一种基于仿真工业机器人的运动学自抓取学习方法和系统与流程
本发明属于计算机辅助制造领域,更具体地,涉及一种基于仿真工业机器人的运动学自抓取学习方法和系统。
背景技术:
以六关节机械手为代表的工业机器人在功能和应用上已趋于完善,机器人现在已经广泛应用于各种任务当中,如喷涂、码垛、搬运、包装、焊接、装配等任务大都使用机器人代替人工作业。机器人的使用极大地解放了人力,提高了安全系数,提高了生产效率与质量。
然而,当前工业生产中使用的机器人智能化水平仍然比较低。即便在自动化水平比较高的生产线上,机器人的动作通常也需要操作者事先进行动作示教或者需要对特定任务进行离线编程。这一过程需要工程师熟悉专业知识,对生产过程有充分了解,进行科学的设计,准确的计算和耐心的编程。这一过程不仅对操作者的技术水平要求极高,而且缺乏可扩展性,即使只是操作对象形状、位置、摆放角度或者背景环境有细微的改变,都需要系统停机,重新进行示教或离线编程,进行复杂的修改,浪费人力的同时极大地降低了生产效率,提高了生产成本。
技术实现要素:
针对现有技术的以上缺陷或改进需求,本发明提供了一种基于仿真工业机器人的运动学自抓取学习方法和系统,其目的在于基于仿真环境并利用强化学习理论对机器人进行训练,由此实现机器人抓取自我学习能力,提高机器人程序的扩展性,当抓取对象发生改变时,不必对抓取程序进行大的修改,极大地提高了机器人在工业上的应用范围和实际生产中的工作效率。
为实现上述目的,本发明提供了一种基于仿真工业机器人的运动学自抓取学习方法,所述方法包括以下步骤:
(1)建立仿真机器人环境,并在仿真机器人环境中导入待训练机器人、工具和目标物品;
(2)实时获取当前仿真机器人采集的图像;
(3)将当前采集的图像输入到动作选择网络中,所述动作选择网络先对图像进行预处理,之后提取图像特征识别图像中目标物品和机器人手爪,并分析出机器人手爪当前应该做出运动的概率分布,根据所述概率分布做出决策,输出机器人控制指令;
(4)仿真机器人执行所述控制指令对目标物品进行抓取,并根据抓取结果输出奖励值;
(5)将当前采集的图像和前一次采集的图像输入价值估计网络中,所述价值估计网络从两张图像中提取图像特征,并对所有图像特征进行分析结合,输出当前累计奖励值的估计值;同时,根据当前奖励值和估计值,作为标签对所述价值估计网络进行一次反向传播,完成一次价值估计网络的训练;
(6)根据累计奖励的估计值及机器人控制指令,对动作选择网络进行一次训练;
(7)判断训练时间是否达到预设时间,或者判断抓取准确率是否达到预设值,若没有,则返回步骤(2),否则完成机器人抓取学习。
进一步地,所述步骤(3)中对图像进行预处理包括以下子步骤:
(11)运用模版匹配技术在图像上定位出抓取手抓的像素位置locationt;
(12)以locationt为中心,分别在原图上剪裁出尺寸为l×l和2l×2l的图片块x1,x2;
(13)将图片块x2调整为尺寸为l×l的图片块x’2;
(14)模拟人眼注视特定位置时看到的景象,使两种图片块x1,x’2在通道维度上拼接得到图像xt。
进一步地,所述步骤(3)中通过卷积单元的叠加组成特征提取网络从图片xt中提取图像特征,所述卷积单元包括5个通道,其中:
通道1,4,5中包含有1x1卷积操作,1x1卷积操作的目的是为减少网络参数,减小过拟合风险;同时加深网络的深度,增强网络的非线性;
