基于强化学习的足球机器人防守策略的制作方法
本发明涉及机器人运动算法领域,具体涉及一种基于强化学习的足球机器人防守策略。
背景技术:
自stone等人推出robocup2dkeepaway模型以来已过了十年。keepaway本质上与半场进攻(halffieldoffensive.hfo)最为相似,但是hfo更加具有扩展性,并且涵盖了一系列的自定义比赛模式。hfo不仅具有状态和动作空间,还具有探索单个机器人学习、临时团队合作、多机器人学习和模仿学习的能力。
然而,在真正的比赛当中,由于进行的是全场的仿真足球比赛。这样必然会导致状态变量的增多,也会有更多不可控的因素影响球员的动作选择。为了消除不必要噪声,需要扩大球员的视觉范围。但在真实的比赛当中,球员的视野是有一点的限制的,这就导致了状态变量重新选择以及如何在更多状态变量进行取舍的问题。另外,奖惩值的设定对算法的学习效率同样有举足轻重的影响。因此,奖惩值的设定以及状态变量的选取等问题成为了该算法应用到2d仿真足球中的一大挑战。
技术实现要素:
本发明针对上述问题,提出一种基于强化学习的足球机器人防守策略。
基于强化学习的足球机器人防守策略,基于半场进攻平台hfo环境和td算法的足球机器人防守策略,其特征在于:
所述hfo环境建立在robocup2d仿真平台的基础之上;
所述td算法对防守角色的机器人进行强化学习,利用值函数的更新来优化策略,帮助机器人选择效果更佳的动作来提高球权占有率;然后在td算法中加入通讯来提高强化学习的效率,利用广播来传递机器人状态-动作等实时信息,加速算法收敛,提升机器人的协作防守效率。
进一步地,所述td算法是结合了蒙特卡洛和动态规划思想的产物,具体地,采用td(λ)算法,算法的迭代公式可用下列公式表示:
v(s)←v(s)+α[rt+1+γv(s')-v(s)]
其中,α为学习率,rt+1+γv(s')被称作td目标,δt=rt+1+γv(s')-v(s)称作td偏差。该算法通过不断更新v(s)的值,它估计的是即将执行策略的值。具体过程为:机器人在当前环境状态s下,执行动作a,环境状态迁移至新的环境状态,机器人接受奖惩值r,结束于状态s',该过程提供了一个用以更新v(s)的新值,即td目标rt+1+γv(s')。
进一步地,在所述td(λ)算法中,规定一个阈值,对于每一个状态s,当收到的新的奖惩值时便更新v(s)的值但仅仅更新那些资格大于阈值的,算法描述如下:
输入:s是环境状态的集合,a是动作的集合,γ是折扣率,α是学习率,π是现存策略;
内部状态:状态值函数v(s),前一状态s,前一行为a,奖惩值r;
begin:
任意地初始化v(s)(如,v(s)=0,
初始化s
观察目前状态s
采用一个基于v(s)的策略选择a
repeatforever:
执行动作a
观察回报r和状态s'
δt←rt+1+γv(s')-v(s)
v(s)←v(s)+α[rt+1+γv(s')-v(s)]
s←s'
a←a'
end-repeat
在执行每一个动作之后,根据新的迁移状态s去更新v(s)值。
进一步地,所述环境状态集合s,包含变量环境状态s,利用球员之间的距离和角度来提取状态变量,利于动作参数的选择,所述状态变量包括:
dist(o1,ok)表示防守队员o1与每个队友之间的距离;
dist(o1,g)表示持球的防守球员与己方守门员之间的距离;
dist(o1,d),dist(o2,d),dist(o3,d)表示防守球员与对方进攻球员的距离;
min_ang(o2,o1,d),min_ang(o3,o1,d)表示队员与持球队员o1的最小角度∠oio1d);
其中,这些状态变量都会影响防守球员对动作的选择;在hpo中,因为只考虑防守的效率,所以可以利用半场进攻这一特点,将策略加入到防守球员中进行训练学习;状态变量的个数与防守球员的数量呈线性关系,而跟进攻球员的数量线性无关。
进一步地,所述动作集合a,包含动作a,动作集中,一般包含传球、带球、截球,踢球等动作;
其中截球属于守门员特有的动作,专门阻止进攻球员的射门;
传球动作pass,是在考虑队友距离的基础上,对指定的球员k进行传球,其中k是基于自身与队友距离,由近到远进行排序,k越小的球员距离持球球员越近;
带球动作dribble则是让球员在回避对手的情况下向远离己方球门的方向推进;
