一种空间机械臂与未知环境接触过程的智能柔顺操控方法
1.本发明属于空间机器人智能控制领域,具体涉及一种空间机械臂与未知环境接触过程的智能柔顺操控方法。
背景技术:
2.空间机械臂在现代空间任务中发挥着越来越重要的作用,如空间碎片清理、在轨组装与维护、非合作航天器抓捕与破坏等。空间机械臂抓捕目标通常可分为抓捕前、抓捕中、抓捕后三个阶段,本发明考虑抓捕中阶段,若机械臂末端位置存在控制误差或待抓捕/接触目标的位置存在测量误差,则末端工具与目标表面的接触就会产生接触力,其大小与接触刚度和形变量成正比,一旦接触力过大就会损坏所抓取的物体甚至破坏空间机械臂系统,因此亟需对末端接触过程施加安全控制。
3.阻抗控制(也称导纳控制)是一种控制末端接触过程的柔顺算法,1985年由hogan首次提出,其将末端工具的位姿与接触力/力矩之间的关系视为一个弹簧-质量-阻尼系统,可通过测量接触力对末端位姿进行实时修正,在现代机械臂柔顺控制中被广泛应用。传统阻抗控制中,力与位置之间是一对相互矛盾的指标,且阻抗参数通常固定或需要已知环境参数,在解决这些问题的方案中,自适应控制无法实现力与位置的最优权衡(cn202011169349.x,cn202010087388.9),迭代学习控制方法需要重复训练(y.li and s.s.ge,"impedance learning for robots interacting with unknown environments,"in ieee transactions on control systems technology,vol.22,no.4,pp.1422-1432,2014),基于模型辨识的方法则增加了算法的复杂性(cn202010226048.x)。考虑到强化学习在处理最优控制与无模型控制方面具有较大的优势,本发明将自适应/近似动态规划算法应用到最优阻抗控制问题求解中。积分强化学习作为一种处理连续系统最优控制问题的自适应/近似动态规划算法,在诸多领域得到了应用。但是目前积分强化学习算法在处理状态不完全可测、模型完全未知问题时存在依赖初始稳定控制策略、状态重构受噪声影响大等问题(h.modares,f.l.lewis and z.-p.jiang,"optimal output-feedback control of unknown continuous-time linear systems using off-policy reinforcement learning,"in ieee transactions on cybernetics,vol.46,no.11,pp.2401-2410,2016.),因此提出一种基于测量数据的无模型值迭代积分强化学习算法,并成功应用于空间机械臂阻抗控制中,能够有效保证机械臂操纵的成功率,增强机械臂系统的可靠性。
技术实现要素:
4.针对现有机械臂阻抗控制算法中无法实现接触力与位置的最优控制、阻抗参数固定或需要已知环境参数、需要重复训练等问题,本发明提供一种空间机械臂与未知环境接触过程的智能柔顺操控方法,其基于状态观测器的连续系统积分强化学习算法,具有自主学习、不依赖模型和全状态测量信息等优点,可应用于空间机械臂最优阻抗控制。
5.为达到上述目的,本发明采用的技术方案为:
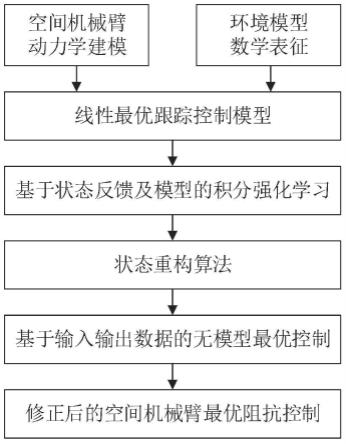
6.针对空间机械臂抓捕非合作目标接触过程的控制问题,首先,根据将空间机械臂视为一类多体系统,利用凯恩方程建立一套通用动力学模型,并对接触过程中未知的环境模型进行数学表征;其次,基于简化的数学模型设计依赖全状态反馈和部分模型信息的积分强化学习算法;然后,设计状态重构算法,与积分强化学习算法融合得到基于测量数据的无模型积分强化学习算法;最后,对算法进行修正,扩展并应用至空间机械臂最优阻抗控制中,完成环境接触模型未知和状态不完全可测情况下的安全智能柔顺控制。具体实施步骤如下:
