一种密集场景下机械臂抓取目标物体的方法
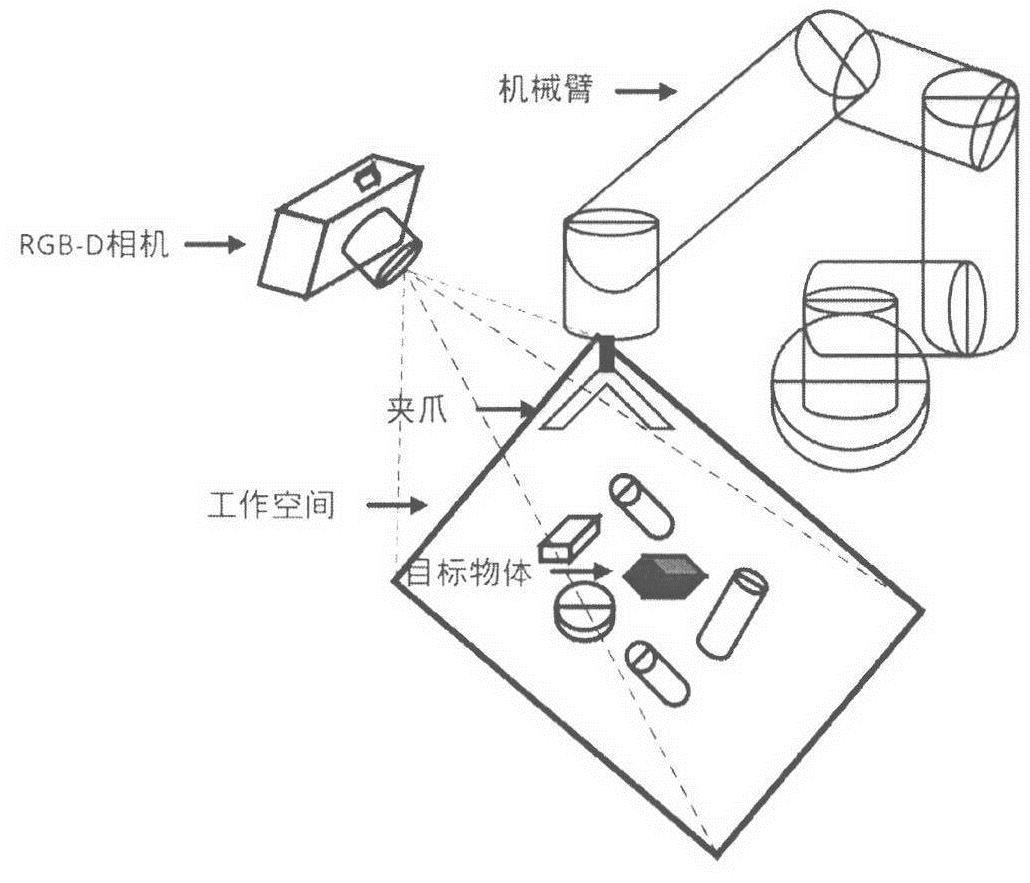
本发明涉及机器人技术应用,具体为一种密集场景下机械臂抓取目标物体的方法。
背景技术:
1、随着人工智能的工业化,机械臂所处的角色愈发重要,它是完成复杂任务的基本组成部分。透其本质,机械臂提供了核心功能“抓取”。传统的示教方法简单易于操作,但机械臂受限作用于高度重复的环境下,不具备自适应抓取能力。利用深度学习目标检测的方法检测出目标物体在二维空间的位置,再采用基于对应点的方法、基于模板的方法、基于投票的方法预测目标物体实际三维空间位姿,进而机械臂抓取任意位置的物体,但这些方法需要事先知道对象模型,只能在结构化简单环境下进行物体抓取。深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,生成适合目标物体抓取任务的决策网络,直接根据输入的图像计算得到逼近最优决策的动作,在一定程度上提高了不同场景下物体的抓取成功率。但是在物体密集堆叠的环境下,目标物体易被其他物体遮挡,机械臂仍然无法找到合适的抓取位姿从而导致最终抓取失败。基于深度强化学习的推动抓取系统通过“推动”动作将密集场景下的物体分离,再实施“抓取”已分离的物体,通过推动和抓取之间的协同效应解决密集场景下物体抓取问题。但是这类方法逐一抓取密集场景下的任意物体,而不是指定的目标物体,并且奖励函数未能有效评估推动和抓取动作的有效性,导致有时“推动”动作和“抓取”动作不是非常合理。
2、因此,如何设计合理的推动和抓取协同策略网络,使得机械臂在密集场景下成功抓取到指定的目标物体是一个值得思考的问题。
技术实现思路
1、本发明提出了一种密集场景下机械臂抓取目标物体的方法,基于深度强化学习构建了针对目标物体的推动与抓取协同策略网络,设计了目标物体的推动动作和抓取动作奖励函数,判断推动动作是否有效地将目标物体与其他物体分开,抓取动作是否地成功地抓取目标物体,基于q学习算法不断在工作环境中尝试动作获取奖励值来训练推动与抓取协同策略网络。本方法合理评估了推动和抓取动作的有效性,通过“推动”与“抓取”动作协同合作完成密集场景下完成目标物体的精准抓取。
2、本发明提出了一种密集场景下机械臂抓取目标物体的方法,包含以下主要步骤:
3、步骤s1:在v-rep仿真环境中搭建用于机械臂工作的物体密集复杂环境;
4、步骤s2:在仿真环境中构建端到端基于深度强化学习的推动与抓取协同策略网络,采用编码器-解码器结构;
5、步骤s3:在步骤s1搭建的仿真环境中基于q学习算法不断在工作环境中尝试动作获取奖励值来训练推动与抓取协同策略网络,若目标物体被严重遮挡,则屏蔽抓取网络仅仅训练推动网络若目标物体未被严重遮挡,则并行训练推动与抓取协同策略网络;
6、步骤s4:搭建真实的密集堆叠复杂场景,将仿真端训练好的推动与抓取协同网络移植到实物平台,机械臂在真实环境下进行动作决策抓取目标物体。
7、2.可选地,步骤s2所述的编码器-解码器结构,具体包括如下步骤:
8、步骤s2-1:采用密集卷积神经网络densenet121构建编码器,提取用于计算机械臂动作的潜在特征图;
9、步骤s2-2:采用两个并行的全卷积神经网络构建解码器,分别为推动网络和抓取网络
10、3.可选地,步骤s3所述的训练推动与抓取协同策略网络,具体包括如下步骤:
11、步骤s3-1:利用深度相机采集工作空间内的rgb图像ic和深度图像id,在rgb图像中id中将待抓取的目标分割出来,形成目标物体掩码图像im,将三种图像信息进行处理,融合生成特征图hcdm;
12、步骤s3-2:将上述步骤s3-1生成特征图hcdm,通过顺时针依次旋转获得n幅旋转的特征图,并依次输送至上述步骤s2-1构建的编码器提取t时刻n幅潜在特征图
13、步骤s3-3:若目标物体被严重遮挡,则屏蔽抓取网络仅仅训练推动网络将步骤s3-2提取的n幅潜在特征图依次输入至推动网络输出推动网络q值矩阵,选择最大q值对应的动作为最优决策动作at;若目标物体未被严重遮挡,则并行训练推动与抓取协同策略网络,将步骤s3-2提取的n幅潜在特征图依次输入至推动网络和抓取网络输出推动网络q值矩阵和抓取网络的q值矩阵,选择最大q值对应的动作为最优决策动作at;
14、步骤s3-4:机械臂执行最优动作at,工作场景发生变化,重新执行步骤s3-1和s3-2获取t+1时刻的n幅潜在特征图
15、步骤s3-5:根据动作之后的状态st+1,利用分段奖励函数rt计算机械臂做出动作at后的奖励值,评估动作at对促使完成最终任务的肯定或否定;
16、步骤s3-6:存储交互数据四元组(st,at,st+1,rt)至经验池;
17、步骤s3-7:根据步骤s3-5计算得到的奖励值,计算目标函数其中γ∈[0,1]为折扣因子;
18、步骤s3-8:以最小化huber损失函数进行网络训练:
19、
20、式中,为t时刻网络输出的预估值,为根据t+1时刻的q值回溯t时刻的真实值,两者之差作损失函数;
21、步骤s3-9:将huber损失函数迭代更新推动和抓取协同策略网络直至成功率曲线达到平稳振荡状态时终止训练,保存最新的推动和抓取协同策略网络参数。
22、4.可选地,步骤s3-1所述的生成特征图hcdm,具体包括如下步骤:
23、步骤s3-1-1:通过在机械臂外部安置固定点位的摄像头捕获预定义的工作空间,获取该空间内的rgb彩色图像ic和depth深度图像id;
24、步骤s3-1-2:运用预先训练好的分割网络posecnn在rgb彩色图像ic中将待抓取的目标分割出来,将目标物体像素置1,其余像素全部置0,生成目标物体的二值化掩码图像im;
25、步骤s3-1-3:根据步骤s3-1-2中生成目标物体的二值化掩码图像im判断目标物体的遮挡状态,统计目标物体区域内像素个数,若低于阈值c,表示目标物体当前被严重遮挡;相反,目标物体未被遮挡;
26、步骤s3-1-4:已知相机外部参数的条件下,将rgb彩色图像ic、depth深度图像id和掩码图像im在重力方向上正交投影转换为自上而下视角的彩色高度图hc、深度高度图hd和目标物体掩码高度图hm;
27、步骤s3-1-5:将彩色高度图hc、深度高度图hd和目标物体掩码高度图hm高度图分别进行卷积操作提取出同分辨率的特征图,按通道层从上至下拼接成特征图hcdm。
28、5.可选地,步骤s3-3所述的选择最优决策动作at,具体包括如下步骤:
29、步骤s3-3-1:将步骤s3-2提取的n幅潜在特征图依次输入至推动网络计算出t时刻n个“推动”动作的q值矩阵t时刻第i个潜在特征图像素坐标(x,y)处作用“推动”动作的q值为若目标物体未被严重遮挡,同时也将n幅潜在特征图依次输入至推动网络计算出n个“抓取”动作的q值矩阵第i个潜在特征图潜在特征图像素坐标(x,y)处作用“抓取”动作的价值为