通道2,4,5通过不同感受野获取输入层的不同尺度的信息,减弱矩阵的稀疏性问题;
通道1将集中于边缘特征;
通道3保留输入层的所有信息,避免因网络层数的增加而导致的特征信息的丢失。
进一步地,所述步骤(3)中使用三层全连接结构构建分析网络分析出机器人手爪当前应该做出运动的概率分布,所述分析网络接收由特征提取网络提取出来的图像特征,图像特征中包含机器人手爪及目标物体的几何位置与位姿信息。
进一步地,所述步骤(3)中采用全连接网络模型构建专一网络,所述专一网络只针对指令信息的一个维度进行分析,得到单维度的动作概率分布;通过6个专一网络即可得到机器人位置和姿态6个维度的指令。
另一方面,本发明还提出了一种基于仿真工业机器人的运动学自抓取学习系统,所述系统包括依次执行的以下部分:
建模部分,用于建立仿真机器人环境,并在仿真机器人环境中导入待训练机器人、工具和目标物品;
图像采集部分,用于实时获取当前仿真机器人采集的图像;
指令获取部分,用于将当前采集的图像输入到动作选择网络中,先对图像进行预处理,之后提取图像特征识别图像中目标物品和机器人手爪,并分析出机器人手爪当前应该做出运动的概率分布,根据所述概率分布做出决策,输出机器人控制指令;
奖励反馈部分,用于使仿真机器人执行所述控制指令对目标物品进行抓取,并根据抓取结果输出奖励值;
价值估计部分,用于将当前采集的图像和前一次采集的图像输入价值估计网络中,所述价值估计网络从两张图像中提取图像特征,并对所有图像特征进行分析结合,输出当前累计奖励值的估计值;
学习升级部分,用于根据当前奖励值和估计值,作为标签对所述价值估计网络进行一次反向传播,完成一次价值估计网络的训练;同时,根据累计奖励的估计值及机器人控制指令,对动作选择网络进行一次训练;
流程控制部分,用于判断训练时间是否达到预设时间,或者判断抓取准确率是否达到预设值,若没有,则返回图像采集部分,否则完成机器人抓取学习。
进一步地,所述指令获取部分中包括预处理模块,所述预处理模块具体包括以下单元:
第一单元,用于运用模版匹配技术在图像上定位出抓取手抓的像素位置locationt;
第二单元,用于以locationt为中心,分别在原图上剪裁出尺寸为l×l和2l×2l的图片块x1,x2;
第三单元,用于将图片块x2调整为尺寸为l×l的图片块x’2;
第四单元,用于模拟人眼注视特定位置时看到的景象,使两种图片块x1,x’2在通道维度上拼接得到图像xt。
进一步地,所述指令获取部分中包括特征提取模块,所述特征提取模块用于通过卷积单元的叠加组成特征提取网络从图片xt中提取图像特征,所述卷积单元包括5个通道,其中:
通道1,4,5中包含有1x1卷积操作,1x1卷积操作的目的是为减少网络参数,减小过拟合风险;同时加深网络的深度,增强网络的非线性;
通道2,4,5通过不同感受野获取输入层的不同尺度的信息,减弱矩阵的稀疏性问题;
通道1将集中于边缘特征;
通道3保留输入层的所有信息,避免因网络层数的增加而导致的特征信息的丢失。
进一步地,所述指令获取部分中包括分析网络模块,所述分析网络模块用于使用三层全连接结构构建分析网络分析出机器人手爪当前应该做出运动的概率分布,所述分析网络接收由特征提取网络提取出来的图像特征,图像特征中包含机器人手爪及目标物体的几何位置与位姿信息。
