一种快速识别药物标识位点的系统及其应用的制作方法
本发明属于生物学与精准医学基因组变异检测,具体涉及一种快速识别药物标识位点的系统及其应用,尤其涉及通过优化生物信息学算法从大量变异位点中筛选出有临床药物关联的变异位点,从而提高医学解读效率的方法。
背景技术:
1、高通量测序(nextgeneration sequencing,ngs)能够同时对上百万甚至数十亿个dna片段进行测序,因此可以在较低的成本下对多至上百个肿瘤相关基因、全外显子及全基因组进行检测。ngs进行肿瘤基因突变检测的技术路线主要包括:全基因组测序(wgs)、全外显子测序(wes)和靶向捕获测序(targeted sequencing)。其中靶向测序是指选择基因组上感兴趣的基因或基因区域作为靶向检测区域,可以是几个基因上的个别外显子区域,也可以是几百上千个基因上的全部外显子区域,靶向测序兼顾了实际检测需求,又降低了测序成本,因此目前在临床上的应用广泛。
2、在肿瘤检测方面,基于靶向捕获测序技术寻找与患者高度相关的基因突变已经成为了一种常见且有效的诊断方案,目前市面上已经有很多款针对不同肿瘤类型、不同基因、不同捕获区域的检测基因组合(panel)。这些检测基因组合的一般性方案都是使用患者的肿瘤部位dna和正常部位dna构建测序文库,样本类型可以是组织,也可以是外周血或cfdna等,然后进行靶向捕获测序,之后对测序数据进行生物信息学分析并寻找与疾病关联的基因变异。这种方法在实际操作中,与疾病相关的变异位点的筛选是一个非常耗时且需要丰富临床解读知识的过程,如果不能够对相关的肿瘤在基因层面致病原理有足够的了解、不能对相关药物和药物标识变异位有深入的认知、以及快速有效去除假阳性干扰位点的能力,那么处理一例患者样本将会是耗时费力且没有保障的工作。
3、目前从大量的变异位点中筛选出真正与疾病相关的变异位点、从而根据变异位点选择合适的药物,这一过程基本都是人工对变异位点进行逐一解读后完成的,这既低效又依赖于解读人员的主观认知,往往出现同一个变异位点在不同的解读人员解读后出现不同的结论,在临床上的复用性不够。因此提供一种协助医学解读人员快速识别有用药指导变异位点的方法在肿瘤检测方面中具有重要的应用价值。
技术实现思路
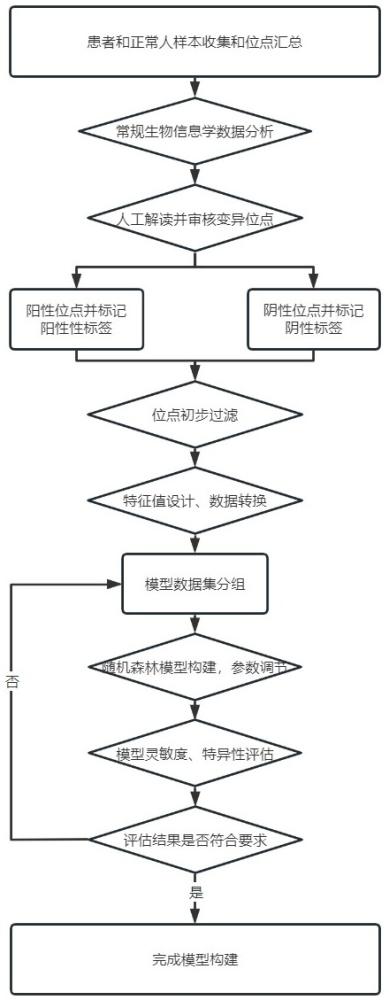
1、针对现有技术存在的不足,本发明的目的在于提供一种快速识别药物标识位点的系统及其应用。本发明使用随机森林的算法构建生物信息分析模型,通过大量经过人工解读的位点信息做基础数据,收集了每个变异位点的近百种特征值信息,模型利用这些数据创建出一组不再依赖解读人员主观知识的数据库,后期其他样本的分析基于该模型即可。
2、为达到此发明目的,本发明采用以下技术方案:
3、第一方面,本发明提供一种快速识别药物标识位点的系统,所述系统包括:
4、(1)数据收集单元:收集疾病患者和正常样本的基因组合测序数据,筛选阳性位点和阴性位点;
5、(2)数据筛选单元:设置特征值,根据特征值从测试样本中筛选与患者疾病相关的致病性变异位点,作为模型数据集;所述特征值如下所示:
6、
7、;
8、(3)模型构建单元:将模型数据集分为训练集和测试集,采用随机森林法构建生物信息分析模型。
9、本发明选择的特征值是能够反映链偏好性、变异位点在读段中坐标位置比例、参考碱基和变异碱基质量值、读段比对质量值、变异碱基距离读段末端距离、读段发生软剪接等都能够对构建模型起到十分重要的作用。