7.(1)根据凯恩方程与多体动力学理论,建立空间机械臂系统的通用动力学模型,并对环境接触模型进行数学表征;
8.利用凯恩方程进行多体动力学建模的一般形式可以写为:
[0009][0010]
其中和分别表示系统第k阶广义主动力和广义惯性力,n是系统所有广义速率写成分量列阵形式,分量列阵的个数。选取空间机械臂系统的广义速率为:
[0011][0012]
其中,和分别表示基座的速度和角速度在基座本体坐标系中的分量,表示第i个机械臂关节的角速度。通过凯恩方程进行规范化推导,可以得到空间机械臂系统的动力学模型为:
[0013][0014]
其中为υ的导数,η为系统全局质量阵,f
non
为系统全局非线性项,fa表示广义主动力为:
[0015][0016]
其中f0是基座受到的推力在基座本体坐标系中的分量列阵,rb是f0作用点在基座本体坐标系中的矢径,t0是基座受到的力矩在基座本体坐标系中的分量列阵,ti是第i个电机转子的驱动力矩,0矩阵具有其对应的广义速率相容的维数;下标“i-1”和“2m-i”分别表示有i-1和2m-i个0矩阵,上标“t”表示矩阵的转置;对于任意三维列向量χ=[χ
1 χ
2 χ3]
t
,上标“~”的定义为其中标量χ1、χ2、χ3为向量χ中的元素。
[0017]
对于目标位置固定的抓捕任务中,空间机械臂末端与环境的接触力fe的数学模型可表征为:
[0018][0019]
式中,ge表示环境模型的刚度系数,ce为阻尼系数,me为质量系数,x表示机械臂末端位置在惯性系中的分量,分别表示x的一阶导数和二阶导数,xe表示目标位置在惯性系中的分量。
[0020]
阻抗控制模型的表达式为:
[0021][0022]
式中,md、cd、gd分别表示阻抗模型的期望惯量、阻尼、刚度参数,xd表示机械臂末端的期望位置。
[0023]
将环境模型与阻抗模型相加,得到:
[0024][0025]
其中,f=gd(x-xd)为控制输入。
[0026]
取状态变量控制输入取u=f,则可以得到阻抗控制模型的线性状态方程形式:
[0027][0028]
其中表示x的导数,re=xe表示环境位置输入,
[0029]
c=[0 ι]。
[0030]
(2)忽略环境位置信息,将接触模型简化为一般的最优跟踪模型,设计最优性能函数与基于状态反馈及模型信息的积分强化学习算法;
[0031]
首先忽略环境位置re的影响,针对一般的线性系统:
[0032][0033]
参考轨迹通过以下轨迹生成器产生:
[0034][0035]
其中f是常值矩阵,用于生成轨迹。
[0036]
取性能函数为:
[0037][0038]
其中q0≥0和r>0分别为相应的对称权重矩阵,γ为折扣因子,t表示当前时间。
[0039]
然后构造增广系统的状态为得到增广系统为:
[0040][0041]
从而性能函数可改写为:
[0042][0043]
其中i表示与c维数一致的三维矩阵。
[0044]
从而得到的基于状态反馈的值迭代积分强化学习算法为:
[0045]
a)初始化:给定任意初始控制策略u0;
[0046]
b)策略评估:对当前时刻i的控制策略ui,利用以下bellman方程求解i+1时刻的正定对称矩阵p
i+1
;
[0047][0048]
其中pi表示i时刻的正定对称矩阵,δt表示系统采样周期;
[0049]
c)策略改进:更新控制策略;
[0050][0051]
d)收敛条件:如果满足||p
i+1-pi||≤ε则停止迭代,否则设置i=i+1并转到策略评估步骤。
[0052]
(3)设计状态重构观测器,与积分强化学习算法结合,利用输入输出数据实现系统的无模型最优阻抗控制;
[0053]
增广系统的状态可以通过输入输出数据重构,表达式为:
[0054][0055]
其中为可观测的历史数据,由t-δt时刻到t-nδt时刻的输入数据集和输出数据集以及t-nδt时刻的期望轨迹r(t-nδt)组成,m为重构矩阵,表示为:
