一种基于深度学习的机械臂手部抓取物体的方法与流程
本发明属于多自由度机械手控制技术领域,具体涉及一种基于深度学习的机械臂手部抓取物体的方法。
背景技术:
随着社会的不断发展,人们对社会服务的需求也会随之增加,老年人与残疾人士也成为人们关注的焦点。老年人口的迅速增长,导致老龄化在我国已经非常严重。据统计,在2016年60岁以上的人口已经达到了2.3亿多,但并没有如此多的护理人员来照顾这些老人。不仅如此,大量的伤残人士同样需要大量的护理人员。传统的护理方式已经不能满足现在社会现状的需求,先进的护理机器人将会改善老年人与残疾人的生活。随着护理机器人走进人们的视野,护理机器人的功能更加完善。国内外对护理机器人的研发一直没有松懈过,不论是荷兰exactdynamics公司生产的manus康复机器人手臂,还是德国宇航中心研发的lwr轻型机械臂,护理机械臂的研发从未停止过,护理机械臂手部准确抓取不同物体的难点也随之凸显出来。
关节电机转动一定的角度,通过路径规划找到合理的路径,转到目标,通过手部来进行抓取,但是具有如下缺点:不同物体的抓取稳定度不足,大多数机械臂只抓取单一特定结构的物体,而且容易将待抓取物碰倒。
技术实现要素:
针对现有技术中存在的上述技术问题,本发明提出了一种基于深度学习的机械臂手部抓取物体的方法,设计合理,克服了现有技术的不足,具有良好的效果。
为了实现上述目的,本发明采用如下技术方案:
一种基于深度学习的机械臂手部抓取物体的方法,采用双目相机、工作站以及多自由度机械臂实现语音控制机械臂抓取物体,采取对待抓取物进行理想化抓取,记录下此时机械臂各关节电机的角度,做好映射关系,一个物体对应着一组机械臂电机的理论角度值;
具体包括如下步骤:
步骤1:特定人语音训练;具体包括如下步骤:
步骤1.1:对语音信号序列x(n)进行预处理,得到序列xm(n)后,进行傅里叶变换:
x(i,k)=fft[xm(n)];
普线能量:e(i,k)=[x(i,k)]2;
步骤1.2:经过mel滤波器hm(k)滤波:
其中,0≤m≤m,m是滤波器hm(k)的数量;
经过mel滤波器hm(k)之后的能量:
步骤1.3:计算离散余弦变化倒谱的mfcc特征参数:
步骤1.4:将计算得到的特征矩阵跟指令以文件名称的形式存起来,当收到语音信号时进行匹配,确定语音命令,得到待抓取物体;
步骤2:通过双目相机进行三维建模;具体包括如下步骤:
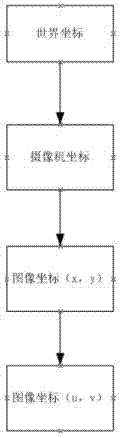
步骤2.1:进行离线双目相机标定,求得双目相机的内外参数,确定旋转矩阵与平移矩阵,从而将世界坐标系进行平移和转换得到摄像机坐标系;
步骤2.2:根据双目相机焦距进行三角几何变换得到图像物理坐标系;
步骤2.3:根据双目相机内参数、像素和公制单位的比率得到图像像素坐标系,得到物体在图像物理坐标系中的坐标值;
步骤3:通过粒子群优化三层bp神经网络对机械臂的角度进行矫正;具体包括如下步骤:
步骤3.1:样本采集,输入样本是不准确的三维坐标值,输出样本是期望的三维坐标值;
步骤3.2:初始化,对中间多个神经元的权值跟阈值进行赋值;
步骤3.3:将训练样本输入到网络中,通过传递函数计算出网络的实际输出;
步骤3.4:根据目标输出和实际输出求得一般化误差;
步骤3.5:根据一般化误差对中间多个神经元的权值跟阈值进行矫正,直至神经网络的全局误差小于设定的误差;
步骤3.6:粒子群优化bp的误差函数;
隐含层节点yi输出:
其中:xi为输入节点,wji为输入与隐层之间的权值,
输出节点的输出:
其中:vij为隐层与输出之间的权值,
输出节点的误差e:
其中:tl为期望的输出;输出节点的误差函数e作为粒子群的优化函数;
