一种考虑位姿测量误差的非合作目标智能柔顺捕获控制方法
本发明属于空间机器人智能控制领域,具体涉及一种考虑位姿测量误差的非合作目标智能柔顺捕获控制方法。
背景技术:
1、随着空间技术的蓬勃发展,人类对太空的探索和开发、利用需求快速增长,失效卫星、空间碎片数量急剧增长,使得空间环境日益恶化。这些在轨目标通常具有结构特征、运动信息未知等典型非合作特征,严重威胁空间站、通信、导航卫星等一些基础性空间项目的安全,如何利用空间机器人捕获这些目标,为在轨航天器提供安全可靠的运行环境,是近年来被重点关注的方向。
2、为成功捕获非合作目标,通常需要借助视觉测量技术获取目标运动信息。但是,受限于恶劣太空环境、测量距离以及传感器性能,测量精度将不可避免地下降,应用于空间抓捕任务时可能产生超出航天器承受能力的接触力/力矩,给航天器系统带来了极大的风险和不确定性。如何使机器人与目标柔顺交互完成捕获任务,是一项亟待解决且非常具有挑战性的工作。
3、阻抗控制算法是处理接触控制问题的一种有效手段,能够处理非合作目标柔顺捕获任务。传统阻抗控制方法严重依赖手动调参,无法处理未知接触环境及变化的操作任务,因此需要发展如自适应变阻抗控制(p.xia,j.luo,and m.wang,“adaptive compliantcontroller for space robot stabilization in post-capture phase,”proceedingsof the institution of mechanical engineers,part g:journal of aerospaceengineering,vol.235,no 8,pp 937-948,2021)及环境参数在线估计(y.lin,z.chen,andb.yao,“unified motion/force/impedance control for manipulators in unknowncontact environments based on robust model-reaching approach,”in ieee/asmetransactions on mechatronics,vol.26,no.4,pp.1905-1913,2021)等技术。近年来,强化学习算法在阻抗控制领域得到广泛应用(cn112894809a),相对于自适应控制及环境参数估计等技术,该算法不仅能够利用经验数据自主学习阻抗参数,而且能够通过定义交互性能函数实现接触力和跟踪精度间的最优权衡。现有基于强化学习的阻抗控制方法大多需要将接触模型离散化,如文献(x.liu,s.s.ge,f.zhao,and x.mei,“optimized interactioncontrol for robot manipulator interacting with flexible environment,”ieee/asme transactions on