用于机器人抓握的深度机器学习方法和装置与流程
分案说明
本申请属于申请日为2016年12月13日的中国发明专利申请no.201680083745.6的分案申请。
背景技术:
许多机器人被编程为利用一个或多个末端执行器来抓握一个或多个对象。例如,机器人可以利用诸如“冲击式(impactive)”抓手或“进入式(ingressive)”抓手(例如,使用销、针等物理地穿透对象)的抓握末端执行器从第一位置拾取对象,移动对象到第二位置,并且在第二位置放下对象。可以抓握对象的机器人末端执行器的一些附加示例包括“收敛式(astrictive)”末端执行器(例如,使用抽吸或真空来拾取对象)和一个或多个“连续(contigutive)”末端执行器(例如,使用表面张力、冷冻或粘合剂来拾取对象),此处仅举几例。
技术实现要素:
本说明书一般涉及与机器人的末端执行器对对象的操纵有关的深度机器学习方法和装置。一些实施方式涉及训练深度神经网络,例如卷积神经网络(在本文中也称为“cnn”),以预测机器人的末端执行器的候选运动数据将导致由末端执行器成功抓握一个或多个对象的概率。例如,一些实施方式使得能够作为输入对于经训练的深度神经网络至少应用:(1)定义机器人的抓握末端执行器的候选运动(如果有的话)的候选运动向量和(2)捕获机器人的至少一部分工作空间的图像;并且基于所述应用,至少生成直接或间接指示候选运动向量将导致成功抓握的概率的度量。然后,预测概率可以用于伺服具有抓握末端执行器的机器人的抓握尝试的性能,从而提高机器人成功抓握其环境中的对象的能力。
一些实施方式涉及利用经训练的深度神经网络来伺服机器人的抓握末端执行器以通过抓握末端执行器实现对对象的成功抓握。例如,经训练的深度神经网络可以用于机器人的一个或多个致动器的运动控制命令的迭代更新,所述一个或多个致动器控制机器人的抓握末端执行器的姿势,并且确定何时生成抓握控制命令以通过抓握末端执行器实现尝试的抓握。在各种实施方式中,利用经训练的深度神经网络来伺服抓握末端执行器可以实现对机器人扰动和/或环境对象的运动的快速反馈和/或对不准确的机器人致动的鲁棒性。
在一些实施方式中,提供了一种方法,包括:生成候选末端执行器运动向量,所述候选末端执行器运动向量定义用于将机器人的抓握末端执行器从当前姿势移动到附加姿势的运动。所述方法还包括:识别当前图像,所述当前图像由与所述机器人相关联的视觉传感器捕获,并且捕获所述抓握末端执行器和所述机器人的环境中的至少一个对象。所述方法还包括:将所述当前图像和所述候选末端执行器运动向量作为输入应用于经训练的卷积神经网络,并且在所述经训练的卷积神经网络上,生成在应用所述运动的情况下成功抓握所述对象的度量。所述度量是基于向所述经训练的卷积神经网络应用所述图像和所述末端执行器运动向量来生成的。所述方法选用地还包括:基于所述度量生成末端执行器命令,并且将所述末端执行器命令提供给所述机器人的一个或多个致动器。所述末端执行器命令可以是抓握命令或末端执行器运动命令。
该方法和本文公开的技术的其他实施方式可以各自可选地包括以下特征中的一个或多个。
在一些实施方式中,所述方法还包括确定在不应用所述运动的情况下成功抓握所述对象的当前度量;并且基于所述度量和所述当前度量生成所述末端执行器命令。在那些实施方式的一些版本中,末端执行器命令是抓握命令,并且生成抓握命令是响应于确定度量与当前度量的比较满足阈值。在那些实施方式的一些其他版本中,末端执行器命令是末端执行器运动命令,并且生成末端执行器运动命令包括生成末端执行器运动命令以符合候选末端执行器运动向量。在那些实施方式的其他版本中,末端执行器命令是末端执行器运动命令,并且生成末端执行器运动命令包括生成末端执行器运动命令以实现对末端执行器的轨迹校正。在一些实施方式中,确定在不应用运动的情况下成功抓握对象的当前度量包括:将所述图像和空末端执行器运动向量作为输入应用到所述经训练的卷积神经网络;以及在所述经训练的卷积神经网络上,生成在不应用所述运动的情况下成功抓握所述对象的所述当前度量。
在一些实施方式中,末端执行器命令是末端执行器运动命令并且符合候选末端执行器运动向量。在这些实施方式中的一些实施方式中,向所述一个或多个致动器提供所述末端执行器运动命令将所述末端执行器移动到新姿势,并且所述方法还包括:生成附加的候选末端执行器运动向量,所述附加的候选末端执行器运动向量定义用于将所述抓握末端执行器从所述新姿势移动到另一个附加姿势的新运动;识别由与所述机器人相关联的视觉传感器捕获的新图像,所述新图像捕获在所述新姿势的所述末端执行器并捕获所述环境中的所述对象;将所述新图像和所述附加候选末端执行器运动向量作为输入应用于所述经训练的卷积神经网络;在所述经训练的卷积神经网络上生成在应用所述新运动的情况下成功抓握所述对象的新度量,所述新度量是基于向所述训练卷积神经网络应用所述新图像和所述附加末端执行器运动向量来生成的;基于所述新度量生成新的末端执行器命令,所述新的末端执行器命令是所述抓握命令或新的末端执行器运动命令;并且向所述机器人的一个或多个致动器提供所述新的末端执行器命令。
在一些实施方式中,将所述图像和所述候选末端执行器运动向量作为输入应用于所述经训练的卷积神经网络包括:将所述图像作为输入应用于所述经训练的卷积神经网络的初始层;以及将所述候选末端执行器运动向量应用于所述经训练的卷积神经网络的附加层。所述附加层可以位于所述初始层的下游。在这些实施方式中的一些实施方式中,将所述候选末端执行器运动向量应用于所述附加层包括:使所述末端执行器运动向量通过所述卷积神经网络的完全连接层,以生成末端执行器运动向量输出;以及将所述末端执行器运动向量输出与上游输出连接起来。所述上游输出来自所述卷积神经网络的紧邻上游层,所述紧邻上游层位于所述附加层的紧邻上游并且位于所述初始层和所述卷积神经网络的一个或多个中间层的下游。所述初始层可以是卷积层,并且所述紧邻上游层可以是池化层。
在一些实施方式中,所述方法还包括:识别由所述视觉传感器捕获的附加图像,并且将所述附加图像作为附加输入应用于所述经训练的卷积神经网络。所述附加图像可以捕获所述一个或多个环境对象并省略所述机器人末端执行器或包括处于与所述图像中的所述机器人末端执行器的姿势不同的姿势的所述机器人末端执行器。在这些实施方式中的一些实施方式中,将所述图像和所述附加图像应用于所述卷积神经网络包括:连接所述图像和所述附加图像以生成连接图像;以及将所述连接图像作为输入应用于所述卷积神经网络的初始层。
在一些实施方式中,生成所述候选末端执行器运动向量包括:生成多个候选末端执行器运动向量;以及对所述多个候选末端执行器运动向量执行交叉熵优化的一次或多次迭代,以从所述多个候选末端执行器运动向量中选择所述候选末端执行器运动向量。
在一些实施方式中,提供了一种方法,包括识别在所述机器人的多次抓握尝试期间基于来自一个或多个机器人的传感器输出而生成的多个训练示例。每个所述训练示例包括训练示例输入和训练示例输出。每个所述训练示例的训练示例输入包括:用于所述抓握尝试的对应抓握尝试的对应时间实例的图像,所述图像在所述对应时间实例捕获机器人末端执行器和一个或多个环境对象;以及末端执行器运动向量,所述末端执行器运动向量定义所述末端执行器从在所述对应的时间实例处的所述末端执行器的时间实例姿势移动到所述末端执行器的最终姿势以进行所述对应的抓握尝试的运动。每个所述训练示例的训练示例输出包括:指示所述对应抓握尝试的成功的抓握成功标签。所述方法还包括:基于所述训练示例训练所述卷积神经网络。