步骤4:通过广义回归神经网络grnn进行求逆解,从而求出各个电机的角度;具体包括如下步骤:
步骤4.1:采集机械臂待抓取物体位置的三维坐标,以及此时对应的电机角度;
步骤4.2:将采集的机械臂的三维坐标作为输入,将电机角度作为期望输出,进行grnn网络建模;
步骤5:训练alexnet网络的model;
在caffe环境下,通过gpu训练alexnet网络的model,通过python或者vs2013加载caffe,调用model,对待抓取的物体进行识别;
步骤6:通过机械臂进行抓取。
优选地,步骤5中,具体包括如下步骤:
步骤5.1:收集样本,做好标签分类,选择物体的照片,对物体进行人工分类并做好标记,图片的大小均为227*227像素;
步骤5.2:样本输入时减去每张照片的均值,生成均值文件;
步骤5.3:建立alexnet神经网络;具体包括如下步骤:
步骤5.3.1:修改输出神经元的个数,对来自最底层的数据类型imagedata类型进行转换,转成lmdb格式,然后执行步骤5.3.2进行初始化;
步骤5.3.2:对图片进行剪切并设置顶层数据的维数,进行卷积操作,对图像的局部特征进行相关性特征提取,然后将局部特征连接起来就是图像整体的图像特征,每张图片的数据与权重相乘然后加上偏置就是中间层输出结果;
步骤5.3.3:经过下采样层对卷积层的输出进行平均值池化,降低数据维数,之后进行全连接得到最终的数据;
步骤5.3.4:从输出层到输入层的反向计算,也是遍历所有数据,然后根据顶层的数据梯度直接计算出偏置梯度,根据底层数据和顶层的数据梯度相乘计算出权重的梯度,然后顶层数据梯度与权重相乘得到底层的数据梯度;
步骤5.4:进行参数调节,修改参数文件的内容;
每次测试迭代1000次,每1000次进行一次测试,网络学习率0.01,网络动量值0.9,网络权重衰减0.0005,最大迭代次数设置5000,每20次显示一次,保存中间结果1000,model模式选择gpu;
步骤5.5:应用python加载caffe训练好的model,然后通过摄像头对待识别物体进行识别,之后与样本匹配选择出与待识别物体最接近的标签。
本发明所带来的有益技术效果:
本发明提出的基于深度学习的机械臂手部物体抓取方法,极大地提高了机械臂抓取物体时的准确度与稳定性,可以很好的解决机械手在抓取物体时导致的抓取物不平衡或者碰倒抓取物等一系列抓取问题,并且可以对多种物体进行稳定抓取。
附图说明
图1为基于深度学习的机械臂手部物体抓取方法的流程图。
图2为双目相机坐标转换示意图。
图3为alexnet网络结构图。
图4为bp神经网络误差示意图。
图5为alexnet训练参数结果测试图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
一种基于深度学习的机械臂手部抓取物体的方法,其流程如图1所示,采用双目相机、工作站以及多自由度机械臂实现语音控制机械臂抓取物体,采取对待抓取物进行理想化抓取,记录下此时机械臂各关节电机的角度,做好映射关系,一个物体对应着一组机械臂电机的理论角度值;具体包括以下步骤:
步骤1:特定人语音训练;具体包括如下步骤:
步骤1.1:对语音信号序列x(n)进行预处理,得到序列xm(n)后,进行傅里叶变换:
x(i,k)=fft[xm(n)];
普线能量:e(i,k)=[x(i,k)]2;
步骤1.2:经过mel滤波器hm(k)滤波:
其中,0≤m≤m,m是滤波器hm(k)的数量;
经过mel滤波器hm(k)之后的能量:
步骤1.3:计算离散余弦变化倒谱的mfcc特征参数:
步骤1.4:将计算得到的特征矩阵跟指令以文件名称的形式存起来,当收到语音信号时进行匹配,确定语音命令,得到待抓取物体;
