠阶段分类。
技术实现思路
1、本发明设计了一种基于智能手环数据的驾驶员活动状态递进式判别方法,先通过姿态数据进行状态初判,然后结合生理数据进行精确判定,实现递进式判别,有效地识别驾驶员状态,避免传统方法仅依赖姿态数据进行识别,无法区分乘员和驾驶员,且识别精度不高的问题;同时也为进一步评估驾驶员的驾驶风险、对驾驶员长周期生命管理提供先决条件。
2、国际睡眠医学将睡眠阶段分为五期:入睡期、浅睡期、熟睡期、深睡期、快速眼动期。每个阶段的持续时间和发生次数均对人体第二天的活动能力有显著影响,用于评估驾驶员驾驶能力。另外,在驾驶、日常、睡眠三类不同状态下,驾驶员的精神紧张和压力、身体活动水平、以及交通环境给予人的反馈都是不同的。
3、本发明提出一种基于智能手环生理和姿态数据的递进式状态判别方法,用于识别驾驶、日常、睡眠三类不同状态,并且先利用姿态数据初判佩戴者状态,然后在识别模型中添加生理因素进行精确判定,将极大降低设备能耗,提高工作效率,提升判别模型的鲁棒性。
4、对本发明中驾驶员活动状态进行特别解释和定义:本发明中将驾驶员活动状态分为驾驶状态、日常活动状态和睡眠状态三类,驾驶员的日常活动状态和睡眠状态对个人情绪、精力、驾驶适宜性均有较大影响,对这三种状态进行判别,为评估驾驶能力、驾驶员长生命周期健康管理、不同活动状态下的进一步研究以及更精准的驾驶在岗风险评估提供先决条件。
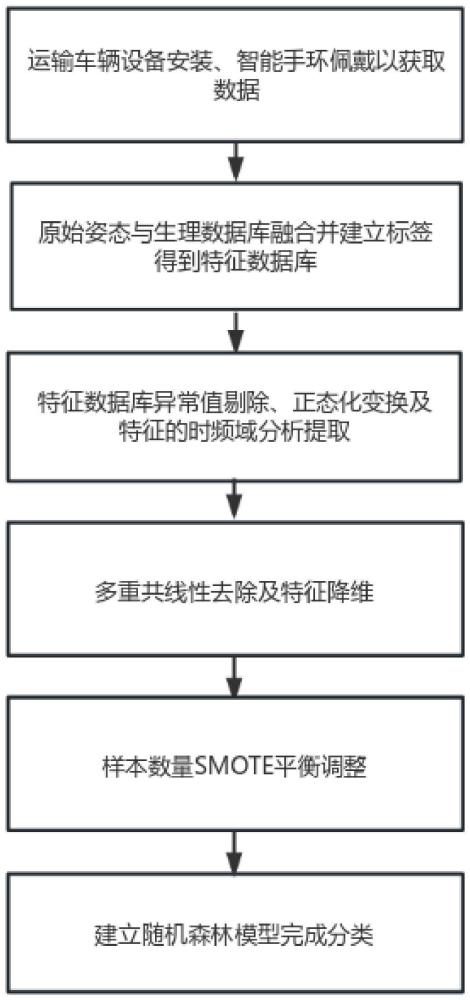
5、一种基于智能手环数据的驾驶员活动状态递进式判别方法,包括两部分,第一部分:基于智能手环的数据采集及特征数据库建立方法。第二部分:基于特征数据库的数据特征工程、模型选择及递进式模型建立方法。
6、进一步,所述第一部分基于智能手环的数据采集及特征数据库建立方法,其特征是:包括以下步骤,且以下步骤顺次进行:
7、步骤s1:将数据获取系统安装在试验车上,在云端获取车辆及驾驶员的数据信息,得到的信息类型包括:手环获取的驾驶员生理和姿态数据、摄像头获取的驾驶员图像数据、gps获取的车辆位置数据,且所有数据均有时间戳。
8、根据所述条件建立特征数据库步骤如下:
9、步骤s2:利用智能手环和车载gps获取驾驶员驾驶任务途中的数据。开发自动标注算法,获取车辆连续驾驶样本,本发明定义连续驾驶截止时间tc=600s,获取到驾驶状态标签数据;由驾驶员自我报告每天的睡眠时间,获取驾驶员睡眠状态标签数据。
10、进一步,步骤s2所述自动标注算法包括以下步骤:
11、对数据集a和数据集b进行融合,由于数据采样频率不同,需要对数据进行重采样,目标数据集为智能手环数据集,因此主数据集为a,副数据集为b。首先在数据集b中添加[mask]标记列,并将[mask]列数值全部初始化为1。
12、在数据集融合前,需要将数据集a中和数据集b中time转化为时间戳,时间精度到达毫秒的选择13位时间戳,不足毫秒的选择10位时间戳。
13、利用pandas中的merge方法,将数据集a和数据集b融合为数据集c。
14、接下来是进行数据请洗。
15、此时融合数据集c中包含a和b中的所有数据,且数据集c中所有低频数据集已经被升采样,此时mask列包含nan和1。
16、创建一个series来存储mask列中数值为1的行的索引。形成series[s1,s2,s3,...,sn],n∈n*。
17、定义tc为连续驾驶截止时间。具体来说,如设置tc=600s,则含义为车辆因交通信号灯、交通拥堵导致的停车时间小于600s时,系统仍判定驾驶员处于连续驾驶状态。
18、此时,以所有sn-sn-1)>tc做隔断,获取到原始连续驾驶样本并标记。
19、完成标记的数据集c含有驾驶状态标签,继承给dataset,其元素包含[a11,a12,a13,...,a1n,a21,a22,a23,...,a2n,b1,b2,b3,...,bn],n∈n*,成为数据处理和后续特征工程的基础数据库。
20、步骤s3:将所述步骤s1中获取到的所有数据以及所述步骤s2获取到的驾驶状态标签数据和睡眠状态标签数据与原数据结合得到带有标签的原始数据集,并对获取到的带有标签的原始数据集进行预处理,对获取到的数据的每个维度进行box-cox变换(box-coxtransformation)以获取正态化数据,然后根据高斯分布3σ原则,对数据异常值进行处理,并对处理后的数据集进行插值,获取到原始特征数据库。