10、本发明中,读段(读段)指的是测序仪单次测序所得到的碱基序列,也就是一连串的atcgggta之类的,不同的测序仪器,读段长度不一样。对整个基因组进行测序,就会产生成百上千万的读段。
11、优选地,所述数据收集单元中,与疾病和药物有关联的变异位点作为阳性位点。
12、优选地,与疾病和药物无关联的位点作为阴性位点,含有阴性位点的样本定义为阴性样本。
13、优选地,所述数据收集单元中,对阳性位点阴性位点进行筛选,去除部分容易区别的且普遍采用的过滤指标的假阳性位点。
14、优选地,去除部分假阳性位点的过滤指标包括:
15、(a)注释变异位点的功能区域后,去除位于内含子区、基因间区和非编码rna内含子区的变异位点;
16、(b)去除在clinvar数据库中标记为影响、关联、良性、良性/疑似良性、疑似良性、无注释、其他、保护、风险因子、对致病性解释相互矛盾、可能为良性/药物反应/其他、可能良性/其他字符的变异位点;
17、(c)去除在intervar软件中注释为良性、疑似良性的变异位点;
18、(d)注释人群频率,去除东亚人群频率高于0.0008、非癌症人群频率高于0.0023、对照人群频率高于0.0008、esp6500siv2项目频率高于0.005的变异位点;
19、(e)根据变异位点的测序深度、变异频率进行过滤。
20、优选地,所述根据变异位点的测序深度、变异频率进行过滤的过滤指标包括:
21、对照样本的测序深度≥50x、肿瘤样本的测序深度≥90x、肿瘤样本的变异碱基的读段数≥4条或肿瘤样本的变异频率≥0.01。
22、优选地,所述特征19的值采用如下计算方式计算得到:
23、;
24、其中,falt和ralt分别表示变异碱基比对到正链和负链的读段数,f和r分别表示在该位点上正链和负链的总读段数,计算结果中,如果特征19的值接近于0,则偏好性低。本特征值能够反映出链偏好性的程度且具有连续性,在利用测试数据评估时其对数据的分组能力也较强。
25、优选地,所述特征22和特征24分别表示根据体细胞变异位点的p值利用phred方式计算的体细胞分值,和对照样本和肿瘤样本在体细胞变异位点和杂合性缺失变异位点利用费歇尔精准性测试计算的p值;
26、;
27、其中a、b、c、d分别表示期望的对照样本参考碱基的读段数、期望的对照样本变异碱基的读段数、肿瘤样本参考碱基的读段数、肿瘤样本变异碱基的读段数;n表示总读段数即a+b+c+d之和;p经过fisher精确验证计算得到的p概率值;在p值大于0的情况下,特征22采用如下公式计算:
28、;
29、特征22式中int表示取整;
30、特征24是对p值的格式化转换,输出为科学计数格式。
31、所述特征22和特征24是对变异位点做的可靠性验证,是在识别到变异位点后进一步验证位点是否真实,能够在初始阶段去除假阳性,对提供本发明最终的检测效果有较大提升作用。
32、优选地,所述特征27和特征116的值采用如下计算方式计算得到:
33、特征27=∑(st)
34、st表示从cosmic数据库中提取的不同癌症种类的次数。
35、根据对临床样本分析的经验来看,cosmic数据库中变异位点注释到的癌症种类次数越多,则该变异位点是真实致病性位点的可能性更高,本发明利用cosmic注释信息进行数据分组,在测试和评估数据中的效果非常明显,特征27的重要性也非常靠前。