[0056][0057]
其中un、vn、φn均表示参数矩阵,表示φn的伪逆,
[0058][0059][0060]
将重构状态表达式代入基于状态反馈的值迭代积分强化学习算法,并定义为正定对称矩阵,其中p0、pu、py、pr均为矩阵中的元素,“*”表示与控制无关的矩阵元素。则可得到基于输入输出数据的无模型值迭代积分强化学习算法:
[0061]
a)初始化:任意初始控制策略根据i时刻的p
i*
给出;
[0062]
b)策略评估:对于当前的控制策略ui,利用接下来的bellman方程求解矩阵p
*
在i+1时刻的值
[0063][0064]
其中,p
i*
表示i时刻的矩阵p
*
;
[0065]
c)策略改进:更新控制策略;
[0066][0067]
其中分别为i+1时刻p0、pu、py、pr的值;
[0068]
d)收敛条件:如果满足则停止迭代,否则设置i=i+1并转到策略评估步骤。
[0069]
(4)根据简化前的数学模型,将提出的积分强化学习算法进行修正,将算法应用于空间机械臂智能柔顺操控;
[0070]
上一步中算法是针对系统π2和π3提出的,没有考虑目标位置的影响,为使算法在空间机械臂阻抗控制中的应用具有通用性,需要针对系统π1对算法进行改进。首先修正的状态重构表达式为:
[0071][0072]
其中为可观测的历史数据,相对于上一步中的增加了re,由于本发明研究的阻抗控制问题中,环境位置re和期望位置r均为常值,因此在实现过程中取任意时刻均可;m
′
为修正的重构矩阵,表示为:
[0073][0074]
其中vn、φn、的定义均与上一步相同。
[0075]
重新定义则修正后的控制策略为:
[0076]
[0077]
其中分别为i+1时刻p0、pu、py、p
r1
、p
r2
的值。本发明与现有技术相比的优点在于:本发明通过将状态重构算法与积分强化学习相结合提出一种基于输入输出数据的无模型值迭代积分强化学习算法,能够解决机械臂与未知环境接触过程的最优阻抗控制问题。本发明不依赖模型信息、能够充分利用输入输出的历史数据,克服了现有算法中状态重构精度低、依赖初始稳定控制策略等问题,可应用于空间机械臂智能柔顺控制。本发明在接触环境模型未知情况下,能够通过自主学习实现机械臂末端工具与非合作目标的安全柔顺接触。
附图说明
[0078]
图1为本发明的空间机械臂与未知环境接触过程的智能柔顺操控方法流程框图;
[0079]
图2为本发明的空间机械臂系统结构图;
[0080]
图3为本发明的空间机械臂末端与目标接触的环境模型;
[0081]
图4为本发明的空间机械臂末端抓捕目标产生的接触力仿真曲线;
[0082]
图5为本发明的空间机械臂末端位置的仿真曲线。
具体实施方式
[0083]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0084]
如图1所示,本发明具体实现步骤如下:
[0085]
第一步,针对图2所示的空间机械臂系统,根据凯恩方程与多体动力学理论,建立空间机械臂系统的通用动力学模型,并对环境接触模型进行数学表征:
[0086]
利用凯恩方程进行多体动力学建模的一般形式可以写为:
[0087][0088]
其中和分别表示系统第k阶广义主动力和广义惯性力,n是系统所有广义速率写成分量列阵形式,分量列阵的个数。
[0089]
选取空间机械臂系统的广义速率为:
[0090][0091]
其中,和分别表示基座的速度和角速度在基座本体坐标系中的分量,表示第i个机械臂关节的角速度。通过凯恩方程进行规范化推导,可以得到空间机械臂系统的动力学模型为:
[0092][0093]
其中为υ的导数,h为系统全局质量阵,f
non
为系统全局非线性项,fa表示广义主动力为:
[0094]
[0095]
