一种基于强化学习的机器人恒力曲面跟踪方法与流程
本发明涉及机器人恒力控制技术领域,特别涉及一种基于强化学习的机器人恒力曲面跟踪方法。
背景技术
利用机器人末端执行器对曲面进行跟踪能够得到曲面的轮廓,稳定的轮廓轨迹可以为机加工,如打磨、抛光提供初始轨迹,减轻手动示教的工作量。然而,机器人在运动过程中具有非线性、时变性和耦合性会造成不确定的因素;机器人自身刚度(如减速器、开链结构)不足会造成机器人振动;未知曲面轮廓需要机器人调节自身参数来适应外界环境的变化,因此机器人与曲面的接触力常常不稳定,波动较大。
传统的智能算法往往需要先获取先验知识和模型,先验模型的准确程度决定了控制算法的好坏。人工获取先验特定的模型是极其繁琐的,而强化学习不需要专家知识,也不需要对底层世界的复杂的先验理解,在不断的与环境反复交互过程中,能自主地发现最优行为,减轻人工作业的难度,最终到达较好的控制效果。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于强化学习的机器人恒力曲面跟踪方法,旨在解决迭代数据较小的情况下实现机器人恒力曲面跟踪的效果。
本发明的目的通过以下的技术方案实现:一种基于强化学习的机器人恒力曲面跟踪方法,包括以下步骤:
(1)针对工业机器人末端执行器与曲面轮廓接触时的特征,建立曲面法向力和已知传感器坐标系的映射关系;
(2)设计显式力控制器控制机器人和曲面的接触过程;
(3)利用基于高斯模型推测的强化学习方法对控制器的参数(如显示力控制中力控制器的pid参数)进行优化;
(4)迭代实验直到得到力和期望的误差在设定的范围之内。
优选的,在进行步骤(1)之前,还包括步骤:根据力传感器采集的信号,上位机运行算法给机器人发送位置指令。
进一步的,上述的根据力传感器采集的信号上位机运行算法给机器人发送位置指令的步骤具体包括:
(a)数据采集模块采集力传感器的x和y方向的力信号,并将信号发送给上位机;
(b)上位机发送模拟信号给机器人控制箱,机器人产生偏移,偏移位移方向与模拟信号符号一致,偏移位移与电压绝对值大小成正比。
优选的,所述的步骤(1)具体包括:
建立研究对象曲面法向力和已知传感器坐标系的映射关系:
fn=tfxsinθ-tfycosθ
式中fn为曲面法向量力,tfx为传感器坐标系{t}中x方向上的力,tfy为传感器坐标系y方向上的力,θ为曲面倾斜角。
优选的,所述的步骤(2)具体包括:
机器人恒力曲面跟踪实验中,显式力控制中设计的力控制器的表达式为:
δut=kp*(δft-δft-1)+kd*δft
δft=fn-fd
ut=ut-1+δut
式中,δut为t时刻增加的输出量,实验中输出量为偏置电压;ut为t时刻的输出量;kp和kd为比例值;fn为曲面法向量力;fd是期望力;δft为t时刻曲面法向量力与期望力之差。
优选的,所述的步骤(3)具体包括:
(31)概率动力学模型学习,通过先验概率,得到后验概率分布,即当输入为测试参数x*时,根据先验概率得到后验概率分布为:
p(y*|x*)=n(k*t(k+σε2i)-1y,k**-k*t(k+σε2i)-1k*)