30、步骤s3-3-2:若目标物体被严重遮挡,集合步骤s3-3-1中t时刻下所有旋转角度下的“推动”q值矩阵找出t时刻最大q值i=1,2...n;若目标物体未被严重遮挡,集合步骤s3-3-1中t时刻下所有旋转角度下的“推动”和“抓取”动作q值矩阵找出t时刻最大q值其中,
31、步骤s3-3-3:以最大q值qmax所对应的动作为t时刻机械臂的最优动作at,a=<m,d,θ>,其中m表示机械臂的动作类型,m∈{p,g},p表示“推动”动作,g表示“抓取”动作,d=(x,y,z)表示机械臂动作点的三维坐标,θ表示机械臂末端绕z轴旋转的角度;若等于则机械臂执行“推动”动作,动作点的三维坐标d为(x*,y*,z*),z*为像素(x*,y*)处的深度值,机械臂末端绕z轴旋转角度θ为反之,若等于则机械臂执行“抓取”动作;动作点的三维坐标d为(x*,y*,z*),z*为像素(x*,y*)处的深度值,机械臂末端绕z轴旋转角度θ为
32、6.可选地,步骤s3-5所述的分段奖励函数rt计算奖励值,具体包括如下步骤:
33、步骤s3-5-1:运用插值法使目标物体掩码图像im放大至原来的一倍im′,图像矩寻找im与im′目标物体区域像素的质心坐标,将im′目标物体区域像素映射至im目标物体区域内,保证两者质心坐标重合,生成目标奖励区域rarea;
34、步骤s3-5-2:计算rarea内非目标物体的面积占比rno_object为目标奖励区域rarea内不存在物体的区域面积大小,rtarget_area为目标奖励区域rarea内目标物体的区域面积大小;
35、步骤s3-5-3:预设奖励,当最大q值对应的动作为“推动”,且动作点的二维坐标位于目标奖励区域rarea内,若推动之后非目标物体的面积占比poccupy小于推动之前,意味着t时刻下“推动”动作有效地将目标物体与其他物体分开,赋予奖励值rt=0.5;反之,若推动之后非目标物体的面积占比poccupy大于推动之前,意味着t时刻下“推动”动作未能有效地将目标物体与其他物体分开,赋予奖励值rt=0.25;
36、步骤s3-5-4:同样,当最大q值对应的动作为“抓取”,且动作点的二维坐标位于目标奖励区域rarea内,若机械臂成功抓取目标物体,赋予奖励值rt=1,反之,机械臂未成功抓取目标物体,赋予奖励值rt=0.5;
37、步骤s3-5-5:其他情况视为推动失败和抓取失败,设置奖励值为0。
38、7.可选地,步骤s4所述的密集堆叠复杂场景,具体包括如下步骤:
39、步骤s4-1:利用标定板和深度相机做手眼标定工作,获取相机的内外参数,得到二维像素坐标(x,y)对应三维空间坐标(x,y,z)之间的变换矩阵m;
40、步骤s4-2:通过训练好的推动与抓取协同策略网络输出最大q值的二维像素坐标(x*,y*),结合变换矩阵m得到最优动作at,即机械臂的动作类型、动作点在实际空间中的三维坐标(x*,y*,z*),以及机械臂末端绕z轴旋转角度θ;
41、步骤s4-3:控制机械臂末端执行器旋转至最大q值所在特征图的角度θ,运用机械臂内部ik解算器解算出运动至三维坐标(x*,y*,z*)各自由度所需转动大小,驱动机械臂各关节轨迹运动执行最优动作at;
42、步骤s4-4:多次重复上述步骤s4-1到s4-3,实现在密集场景下抓取目标物体。
- 还没有人留言评论。精彩留言会获得点赞!