其中f0是基座受到的推力在基座本体坐标系中的分量列阵,rb是f0作用点在基座本体坐标系中的矢径,t0是基座受到的力矩在基座本体坐标系中的分量列阵,ti是第i个电机转子的驱动力矩,0矩阵具有其对应的广义速率相容的维数;下标“i-1”和“2m-i”分别表示有i-1和2m-i个0矩阵,上标“t”表示矩阵的转置;对于任意三维列向量χ=[χ
1 χ
2 χ3]
t
,上标“~”的定义为其中标量χ1、χ2、χ3为向量χ中的元素。
[0096]
在实施过程中,采用空间六自由度机械臂系统作为空间机械臂系统进行仿真实验,系统参数如下所示:
[0097][0098]
其中,“#”处基体的长度实际上应该是臂杆1与基体的连接点在基体中的位置矢量,为[-10.88,-2.45,0.93]
t
m。
[0099]
对于目标位置固定的抓捕任务中,空间机械臂末端与环境的接触过程如图3所示,接触力fe的数学模型可表征为:
[0100][0101]
为说明算法有效性,假设y、z方向不存在接触力,仅研究x方向的柔顺控制问题。式中,环境模型的刚度系数取ge=100n/m,阻尼系数ce=10ns/m,质量系数me=1kg,xe表示目标位置在惯性系中的分量,x表示机械臂末端位置在惯性系中的分量,分别表示x的一阶导数和二阶导数。
[0102]
阻抗控制模型的表达式为:
[0103][0104]
式中,md、cd、gd分别表示阻抗模型的期望惯量、阻尼、刚度参数,xd表示机械臂末端的期望位置。末端接触力与平衡位置仅与gd相关,因此取md=1kg,cd=100ns/m,gd通过自主学习确定。
[0105]
将环境模型与阻抗模型相加,得到:
[0106][0107]
其中,f=gd(x-xd)为控制输入。
[0108]
取状态变量输入变量u=f,则可以得到阻抗控制模型的线性状态方程形式:
[0109][0110]
其中表示x的导数,re=xe表示环境位置输入,因此:
[0111]
c=[0 1]。
[0112]
第二步,忽略环境位置信息,将接触模型简化为一般的最优跟踪模型,设计最优性能函数与基于状态反馈及模型信息的积分强化学习算法:
[0113]
首先忽略环境位置re的影响,针对一般的线性系统:
[0114][0115]
参考轨迹通过以下轨迹生成器产生:
[0116][0117]
其中常值矩阵f=0,轨迹为常值r=xd。
[0118]
取性能函数为:
[0119][0120]
其中取权重矩阵q0=50000和r=0.001,折扣因子γ=500,t表示当前时间。
[0121]
然后构造增广系统的状态为得到增广系统为:
[0122][0123]
从而性能函数可改写为:
[0124][0125]
其中i表示与c维数一致的三维矩阵。
[0126]
从而得到的基于状态反馈的值迭代积分强化学习算法为:
[0127]
a)初始化:给定任意初始控制策略u0;
[0128]
b)策略评估:对当前时刻i的控制策略ui,利用以下bellman方程求解i+1时刻的正定对称矩阵p
i+1
;
[0129][0130]
其中pi表示i时刻的正定对称矩阵,δt表示系统采样周期;
[0131]
c)策略改进:更新控制策略:
[0132][0133]
d)收敛条件:如果满足||p
i+1-pi||≤ε则停止迭代,否则设置i=i+1并转到策略评估步骤。
[0134]
第三步,设计状态重构观测器,与积分强化学习算法结合,利用输入输出数据实现系统的无模型最优阻抗控制:
[0135]
增广系统的状态可以通过输入输出数据重构,表达式为:
[0136][0137]
其中为可观测的历史数据,由t-δt时刻到t-nδt时刻的输入数据集和输出数据集以及t-nδt时刻的期望轨迹r(t-nδt)组成,m为重构矩阵,表示为:
[0138][0139]
其中un、vn、φn均表示参数矩阵,表示φn的伪逆,
[0140][0141][0142]