该方法和本文公开的技术的其他实施方式可以各自可选地包括以下特征中的一个或多个。
在一些实施方式中,每个所述训练示例的所述训练示例输入还包括:用于所述对应抓握尝试的附加图像。所述附加图像可以捕获所述一个或多个环境对象并且省略所述机器人末端执行器或者包括处于与所述图像中的所述机器人末端执行器的姿势不同的姿势的所述机器人末端执行器。在一些实施方式中,训练所述卷积神经网络包括向所述卷积神经网络应用所述训练示例的给定训练示例的所述训练示例输入。在这些实施方式中的一些实施方式中,应用所述给定训练示例的所述训练示例输入包括:连接所述给定训练示例的所述图像和所述附加图像以生成连接图像;以及将所述连接图像作为输入应用于所述卷积神经网络的初始层。
在一些实施方式中,训练所述卷积神经网络包括向所述卷积神经网络应用所述训练示例的给定训练示例的所述训练示例输入。在这些实施方式中的一些实施方式中,应用所述给定训练示例的训练示例输入包括:将所述给定训练示例的所述图像作为输入应用于所述卷积神经网络的初始层;以及,将所述给定训练示例的所述末端执行器运动向量应用于所述卷积神经网络的附加层。所述附加层可以位于所述初始层的下游。在这些实施方式中的一些实施方式中,将所述末端执行器运动向量应用于所述附加层包括:将所述末端执行器运动向量传递通过完全连接的层以生成末端执行器运动向量输出,并将所述末端执行器运动向量输出与上游输出连接。所述上游输出可以来自所述卷积神经网络的紧邻上游层,所述紧邻上游层位于所述附加层的紧邻上游,并且位于所述初始层和所述卷积神经网络的一个或多个中间层的下游。所述初始层可以是卷积层,并且所述紧邻上游层可以是池化层。
在一些实施方式中,所述末端执行器运动向量定义所述末端执行器在任务空间中的运动。
在一些实施方式中,训练示例包括:在第一机器人的多次抓握尝试期间基于来自所述第一机器人的多个第一机器人传感器的输出生成的第一组所述训练示例;以及在第二机器人的多次抓握尝试期间基于来自所述第二机器人的多个第二机器人传感器的输出生成的第二组所述训练示例。在这些实施方式中的一些中:所述第一机器人传感器包括生成用于所述第一组的所述训练示例的所述图像的第一视觉传感器;所述第二机器人传感器包括生成用于所述第二组的所述训练示例的所述图像的第二视觉传感器;所述第一视觉传感器相对于所述第一机器人的第一基座的第一姿势与所述第二视觉传感器相对于所述第二机器人的第二基座的第二姿势不同。
在一些实施方式中,多个训练示例所基于的所述抓握尝试各自包括多个随机致动器命令,所述随机致动器命令将所述末端执行器从所述末端执行器的起始姿势随机地移动到所述末端执行器的最终姿势,然后在所述最终姿势用末端执行器抓握。在这些实施方式中的一些实施方式中,所述方法还包括:基于所述经训练的卷积神经网络生成附加的抓握尝试;基于所述附加的抓握尝试识别多个附加训练示例;以及通过基于所述附加训练示例对所述卷积网络的进一步训练来更新所述卷积神经网络。
在一些实施方式中,每个所述训练示例的所述抓握成功标签是指示成功的第一值或指示失败的第二值。
在一些实施方式中,所述训练包括基于所述多个训练示例的所述训练示例输出在所述卷积神经网络上执行反向传播。
其他实施方式可以包括存储可由处理器(例如,中央处理单元(cpu)或图形处理单元(gpu))执行的指令以执行诸如如上所述的一个或多个方法的方法的非暂时性计算机可读存储介质。又一实施方式可以包括一个或多个计算机和/或一个或多个机器人的系统,所述一个或多个计算机和/或一个或多个机器人包括一个或多个处理器,其可操作以执行存储的指令以执行诸如上述方法中的一个或多个的方法。
应当理解,本文更详细描述的前述概念和附加概念的所有组合都被认为是本文公开的主题的一部分。例如,出现在本公开结尾处的所要求保护的主题的所有组合被认为是本文公开的主题的一部分。
附图说明
图1示出了示例环境,在该示例环境中,可以由机器人执行抓握尝试,可以利用与抓握尝试相关联的数据来生成训练示例,并且/或者,可以利用训练示例来训练卷积神经网络。
图2示出了图1的机器人之一和机器人的抓握末端执行器沿着路径的移动的示例。
图3是示出执行抓握尝试并存储与抓握尝试相关联的数据的示例方法的流程图。
图4是示出基于与机器人的抓握尝试相关联的数据生成训练示例的示例方法的流程图。
图5是示出基于训练示例训练卷积神经网络的示例方法的流程图。
图6a和6b示出了示例卷积神经网络的架构。
图7a是示出利用经训练的卷积神经网络来伺服抓握末端执行器的示例方法的流程图。
图7b是说明图7a的流程图的某些块的一些实施方式的流程图。
图8示意性地描绘了机器人的示例架构。
图9示意性地描绘了计算机系统的示例架构。
具体实施方式
本文描述的技术的一些实施方式涉及训练诸如cnn的深度神经网络,以使得能够利用经训练的深度神经网络来预测指示用于机器人的抓握末端执行器的候选运动数据将导致末端执行器成功抓握一个或多个对象的概率的度量。在一些实施方式中,经训练的深度神经网络接受由视觉传感器生成的图像(it),并接受末端执行器运动向量(vt),例如任务空间运动向量。将图像(it)和末端执行器运动向量(vt)应用于经训练的深度神经网络可以用于在深度神经网络上生成执行命令以实现通过运动向量(vt)定义的运动并随后抓握将生成成功的抓握的预测度量。一些实施方式涉及利用经训练的深度神经网络来伺服机器人的抓握末端执行器以通过抓握末端执行器实现对对象的成功抓握。下面提供对该技术的这些和其他实现的附加描述。
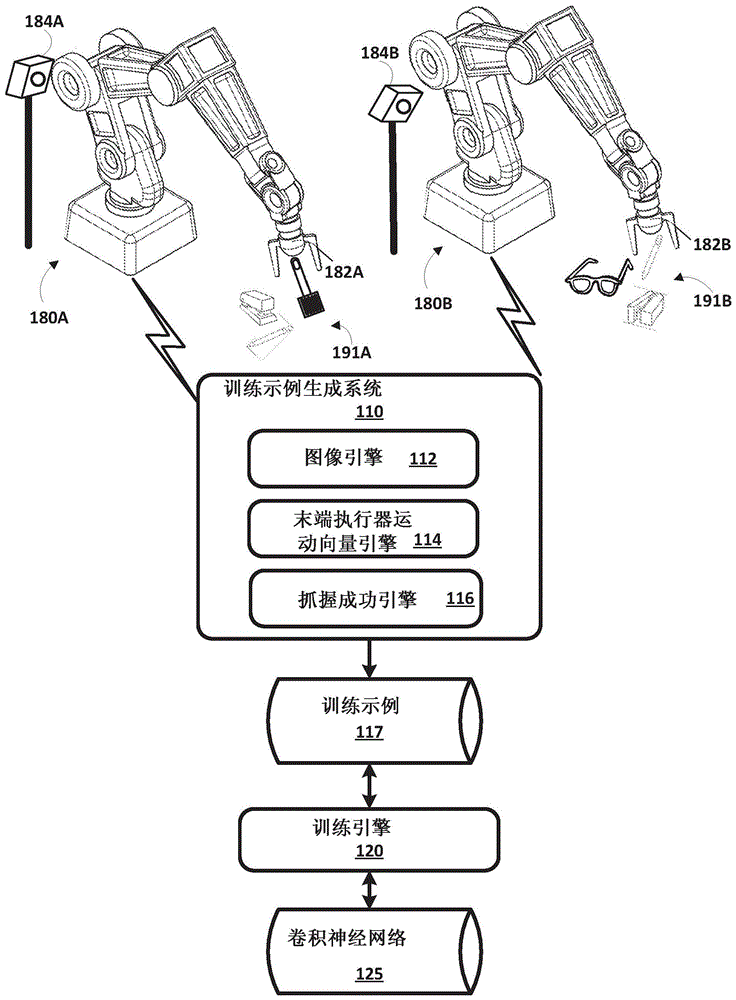
参考图1-6b,描述了训练cnn的各种实施方式。图1示出了下述示例环境,其中,可以由机器人(例如,机器人180a、180b和/或其他机器人)执行抓握尝试,可以利用与抓握尝试相关联的数据来生成训练示例,和/或可以利用训练示例训练cnn。
图1中示出了示例性机器人180a和180b。机器人180a和180b是具有多个自由度的“机器人臂(robotarms)”,以使得能够沿着多个潜在路径中的任何一个遍历抓握末端执行器182a和182b,以将抓握末端执行器182a和182b定位在期望的位置。例如,参考图2,示出了机器人180a沿路径201遍历其末端执行器的示例。图2包括机器人180a的虚线和非幻像图像,示出了机器人180a及其末端执行器在沿着路径201遍历时所遇到的姿势集合的两个不同姿势。再一次参见图1,机器人180a和180b各自进一步控制其对应的抓握末端执行器182a、182b的两个相对的“爪(claws)”,以在至少打开位置和闭合位置(和/或可选地多个“部分闭合(partiallyclosed)”位置)之间致动爪。