36、特征116=∑(si)
37、si表示从cosmic数据库中提取的在癌症中发生的次数。
38、特征116与特征27的原理类似,在cosmic数据库中的记录次数也直接影响到位点真实性,因此作为特征值进行数据评估,其可靠性也很靠前。
39、优选地,所述特征80和特征93的值从比对结果文件中获得,再采用如下计算方式计算平均值:
40、特征80=∑(maqi)
41、特征93=∑(maqi)
42、maqi表示从覆盖该变异位点的读段的比对质量值。
43、优选地,所述特征81和特征82的值采用如下计算方式计算得到:
44、特征81=(alt_plus -alt_minus)2/(alt_plus+alt_minus)
45、特征82=(alt_plus-alt_minus)2/(alt_plus+alt_minus)
46、其中,alt_plus表示变异碱基或其他碱基在正链的读段数,alt_minus表示变异碱基或其他碱基在负链的变异数,如果链偏好性较小,则特征81接近于0,否则数值大小反应了链偏好性的程度。这是另一种反应链偏好性的方法,因为链偏好性的变异位点在叫容易出现且大多是假阳性,会影响到最终的解读,因此使用多种算法识别链偏好性能够提升本发明的准确度。
47、优选地,所述特征83和特征96值采用如下计算方式计算得到:
48、;
49、其中i表示一条覆盖到该变异位点的读段,n表示覆盖该变异位点的总读段数,ri表示变异位点在读段中的位置数,li表示这条读段的长度;特征96的计算方式同特征83。
50、本发明充分挖掘每个变异位点的各种特征,该特征值是从变异位点在读段中的位置出发进行评估真实性,因为越靠近两端的变异位点也可能是测序错误导致,一般认为靠近读段中部的变异位点更加真实,因此该方法也能够比较有效的识别出假阳性位点。
51、优选地,所述模型构建单元中,将模型数据集分为训练集和测试集,对训练集进行随机森林建模,使用测试集对模型进行评估。
52、第二方面,本发明提供第一方面所述的快速识别药物标识位点的系统在制备肿瘤检测的产品中的应用。
53、第三方面,本发明提供一种计算机可读存储介质,所述介质上存储有程序,所述程序被处理器执行时,用于实现第一方面所述的快速识别药物标识位点的系统中的程序。
54、第四方面,本发明提供一种计算设备,包括至少一个处理器、存储器、及至少一个程序,其中程序存储在所述存储器中并被配置为所述处理器执行,所述程序包括用于执行第一方面所述的快速识别药物标识位点的系统的程序。
55、本发明所述的数值范围不仅包括上述列举的点值,还包括没有列举出的上述数值范围之间的任意的点值,限于篇幅及出于简明的考虑,本发明不再穷尽列举所述范围包括的具体点值。
56、相对于现有技术,本发明具有以下有益效果:
57、本发明提供了一种协助医学解读人员快速识别有用药指导变异位点的方法,通过优化生物信息学算法,在待测样本完成正常的生物信息分析流程后,使用随机森林方法构建算法模型,由于模型构建时创新性地运用了一系列有效的特征值,能够高效的从大量的假阳性位点中识别出与患者疾病相关的变异位点,并且本发明使用的测试集都经过人工审核,每个阳性变异位点都是经过人工确认且可以用药的,每个阴性位点都确认不是与患者疾病相关的。本发明的最终结果是能够根据ngs测序结果报告有药物相关的致病性位点及提示对应可用的药物。
- 还没有人留言评论。精彩留言会获得点赞!