一种基于深度强化学习的机器人推拨装箱方法及系统
1.本发明涉及机器人装箱领域,尤其涉及一种基于深度强化学习的机器人推拨装箱方法及系统。
背景技术:
2.三维装箱问题是一个组合优化问题,广泛存在于物流、仓储、码垛等领域。通过优化装箱过程,可以提高空间利用率,减小运输成本,增加经济效益。
3.随着机器人技术的发展,机器人在仓储自动化领域得到广泛的应用,用机器人代替工人完成重复繁琐的工作,大大提高了生产效率。其中一个重要应用就是机器人的打包装箱。这项工作通常需要将一定数量的物体装进一个容积有限的箱子中,在这个过程中需要利用视觉技术获取物体信息,并用合适的算法规划物体位置,使用机器人完成装箱。机器人装箱不仅需要针对装箱问题本身进行优化,还要考虑机器人的操作问题。
4.现有对机器人装箱问题的研究大多针对放置物体位置的优化。对于三维装箱问题,通过传统的分析计算的方法可以在一些简单情况下得到精确解,如martello在《operations research》发表的论文《the three-dimensional bin packing problem》提出分支边界的方法,解决三维装箱问题。但三维装箱问题是一个np(non-deterministic polynomial)完全问题,在维数增加时不能保证在有限时间内得到精确解。因此更多的人采用启发式算法或者通过强化学习的方法寻找局部最优解,如wang在《ieee transactions on robotics》发表的论文《dense robotic packing of irregular and novel 3-d objects》提出高度图最小化算法,实现了对于不规则物体的三维装箱规划;hu在《acm transactions on graphics》发表的论文《tap-net:transport-and-pack using reinforcement learning》提出tap-net网络,通过强化学习方法解决物流运输过程中的打包问题。这些方法只考虑了机器人打包过程中的物体放置问题,但是机器人在操作过程中识别、抓取、放置存在误差,操作的不确定性会导致最终结果与规划产生误差,放置物体时可能会发生碰撞、倾覆等问题。
5.因此,本领域的技术人员致力于开发一种基于深度强化学习的机器人推拨装箱方法及系统。
技术实现要素:
6.有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是减小由于机器人操作不确定性对装箱结果的影响,提高空间利用率。
7.为实现上述目的,本发明提供了一种基于深度强化学习的机器人推拨装箱方法,其特征在于,所述方法包括以下步骤:
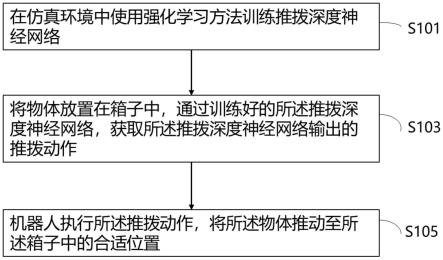
8.s101:在仿真环境中使用强化学习方法训练推拨深度神经网络;
9.s103:将物体放置在箱子中,通过训练好的所述推拨深度神经网络,获取所述推拨深度神经网络输出的推拨动作;
10.s105:机器人执行所述推拨动作,将所述物体推动至所述箱子中的合适位置。
11.进一步地,所述强化学习方法使用q-learning算法,将状态空间表示为所述箱子内所述物体的rgb图像和高度图像,动作空间参数化为所述物体的x、y坐标和推动方向。
12.进一步地,所述s101步骤包括如下步骤:
13.s1011:在所述仿真环境中采用dblf算法确定放置位置,将所述物体放置在所述放置位置上;
14.s1012:通过所述推拨深度神经网络选择推拨动作,使用机器人完成所述推拨动作,计算本次推拨的奖励值并训练所述推拨深度神经网络,所述奖励值采用如下奖励函数计算得到:
[0015][0016]
其中,r
t
表示t时刻奖励期望,γ表示折扣因子,γ=0.5,ra(s
t
,s
t+1
)表示状态从s
t
转移到s
t+1
的动作奖励;
[0017]
s1013:当所述推拨次数未超过预定次数时,继续执行所述s1012步骤;
[0018]
s1014:放入下一个所述物体,当放入所述物体的数量未超过预定数量时,执行步骤所述s1011-s1013步骤,否则,完成本轮所述推拨深度神经网络的训练。
