一种融合文本指令和运动信息的机器人运动技能学习方法
本发明涉及机器人运动规划领域,具体来说,涉及一种融合文本指令和运动信息的机器人运动技能学习方法。
背景技术:
1、随着现代科技的不断发展,机器人已经在多个领域中发挥着重要的作用,传统的机器人已经不能满足人们的生活需求,机器人运动规划和人机交互相结合成为目前机器人运动规划的研究热点。
2、在人类环境中,为了替代人类完成复杂的任务,机器人被期望根据语言指令完成对应的任务,然而,由于在不同任务之间目标形状的不同,操作时间不同,任务复杂度不同,因此,很难通过学习一种技能兼顾不同的任务需求,并且根据现有学习到的技能很难拓展到未学习的任务中去,导致泛化性能较差。
3、目前的输入格式有两种:文本数据和视觉数据。文本数据是每个任务对应的文本信息,可以是一组,也可以是多组信息。视觉数据是根据多组相机拍摄的rgbd数据格式信息和掩码数据信息。人们对于研究文本信息和视觉信息融合,使得机器人可以更好的理解人类的语言,根据语言指令完成相应的任务仍是一项重要的挑战。
4、针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现思路
1、针对相关技术中的问题,本发明提出一种融合文本指令和运动信息的机器人运动技能学习方法,以克服现有相关技术所存在的上述技术问题。
2、为此,本发明采用的具体技术方案如下:
3、一种融合文本指令和运动信息的机器人运动技能学习方法,该方法包括以下步骤:
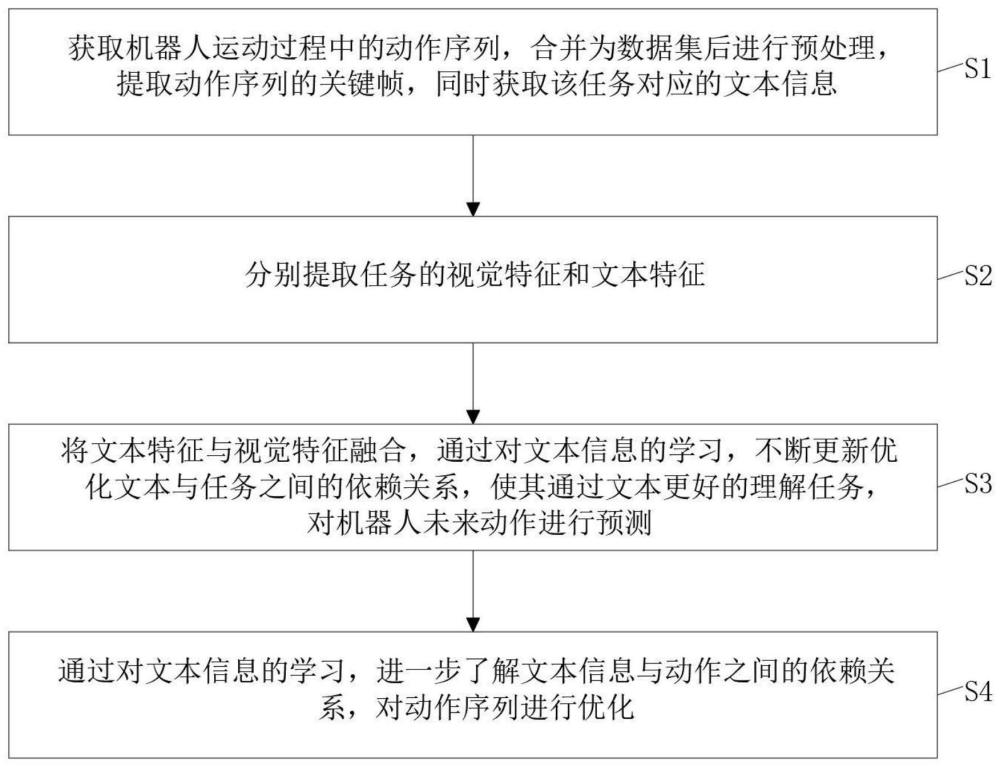
4、s1、获取机器人运动过程中的动作序列,合并为数据集后进行预处理,提取动作序列的关键帧,同时获取该任务对应的文本信息;
5、s2、分别提取任务的视觉特征和文本特征;
6、s3、将文本特征与视觉特征融合,通过对文本信息的学习,不断更新优化文本与任务之间的依赖关系,使其通过文本更好的理解任务,对机器人未来动作进行预测;
7、s4、通过对文本信息的学习,进一步了解文本信息与动作之间的依赖关系,对动作序列进行优化。
8、进一步的,获取机器人运动过程中的动作序列,合并为数据集后进行预处理,提取动作序列的关键帧,同时获取该任务对应的文本信息包括以下步骤:
9、s11、通过示教学习的方式,操控机器人完成设定任务,获取连续运动状态下的视觉信息与动作信息,并将视觉信息和动作信息合并为该任务的数据集;
10、s12、对机器人操作过程中的连续动作序列进行采样,提取视觉信息数据集中的关键帧,包括起始帧、末端夹持器速度趋于静止的中间帧以及末端夹持器状态发生改变的中间帧。其目的是将任务序列长度限制在10个宏步长以内;
11、s13、获取该任务对应的文本信息集合,其目的在于对不同文本进行学习,保证机器人在接收到不同文本信息后均能执行该任务;
12、进一步的,分别提取任务的视觉特征和文本特征包括以下步骤:
13、s21、首先分别采用全局特征编码器和局部特征编码器对视觉信息进行编码,其次构建视觉信息融合编码器,实现多尺度特征信息融合。
14、s22、基于clip预训练模型中文本编码器,提取文本信息的文本特征。
15、进一步的,首先分别采用全局特征编码器和局部特征编码器对视觉信息进行编码,其次构建视觉信息融合编码器,实现多尺度特征信息融合包括以下步骤:
16、s211、将视觉信息中由全视角组成的整体环境作为多视角图像信息,将视觉信息中由单一视角组成的局部环境作为局部图像信息;