示例性视觉传感器184a和184b也在图1中示出。在图1中,视觉传感器184a相对于机器人180a的基座或其他固定参考点以固定姿势安装。视觉传感器184b也相对于机器人180b的基座或其他固定参考点以固定姿势安装。如图1所示,视觉传感器184a相对于机器人180a的姿势不同于视觉传感器184b相对于机器人180b的姿势。如本文所述,在一些实施方式中,这可以有益于使得能够生成可以用于训练对相机校准的鲁棒性和/或独立于相机校准的神经网络的各种训练示例。视觉传感器184a和184b是可以生成与传感器的视线中的对象的形状、颜色、深度和/或其他特征有关的图像的传感器。例如,视觉传感器184a和184b可以是专题相机、立体相机和/或3d激光扫描仪。3d激光扫描仪包括一个或多个发光的激光器和一个或多个传感器,所述一个或多个传感器收集与发射光的反射有关的数据。例如,3d激光扫描仪可以是飞行时间3d激光扫描仪或基于三角测量的3d激光扫描仪,并且可以包括位置敏感检测器(psd)或其他光学位置传感器。
视觉传感器184a具有机器人180a的工作空间的至少一部分的视野,所述工作空间的至少一部分诸如是包括示例性对象191a的工作空间的部分。尽管在图1中未示出用于对象191a的静止表面,但是这些对象可搁置在桌子、托盘和/或其他表面上。对象191a包括刮刀、订书机和铅笔。在其他实施方式中,可以在如本文所述的机器人180a的抓握尝试的全部或部分期间提供更多对象、更少对象、附加对象和/或替代对象。视觉传感器184b具有机器人180b的工作空间的至少一部分的视野,所述机器人180b的工作空间的至少一部分诸如是包括示例性对象191b的工作空间的部分。尽管在图1中未示出用于对象191b的静止表面,但是它们可以搁置在桌子、托盘和/或其他表面上。对象191b包括铅笔、订书机和眼镜。在其他实施方式中,可以在如本文所述的机器人180b的抓握尝试的全部或部分期间提供更多对象、更少对象、附加对象和/或替代对象。
尽管图1中示出了特定的机器人180a和180b,但是可以使用附加的和/或替代的机器人,包括类似于机器人180a和180b的附加机器人臂、具有其他机器人臂形式的机器人、具有人形形式的机器人、具有动物形式的机器人、通过一个或多个车轮移动的机器人(例如,自平衡机器人)、潜水车辆机器人和无人驾驶飞行器(“uav”)等。而且,尽管在图1中示出了特定的抓握末端执行器,但是可以使用附加的和/或替代的末端执行器,例如替代的冲击式抓握末端执行器(例如,具有抓握“板”的那些、具有更多或更少“数字”/“爪”的那些)、“进入式”抓握末端执行器、“收敛式”抓握末端执行器或“连续”抓握末端执行器或非抓握末端执行器。附加,尽管图1中示出了视觉传感器184a和184b的特定安装,但是可以使用附加的和/或替代的安装件。例如,在一些实施方式中,视觉传感器可以直接安装到机器人,例如机器人的不可致动组件上或机器人的可致动组件上(例如,在末端执行器上或靠近末端执行器的组件上)。而且,例如,在一些实施方式中,视觉传感器可以安装在与其相关联的机器人分离的非固定结构上和/或可以以非固定方式安装在与其相关联的机器人分离的结构上。
机器人180a、180b和/或其他机器人可以用于执行大量的抓握尝试,并且训练示例生成系统110可以利用与抓握尝试相关联的数据来生成训练示例。在一些实施方式中,训练示例生成系统110的全部或方面可以在机器人180a和/或机器人180b上实现(例如,经由机器人180a和180b的一个或多个处理器)。例如,机器人180a和180b每个可以包括训练示例生成系统110的实例。在一些实施方式中,训练示例生成系统110的全部或方面可以在与机器人180a和180b分离但与机器人180a和180b具有网络通信的一个或多个计算机系统上实现。
机器人180a、180b和/或其他机器人的每次抓握尝试由t个单独的时间步骤或实例组成。在每个时间步骤处,存储由执行抓握尝试的机器人的视觉传感器捕获的当前图像
每次抓握尝试生成t个由
由与机器人相关联的传感器生成的数据和/或从生成的数据导出的数据可以存储在机器人本地和/或远离机器人的一个或多个非暂时性计算机可读介质中。在一些实施方式中,当前图像可包括多个通道,例如红色通道、蓝色通道、绿色通道和/或深度通道。图像的每个通道为图像的多个像素中的每个像素定义值,例如用于图像的每个像素的值从0到255。在一些实施方式中,每个训练示例可以包括当前图像和用于对应抓握尝试的附加图像,其中,附加图像不包括抓握末端执行器或者包括具有不同姿势的末端执行器(例如,不与当前图像的姿势重叠的姿势)。例如,可以在任何先前的抓握尝试之后但在用于抓握尝试的末端执行器移动开始之前以及当抓握末端执行器移出视觉传感器的视野时捕获附加图像。可以在任务空间、关节空间或另一空间中表示当前姿势和从抓握尝试的当前姿势到最终姿势的末端执行器运动向量。例如,末端执行器运动向量可以由任务空间中的五个值表示:定义三维(3d)平移向量的三个值以及表示围绕末端执行器的轴的末端执行器的方向变化的正弦-余弦编码的两个值。在一些实施方式中,抓握成功标签是二进制标签,诸如“0/成功”或“1/不成功”标签。在一些实施方式中,抓握成功标签可以从多于两个选项中选择,例如0、1以及0和1之间的一个或多个值。例如,“0”可以指示确认的“未成功抓握(notsuccessfulgrasp)”,“1”可以指示确认的成功抓握,“0.25”可以指示“最可能不成功的抓握(mostlikelynotsuccessfulgrasp)”,“0.75”可以表示“最可能成功抓握(mostlikelysuccessfulgrasp)”。
训练引擎120基于训练示例数据库117的训练示例训练cnn125或其他神经网络。训练cnn125可以包括基于训练示例向cnn125的应用迭代地更新cnn125。例如,当前图像、附加图像以及从训练示例的抓握尝试的当前姿势到最终姿势的向量可以用作训练示例输入;并且抓握成功标签可以用作训练示例输出。经训练的cnn125被训练以预测指示下述概率的度量:鉴于当前图像(以及可选地附加图像,例如至少部分地省略末端执行器的图像)而根据给定的末端执行器运动向量移动抓手并随后抓握将生成成功抓握的概率。
图3是示出执行抓握尝试并存储与抓握尝试相关联的数据的示例方法300的流程图。为方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括机器人的一个或多个组件,例如机器人180a,180b,840的处理器和/或机器人控制系统,和/或其他机器人。此外,虽然方法300的操作以特定顺序示出,但这并不意味着限制。可以重新排序,省略或添加一个或多个操作。
在框352处,系统开始抓握尝试。在框354处,系统存储在没有末端执行器存在于图像中的情况下的环境的图像。例如,系统可以将抓握末端执行器移出视觉传感器的视野(即,不遮挡环境的视野)并且在抓握末端执行器在视野之外的情况下捕获实例处的图像。然后可以存储图像并将其与抓握尝试相关联。
在框356处,系统确定并实施末端执行器移动。例如,系统可以生成一个或多个运动命令以使控制末端执行器的姿势的一个或多个致动器致动,从而改变末端执行器的姿势。
在框356的一些实施方式和/或迭代中,运动命令在给定空间内可以是随机的,给定空间例如是末端执行器可到达的工作空间、末端执行器被限制在其中以供抓握尝试的受限空间和/或由控制末端执行器的姿势的致动器的位置和/或扭矩限制限定的空间。例如,在完成神经网络的初始训练之前,由系统在框356处生成的用于实现末端执行器移动的运动命令在给定空间内可以是随机的。这里使用的随机可以包括真正随机或伪随机。