[0019]
进一步地,所述s1012步骤还包括如下步骤:
[0020]
使用rgbd相机采集箱内所述物体的rgb图像和深度图像,并沿重力方向投影获得高度图;
[0021]
将所述rgb图像和所述深度图像输入所述推拨深度神经网络中提取特征,通过两层卷积神经网络和一层上采样得到与输入图像大小相同的输出,所述输出包括16张与输入图像大小相同的动作价值图;
[0022]
选择所述动作价值图中动作价值最大的像素所对应的所述推拨动作作为所述推拨深度神经网络的输出动作,机器人使用所述推拨动作完成箱子的推拨操作;
[0023]
使用dblf启发式算法计算所述物体的放置位置分数,并将执行动作前后的所述分数差作为奖励,使用所述奖励对所述推拨深度神经网络进行训练。
[0024]
进一步地,所述16张动作价值图代表与将重力方向垂直的表面平分为16个推动方向,每一个像素对应所述动作空间中的x、y坐标,z轴高度为根据所述深度图像计算的手爪与其他物体不发生碰撞时的最低高度,推动距离为预先设置的固定距离。
[0025]
进一步地,使用所述强化学习方法训练所述推拨深度神经网络时,对所述动作空间进行掩码操作,减少训练过程中的无效探索,所述掩码操作由掩码函数实现,所述掩码函数为m(s
t
,a),当动作a在状态s
t
下一定失败时m=0,否则m=1。
[0026]
进一步地,在所述s103步骤中,将所述物体放置到所述箱子中时,使用所述dblf启发式算法确定所述物体的所述放置位置。
[0027]
进一步地,在所述s105步骤中,获取所述推拨深度神经网络每次输出的所述动作价值,当所述动作价值小于预定阈值时,则判定已将所述物体推动到合适位置。
[0028]
另一方面,本发明还提供了一种基于深度强化学习的机器人推拨装箱系统,其特征在于,所述系统采用基于深度强化学习的机器人推拨装箱方法,完成对所述箱子内部所述物体的推拨操作。
[0029]
进一步地,所述系统包括六自由度机械臂,平行二指夹爪,手眼相机和容纳箱,所述手眼相机和所述平行二指夹爪安装在所述六自由度机械臂的末端,所述手眼相机和所述平行二指夹爪执行抓取和推拨操作,所述容纳箱的四个角均放置一个aruco码,所述手眼相机根据所述aruco码来识别所述容纳箱的位姿。
[0030]
在本发明的较佳实施方式中,相对于现有技术,本发明具有如下优点:
[0031]
(1)使用强化学习方法端到端学习推拨动作,避免传统分析方法需要物体模型和对摩擦力等参数需要强假设的问题。
[0032]
(2)通过推拨动作在放置物体后进行归集,将位置发生偏移的物体向角落压缩归集,减少了机器人操作不确定性对装箱结果的影响。
[0033]
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
[0034]
图1是本发明的一个较佳实施例的流程框图;
[0035]
图2是本发明的一个较佳实施例的训练推拨深度神经网络的流程示意图;
[0036]
图3是本发明的一个较佳实施例的深度强化学习网络结构示意图。
具体实施方式
[0037]
以下参考说明书附图介绍本发明的多个优选实施例,使其技术内容更加清楚和便于理解。本发明可以通过许多不同形式的实施例来得以体现,本发明的保护范围并非仅限于文中提到的实施例。
[0038]
在附图中,结构相同的部件以相同数字标号表示,各处结构或功能相似的组件以相似数字标号表示。附图所示的每一组件的尺寸和厚度是任意示出的,本发明并没有限定每个组件的尺寸和厚度。为了使图示更清晰,附图中有些地方适当夸大了部件的厚度。
[0039]
如图1-图2所示,本发明的一个较佳实施例的基于深度强化学习的机器人推拨装箱方法,包括如下步骤:
[0040]
s101:在仿真环境中使用强化学习方法训练推拨深度神经网络;
[0041]
s103:将物体放置在箱子中,通过训练好的推拨深度神经网络,获取推拨深度神经网络输出的推拨动作;
[0042]
s105:机器人执行推拨动作,将物体推动至箱子中的合适位置。
[0043]