球员会首先判断自己队伍是否处于持球状态(kickable),若不处于持球状态,则由距离球最近的球员采取抢球的行为(intercept)或踢球(kick)出界的行为,阻止对手过于靠近球门;若处于持球状态,则由持球队员采取防守策略(clearball)回避对手的同时向安全(safe)的状态推进,即朝着远离己方球门的方向运球或传球,为自己的球队尽可能地争取球权,伪代码如下:
进一步地,由于防守球员要尽可能延长自身持球时间,最大化球权持有时间占比,因此设置了守门员截球成功的奖惩值r为1,运球以及传球成功的时候给予一定的奖励,具体如下所示:
进一步地,所述在td算法中加入通讯来提高强化学习的效率,利用广播来传递机器人状态-动作等实时信息,具体地,在仿真足球模型当中,每个都周期都能通过广播在球员之间传递信息;规定在防守球员持球时,在某一状态下选择动作并且以奖惩值r作为回报时,就向团队进行广播通讯,具体算法如下:
进一步地,所述episode,即片段也就是学习任务,作为训练过程的基本单位,通过设置了一定数量的片段来进行训练,以达到算法的收敛;设置了以下三种情况作为学习任务结束的标志:对方球员获得球权;球出界;对手进球;
每个机器人都有各自的状态值函数v(s),当防守队员做出行动后,根据新的迁移环境状态接受奖惩值,并以(s,a,r)的形式广播给教练员(trainer),以保证每个机器人接收的广播信息的一致性,而后续的通讯则通过(s',a',r')迭代更新。
本发明为了加强机器人之间的通讯,提高学习速度,将通讯加入到td算法当中,利用广播来传递机器人状态-动作等实时信息。最后通过hfo平台来验证对比通讯的加入对算法效率的提高程度,通过比较数目不同的机器人在加入通讯时的学习效率,得出本发明的防守效率得到了一定的提高。
附图说明
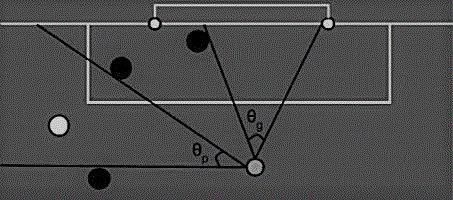
图1为本发明中hfo状态表示的最大开放目标角示意图。
图2为本发明所述的强化学习模型示意图。
图3为基于td算法的防守球员学习和原始的数据对比图。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
基于强化学习的足球机器人防守策略,基于半场进攻平台hfo环境和td算法的足球机器人防守策略,所述hfo环境建立在robocup2d仿真平台的基础之上;所述td算法对防守角色的机器人进行强化学习,利用值函数的更新来优化策略,帮助机器人选择效果更佳的动作来提高球权占有率;然后在td算法中加入通讯来提高强化学习的效率,利用广播来传递机器人状态-动作等实时信息,加速算法收敛,提升机器人的协作防守效率。
hfo环境的开源版本带来几个方便的特性,如与robocup标准服务器类mdp的接口,访问高级和低级状态空间,访问高级和低级行为空间,支持自动化的队友和对手,npc兼备进攻和防守能力,机器人之间进行通讯,设置执行可重复的实验,表现评估和分析工具。
机器人robocup2d仿真足球比赛由两个队之间自主进行的,同时每个队会与中央服务器进行通信。hfo环境建立在可用于比赛的robocup2d服务器之上,但它能够支持自动化球员(“非玩家角色”的npc)和玩家控制的机器人(每队最多10名队员)任意组合而成的小型队伍。
因为官方的robocup2d足球服务器是hfo环境的核心,希望在hfo中的机器人和学习到的技能能够轻松转化为robocup足球比赛当中。此外,在机器人robocup比赛中获胜的强大的机器人能够被移植到hfo中作为npc。目前,hfo只支持一种helios-agent2d,标准的通信接口允许其他机器人能够轻松的接入。
与hfo连接的机器人能够在低级状态和高级状态之间进行切换。这种状态的选择影响hfo任务的难度。低级状态表示提供更多的特征,但预处理更少,而高级状态表示提供数量更少的、信息量更大的特征。例如,通过计算守门员的位置和目标位置,高级状态会提供一个叫做最大开放目标角的特征(如图1)。相比之下,低级状态则提供球门的角度和每个对手的角度,但判断“哪个对手是守门员”和计算“开球角度”的任务则留给了球员。下面我们对这些状态的表示进行更详细地描述。