步骤2:通过双目相机进行三维建模;其流程如图2所示,具体包括如下步骤:
步骤2.1:进行离线双目相机标定,求得双目相机的内外参数,确定旋转矩阵与平移矩阵,从而将世界坐标系进行平移和转换得到摄像机坐标系;
步骤2.2:根据双目相机焦距进行三角几何变换得到图像物理坐标系;
步骤2.3:根据双目相机内参数、像素和公制单位的比率得到图像像素坐标系,得到物体在图像物理坐标系中的坐标值;
步骤3:通过粒子群优化三层bp神经网络对机械臂的角度进行矫正;具体包括如下步骤:
步骤3.1:样本采集,输入样本是不准确的三维坐标值,输出样本是期望的三维坐标值;
步骤3.2:初始化,对中间多个神经元的权值跟阈值进行赋值;
步骤3.3:将训练样本输入到网络中,通过传递函数计算出网络的实际输出;
步骤3.4:根据目标输出和实际输出求得一般化误差;
步骤3.5:根据一般化误差对中间多个神经元的权值跟阈值进行矫正,直至神经网络的全局误差小于设定的误差;
步骤3.6:粒子群优化bp神经网络的误差函数;
隐含层节点yi输出:
其中:xi为输入节点,wji为输入与隐层之间的权值,
输出节点的输出:
其中:vij为隐层与输出之间的权值,
输出节点的误差e:
其中:tl为期望的输出;输出节点的误差函数e作为粒子群的优化函数;
bp神经网络误差如图4所示。
步骤4:通过广义回归神经网络grnn进行求逆解,从而求出各个电机的角度;具体包括如下步骤:
步骤4.1:采集机械臂待抓取物体位置的三维坐标,以及此时对应的电机角度;
步骤4.2:将采集的机械臂的三维坐标作为输入,将电机角度作为期望输出,进行grnn网络建模;
步骤5:训练alexnet网络的model;
在caffe环境下,通过gpu训练alexnet网络的model,通过python或者vs2013加载caffe,调用model,对待抓取的物体进行识别;
alexnet网络结构如图3所示,alexnet训练参数结果如图5所示。
步骤6:通过机械臂进行抓取。
在步骤5中,具体包括如下步骤:
步骤5.1:收集样本,做好标签分类,选择物体的照片,对物体进行人工分类并做好标记,图片的大小均为227*227像素;
步骤5.2:样本输入时减去每张照片的均值,生成均值文件;
步骤5.3:建立alexnet神经网络;具体包括如下步骤:
步骤5.3.1:修改输出神经元的个数,对来自最底层的数据类型imagedata类型进行转换,转成lmdb格式,然后执行步骤5.3.2进行初始化;
步骤5.3.2:对图片进行剪切并设置顶层数据的维数,进行卷积操作,对图像的局部特征进行相关性特征提取,然后将局部特征连接起来就是图像整体的图像特征,每张图片的数据与权重相乘然后加上偏置就是中间层输出结果;
步骤5.3.3:经过下采样层对卷积层的输出进行平均值池化,降低数据维数,之后进行全连接得到最终的数据;
步骤5.3.4:从输出层到输入层的反向计算,也是遍历所有数据,然后根据顶层的数据梯度直接计算出偏置梯度,根据底层数据和顶层的数据梯度相乘计算出权重的梯度,然后顶层数据梯度与权重相乘得到底层的数据梯度;
步骤5.4:进行参数调节,修改lenet_solver.prototxt文件内容;
每次测试迭代1000次,每1000次进行一次测试,网络学习率0.01,网络动量值0.9,网络权重衰减0.0005,最大迭代次数设置5000,每20次显示一次,保存中间结果1000,model模式选择gpu;
步骤5.5:应用python加载caffe训练好的model,然后通过摄像头对待识别物体进行识别,之后与样本匹配选择出与待识别物体最接近的标签。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!