本发明实施例使用深度强化学习方法,在离线环境下搭建推拨深度神经网络的训练模型,并通过离线训练,实现端到端学习推拨动作,完成箱子内部物体的装箱整理工作。这种通过深度学习方法,避免传统分析方法需要物体模型和对摩擦力等参数需要强假设的问题,减小由于机器人操作不确定性对装箱结果的影响,提高空间利用率。
[0044]
在离线训练本发明实施例的基于深度强化学习的机器人推拨装箱方法中所使用的推拨深度神经网络,采用如下训练步骤:
[0045]
s1011:在离线仿真环境中采用dblf算法确定放置位置,将物体放置在该放置位置上;
[0046]
s1012:通过推拨深度神经网络选择推拨动作,使用机器人完成该推拨动作,计算
本次推拨的奖励值并训练所述推拨深度神经网络,所述奖励值采用如下奖励函数计算得到:
[0047][0048]
其中,r
t
表示t时刻奖励期望,γ表示折扣因子,γ=0.5,ra(s
t
,s
t+1
)表示状态从s
t
转移到s
t+1
的动作奖励;
[0049]
具体的训练包括:
[0050]
使用rgbd相机采集箱内所述物体的rgb图像和深度图像,并沿重力方向投影获得高度图;
[0051]
将所述rgb图像和所述深度图像输入所述推拨深度神经网络中提取特征,通过两层卷积神经网络和一层上采样得到与输入图像大小相同的输出,所述输出包括n张与输入图像大小相同的动作价值图;
[0052]
选择所述动作价值图中动作价值最大的像素所对应的所述推拨动作作为所述推拨深度神经网络的输出动作,机器人使用所述推拨动作完成箱子的推拨操作;
[0053]
使用dblf启发式算法计算所述物体的放置位置分数,并将执行动作前后的所述分数差作为奖励,使用所述奖励对所述推拨深度神经网络进行训练。
[0054]
s1013:当所述推拨次数未超过预定次数时,继续执行所述s1012步骤;
[0055]
s1014:放入下一个所述物体,当放入所述物体的数量未超过预定数量时,执行步骤所述s1011-s1013步骤,否则,完成本轮所述推拨深度神经网络的训练。
[0056]
可以根据实际中箱子内物体推拨情况,可以对推拨深度神经网络的进行多轮次的训练,从而实现模型最优。
[0057]
本发明提供两种具体的优选实施例,实现基于深度强化学习的推拨装箱方法。
[0058]
实施例1
[0059]
本实施例提供了一种基于深度强化学习的机器人推拨装箱方法,如图1所示,具体包括以下步骤:
[0060]
1)在仿真环境中使用强化学习方法训练一个推拨深度神经网络。
[0061]
具体地,所述步骤1包含以下步骤,如图2所述。
[0062]
1.1)在仿真中随机生成放置位置,将物体放置在箱子中。
[0063]
具体地,使用coppliasim仿真软件,仿真中使用大小为为22cm
×
22cm
×
12cm的盒子作为箱子,使用ur-5机器人模型,机械臂末端连接一个3.2cm
×
2cm
×
20cm的长方体作为末端执行器,待装箱的物体为30个边长为5cm,颜色不同的正方块,箱子的位置固定不动。
[0064]
1.2)通过网络选择推拨动作,在仿真中使用机器人完成推拨动作,并计算奖励,训练网络。
[0065]
具体地,将本问题看做一个马尔科夫决策过程(s,a,p,r),其中:
[0066]
s为状态空间,a为动作空间,p为状态转移概率函数,r为奖励函数。在t时刻,机器人通过箱子上方的相机得到箱子内物体的状态s
t
,并根据策略π,选择执行动作a
t
,执行动作后状态s
t
根据状态转移概率函数变为s
t+1
,并获得奖励r。我们通过函数q估计每个状态下执行动作所获得的未来奖励。通过策略函数π选择q值最大的动作,策略π为:
[0067]
π(s
t
)=argmax
a∈a q(s
t
,a
t
)
[0068]
训练的目标是通过迭代最小化|q(s
t
,a
t
)-y
t
|获得使r最大的q函数。其中目标y
t
为:
[0069]yt
=ra(s
t
,s
t+1
)+γq(s
t+1
,π(s
t+1
))
[0070]
强化学习方法使用q-learning算法,将状态空间表示为箱子内物体的rgb图像和高度图像,动作空间参数化为x、y坐标和推动方向。