进一步地,所述指令获取部分中包括6个专一网络模块,所述专一网络模块用于采用全连接网络模型构建专一网络,所述专一网络只针对指令信息的一个维度进行分析,得到单维度的动作概率分布;通过6个专一网络模块即可得到机器人位置和姿态6个维度的指令。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
(1)本技术方案是基于仿真环境并利用强化学习理论进行机器人抓取训练,相对于传统的机器人抓取应用的优势在于,机器人可以通过自我尝试,自我学习,可以通过相机拍摄的图像自动获取物体的位置信息,决定机器人末端抓取工具的抓取位置;同时,基于强化学习的图像处理方法可根据观察到的图像中被抓取物体形状和摆放状态,决定抓取工具的姿态,最终成功抓取形状各异、随意摆放的物品;本方案中机器人智能抓取技术可应用于很多工业与生活场景,工业中,它可以简化传统机器人的抓取、分拣、码垛等工作编程的复杂性,提高机器人程序的扩展性,当抓取对象发生改变时,不必对抓取程序进行大的修改,极大地提高了机器人在工业上的应用范围和实际生产中的工作效率;在日常应用方面,由于服务类机器人面对任务的多样性,需要抓取的物品在形状、质量、质地、摆放状态等更是千差万别,因此实现机器人抓取的智能化将会使机器人在走进生活方面实现大的跨越;因此本技术方案抓取学习方法具有较强的现实意义;
(2)本技术方案设计了一种动作选择网络,用于扮演人脑在人类抓取过程中的角色,其功能是每次观察从相机传来的实时图像,并分析出当前智能机器人应该执行的控制指令,即机器人当前应该执行的移动;所述动作选择网络具有很强的图像特征提取能力,能够解析出图像中特征位置和实际机器人基坐标系下物体位置的关系,从而指导机器人执行某一基坐标系下的控制指令;
(3)本技术方案设计了一种价值估计网络,价值估计网络由卷积神经网络和全连接网络组成,可以估计当前决策网络所做出的决策指令的回合折算奖励值,这就像小孩子在学习拿取物品时,一旁的大人对其当前动作作出评价,在每次迭代中,通过奖励值估计网络估计出来的奖励值更新决策网络。
附图说明
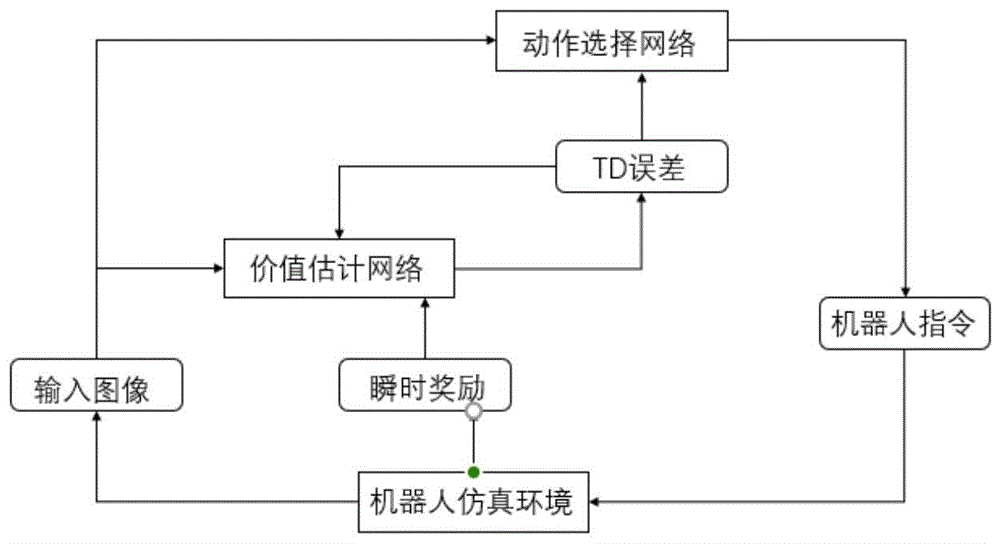
图1是本发明方法的整体流程图;
图2是本发明中动作选择网络的结构示意图;
图3是本发明中特征提取网络卷积单元的结构示意图;
图4是本发明中价值估计网络的结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示为本发明方法的流程图,本发明方法包括以下步骤:
(1)建立仿真机器人环境,并在仿真机器人环境中导入需要训练的机器人、需要用到的工具及要抓取的工具。
(2)以机器人的视角获取当前仿真机器人环境的图像,并剪裁处理成224*224*3(rgb)图像,以便神经网络处理。
(3)将224*224*3图像输入动作选择网络,经多个卷积层提取特征,并通过全连接层最后输出六维指令,对应机器人x,y,z,a,b,c(位置,姿态)六个方向的指令。
(4)当动作选择网络输出的指令传入仿真机器人后,机器人到达指定位置执行指令,并判断是否抓取成功,以输出奖惩奖励值。
(5)将相邻两次的224*224*3图像输入价值估计网络中,输入出一维值,为当前价值估计网络对当前环境累计奖励值的估计,根据当前奖励及对后一次的估计值,作为标签对价值估计网络进行一次反向传播,完成一次c网络的训练。