将重构状态表达式代入基于状态反馈的值迭代积分强化学习算法,并定义为正定对称矩阵,其中p0、pu、py、pr均为矩阵中的元素,“*”表示与控制无关的矩阵元素。则可得到基于输入输出数据的无模型值迭代积分强化学习算法:
[0143]
a)初始化:任意初始控制策略根由初始时刻的p
0*
给出;
[0144]
b)策略评估:对于当前的控制策略ui,利用接下来的bellman方程求解矩阵p
*
在i+1时刻的值
[0145]
[0146]
其中,p
i*
表示i时刻的矩阵p
*
;
[0147]
c)策略改进:更新控制策略;
[0148][0149]
其中分别为i+1时刻p0、pu、py、pr的值;
[0150]
d)收敛条件:如果满足则停止迭代,否则设置i=i+1并转到策略评估步骤。
[0151]
第四步,根据简化前的数学模型,将第三步中提出的算法进行修正,将算法应用于空间机械臂智能柔顺操控:
[0152]
第三步中算法是针对系统π2和π3提出的,没有考虑目标位置的影响,为使算法在空间机械臂阻抗控制中的应用具有通用性,需要针对系统π1对算法进行改进。首先修正的状态重构表达式为:
[0153][0154]
其中为可观测的历史数据,相对于第三步中的增加了re,由于本发明研究的阻抗控制问题中,环境位置re和期望位置r均为常值,因此在实现过程中取任意时刻均可;m
′
为修正的重构矩阵,表示为:
[0155][0156]
其中vn、φn、的定义均与第三步定义相同。
[0157]
重新定义则修正后的控制策略为:
[0158][0159]
其中分别为i+1时刻p0、pu、py、p
r1
、p
r2
的值。
[0160]
仿真步长/采样周期设置为δt=2ms,用于恢复状态信息的采样数据点数量n=2,为了满足满秩条件,搜集数据用的初始控制策略需设置探索噪声,本发明取为其中randn表示-1~1之间的随机数,用于训练的环境末端位置为re=0.3m,机械臂末端期望位置为r=0.4m,末端初始位置为x0=0.31m。
[0161]
利用含噪声的控制策略,搜集控制数据与机械臂末端位置的测量数据,作为学习最优阻抗控制策略的数据集;然后利用第四步修正后的算法,通过记录的输入输出数据进行迭代得到最优策略对应的矩阵p
′
*
,其中基于状态反馈得到的最优策略对应的矩阵记为p,二者之间的转换关系为p
′
*
=m
′
t
pm
′
。
[0162]
矩阵p的理论值可利用线性二次型调节器设计,即lqr方法,得到:
[0163][0164]
利用基于输入输出数据的无模型强化学习算法得到最优阻抗控制策略对应的矩阵p为:
[0165][0166]
可以看出,所提出算法求解得到的矩阵p与理论值一致。因此,该算法不仅能够有效收敛到最优控制策略,且具有较高的收敛精度。值得指出,实际应用中求解得到的是矩阵p
′
*
,而p不可以直接求解,以上结果仅用于对算法精度进行说明。
[0167]
最后,将环境位置设置为7.7m,期望位置设置为8.1m,对以上学习得到的最优阻抗控制策略p
′
*
应用于空间机械臂柔顺控制仿真。本发明提出的基于输入输出数据的无模型积分强化学习算法简称为adp方法,将其仿真得到的环境接触力与末端位置运动曲线与lqr方法对比,如图4和图5所示。可以看出lqr方法与adp方法得到的环境接触力曲线与末端位置曲线基本重合;机械臂末端运动0.15s左右均达到环境位置,开始产生接触力,经过4s左右,末端位置与环境接触力达到最优的平衡状态,最优接触力分别为17.61n与17.22n,最优位置分别为7.8761m与7.8722m,最优接触力误差为2.21%,最优位置误差为0.05%。考虑到adp算法计算的阻抗控制策略是在无模型和状态信息不完全可测情况下得到的,误差范围合理,验证了本发明的合理性和有效性。
[0168]
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1