一种基于Q学习的Baxter机械臂智能优化控制方法
一种基于q学习的baxter机械臂智能优化控制方法
技术领域
1.本发明属于控制技术领域,具体提供了一种基于q学习的baxter机械臂智能优化控制方法,是一种智能控制方法。
背景技术:
2.在现代科技飞速发展的今天,机械臂以其小巧灵活,操作简单,灵活多样等特点,始终处于科技的前沿,一直引领着高新技术的方向。随着人工智能和计算机大数据时代的到来,人类总是期望机械臂能够具有更加强大的自主化能力,以代替我们在更多的邻域完成更加复杂危险的操作任务,为实现这一目标,其核心技术就是需要机械臂具有优良的运动规划能力,使机械臂在无人干扰的条件下也可以在未知的环境中有目的,准确高效的工作。
3.机械臂动力学方程是非线性,现有的控制方法大多数是基于模型,如pid控制、模糊控制、滑模变结构控制等,虽然很多线性方法在机器人控制中得到广泛应用,但经过线性化的模型与机器人的实际模型仍然有差别,并且经过线性化对机器人建模十分困难,当模型不精确时,甚至可能起反作用。
技术实现要素:
4.为了克服现有技术的不足,本发明提供了一种基于q学习的智能优化控制方法,它是一种基于数据驱动的控制算法,并不需要系统模型,它通过系统以往的历史数据构造出近似的模型来逼近真实情况,在误差允许的范围内,单从结果上和精确的模型是等效的。实验结果验证了该方法的有效性。
5.本发明为解决上述技术问题提供了如下技术方案:
6.一种基于q学习的baxter机械臂智能优化控制方法,包括以下步骤:
7.步骤1)建立一个非线性机械臂动力学方程:
[0008][0009]
其中q,分别表示机械臂角度,角速度,角加速度,向量m(q)表示机械臂惯性矩阵,表示机械臂科氏力矩向量,g(q)表示机械臂重力矩向量,τ(k)表示第k步的机械臂控制力矩向量,表示模型不确定性,u(k)表示第k步的控制策略;
[0010]
考虑机器人动力学模型已知,定义为便于分析,将式(1)转化成如下状态空间模型:
[0011][0012]
y(k)=x(k)
[0013]
其中
[0014]
x(k)是第k步的状态,y(k)是第k步的系统输出,
[0015]
o3×3表示3行3列的零矩阵,i3×3表示3行3列的单位矩阵,n(x1,x2)表示采点个数,
‑
m
‑1(x1)表示惯性矩阵的逆矩阵。
[0016]
步骤2)q
‑
learning算法设计,过程如下:
[0017]
定义一个基于稳定策略u(0)的q函数
[0018]
q
u(0)
(x(k),u(k))=c(x(k),u(k))+γv
u
(x(k+1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0019]
其中v
u(0)
(x(k+1))是第k+1步系统价值函数,
[0020]
x(k+1)是第k+1步的状态,
[0021]
c(x(k),u(k))=u
t
ru+y
t
(k)q
u(0)
(x(k),u(k))y(k)
[0022][0023]
γ是折扣因子,r和u是系统加权矩阵,一旦可以使用数据识别q
u(0)
(x(k),u(k)),那么根据式(4),得到改进的策略u(x(k)):
[0024][0025]
在lqr情况下,q函数(3)在稳定策略u(x(k))=f*x(k)下显式表示为式(5)
[0026][0027]
其中p是黎卡提方程解,h
u
是在控制策略u(x(k))下系统内核矩阵,是内核矩阵里面的分块矩阵,基于(4),改进策略u(x(k))的状态反馈增益f由式(6)得:
[0028][0029]
计算q
‑
函数和改进策略的过程是交替进行的,那么对于lqr情形,策略保证收敛到最优策略;对改进的策略u(x(k))评估,其核心是确定h
u
;
[0030]
将式(5)代入式(3)中,得到temporal difference误差,
[0031][0032]
其中其中表示kronecker内积操作,vec(
·
)是一种矢量化操作,从(7)可以看出,通过使用可用数据x(k),u(k)和x(k+1)最小化td误差来识别h,这是一个线性回归问题,采用随机梯度下降sgd或递推最小二乘ls方法解决所述线性回归问题。
[0033]