式中,x*为输入为测试参数;y*为预测输出的值;n表示是高斯分布;k*=k(x,x*),k**=k(x*,x*);k为内核函数选择平方指数协方差,k为内核函数的矩阵,其中kij=k(xi,xj);σε为独立的高斯噪声;i为单位矩阵。
(32)强化学习最优策略的学习,目的是得到概率动力学模型学习的最优策略,策略为满足以下条件为最优策略:
π*∈argminvπ(x0)
式中vπ(x0)为初始条件下x0下在π策略下强化学习值函数的值。将值函数策略参数线性或者非线性化,对值函数的策略参数求导得到策略参数的梯度。通过不停的迭代,直到策略参数满足最优策略条件。
(33)恒力跟踪实验中策略应用。将机器人跟踪的时间段平均分成n段,假设在不同时间段内策略对各段接触的影响是相互独立的,提取出每一段的力信号,得到曲面法向量力与期望力fd之差△f,求出△f的平均力fave、△f的方差fvar和每段末尾的角度θ三个参数构成机器人的状态值,显示力控制器中的需要调节参数(pid的值)为策略值,得到的状态值和策略值带入概率动力学模型学习的公式中,得到预测的值,即在第i段中在某一状态下,输入不同的策略值,得到预测i+1段的状态。利用rbf神经网络将i时间段状态的值、输入值和i+1时间段状态的值,输入值进行拟合,在得到概率动力学模型下,求出强化学习的值函数的值,通过改变神经网路参数的值,得到值函数的梯度,利用梯度对神经网络的参数进行更新,在找到最小值函数的同时也得到了策略的值。得到新的策略后,迭代实验,得到新的n组策略和n组角度。从第二次实验开始,在到达第i个角度时,更新第i个策略参数的值。
优选的,所述的步骤(4)具体包括:所得力信号在阈值范围内时,迭代停止。
本发明与现有技术相比,具有如下优点和有益效果:
本发明解决了现有机器人曲面跟踪中难以得到恒定跟踪力的问题,具有不需要先验经验,数据利用率高和收敛速度快的优点,得到的曲面轮廓轨迹为后续的打磨,抛光等加工提供初始的参考轨迹。
附图说明
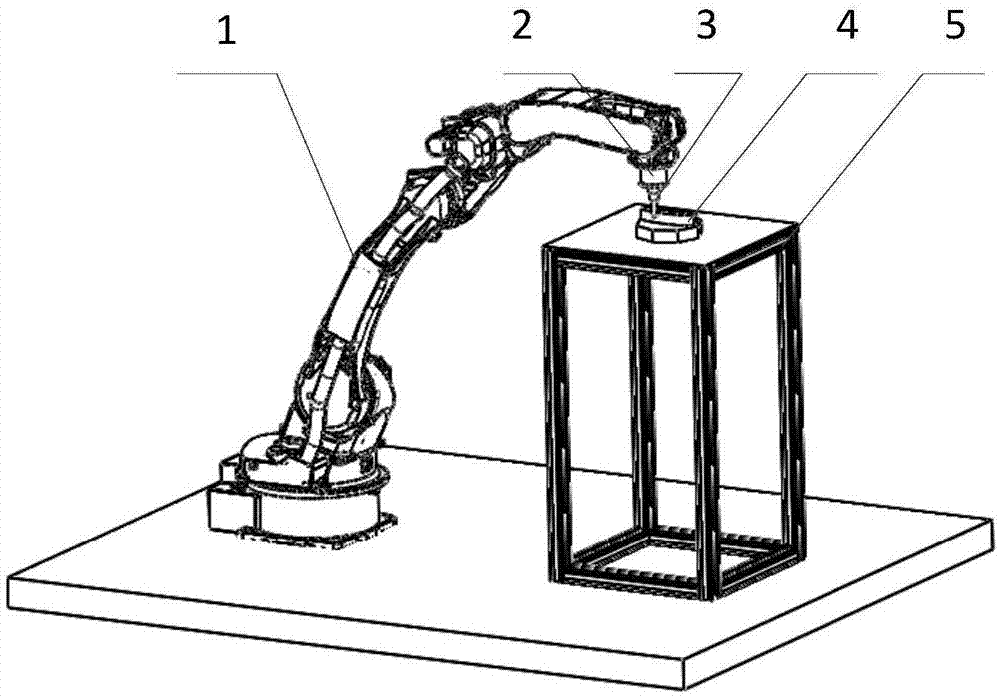
图1是实施例机器人恒力曲面跟踪平台示意图。
图2是实施例机器人恒力曲面跟踪平台局部放大图示意图。
图中:1-机器人;2-六维力传感器;3-探头;4-曲面工件;5-工作台。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
一种基于强化学习的机器人恒力曲面跟踪方法,该方法基于机器人恒力跟踪平台包括六轴工业机器人、工作台、曲面工件、六维力传感器、上位机、数据采集模块;机器人始终以恒定的速度沿着x方向移动,当机器人与工件接触的时,根据的力的大小沿着y方向偏移。
具体包括以下步骤:
(1)针对6轴工业机器人末端执行器与曲面轮廓接触时的特征,建立曲面法向力和已知传感器坐标系的映射关系;
(2)设计显式力控制器控制机器人和曲面的接触过程;
(3)利用基于高斯模型推测的强化学习方法(pilco,probabilisticinferenceandlearningforcontrol)对控制器的参数(如显示力控制中力控制器的pid参数)进行优化;
(4)迭代实验直到得到力和期望的误差在设定的范围之内。
在进行步骤(1)之前,还包括步骤:根据六维力传感器采集的信号,上位机运行算法给机器人发送位置指令。