[0071]
rgb图像和高度图像由箱子上rgbd相机采集图像信息并在重力方向上投影得到。参数化动作空间通过与输入图像大小相同的图像表示,每个像素点包含16个数据,代表16个均分的推动方向,推动距离设置为5cm。
[0072]
将rgb图像和深度图像输入到预训练densenet网络中提取特征,并通过两层卷积神经网络和一层上采样得到与输入图像大小相同的输出,该网络结构如图3所示。
[0073]
使用dblf启发式算法计算物体放置位置分数,并将执行动作前后的分数差作为奖励,通过箱子内物体位置是否发生变化判断推拨动作是否产生效果,如果没有则将奖励置零并切断未来奖励。位置分数为:
[0074]
score=z+c(x+y)
[0075]
其中,x、y、z表示物体坐标,c为常量,这里取0.1。
[0076]
奖励函数为:
[0077][0078]
其中,r
t
表示t时刻奖励期望,γ表示折扣因子,γ=0.5,ra(s
t
,s
t+1
)表示状态从s
t
转移到s
t+1
的动作奖励;
[0079]
ra(s
t
,s
t+1
)=-δscore
[0080]
选择推拨动作时会对网络输出进行掩码操作,只从可能有效的推拨动作中选择。
[0081]
进一步的,定义一个掩码函数m(s
t
,a),当动作a在状态s
t
下一定失败时,m=0,否则m=1。网络预测的动作空间变为:
[0082]mt
(a)={a∈a|m(s
t
,a)=1}
[0083]
因此选择执行动作时只在可能成功的范围内选择,为了在训练过程中有效利用动作空间的遮蔽,目标函数变为:
[0084][0085]
1.3)当推拨次数超过一定值时,放入下一个物体,这里设置为每放入一个方块推动20次,然后放入下一个方块,继续步骤1.2)。
[0086]
1.4)当放入的物体超过一定数量时,清空所有物体,这里设置为30块方块,可以整齐地铺满两层,之后重新开始执行步骤1.1)-1.3)。
[0087]
2)装箱时将物体放置在箱子中,通过网络选择推拨动作,对物体进行归集。
[0088]
具体地,放置物体时采用dblf算法确定放置位置,所述算法与步骤1)中训练网络时所用dblf算法相同。
[0089]
由于机器人操作不确定性,放置物体时会偏离规划位置,通过步骤1)训练好的网
络选择推拨动作,将物体向角落归集,减小操作不确定性对装箱结果的影响。
[0090]
3)使用机器人通过多次推动将物体推动至合适位置,然后放置下一个物体,最终完成装箱过程。
[0091]
具体地,当使用和仿真中相同的方块装箱时,使用步骤1)训练好的网络输出的动作价值,判断是否已将物体推动至合适位置。本实例中,当网络输出动作价值小于预定阈值1.3时,则认为已经将箱子内物体归集完成,装入下一个方块继续执行步骤2)。
[0092]
当使用其他物体装箱时,每次放入物体后固定推动4次,之后装入下一个物体继续执行步骤2)。
[0093]
实施例2
[0094]
本实施例提供了一种基于深度强化学习的机器人推拨装箱系统,具体包括六自由度机械臂,平行二指夹爪,手眼相机,容纳箱。其中,机械臂选用jakazu7六自由度机械臂,平行二指夹爪选用robotiq 2f-140二指机械夹爪,手眼相机选用realsense sr305。手眼相机和平行二指夹爪安装在机械臂末端,用于执行抓取和推拨操作。相机与机械臂末端相对位姿保持不变,并对相机坐标系和机械臂末端坐标系进行了标定,容纳箱为长方形,内侧尺寸为27cm
×
17cm
×
6cm。在容纳箱上四个角贴上4个aruco码,用于手眼相机识别箱子位姿。aruco码类似于二维码,它是一个由黑色边框组成的二进制矩阵,它是一种合成标记,用于在图像或视频中物体定位。
[0095]
在执行装箱任务时,在每次放置物体和推拨物体时,机械臂移动到固定位置,通过手眼相机识别箱子位姿,之后移动到箱子正上方一定距离,通过相机获得箱内物体的rgb图像和深度图像,用于判断放置位置和规划推拨动作。
[0096]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1