进一步,考虑到一个应用的目标策略u(x(k)),使用递归ls方法来识别相应的h
u
,
对于某些大常数β和给定初始值递推关系如下所示:
[0034][0035][0036]
其中,i和j表示循环次数,i是单位矩阵,表示第j次的内核矩阵,表示第j+1次的内核矩阵,表示第i次下的第j次的矩阵,表示第i次下的第j+1次的矩阵;
[0037]
选择目标策略加上白噪声或简单白噪声之和作为行为策略u(x(k)),由于h是具有(n+k)(n+k+1)/2个未知参数的对称矩阵,因此可以用至少(n+k)(n+k+1)/2个数据集来识别它。
[0038]
本发明提供了一种基于q学习的智能优化控制方法,具体地说,先定义一个q函数,然后建立temporal difference(td)误差方程,h矩阵是td误差方程里面的一个矩阵,可以通过使用可用数据x(k),u(k)和x(k+1)来最小化td误差来识别,误差收敛之后,h矩阵就可以确定,通过h矩阵可以确定反馈增益,从而得到最优控制策略。
[0039]
实验所用机器人平台为baxter机器人,baxter机器人是美国rethink robotics公司研发的一款双臂机器人,其单机械臂是一种具有七自由度的冗余柔性关节机械臂。通过移动底座支撑机器人本体,机器人手臂采用旋转关节连接刚性连杆,关节处采用弹性制动器连接,即通过电机、减速器串联弹簧带动负载,在人机协作或外部冲击下起到保护人或机器人本体的作用.柔性关节还可通过霍尔效应检测角度偏差。在baxter关节处都具有力矩传感器.手臂前后端通过26w和63w伺服电机驱动,通过14bit编码器实现关节角度的读取。baxter机器人为基于ros(robot operating system)操作系统的开源机器人,通过linux平台运行,用户可通过网络与机器人内部计算机互联读取信息或发送指令,或通ssh远程控制在内部计算机运行相关程序.利用baxter相关的sdk(software development kit),通过ros的api(application programming interface)可以实现对baxter机器人的信息读取与实时控制.baxter中的sdk可以提供相关函数接口与重要工具:如gazebo仿真器及moveit移动软件包等.baxter机器人在力矩控制模式下,还需设置补偿力矩以抵消机械臂重力和关节支撑弹簧形变带来的影响。
附图说明
[0040]
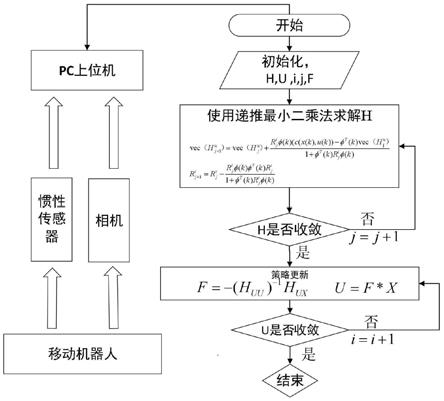
图1是q
‑
learning算法流程图。
[0041]
图2是反馈增益变化图。
[0042]
图3是机械臂价值函数变化图。
[0043]
图4是机械臂控制效果图。
具体实施方式
[0044]
以下结合附图详细说明和陈述了本发明的实施方式,但并不局限于上述方式。在本领域的技术人员所具备的知识范围内,只要以本发明的构思为基础,还可以做出多种变
化和改进。
[0045]
参照图1~图4,一种基于q学习的baxter机械臂智能优化控制方法,所述方法包括以下步骤:
[0046]
步骤1)建立一个非线性机械臂动力学方程:
[0047][0048]
其中q,分别表示机械臂角度,角速度,角加速度,向量m(q)表示机械臂惯性矩阵,表示机械臂科氏力矩向量,g(q)表示机械臂重力矩向量,τ(k)表示第k步的机械臂控制力矩向量,表示模型不确定性,u(k)表示第k步的控制策略;
[0049]
考虑机器人动力学模型已知,定义为便于分析,将式(1)转化成如下状态空间模型:
[0050][0051]
y(k)=x(k)
[0052]
其中
[0053]
x(k)是第k步的状态,y(k)是第k步的系统输出,o3×3表示3行3列的零矩阵,i3×3表示3行3列的单位矩阵,n(x1,x2)表示采点个数,
‑
m
‑1(x1)表示惯性矩阵的逆矩阵;
[0054]
步骤2)q
‑
learning算法设计,过程如下;
[0055]
定义一个基于稳定策略u(0)的q函数
[0056]
q
u(0)
(x(k),u(k))=c(x(k),u(k))+γv
u
(x(k+1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0057]
其中v
u(0)