上述的根据六维力传感器采集的信号上位机运行算法给机器人发送位置指令的步骤具体包括:
(a)数据采集模块采集六维力传感器的x和y方向的力信号,并将信号发送给上位机;
(b)上位机发送模拟信号给机器人控制箱,机器人产生偏移,偏移位移方向与模拟信号符号一致,偏移位移与电压绝对值大小成正比。
所述的步骤(1)具体包括:
建立研究对象曲面法向力和已知传感器坐标系的映射关系:
fn=tfxsinθ-tfycosθ
式中fn为曲面法向量力,tfx为传感器坐标系{t}中x方向上的力,tfy为传感器坐标系y方向上的力,θ为曲面倾斜角。
所述的步骤(2)具体包括:
机器人恒力曲面跟踪实验中显式力控制中设计的力控制器的表达式为:
δut=kp*(δft-δft-1)+kd*δft
δft=fn-fd
ut=ut-1+δut
式中,δut为t时刻增加的输出量,实验中输出量为偏置电压;ut为t时刻的输出量;kp和kd为比例值;fn为实际的力;fd是期望力;δft为t时刻实际力与期望力之差。
所述的步骤(3)具体包括:
(31)概率动力学模型学习,通过先验概率得到后验概率分布,即当输入为测试参数为x*时,根据先验概率得到后验概率分布为:
p(y*|x*)=n(k*t(k+σε2i)-1y,k**-k*t(k+σε2i)-1k*)
式中,x*为输入为测试参数;y*为预测输出的值;n表示是高斯分布,i为单位矩阵;k*=k(x,x*),k**=k(x*,x*);k为内核函数选择平方指数协方差,k为内核函数的矩阵,其中kij=k(xi,xj);
(32)强化学习最优策略的学习,目的是得到概率动力学模型学习的最优策略,策略为满足以下条件为最优策略:
π*∈argminvπ(x0)
式中vπ(x0)为初始条件下x0下在π策略下强化学习值函数的值。将值函数策略参数线性或者非线性化,对值函数的策略参数求导得到策略参数的梯度。通过不停的迭代,直到策略参数满足最优策略条件。
(33)恒力跟踪实验中策略应用。将机器人跟踪的时间段平均分成n段,假设在不同时间段内策略对各段接触的影响是相互独立的,提取出每一段的力信号,得到接触力fn与期望力fd之差△f,求出△f的平均力fave、△f的方差fvar和每段末尾的角度θ三个参数构成机器人的状态值,显示力控制器中的需要调节参数(pid的值)为策略,得到的状态值和策略值带入概率动力学模型学习的公式中,得到预测的值,即在第i段中在某一状态下,输入不同的策略值,得到预测i+1段的状态。利用rbf神经网络将i时间段状态的值,输入值和i+1时间段状态的值,输入值进行拟合,在得到概率动力学模型下,求出强化学习的值函数的值,通过改变神经网路参数的值,得到值函数的梯度,利用梯度对神经网络的参数进行更新,在找到最小值函数的同时也得到了策略的值。得到新的策略后,迭代实验,得到新的n组策略和n组角度。从第二次实验开始,在到达第i个角度时,更新第i个策略参数的值。
所述的步骤(4)具体包括:所得力信号在阈值范围内时,迭代停止。
本发明所述的各零部件可选型如下,但选型不限于此:六轴工业机器人:可选用其他同类型的机器人;工件2:可选用形状规则的同类型工件。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!