mechatronics,vol.26,no.6,pp.2888-2898,2021);为避免离散化步骤,使设计的算法更接近于实际接触过程,文献(h.wu,q.hu,y.shi,j.zheng,k.sun,andj.wang,“space manipulator optimal impedance control using integralreinforcement learning,”aerospace science and technology,139,108388,2023)研究了基于连续接触模型的强化学习方法,但该算法主要应用于合作目标的操作任务,且目标位姿被假设为常值,无法直接用于非合作目标捕获任务。在此基础上,同时考虑非合作目标运动特性以及位姿测量误差等实际问题,如何发展强化学习技术是一项有待解决且极具挑战的难题。为此,本发明设计了一种基于位姿测量误差的强化学习最优阻抗控制方法,能够适应未知接触环境以及变化的接触任务,为空间机器人捕获非合作目标任务提供了理论和技术支撑。
技术实现思路
1、针对空间机器人捕获非合作目标的在轨操作任务,考虑非合作目标运动、位姿测量不精确、接触模型连续且未知等问题,本发明提供一种考虑位姿测量误差的非合作目标智能柔顺捕获控制方法。该方法由阻抗控制及强化学习技术发而来,能够利用有限测量数据在线学习最优阻抗参数,不依赖任何环境模型的先验知识,并根据测量误差产生的扰动项实现柔顺接触效果,能够处理目标运动、位姿测量不精确、接触模型连续且未知、机器人与运动目标的最优交互等问题,可用于非合作目标的智能柔顺捕获控制。
2、为达到上述目的,本发明采用的技术方案为:
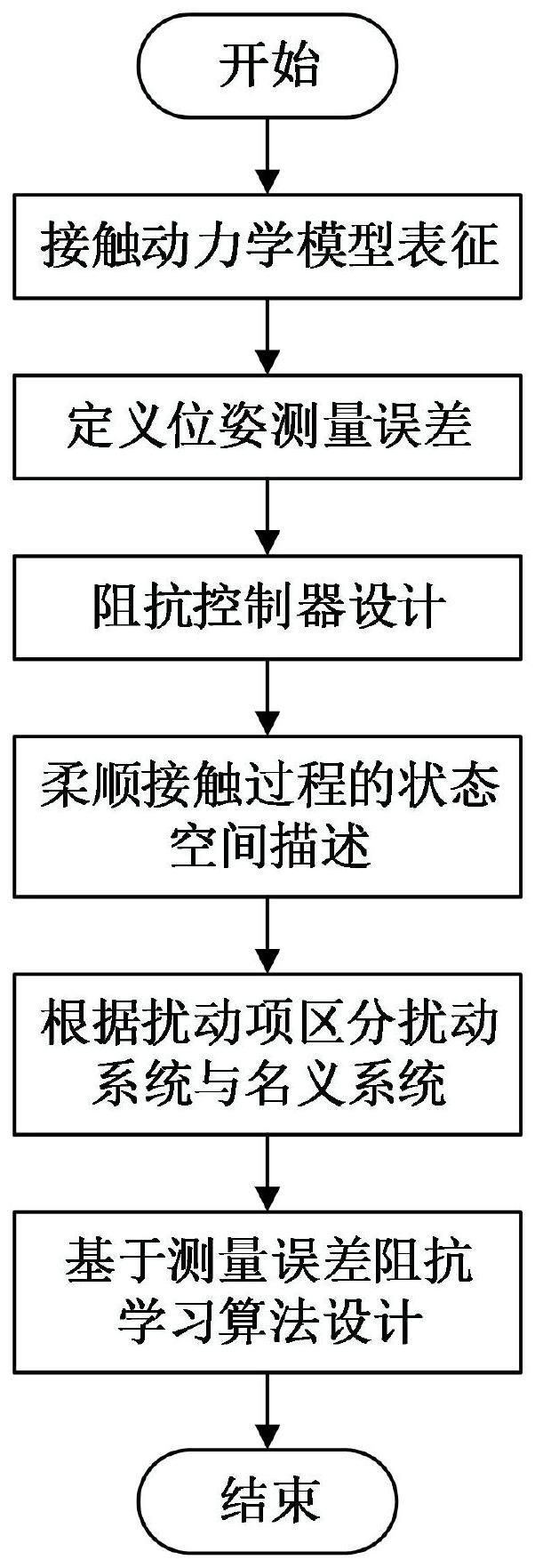
3、一种考虑位姿测量误差的非合作目标智能柔顺捕获控制方法,针对非合作目标运动、位姿测量不精确、接触模型连续且未知的最优阻抗控制问题,首先,采用线性模型近似未知接触环境,设计基于位姿测量值的阻抗控制器;接下来,考虑位姿测量误差,构造空间机器人与目标接触过程的状态空间表达式,根据误差是否存在将系统分为名义和扰动两类系统;最后,针对名义系统提出一种积分强化学习方法在线更新阻抗控制参数,然后应用于扰动系统利用测量误差达成柔顺接触效果;具体实施步骤如下:
4、(1)采用线性模型近似未知接触环境,设计基于位姿测量值的阻抗控制器;
5、空间机器人末端与非合作目标接触过程产生的接触力可以表示为:
6、
7、其中,de表示环境阻尼系数矩阵,ge表示环境刚度系数矩阵,x和分别表示空间机器人末端工具的位姿和速度向量,xe和分别表示非合作目标的实际位姿和实际速度向量,fe表示接触过程产生的作用力;
8、由于非合作目标的实际位姿难以精确获取,通常采用视觉测量方法粗略得到,定义位姿测量误差为:
9、
10、其中,表示非合作目标实际测量位姿,δxe表示位姿测量误差。假设δxe<0表示空间机器人未与目标发生接触,则此时无法判断捕获任务是否成功;因此为保证捕获任务成功,需要令δxe≥0,使空间机器人能够与目标发生接触;
11、根据测量的位姿,阻抗控制器的表达式可被选择为:
12、
13、其中,md表示期望的质量系数矩阵,dd、gd分别表示期望的阻尼系数和刚度系数矩阵,有待进一步设计;为x对时间的二阶导数;
14、(2)基于位姿测量误差构造空间机器人与目标接触过程的状态空间表达式,根据误差是否存在将系统分为名义和扰动两类系统;
15、令e=x-xe表示空间机器人末端位姿与非合作目标实际位姿的误差,表示空间机器人末端位姿与非合作目标测量位姿的误差,则位姿测量误差可进一步表示为:
16、δxe=e′-e
17、根据接触力和阻抗控制器的表达式,空间机器人末端与非合作目标的柔顺接触动力学可表示误差的形式为:
18、
19、其中,为选择的状态向量,为ξ的一阶时间导数,为e′的一阶时间导数;系统矩阵a和输入矩阵b可表示为:
20、
21、其中,0和i表示适当维数的零矩阵和单位矩阵;注意到矩阵a中含有环境参数de和ge,因此是完全未知的;而矩阵b中的md是给定的期望参数,因此是已知的;d为测量误差产生的扰动项,表达式为:
22、
23、u表示控制输入向量,其表达式为:
24、
25、其中,k=[dd gd]表示需要进一步设计的控制增益;
26、系统π1含有扰动项d,称为扰动系统;当扰动项d不存在时,则产生如下的名义系统π2:
27、
28、其中,参数ξ、a、b、u的定义与系统π1相同;
29、(3)针对名义系统提出一种积分强化学习方法在线更新阻抗控制参数,然后应用于扰动系统利用测量误差达成柔顺接触效果;
30、选择如下值函数v描述空间机器人末端与非合作目标的动态交互性能:
31、
32、其中,q和r表示对称的权重系数矩阵,γ为折扣因子,t表示当前时间,τ表示积分变量,p表示待求解的核矩阵;
33、针对模型参数a完全未知的名义系统π2,为学习最优阻抗控制参数,所设计的在线策略迭代积分强化学习方法如下:
34、a)初始化:给定一个初始稳定的控制策略u0;
35、b)策略评估:将当前时刻的控制策略ui用于扰动系统,记录历史输入输出数据;令δt表示采样周期,则通过如下bellman方程可在线求解第i×δt时刻的核矩阵pi:
36、
37、其中,ξ(t)、ξ(t+δt)分别表示t、t+δt时刻的状态向量;如果条件||pi-pi-1||≤κ成立,则完成学习,否则转到步骤c);其中κ为设定的常数,用于判断矩阵pi是否收敛到给定的阈值内,符号||·||表示矩阵范数;
38、c)策略提升:更新下一时刻的控制策略:
39、ui+1=-r-1btpiξ
40、转到步骤b)。
41、本发明与现有技术相比的优点在于:本发明考虑了非合作运动目标位姿测量误差的影响,针对动态柔顺交互过程提供了基于测量误差的状态空间模型;借助强化学习、阻抗控制技术及扰动控制理论,设计了一种在线策略迭代积分强化学习方法用于实时更新最优阻抗参数。本发明涉及的控制方法均针对连续接触模型设计,无需任何接触模型的先验信息,克服了传统方法未考虑目标运动及位姿测量误差的局限性,可用于实际场景下非合作目标的柔顺捕获控制。
- 还没有人留言评论。精彩留言会获得点赞!