在一些实施方式中,由系统在框356处生成以用于实现末端执行器移动的运动命令可以至少部分地基于经训练的神经网络的当前版本和/或基于其他标准。在一些实施方式中,在对于每次抓握尝试的框356的第一次迭代中,末端执行器可以基于它在框354处移出视野而“不在适当位置(outofposition)”。在这些实施方式中的一些实施例中,在框356的第一次迭代之前,末端执行器可以随机地或以其他方式“移回到位置(backintoposition)”。例如,末端执行器可以移回到设定的“起始位置(startingposition)”和/或移动到给定空间内的随机选择的位置。
在框358,系统存储:(1)捕获末端执行器和在抓握尝试的当前实例处的环境的图像,以及(2)在当前实例处的末端执行器的姿势。例如,系统可以存储由与机器人相关联的视觉传感器生成的当前图像,并将所述图像与当前实例相关联(例如,利用时间戳)。而且,例如,系统可以基于来自其位置影响机器人的姿势的机器人关节的一个或多个关节位置传感器的数据来确定末端执行器的当前姿势,并且系统可以存储该姿势。系统可以确定并在任务空间、关节空间或其他空间中存储末端执行器的姿势。
在框360处,系统确定当前实例是否是用于抓握尝试的最终实例。在一些实施方式中,系统可以在框352、354、356或358处递增实例计数器和/或随着时间的推移递增时间计数器-并且基于对计数器的值和阈值进行比较来确定当前实例是否是最终实例。例如,计数器可以是时间计数器,并且阈值可以是3秒、4秒、5秒和/或其他值。在一些实施方式中,阈值可以在方法300的一次或多次迭代之间变化。
如果系统在框360处确定当前实例不是用于抓握尝试的最终实例,则系统返回到框356,其中,它确定并实施另一个末端执行器移动,然后进行到框358,其中,它存储图像和在当前实例的姿势。对于给定的抓握尝试,通过框356、358和360的多次迭代,将通过框356的多次迭代来改变末端执行器的姿势,并且在这些实例中的每一个处存储图像和姿势。在许多实施方式中,可以以相对高的频率执行框356、358、360和/或其他框,从而为每次抓握尝试存储相对大量的数据。
如果系统在框360处确定当前实例是用于抓握尝试的最终实例,则系统进行到框362,其中,其致动末端执行器的抓手。例如,对于冲击式抓握器末端执行器,系统可以使一个或多个板、数字和/或其他构件闭合。例如,系统可以使构件闭合,直到它们处于完全闭合位置或者由与构件相关联的扭矩传感器测量的扭矩读数满足阈值。
在框364处,系统存储附加数据并且可选地执行一个或多个附加动作以使得能够确定框360的抓握成功。在一些实施方式中,附加数据是位置读数、扭矩读数和/或来自抓握末端执行器的其他读数。例如,大于某个阈值(例如,1cm)的位置读数可指示成功抓握。
在一些实施方式中,在框364处,系统附加和/或替代地:(1)将末端执行器保持在致动(例如,闭合)位置并且移动(例如,垂直和/或横向)末端执行器和任何可以被末端执行器抓握的对象;(2)存储在移动末端执行器后捕获原始抓握位置的图像;(3)使末端执行器“掉落(drop)”由末端执行器正在抓握的任何对象(可选地在将抓手移回原始抓握位置之后);(4)存储在已经丢弃对象(如果有的话)之后捕获原始抓握位置的图像。系统可以存储在末端执行器和对象(如果有的话)被移动之后捕获原始抓握位置的图像,并且存储在对象(如果有的话)已经被丢弃之后捕获原始抓握位置的图像-并且将所述图像与抓握尝试相关联。比较在末端执行器和对象(如果有的话)被移动之后的图像和在已经丢弃对象(如果有的话)后的图像可以指示抓握是否成功。例如,出现在一个图像中但不出现在另一个图像中的对象可能表示成功抓握。
在框366处,系统重置计数器(例如,实例计数器和/或时间计数器),并且返回到框352以开始另一个抓握尝试。
在一些实施方式中,图3的方法300可以在多个机器人中的每一个上实施,所述机器人可选地在方法300的它们各自的迭代中的一个或多个(例如,全部)期间并行操作。这可以使得能够在给定时间段内实现比如果仅仅一个机器人正在操作方法300更多的抓握尝试。此外,在其中多个机器人中的一个或多个包括相关联的视觉传感器的实施方式中,该视觉传感器具有相对于机器人的姿势,该姿势相对于一个或多个与其他机器人相关联的视觉传感器的姿势是唯一的,基于来自多个机器人的抓握尝试而生成的训练示例可以在基于那些训练示例经训练的神经网络中提供对视觉传感器姿势的鲁棒性。此外,在其中抓握末端执行器和/或多个机器人的其他硬件组件不同地变化和/或磨损和/或其中不同的机器人(例如,相同的制造和/或型号和/或不同的制造和/或型号)与不同的对象(例如,不同大小、不同的重量、不同的形状、不同的透明度、不同的材料的对象)和/或在不同的环境(例如,不同的表面、不同的照明、不同的环境障碍物)中交互的实施方式中,基于来自多个机器人的抓握尝试而生成的训练示例可以提供对各种机器人和/或环境配置的鲁棒性。
在一些实施方式中,在方法300的不同迭代期间,可由给定机器人到达并且可在其上进行抓握尝试的对象可以是不同的。例如,人类操作员和/或另一个机器人可以在机器人的一次或多次抓握尝试之间相对于机器人的工作空间添加和/或移除对象。此外,例如,在成功抓握这些对象之后,机器人本身可能会将一个或多个对象从其工作空间中删除。这可以增加训练数据的多样性。在一些实施方式中,诸如照明、表面、障碍物等的环境因素可以在方法300的不同迭代期间附加和/或替代地不同,这也可以增加训练数据的多样性。
图4是示出基于与机器人的抓握尝试相关联的数据生成训练示例的示例方法400的流程图。为方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括机器人和/或另一计算机系统的一个或多个组件,例如机器人180a、180b、1220的处理器和/或机器人控制系统和/或训练示例生成系统110和/或可选地可以与机器人分开实现的其他系统的处理器。此外,虽然以特定顺序示出方法400的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框452处,系统开始训练示例生成。在框454,系统选择抓握尝试。例如,系统可以访问包括与多个存储的抓握尝试相关联的数据的数据库,并选择所存储的抓握尝试之一。所选择的抓握尝试可以是例如基于图3的方法300生成的抓握尝试。
在框456处,系统基于所选择的抓握尝试的存储数据来确定所选择的抓握尝试的抓握成功标签。例如,如关于方法300的框364所描述的,可以存储附加数据用于抓握尝试以使得能够确定抓握尝试的抓握成功标签。存储的数据可以包括来自一个或多个传感器的数据,其中,在抓握尝试期间和/或之后生成数据。
作为一个示例,附加数据可以是位置读数、扭矩读数和/或来自抓握末端执行器的其他读数。在这样的示例中,系统可以基于读数确定抓握成功标签。例如,在读数是位置读数的情况下,如果读数大于某个阈值(例如,1cm),则系统可以确定“成功抓握”标签-并且如果读数小于某个阈值(例如,1cm)则可以确定“不成功抓握”标签。