所述低级状态表示,hfo使用了58个连续值表示的特征(每个队友和对手都有8个附加特征)定义了一个低级的以自我为中心的视角。这些特征是通过helios的世界模型得到的,并为各种重要的场上物体提供了角度和距离,如球、球门和其他球员。最相关的特征包括机器人的位置、速度、方向和耐力;是否能踢球的标识;球的角度和距离、球门、场地的角的位置;队友和对手的位置,角度,速度和方向。这些特征将被一个能够处理原始感知信息的学习算法所使用。
所述高级状态表示,高级特征空间是一种精炼的表示,使机器人能够通过总结某些类似状态的知识来快速学习。这包含了至少9个连续值特征,每个队友有5个附加特征。特征包括:机器人的位置和趋向;球的距离、角度;是否能踢球的标识;到目标的距离和角度;最大的开放目标角;队友距离、角度、号码、最大开球角度和最近对手距离;传球给每一个队友所需要的角度。这个特征集的灵感来自于barrett等人对hfo的探索。这些高级特征允许智能机器人快速提高hfo性能。
所述动作表示包括低级动作表示和高级动作表示。
所述低级动作表示,hfo使用一个参数化的低级动作空间,在这个空间中,机器人首先要决定选择那种类型的动作,然后再决定如何执行该动作。hfo的低级参数化动作空间的正式特征是参数化动作markov决策过程(pamdp),它具有四个相互排斥的基本动作类型:dash、turn、tackle和kick。每个动作都必须要指定两个连续的参数。机器人必须同时选择它希望执行的离散动作和伴随的连续参数:dash(power,direction):以指定的速度将机器人移动到指定的方向。向前运动比横向或后向快。turn(direction):将机器人转向指定的方向,tackle(direction):向指定方向移动拦截球员。kick(power,direction):用指定的力量将球踢向指定的方向。
所述高级动作表示,hfo的高级动作空间为helios机器人s的足球行为定义了一个合适的接口。每个高级动作最终都由低级动作组成,但包含了helios的策略,用于选择和参数化低级动作。hfo支持五种高级动作:
move():根据helios的策略对机器人进行移动;
shoot():采用可用的最佳射门策略;
pass(uniformnum):把球传给指定号码的队友;
dribble():用短距离踢球和移动相互配合的方法向球门推进;
catch():属于守门员的特有动作,拦截球。
进攻的球员可以选择shoot、pass和dribble,防守球员可以选择move和catch。机器人还可以选择“不执行任何动作“。利用这个动作空间,一个随机选择动作的进攻球员在没有守门员在场的时候就能进球。
所述自动化队友(npc),在hfo中,自动化队友和对手的策略源自2012年robocup2d冠军团队helios。此策略适用于完整的11对11匹配,也可以扩展到hfo中的任何子任务。helios的球员偏向合作,它们会有策略地把球传给球员。有些传球是直接的,有时会让球员快速调整位置以便接到传球。当球员拿到球时,helios的球员能够聪明地调整自己的位置,并会冲刺着接到队友的传球。
强化学习,是指在未知环境中,通过反复实验,学习如何在长期受益的情况下采取行动。机器人与环境的交互过程可以表述为:机器人在感知当前环境的状态下选择动作,动作执行后迁移至新的环境状态,并由新的环境状态反馈一个强化信号给机器人,机器人根据当前的环境状态信息和强化信号决定下一个动作,其基本的模型如图2所示。
从上述基本模型中可以看出,强化学习的关键部分包含以下四个:
策略π:π(s,a)表示状态s下选择执行动作a,提供了动作到环境感知状态的映射。
值函数:也称状态评价函数。是对确定策略得出的行为进行评估,评价当前状态的表现。强化学习的学习目标是找到最佳策略,这意味着要不断修正值函数来达到修正策略。
奖惩函数r:奖励函数是mdp的重要组成部分,用于指定在一个状态中执行某动作的瞬时期望。
环境模型t:又称状态转移模型,用于预测行动产生后的新的环境状态。
在强化学习的过程当中,机器人能够随机选择执行动作,由新的环境状态反馈一个强化信号来对动作的好坏进行评估,这种无监督的学习方法不需要提前告知计算机如何生成正确的动作。机器人必须依靠自身的经验来进行学习,通过奖惩函数来调整动作的评价值,最终得到最优防守策略,达到提高防守能力的目标。
在本发明中,采用td算法来对机器人进行训练和学习。首先td算法是结合了蒙特卡洛和动态规划思想的产物。td(λ)算法是对td算法(即td(0))的进阶,该算法在一定程度上克服了td算法收敛慢的缺点。算法的迭代公式可用下列公式表示:
v(s)←v(s)+α[rt+1+γv(s')-v(s)]
其中,α为学习率,rt+1+γv(s')被称作td目标,δt=rt+1+γv(s')-v(s)称作td偏差。该算法通过不断更新v(s)的值,它估计的是即将执行策略的值。具体过程为:机器人在当前环境状态s下,执行动作a,环境状态迁移至新的环境状态,机器人接受奖惩值r,结束于状态s',该过程提供了一个用以更新v(s)的新值,即td目标rt+1+γv(s')。
在该算法中,规定一个阈值,对于每一个状态s,当收到的新的奖惩值时便更新v(s)的值但仅仅更新那些资格大于阈值的,使得该算法更加高效,而且也一定程度上减少了准确率的损失。算法描述如下:
输入:s是环境状态的集合,a是动作的集合,γ是折扣率,α是学习率,π是现存策略;
内部状态:状态值函数v(s),前一状态s,前一行为a,奖惩值r;
begin:
任意地初始化v(s)(如,v(s)=0,
初始化s
观察目前状态s
采用一个基于v(s)的策略选择a
repeatforever:
执行动作a
观察回报r和状态s'
δt←rt+1+γv(s')-v(s)
v(s)←v(s)+α[rt+1+γv(s')-v(s)]
s←s'
a←a'
end-repeat
在执行每一个动作之后,根据新的迁移状态s去更新v(s)值。
在hfo的状态空间中,状态变量的选取与机器人的动作和hfo的环境有关。本发明主要利用了球员之间的距离和角度来提取状态变量,这有利于动作参数的选择。
dist(o1,ok)表示防守队员o1与每个队友之间的距离;
dist(o1,g)表示持球的防守球员与己方守门员之间的距离
dist(o1,d),dist(o2,d),dist(o3,d)表示防守球员与对方进攻球员的距离;
min_ang(o2,o1,d),min_ang(03,01,d)表示队员与持球队员o1的最小角度∠oio1d)。
其中,这些状态变量都会影响防守球员对动作的选择。在hpo中,因为只考虑防守的效率,所以可以利用半场进攻这一特点,将策略加入到防守球员中进行训练学习。状态变量的个数与防守球员的数量呈线性关系,而跟进攻球员的数量线性无关。
在防守球员的动作集中,一般包含传球、带球、截球,踢球。其中,截球属于守门员特有的动作,专门阻止进攻球员的射门。而传球动作pass,是在考虑队友距离的基础上,对指定的球员k进行传球。其中,k是基于自身与队友距离,由近到远进行排序,k越小的球员距离持球球员越近。带球动作dribble则是让球员在回避对手的情况下向远离己方球门的方向推进。一般来说,球员会首先判断自己队伍是否处于持球状态(kickable),若不处于持球状态,则由距离球最近的球员采取抢球的行为(intercept)或踢球(kick)出界的行为,阻止对手过于靠近球门。若处于持球状态,则由持球队员采取防守策略(clearball)回避对手的同时向安全(safe)的状态推进,即朝着远离己方球门的方向运球或传球,为自己的球队尽可能地争取球权,伪代码如下:
在本发明中,最重要的是防守球员能尽可能延长自身持球时间,最大化球权持有时间占比。因此设置了守门员截球成功的奖惩值r为1,运球以及传球成功的时候给予一定的奖励。具体如下所示:
加入通讯能够让机器人之间加强交流,促进信息的共享。在仿真足球模型当中,每个都周期都能通过广播在球员之间传递信息。规定在防守球员持球时,在某一状态下选择动作s并且以奖惩r作为回报时,就向团队进行广播通讯。具体算法如下:
片段(episode)也就是学习任务,作为训练过程的基本单位,我们通过设置了一定数量的片段来进行训练,以达到算法的收敛。我们设置了以下三种情况作为学习任务结束的标志:对方球员获得球权;球出界;对手进球。
每个机器人都有各自的状态值函数v(s),当防守队员做出行动后,根据新的迁移环境状态接受奖惩值,并以(s,a,r)的形式广播给教练员(trainer),以保证每个机器人接收的广播信息的一致性,而后续的通讯则通过(s',a',r')迭代更新。通过加入通讯的方法能够提高td算法的学习效率。
本发明中,在防守球员中分别设置为基于td算法学习的球员与原始的球员进行20组数据对比分析,如图3所示,可以看出,本发明明显提高了机器人的截球成功率。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!