21、进一步,所述步骤s3对获取到的带有标签的原始数据集进行预处理,包括以下步骤,包含以下步骤:
22、步骤s3-1:对各特征x1x2,x3,......,xn进行box-cox变换(box-coxtransformation)以获取正态化的特征数据x1,x2,x3,......,xn。
23、xi=((xiλ)-1)/λ,λ≠0,i=1,2,3,...,n
24、xi=ln(xi),λ=0,i=1,2,3,...,n
25、式中,x代表原始数据集中的观测值;λ是一个参数,可以是任意实数,用于控制变换的形式;x是经过box-cox变换后的值;
26、步骤s3-2:根据高斯分布3σ原则,数据落在3σ范围内的概率应该高于一定比例,该比例对应高斯分布概率密度函数在范围内的积分。范围外的点视为异常点剔除。以下为高斯分布3σ范围对应的概率密度积分:
27、
28、式中,p表示概率,μ表示均值,σ表示标准差;步骤s3-3:对剔除后的特征数据集进行三次样条插值,采用三次多项式作为插值函数,在每个区间[xi,xi+1]上,表示为:
29、s(x)=ai+bi(x-xi)+ci(x-xi)2+di(x-xi)3。
30、式中ai,bi,ci,di是插值多项式的系数,需要根据插值条件来确定x是自变量,xi是当前区间的起点。
31、步骤s3-3:剔除后的特征数据集出现了一些缺失值,并且在数据采集的过程中,也存在一些丢失的样本点,因此对剔除后的特征数据集进行三次样条插值,原理如下:
32、三次样条插值基于两个基本条件:
33、1.插值条件:曲线s(x)必须经过所有给定的数据点,即s(xi)=yi。
34、2.光滑性条件:曲线s(x)在相邻区间[xi,xi+1]的连接处必须一阶导数连续且二阶导数连续。
35、本发明采用三次多项式作为插值函数,在每个区间[xi,xi+1]上,我们可以表示为:
36、s(x)=ai+bi(x-xi)+ci(x-xi)2+di(x-xi)3。
37、式中ai,bi,ci,di是插值多项式的系数,需要根据插值条件来确定x是自变量,xi是当前区间的起点。
38、进一步,所述的第二部分,基于特征数据库的数据特征工程、模型选择及递进式模型建立方法,包括以下步骤,且以下步骤顺次进行:
39、步骤s4:考虑到姿态数据与生理数据的先验知识,为了获得更多的信息以及更丰富的特征表示,本发明根据不同特征的特点,采用时域、频域的特征提取方法,从基本特征中分析时域、频域特征,从原始数据中提取更多的信息,将数据映射到不同的表示空间,更好地捕捉数据中的模式和结构;
40、进一步,步骤s4的时域、频域特征提取包含以下特征:
41、心率:统计特征:均值、标准差、最值。频域特征:使用傅里叶变换进行频域变换,提取频谱能量特征。
42、血压:统计特征:舒张压和收缩压的均值、标准差、最值。压力脉动特征:舒张压和收缩压之间的差异或差异的变化,计算脉压差、脉压差的变化率。
43、脉搏:统计特征:计算脉搏波前面积和后面积的均值、标准差、最值。
44、rr间期(r-r interval):统计特征:计算rr间期的均值、标准差、最值。心率变异性特征:分析rr间期的时间间隔和变化模式来提取心率的变异性信息,均方根差、总功率、高频能量。
45、腕部三轴加速度:统计特征:计算每个轴的加速度信号的均值、标准差、最值。时域特征:提取加速度信号的时域特征,峰值个数、绝对平均值。频域特征:使用傅里叶变换进行频域变换,提取信号能量和频谱峰值特征。
46、步骤s5:在特征数过多的情况下容易产生维度灾难,因此本发明使用了ccm与vif联合的多重共线性去除方法,首先对特征集进行相关系数矩阵(correlation coefficientmatrix-ccm)计算,在阈值0.8的情况下去除相关性特征得特征集a1,对原始特征集计算方差膨胀因子(variance inflation factor-vif),阈值选择5,去除相关特征,得特征集a2,取特征集a1,a2的交集得到最终的特征集a;