作为另一示例,附加数据可以是在末端执行器和对象(如果有的话)被移动之后捕获原始抓握位置的图像和在对象(如果有的话)。已经被丢弃之后捕获原始抓握位置的图像。为了确定抓握成功标签,系统可以比较(1)在末端执行器和对象(如果有的话)被移动后的图像与(2)在对象(如果有的话)已经被丢弃之后的图像。例如,系统可以比较两个图像的像素,并且如果两个图像之间的多于阈值数量的像素不同,则系统可以确定“成功抓握”标签。附加,例如,系统可以在两个图像中的每一个中执行对象检测,并且如果在对象(如果有的话)被丢弃之后捕获的图像中检测到对象但是在末端执行器和对象(如果有的话)被移动后捕获的图像中未检测到对象,则确定“成功抓握”标签。
作为又一个示例,附加数据可以是在末端执行器和对象(如果有的话)被移动之后捕获原始抓握位置的图像。为了确定抓握成功标签,系统可以比较(1)在末端执行器和对象(如果有的话)被移动后的图像与(2)在抓握尝试开始之前获取的环境的附加图像(例如,省略末端执行器的图像)。
在一些实施方式中,抓握成功标签是二元标签,诸如“成功”/“不成功”标签。在一些实施方式中,抓握成功标签可以选自多于两个选项,例如0、1以及0和1之间的一个或多个值。例如,在像素比较方法中,“0”可以指示已确认的“未成功抓握”,并且可以当小于第一阈值数量的像素在两个图像之间不同时被系统选择;“0.25”可以指示“最可能不成功的抓握”并且可以在不同像素的数量从第一阈值到更大的第二阈值时被选择,“0.75”可以指示“最可能成功的抓握”并且可以当不同像素的数量大于第二阈值(或其他阈值)但小于第三阈值时被选择;并且“1”可以表示“确认的成功抓握”,并且可以在不同像素的数量等于或大于第三阈值时被选择。
在框458,系统选择用于抓握尝试的实例。例如,系统可以基于时间戳和/或与将该实例与抓握尝试的其他实例的区分开的数据相关联的其他分界来选择与所述实例相关联的数据。
在框460处,系统基于实例处的末端执行器的姿势和在抓握尝试的最终实例处的末端执行器的姿势来生成用于实例的末端执行器运动向量。例如,系统可以确定抓握尝试的当前姿势和最终姿势之间的变换,并使用变换作为末端执行器运动向量。当前姿势和从抓握尝试的当前姿势到最终姿势的末端执行器运动向量可以在任务空间、关节空间或另一空间中表示。例如,末端执行器运动向量可以由任务空间中的五个值表示:定义三维(3d)平移向量的三个值以及表示围绕末端执行器的轴的末端执行器的方向变化的正弦-余弦编码的两个值。
在框462,系统生成用于实例的训练示例,其包括:(1)用于实例的存储图像,(2)在框460处为实例生成的末端执行器运动向量,以及(3)在框456处确定的抓握成功标签。在一些实施方式中,系统生成训练示例,该训练示例还包括用于抓握尝试的存储的附加图像,例如至少部分地省略末端执行器并且在抓握尝试之前捕获的图像。在这些实施方式中的一些实施方式中,系统将用于实例的存储图像与存储的用于抓握尝试的附加图像连接以生成用于训练示例的连接图像。连接图像包括用于实例的存储图像和存储的附加图像。例如,在两个图像都包括x乘y像素和三个通道(例如,红色、蓝色、绿色)的情况下,连接图像可以包括x乘y像素和六个通道(每个图像三个)。如本文所述,当前图像、附加图像以及从训练示例的抓握尝试的当前姿势到最终姿势的向量可以用作训练示例输入;并且抓握成功标签可以用作训练示例输出。
在一些实施方式中,在框462处,系统可任选地处理图像。例如,系统可以可选地调整图像的大小以适合cnn的输入层的定义大小,从图像中移除一个或多个通道,和/或对深度通道的值进行归一化(在图像包括深度通道的实施方式中)。
在框464处,系统确定所选实例是否是抓握尝试的最终实例。如果系统确定所选实例不是抓握尝试的最终实例,则系统返回到框458并选择另一个实例。
如果系统确定所选实例是抓握尝试的最终实例,则系统进行到框466并确定是否存在附加的抓握尝试要处理。如果系统确定存在附加的抓握尝试要处理,则系统返回到框454并选择另一个抓握尝试。在一些实施方式中,确定是否存在附加抓握尝试要处理可以包括确定是否存在任何剩余的未处理的抓握尝试。在一些实施方式中,确定是否存在附加抓握尝试要处理可以附加地和/或替代地包括确定是否已经生成阈值数量的训练示例和/或是否已经满足其他标准。
如果系统确定没有附加的抓握尝试要处理,则系统进行到框466并且方法400结束。可以再次执行方法400的另一次迭代。例如,可以响应于执行至少阈值数量的附加抓握尝试而再次执行方法400。
尽管为了清楚起见在本文的单独附图中示出了方法300和方法400,但是应当理解,方法400的一个或多个框可以由执行方法300的一个或多个方框的相同组件来执行。例如,方法300和方法400的一个或多个(例如,所有)框可以由机器人的处理器执行。而且,应当理解,方法400的一个或多个框可以与方法300的一个或多个框组合地或在其之前或之后执行。
图5是示出基于训练示例训练卷积神经网络的示例方法500的流程图。为方便起见,参考执行操作的系统描述流程图的操作。该系统可以包括计算机系统的一个或多个组件,例如训练引擎120的处理器(例如,gpu)和/或在卷积神经网络(例如,cnn125)上操作的其他计算机系统。此外,虽然以特定顺序示出方法500的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框552处,系统开始训练。在框554,系统选择训练示例。例如,系统可以选择基于图4的方法400生成的训练示例。
在框556处,系统将用于训练示例的实例的图像和所选训练示例的附加图像应用于cnn的初始层。例如,系统可以将图像应用于cnn的初始卷积层。如本文所述,附加图像可以至少部分地省略末端执行器。在一些实施方式中,系统连接图像和附加图像,并将连接图像应用于初始层。在一些其他实施方式中,图像和附加图像已经在训练示例中连接。
在框558处,系统将所选训练示例的末端执行器运动向量应用于cnn的附加层。例如,系统可以将末端执行器运动向量应用于cnn的附加层,该cnn的附加层是在框556处被应用图像的初始层的下游。在一些实施方式中,为了将末端执行器运动向量应用于附加层,系统将末端执行器运动向量通过完全连接的层以生成末端执行器运动向量输出,并将末端执行器运动向量输出与来自cnn的紧邻的上游层的输出连接。紧邻的上游层紧邻被应用末端执行器运动向量的附加层的上游,并且可选地可以是在框556处应用图像的初始层下游的一个或多个层。在一些实施方式中,初始层是卷积层,紧邻的上游层是池化层,并且附加层是卷积层。
在框560处,系统基于训练示例的抓握成功标签在cnn上执行反向传播。在框562处,系统确定是否存在附加训练示例。如果系统确定存在附加训练示例,则系统返回到框554并选择另一个训练示例。在一些实施方式中,确定是否存在附加训练示例可以包括确定是否存在尚未用于训练cnn的任何剩余训练示例。在一些实施方式中,确定是否存在附加训练示例可以附加地和/或替代地包括确定是否已经利用阈值数量的训练示例和/或是否已经满足其他标准。
如果系统确定不存在附加的训练示例和/或已经满足某些其他标准,则系统进行到框564或框566。
在框564处,cnn的训练可以结束。然后可以提供经训练的cnn以供一个或多个机器人用于伺服抓握末端执行器以实现通过抓握末端执行器成功抓握对象。例如,机器人可以利用经训练的cnn执行图7a的方法700。