(x(k+1))是第k+1步系统价值函数,
[0058]
x(k+1)是第k+1步的状态,
[0059]
c(x(k),u(k))=u
t
ru+y
t
(k)q
u(0)
(x(k),u(k))y(k)
[0060][0061]
γ是折扣因子,r和u是系统加权矩阵,一旦可以使用数据识别q
u(0)
(x(k),u(k)),那么根据式(4),得到改进的策略u(x(k)):
[0062][0063]
在lqr情况下,q函数(3)在稳定策略u(x(k))=f*x(k)下显式表示为式(5)
[0064][0065]
其中p是黎卡提方程解,h
u
是在控制策略u(x(k))下系统内核矩阵,是内核矩阵里面的分块矩阵,基于(4),改进策略u(x(k))的状态反
馈增益f由式(6)得:
[0066][0067]
计算q
‑
函数和改进策略的过程是交替进行的,那么对于lqr情形,策略保证收敛到最优策略;对改进的策略u(x(k))评估,其核心是确定h
u
;
[0068]
将式(5)代入式(3)中,得到temporal difference误差,
[0069][0070]
其中其中表示kronecker内积操作,vec(
·
)是一种矢量化操作,从(7)可以看出,通过使用可用数据x(k),u(k)和x(k+1)最小化td误差来识别h,这是一个线性回归问题,采用随机梯度下降sgd或递推最小二乘ls方法解决所述线性回归问题。
[0071]
进一步,考虑到一个应用的目标策略u(x(k)),使用递归ls方法来识别相应的h
u
,对于某些大常数β和给定初始值递推关系如下所示:
[0072][0073][0074]
其中,i和j表示循环次数,i是单位矩阵,表示第j次的内核矩阵,表示第j+1次的内核矩阵,表示第i次下的第j次的矩阵,表示第i次下的第j+1次的矩阵;
[0075]
选择目标策略加上白噪声或简单白噪声之和作为行为策略u(x(k)),由于h是具有(n+k)(n+k+1)/2个未知参数的矩阵,因此可以用至少(n+k)(n+k+1)/2个数据集来识别它。
[0076]
本实施例的基于q学习的智能优化控制方法,有别于基于价值的方法,基于q学习的强化学习方法直接尝试优化策略函数实现跟踪。对于已知的机械臂系统,通过可用数据x(k),u(k)和x(k+1)用递推最小二乘(ls)方法最小化td误差来识别h。直到h收敛后,通过h矩阵可以求得反馈增益f,从而可以得到跟新的策略,循环以上步骤可得到最优控制策略。包括以下步骤:
[0077]
1)机械臂运动模型及平台介绍
[0078]
2)q
‑
learning算法设计
[0079]
进一步,所述步骤1),实验所用机器人平台为baxter机器人,其单机械臂是一种具有七自由度的冗余柔性关节机械臂。机器人手臂采用旋转关节连接刚性连杆,关节处采用弹性制动器连接,即通过电机、减速器串联弹簧带动负载,在人机协作或外部冲击下起到保护人或机器人本体的作用.柔性关节还可通过霍尔效应检测角度偏差。在baxter关节处都具有力矩传感器.手臂前后端通过26w和63w伺服电机驱动,通过14bit编码器实现关节角度的读取。
[0080]
由(2)已知系统的状态空间模型
[0081]
[0082]
y(k)=x(k)
[0083]
初始化x=[0,0,0,0,0,0],u=[1,1,1];
[0084]
进一步,所述步骤2)中,由于h是具有(n+k)(n+k+1)/2个未知参数的矩阵,因此可以用至少(n+k)(n+k+1)/2个数据集来识别它。通过(2)和(6)可以得到可用数据x(k),u(k)和x(k+1),通过可用数据x(k),u(k)和x(k+1)用递推最小二乘(ls)方法最小化td误差来识别h,当h收敛后,更新一次f,循环上述步骤直到f收敛结束循环,最终得到
[0085][0086][0087]
从实验结果可以看出,基于q学习的智能优化控制方法对其运动轨迹有着良好控制效果。
[0088]
以上结合附图详细说明和陈述了本发明的实施方式,但并不局限于上述方式。在本领域的技术人员所具备的知识范围内,只要以本发明的构思为基础,还可以做出多种变化和改进。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1