47、进一步,相关系数矩阵法计算的是特征两两之间的相关性,方差膨胀因子计算的是单个特征与特征库内其他所有特征的相关性。因此步骤s5所述本发明前后分别使用ccm、vif多重共线性去除方法(顺序不可改变),同时具备去除特征两两之间的共线性以及去除单特征与特征库内其他特征的共线性的能力。
48、步骤s6:在将特征输入到模型之前,通常不希望预先给每个特征不同的期望,即希望每个特征在模型中的重要性是相同的,因此,采用最小-最大规范化(min-maxnormalization)方法对特征进行归一化;
49、进一步,通过以下公式将每个特征值映射到[-1,1]的范围:
50、x′=2*(x-min(x))/(max(x)-min(x))-1
51、式中,x'是归一化后的特征值,x是原始特征值,min(x)是特征向量x中的最小值,max(x)是特征向量x中的最大值。
52、步骤s7:经过特征工程及多重共线性去除后的特征矩阵仍有较高的维度,在建模之前,需要进行特征降维,本发明采用主成分分析(principal component analysis,pca)方法,提取特征集的协方差矩阵,对协方差矩阵采用特征值分解方法,对特征维度进行重规划;
53、进一步,所述步骤s7中,主成分分析方法包括以下步骤:
54、步骤s7-1:对数据进行零均值化,即减去每个特征的均值;
55、步骤s7-2:计算数据的协方差矩阵c:
56、c=(1/n)*xt*x
57、式中x表示原特征矩阵,xt表示原特征矩阵的转置矩阵,n代表观测值的数量。
58、步骤s7-3:对协方差矩阵c进行特征值分解,得到特征值和对应的特征向量,特征值代表了数据在对应特征向量方向上的方差,设特征值为λ1,λ2,...,λp,并按照大小排列;
59、选择前k个最大的特征值所对应的特征向量,构成一个特征向量矩阵v(k×p),这些特征向量称为主成分,表示了数据在原始特征空间中的最重要的方向;
60、步骤s7-4:将零均值化后的数据矩阵x乘以特征向量矩阵v,得到降维后的特征矩阵y(n×k):
61、y=x*vt
62、式中,y的每一行表示一个降维后的样本,对应于p维原始特征向量的前k个主成分。
63、步骤s8:使用姿态数据进行驾驶员状态初判,训练集和测试集划分比例为4:1。
64、步骤s9:在训练集构建过程中,由于正负样本数量差异大,采用少数派过采样技术(synthetic minority over-sampling technique-smote)平衡正负样本比例,然后进行训练,得到状态初判结果。
65、步骤s10:结合姿态数据和生理数据进行二次判别,由于融合数据库拥有较高的特征维度,并且融合效果具有隐匿性,本发明采用随机森林分类方法,建立多个弱分类器,将重规划后的特征矩阵作为模型输入,随机森林中的决策树数量选择100,决策树分支选择采用基尼系数,最终以各分类器分类结果投票得出最终分类结果,并启用袋外样本(out-of-bag-oob)进行验证。
66、进一步,所述步骤s10中的随机森林分类器的构建过程为:
67、步骤s10-1:从原始训练数据集中随机有放回地抽取n个样本,形成一个新的训练集,称为随机样本集;
68、步骤s10-2:针对所述步骤s10-1的随机样本集,构建决策树,在构建每个决策树的过程中,从原始特征集中随机选择一部分特征,同时使用基尼不纯度来选择最佳分裂点;
69、步骤s10-3:对于每个决策树,根据输入特征,沿着树进行遍历,最终落在叶子节点上,每个叶子节点对应一个类别,最终将所有决策树的预测结果进行投票,得到最终的预测类别。
70、进一步,步骤s9、s10所述的驾驶员状态递进式判别方法,初判使用的是姿态数据,二次判别使用的是姿态与生理融合数据。
71、本发明的一种基于智能手环数据的驾驶员活动状态递进式判别方法具有以下优点:
72、1.本发明提出的基于智能手环的数据采集及特征数据库建立方法,解决了当前对于智能手环姿态和生理数据预处理、数据库建立流程不确定、不规范问题,为后续特征工程、模型训练提供良好的原始数据环境。
73、2.本发明提出的基于特征数据库的数据特征工程、模型选择及递进式模型建立方法。解决了现有识别模型单模态导致的识别精度不高、模型鲁棒性低问题,为状态高精判别、进一步评估驾驶疲劳风险提供先决条件。
- 还没有人留言评论。精彩留言会获得点赞!