在框566处,系统可以附加地和/或替代地提供经训练的cnn以基于经训练的cnn生成附加训练示例。例如,一个或多个机器人可以利用经训练的cnn来执行抓握尝试以及利用来自用于生成附加训练示例的抓握尝试的数据。例如,一个或多个机器人可以利用经训练的cnn来基于图7a的方法700执行抓握尝试,并且利用数据,该数据来自用于基于图4的方法400生成附加训练示例方法的那些抓握尝试。其数据用于生成附加训练示例的机器人可以是实验室/训练设置中的机器人和/或由一个或多个消费者实际使用的机器人。
在框568,系统可以基于响应于在框566提供经训练的cnn而生成的附加训练示例来更新cnn。例如,系统可以通过基于附加训练示例执行框554、556、558和560的附加迭代来更新cnn。
如在框566和568之间延伸的箭头所指示的,可以在框566处再次提供更新的cnn以生成进一步的训练示例,并且在框568处利用那些训练示例以进一步更新cnn。在一些实施方式中,与框566的未来迭代相关联地执行的抓握尝试可以是在时间上比在未来迭代中执行的那些和/或在不使用经训练的cnn的情况下执行的那些更长的抓握尝试。例如,在没有使用经训练的cnn的情况下执行的图3的方法300的实施方式可以具有时间上最短的抓握尝试,用初始经训练的cnn执行的那些可以具有在时间上更长的抓握尝试,用经训练的cnn的下一次迭代执行的那些可以具有在时间上更长的抓握尝试等等。这可以可选地通过方法300的可选实例计数器和/或时间计数器来实现。
图6a和6b示出了各种实施方式的cnn600的示例架构。图6a和6b的cnn600是可以基于图5的方法500训练的cnn的示例。图6a和6b的cnn600是cnn的进一步的示例,cnn一旦被训练,就可以用于基于图7a的方法700来伺服抓握末端执行器。通常,卷积神经网络是多层学习框架,其包括输入层、一个或多个卷积层、可选权重和/或其他层以及输出层。在训练期间,训练卷积神经网络以学习特征表示的层次结构。网络的卷积层与过滤器进行卷积,并可选地通过池化层进行下采样。通常,池化层通过一个或多个下采样功能(例如,最大值、最小值和/或归一化采样)在较小区域中聚合值。
cnn600包括初始输入层663,所述初始输入层663是卷积层。在一些实施方式中,初始输入层663是具有步幅2和64个过滤器的6×6卷积层。具有末端执行器661a的图像和没有末端执行器661b的图像也在图6a中示出。图像661a和661b进一步示出为被连接(由从每个延伸的合并线表示),并且连接图像被馈送到初始输入层663。在一些实施方式中,图像661a和661b每个可以是472像素乘以472像素乘以3个通道(例如,可以从深度通道、第一颜色通道、第二颜色通道、第三颜色通道中选择3个通道)。因此,连接图像可以是472个像素乘以472个像素乘以6个通道。可以使用其他尺寸,例如不同的像素尺寸或更多或更少的通道。图像661a和661b被卷积到初始输入层663。在基于多个训练示例的cnn600的训练期间,了解初始输入层和cnn600的其他层的特征的权重。
初始输入层663之后是最大池化层664。在一些实施方式中,最大池化层664是具有64个过滤器的3×3最大池化层。最大池化层664之后是六个卷积层,其中两个在图6a中被665和666表示。在一些实施方式中,六个卷积层每个是具有64个过滤器的5×5卷积层。卷积层666之后是最大池化层667。在一些实施方式中,最大池化层667是具有64个过滤器的3×3最大池化层。
也在图6a中示出末端执行器运动向量662。末端执行器运动向量662与最大池化层667的输出(如图6a的“+”所示)连接,并且连接输出应用于卷积层670(图6b)。在一些实施方式中,将末端执行器运动向量662与最大池化层667的输出连接包括通过完全连接的层668处理末端执行器运动向量662,然后将其输出通过下述方式逐点地添加到最大池化层667的响应图中的每个点:经由平铺向量669在空间维度上平铺输出。换句话说,末端执行器运动向量662被传递通过完全连接的层668,并经由平铺向量669在最大池化层667的响应图的空间维度上被复制。
现在转向图6b,末端执行器运动向量662和最大池化层667的输出的连接被提供给卷积层670,其后是五个更多的卷积层(在图6b中示出这五个的最后卷积层671,但居间的四个未示出)。在一些实施方式中,卷积层670和671以及四个居间卷积层均为具有64个过滤器的3×3卷积层。
卷积层671之后是最大池化层672。在一些实施方式中,最大池化层672是具有64个过滤器的2×2最大池化层。最大池化层672之后是三个卷积层,其中两个在图6a中被673和674表示。
cnn600的最终卷积层674完全连接到第一完全连接层675,第一完全连接层675又完全连接到第二完全连接层676。完全连接的层675和676可以是向量,例如大小为64的向量。第二完全连接层676的输出用于生成成功抓握的度量677。例如,可以利用sigmoid来生成并输出度量677。在训练cnn600的一些实施方式中,可以利用时期、学习速率、权重衰减、丢失概率和/或其他参数的各种值。在一些实施方式中,一个或多个gpu可以用于训练和/或利用cnn600。尽管图6中示出了特定的卷积神经网络600,但是变化是可能的。例如,可以提供更多或更少的卷积层,一个或多个层可以与作为示例提供的那些不同,等等。
一旦根据本文描述的技术训练cnn600或其他神经网络,就可以利用它来伺服抓握末端执行器。参考图7a,示出了示出利用经训练的卷积神经网络来伺服抓握末端执行器的示例方法700的流程图。为方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括机器人的一个或多个组件,例如机器人180a、180b、840和/或其他机器人的处理器(例如,cpu和/或gpu)和/或机器人控制系统。在实现方法700的一个或多个块时,系统可以在经训练的cnn上操作,该cnn可以例如本地存储在机器人处和/或可以远离机器人存储。此外,虽然以特定顺序示出方法700的操作,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
在框752处,系统生成候选末端执行器运动向量。根据要在其他块中使用的经训练的cnn的输入参数,可以在任务空间、关节空间或其他空间中定义候选末端执行器运动向量。
在一些实施方式中,系统生成在给定空间内是随机的候选末端执行器运动向量,所述给定空间例如是末端执行器可到达的工作空间、其中末端执行器被限制用于抓握尝试的限制空间和/或由控制末端执行器姿势的致动器的位置和/或扭矩限制限定的空间。
在一些实施方式中,系统可以利用一种或多种技术来采样一组候选末端执行器运动向量并从采样组中选择子组。例如,系统可以利用优化技术,例如交叉熵方法(cem)。cem是一种无导数优化算法,其在每次迭代时对一批n值进行采样,将高斯分布拟合到这些样本的m<n,并且然后从该高斯采样新的一批n个值。例如,系统可以利用cem和m=64和n=6的值,并且执行cem的三次迭代以确定最佳可用(根据cem)的候选末端执行器运动向量。