(6)根据对当前累计奖励的估计值,及当前指令的选择,对动作选择网络进行一次训练。
(7)循环以上步骤,直到在仿真环境中的抓取准确率达到95%或训练时间达到36小时停止训练。
如图2所示为动作选择网络的结构示意图,根据功能的不同,动作选择网络可分为预处理模块、特征提取模块、分析网络模块和专一网络模块,每个模块将各自的输入映射为固定长度的特征向量,以向所连接的其他模块传递信息;各个模块均由神经网络或其变体实现。
预处理模块将输入图片整理为规则形状以利于后面处理;
特征提取模块使用多层卷积网络从预处理后图像中提取图像特征。通过大小不同的感受野收集各种不同的特征。在借鉴inception网络结构思想和残差网络结构思想的基础上,设计了卷积单元,并通过卷积单元的叠加组成特征提取网络。卷积单元结构如图3所示。
分析网络模块选择的是善于分析和作出决策的全连接网络模型;使用了三层全连接结构。分析网络接收由特征提取网络模块提取出来的高级特征。在其只中蕴含着手爪位置及被抓取物体等几何位置与位姿信息。分析网络用于将这些特征分析结合起来,获得对原图像信息的总体理解。
专一网络模块采用较窄的全连接网络模型,只针对指令信息的某一个维度进行分析,只得到单维度的动作概率分布。专一网络模块设计的目的是为了减轻网络过宽而带来的过拟合问题,将问题分解到六个维度即可以很好地将注意力集中在单一维度上,又可以减少网络的参数个数,进而降低网络过拟合风险。
如图4所示为本发明中价值估计网络的结构示意图,由于输入类型的一致性及所分析问题的相似性,价值估计网络结构与动作选择网络结构相似,但是由于完成功能的不同,两者的输出不同。价值估计网络的结构可以归纳为:预处理模块;特征提取网络;全连接网络;与动作选择网络有专一网络对其输出所控制的各个轴有专一的分析不同的是,价值估计网络直接输出对当前状态价值期望的估计。
以下为采用本发明方法的实施例,该实施例包括以下步骤:
(1)本实施例所训练的机器人选择hsr605机器人,从机器人库中导入后同时导入相应工具及工件,作为强化学习训练环境。
(2)训练过程,在智能机器人抓取训练中,globalagent和并行agent都是actor-critic结构框架。假设globalagent中抓取决策网络参数标记为θπ,奖励估计网络参数标记为θv;异步并行agent个数为m,并标记第i个agent的抓取决策网络参数为θiπ,奖励估计网络参数标记为
创建globalagent,并初始化参数θπ,θv;
并行创建agent(1)~agent(m)及其与之交互的环境对象;
分别对用θπ初始化θiπ;用θv初始化
在每个异步环境中,执行第1~n轮抓取尝试;
在每次抓取尝试中,执行第1~t次动作;
在第n轮抓取尝试第t次动作执行中:
agent从环境获得
根据
从环境中接收奖励
第n轮抓取尝试结束,由:
并根据
同时计算dθiπ,
根据dθiπ,
每执行k轮抓取尝试,从globalagent重新更新参数;分别对用θπ初始化θiπ;用θv初始化
θiπ←θπ;
(3)当达到指定抓取准确率或达到指定训练时长则结束训练。
以上内容本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!