在一些实施方式中,可对可在框752处生成的候选末端执行器运动向量施加一个或多个约束。举例来说,通过cem或其它技术评估的候选末端执行器运动可基于约束被约束。约束的一个示例是人类输入的约束(例如,经由计算机系统的用户接口输入设备),其对可以尝试抓握的区域施加约束,对其上被尝试抓握的特定对象的约束和/或特定对象分类施加约束,等等。约束的另一个例子是计算机生成的约束,其对其中可以尝试抓握的区域施加约束,等等。例如,对象分类器可以基于捕获的图像对一个或多个对象进行分类,并施加限制抓握某些分类的对象的约束。约束的其他示例包括例如基于机器人的工作空间的约束、机器人的关节限制、机器人的扭矩限制、由碰撞避免系统提供以及限制机器人的运动以防止与机器人与一个或多个对象的碰撞的约束,等等。
在框754处,系统识别捕获末端执行器和一个或多个环境对象的当前图像。在一些实施方式中,系统还识别至少部分地省略末端执行器的附加图像,诸如当末端执行器至少部分地不在视觉传感器的视场内时由视觉传感器捕获的环境对象的附加图像。在一些实施方式中,系统连接图像和附加图像以生成连接图像。在一些实施方式中,系统可选地执行图像和/或连接图像的处理(例如,以将大小达到cnn的输入)。
在框756处,系统将当前图像和候选末端执行器运动向量应用于经训练的cnn。例如,系统可以将包括当前图像和附加图像的连接图像应用于经训练的cnn的初始层。系统还可以将候选末端执行器运动向量应用于在初始层下游的经训练的cnn的附加层。在一些实施方式中,在将候选末端执行器运动向量应用于附加层时,系统将末端执行器运动向量传递通过cnn的完全连接层以生成末端执行器运动向量输出,并将末端执行器运动向量输出与cnn的上游输出连接。上游输出来自cnn的紧邻上游层,其紧邻附加层的上游并且在初始层的下游和cnn的一个或多个中间层的下游。
在框758处,系统基于末端执行器运动向量在经训练的cnn上生成成功抓握的度量。基于以下部分来生成度量:在框756处将当前图像(以及可选地附加图像)和候选末端执行器运动向量应用于经训练的cnn,并基于经训练的cnn的了解的权重确定度量。
在框760处,系统基于成功抓握的度量来生成末端执行器命令。举例来说,在一些实施方式中,系统可在框752处生成一个或多个附加候选末端执行器运动向量,且通过下述方式在框758的附加迭代处生成用于那些附加候选末端执行器运动向量的成功抓握的度量:在框756的附加迭代处,将那些和当前图像(以及可选地附加图像)应用到经训练的cnn。框756和758的附加迭代可以可选地由系统并行执行。在这些实施方式中的一些实施方式中,系统可以基于候选末端执行器运动向量的度量和附加候选末端执行器运动向量的度量来生成末端执行器命令。例如,系统可以生成末端执行器命令以完全或基本上符合具有最能指示成功抓握的度量的候选末端执行器运动向量。例如,系统的机器人的控制系统可以生成运动命令,以致动机器人的一个或多个致动器以基于末端执行器运动向量移动末端执行器。
在一些实施方式中,如果没有利用候选末端执行器运动向量来生成新的运动命令(例如,成功抓握的当前度量),则系统还可以基于成功抓握的当前度量来生成末端执行器命令。例如,如果当前度量值与最能指示成功抓握的候选末端执行器运动向量的度量的一个或多个比较未能满足阈值,则末端执行器运动命令可以是“抓握命令”,其导致末端执行器尝试抓握(例如,冲击式抓握末端执行器的紧密数字)。例如,如果当前度量除以最能指示成功抓握的候选末端执行器运动向量的度量的结果大于或等于第一阈值(例如,0.9),则可以生成抓握命令(如果关闭抓手几乎就像当将其移动时产生成功抓握,那么在早期停止抓握的基本原理下)。附加,例如,如果结果小于或等于第二阈值(例如,0.5),则末端执行器命令可以是用于实现轨迹校正的运动命令(例如,将抓握末端执行器“向上”提升至少x米)(在抓握末端执行器很可能没有定位在良好配置并且需要相对大的运动的基本原理下)。而且,例如,如果结果在第一和第二阈值之间,则可以生成基本上或完全符合具有最能指示成功抓握的度量的候选末端执行器运动向量的运动命令。由系统生成的末端执行器命令可以是一组一个或多个命令或一系列组一个或多个命令。
如果没有候选末端执行器运动向量用于生成新的运动命令,则成功抓握的度量可以基于在方法700的前一个迭代中使用的候选末端执行器运动向量的度量和/或基于在框756的附加迭代中,将“空”运动向量和当前图像(以及可选地附加图像)应用到经训练的cnn,并且基于框758的附加迭代生成度量。
在框762处,系统确定末端执行器命令是否是抓握命令。如果系统在块762确定末端执行器命令是抓握命令,则系统进行到块764并实现抓握命令。在一些实施方式中,系统可以可选地确定抓握命令是否导致成功抓握(例如,使用本文描述的技术),并且如果不成功,则系统可以可选地调整末端执行器的姿势并返回到框752。及时在抓握成功的情况下,系统也可以稍后返回到框752以抓握另一个对象。
如果系统在框762确定末端执行器命令不是抓握命令(例如,它是运动命令),则系统进行到框766并实施末端执行器命令,然后返回到框752,其中,它生成另一个候选末端执行器运动向量。例如,在框766处,系统可以实现末端执行器运动命令,该末端执行器运动命令基本上或完全符合具有最能指示成功抓握的度量的候选末端执行器运动向量。
在许多实施方式中,可以以相对高的频率执行方法700的块,从而使得能够迭代更新末端执行器命令并且使得能够沿着由经训练的cnn通知的轨迹伺服末端执行器以导致成功抓握的相对很高的概率。
图7b是说明图7a的流程图的某些块的一些实施方式的流程图。特别地,图7b是说明图7a的块758和760的一些实施方式的流程图。
在框758a,系统基于框752的候选末端执行器运动向量,在cnn上生成成功抓握的度量。
在框758b,系统基于末端执行器的当前姿势确定成功抓握的当前度量。例如,如果没有候选末端执行器运动向量用于基于在方法700的紧接的前一次迭代中使用的候选末端执行器运动向量的度量来生成新的运动命令,则系统可以确定成功抓握的当前度量。而且,例如,系统可以基于下述部分来确定当前度量:在框756的附加迭代处将“空”运动向量和当前图像(以及可选地附加图像)应用于经训练的cnn,并且基于框758的附加迭代生成度量。
在框760a,系统比较框758a和758b的度量。例如,系统可以通过划分度量、减去度量和/或将度量应用于一个或多个函数来比较它们。
在框760b,系统基于框760a的比较生成末端执行器命令。例如,如果框758b的度量除以块758a的度量并且商大于或等于阈值(例如,0.9),则末端执行器运动命令可以是“抓握命令”,其使得末端执行器试图抓握。附加,例如,如果块758b的度量除以块758a的度量并且商小于或等于第二阈值(例如,0.5),则末端执行器命令可以是用于实现轨迹校正的运动命令。而且,例如,如果块758b的度量除以块758a的度量并且商在第二阈值和第一阈值之间,则可以生成基本上或完全符合候选末端执行器运动向量的运动命令。
本文给出了训练cnn和/或利用cnn来伺服末端执行器的特定示例。然而,一些实施方式可以包括与特定示例不同的附加和/或替代特征。例如,在一些实施方式中,可以训练cnn以预测指示下述概率的度量:机器人的末端执行器的候选运动数据将导致成功抓握一个或多个特定对象,例如,特定分类的对象(例如,铅笔、书写用具、刮刀、厨房用具、具有大致矩形构造的对象、柔软对象、最小界限在x和y之间的对象等)。
例如,在一些实施方式中,特定分类的对象可以与其他对象一起被包括以供机器人在各种抓握尝试期间抓握。可以产生其中只有在以下情况下才能找到“成功抓握”抓握标签的训练示例:(1)抓握成功;以及(2)抓握是针对符合特定分类的对象。确定对象是否符合特定分类可以例如基于下述部分被确定:机器人在抓握尝试之后将抓握末端执行器转动到视觉传感器,并且使用视觉传感器捕获通过抓握末端执行器抓握的对象(如果有的话)的图像。然后,人类评论者和/或图像分类神经网络(或其他图像分类系统)可以确定由末端执行器抓握的对象是否是特定分类的-并且该确定用于应用适当的抓握标签。这样的训练示例可以用于训练如本文所述的cnn,并且作为这种训练示例的经训练的结果,经训练的cnn可以用于伺服机器人的抓握末端执行器以实现通过抓握末端执行器成功抓握特定分类的对象。
图8示意性地描绘了机器人840的示例架构。机器人840包括机器人控制系统860、一个或多个操作组件840a-840n以及一个或多个传感器842a-842m。传感器842a-842m可包括例如视觉传感器、光传感器、压力传感器、压力波传感器(例如,麦克风)、接近传感器、加速度计、陀螺仪、温度计和气压计等。虽然传感器842a-m被描绘为与机器人840集成在一起,但这并不意味着限制。在一些实施方式中,传感器842a-m可以例如作为独立单元位于机器人840的外部。
操作组件840a-840n可包括例如一个或多个末端执行器和/或一个或多个伺服马达或其他致动器,以实现机器人的一个或多个组件的运动。例如,机器人840可以具有多个自由度,并且每个致动器可以响应于控制命令在一个或多个自由度内控制机器人840的致动。如本文所使用的,除了可与致动器相关联并且将所接收的控制命令转换成用于驱动执行器的一个或多个信号的任何驱动器之外,术语致动器还包括建立运动的机械或电气设备(例如,电动机)。因此,向致动器提供控制命令可以包括向驱动器提供控制命令,该驱动器将控制命令转换成适当的信号以驱动电气或机械设备以建立期望的运动。
机器人控制系统860可以在诸如机器人840的cpu、gpu和/或其他控制器的一个或多个处理器中实现。在一些实施方式中,机器人840可以包括“脑盒(brainbox)”,这可以包括控制系统860的全部或方面。例如,脑盒可以向操作组件840a-n提供数据的实时突发,其中,每个实时突发包括一组一个或多个控制命令,所述命令除其他之外,指示一个或多个操作组件840a-n中的每一个的运动参数(如果有的话)。在一些实施方式中,机器人控制系统860可以执行本文描述的方法300、400、500和/或700的一个或多个方面。
如本文所述,在一些实施方式中,由控制系统860在定位末端执行器以抓握对象时生成的控制命令的全部或方面可以基于基于诸如经训练的cnn的经训练的神经网络的利用而生成的末端执行器命令。例如,传感器842a-m的视觉传感器可以捕获当前图像和附加图像,并且机器人控制系统860可以生成候选运动向量。机器人控制系统860可以将当前图像、附加图像和候选运动向量提供给经训练的cnn,并利用基于所述应用生成的度量来生成一个或多个末端执行器控制命令,用于控制机器人的末端执行器的移动和/或抓握。尽管图8中将控制系统860示出为机器人840的组成部分,但是在一些实施方式中,控制系统860的全部或方面可以在与机器人840分离但与其通信的组件中实现。例如,控制系统860的全部或方面可以在与机器人840进行有线和/或无线通信的一个或多个计算设备(例如,计算设备910)上实现。
图9是可任选地用于执行本文描述的技术的一个或多个方面的示例计算设备910的框图。计算设备910通常包括至少一个处理器914,其经由总线子系统912与多个外围设备通信。这些外围设备可以包括:存储子系统924,包括例如存储器子系统925和文件存储子系统926;用户接口输出设备920;用户接口输入设备922;和网络接口子系统916。输入和输出设备允许用户与计算设备910交互。网络接口子系统916提供到外部网络的接口并且耦合到其他计算设备中的对应的接口设备。
用户接口输入设备922可以包括键盘;诸如鼠标、跟踪球、触摸板或图形输入板的指示设备;扫描仪;结合到显示器中的触摸屏;诸如语音识别系统的音频输入设备;麦克风和/或其他类型的输入设备。通常,术语“输入设备”的使用旨在包括将信息输入计算设备910或通信网络上的所有可能类型的设备和方式。
用户接口输出设备920可以包括显示子系统、打印机、传真机或诸如音频输出设备的非可视显示器。显示子系统可包括阴极射线管(crt)、诸如液晶显示器(lcd)的平板装置、投影设备或用于生成可见图像的一些其他机构。显示子系统还可以例如通过音频输出设备提供非可视显示。通常,术语“输出设备”的使用旨在包括将信息从计算设备910输出到用户或另一机器或计算设备的所有可能类型的设备以及方式。
存储子系统924存储编程和数据构造,其提供本文描述的一些或所有模块的功能。例如,存储子系统924可以包括执行图3、4、5和/或7a和7b的方法的所选方面的逻辑。
这些软件模块通常由处理器914单独或与其他处理器组合执行。存储子系统924中使用的存储器925可以包括多个存储器,其包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)930和其中存储固定指令的只读存储器(rom)932。文件存储子系统926可以为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、cd-rom驱动器、光盘驱动器或可移动介质盒。实现某些实施方式的功能的模块可以由文件存储子系统926存储在存储子系统924中,或者存储在处理器914可访问的其他机器中。
总线子系统912提供用于使计算设备910的各种组件和子系统按预期彼此通信的机制。虽然总线子系统912被示意性地示为单条总线,但是总线子系统的替代实施方式可以使用多条总线。
计算设备910可以是各种类型,包括工作站、服务器、计算集群、刀片服务器、服务器群或任何其他数据处理系统或计算设备。由于计算机和网络的不断变化的性质,图9中描绘的计算设备910的描述仅旨在作为用于说明一些实施方式的目的的特定示例。计算设备910的许多其他配置可能具有比图9中描绘的计算设备更多或更少的组件。
虽然本文已描述和说明了若干实施方式,但可利用用于执行所述功能和/或获得结果和/或本文中所描述的一个或多个优点的各种其他装置和/或结构,且每一这些变化和/或修改被认为是在本文描述的实施方式的范围内。更一般地,本文描述的所有参数、尺寸、材料和配置旨在是示例性的、并且实际参数、尺寸、材料和/或配置将取决于使用该教导的特定应用。本领域技术人员将认识到或能够使用不超过常规的实验确定本文所述特定实施方式的许多等同物。因此、应该理解,前述实施方式仅作为示例呈现,并且在所附权利要求及其等同物的范围内,可以以不同于具体描述和要求保护的方式实施实施方式。本公开的实施方式涉及本文描述的每个单独的特征、系统、物品、材料、套件和/或方法。此外,如果这些特征、系统、物品、材料、套件和/或方法不相互矛盾,则在本公开的范围内包括两个或更多个这样的特征、系统、物品、材料、套件和/或方法的任何组合。
- 还没有人留言评论。精彩留言会获得点赞!