17、s212、构建全局特征模块,利用投影与坐标转换的方式提取多视角图像信息中的全局特征信息;
18、s213、构建局部特征模块,利用特征映射的方式提取局部图像信息中的局部特征信息;
19、s214、通过全局特征模块与局部特征模块组成视觉信息融合编码器,再结合全局特征信息与局部特征信息,利用全局信息与局部信息多尺度融合的方式实现视觉信息的编码。
20、进一步的,构建全局特征模块,利用投影与坐标转换的方式提取多视角图像信息中的全局特征信息包括以下步骤:
21、s2121、利用卷积神经网络主干从多视角图像信息中提取多尺度特征;
22、s2122、初始化鸟瞰视图特征,该特征被均匀划分为网格,每个鸟瞰视图网格对应三维坐标pi=(xi,yi,z)和查询向量qi,z表示所有查询向量共享的鸟瞰视图平面的预定义高度;
23、s2123、利用几何先验知识引导注意力模型专注于鸟瞰视图中存在区别的区域,使用相机参数,将每个鸟瞰视图网格的三维坐标投影至一组浮点二维坐标,再将该二维坐标四舍五入为鸟瞰视图全局特征坐标;
24、s2124、在先验的鸟瞰视图全局特征坐标周围展开kh×kw核区域,kh与kw分别表示可变的高和长的参数,若核区域超过多视角图像信息的图像边界,则超出部分设置为零,再使用注意力模型将每个鸟瞰视图的查询嵌入与对应的多视角图像信息特征展开核特征进行交互,生成鸟瞰视图表示;
25、s2125、为了增强相偏差的鲁棒性,将相机偏差分解为平移偏差与旋转偏差,并将随机噪声添加至所有x、y、z维度与所有相机;
26、其中,平移偏差的表达式为:
27、
28、旋转偏差的表达式为:
29、rdevi=rθx·rθy·rθz;
30、式中,tdevi表示平移偏差;rdevi表示旋转偏差;δx、δy及δz分别表示x轴、y轴及z轴对应的平移噪声;rθx、rθy及rθz分别表示x轴、y轴及z轴的旋转偏差矩阵。
31、进一步的,构建局部特征模块,利用特征映射的方式提取局部图像信息中的局部特征信息包括以下步骤:
32、s2131、分别获取第t时刻时每个相机拍摄得到的局部图像信息对应的rgb图像数据、点云数据和焦点坐标数据;
33、s2132、将通道维度上的rgb图像数据、焦点坐标数据及鸟瞰视图全局特征坐标进行连接,再经过全卷积网络编码器处理得到特征映射;
34、s2133、将特征映射与通道维度中的点云数据进行连接,用于指示特征图中每个补丁的空间位置,同时对点云数据进行应用均值池化,实现点云数据与特征映射的大小匹配,最终进行特征映射编码的计算,特征映射编码的表达式为:
35、
36、式中,ftk表示特征映射编码;表示rgb图像特征;表示焦点坐标图特征;表示鸟瞰视图全局特征坐标;ptk表示表示点云数据;
37、s2134、将属于特征映射编码中的补丁作为单独的视觉标记,再利用相机id特征编码的嵌入、步长id特征编码的嵌入以及补丁位置的嵌入来表示视觉标记的视觉特征,视觉特征的运算表达式为:
38、
39、式中,表示视觉标记的视觉特征;wf表示卷积神经网络可学习的矩阵;表示特征映射编码中的补丁;表示相机id特征编码;表示步长id特征编码;表示补丁位置;表示视觉标记;
40、s2135、记录每个相机在不同步长时的视觉标记,并将所有相机的编码令牌连接为一个整体的视觉标记集合。
41、进一步的,基于clip预训练模型构建文本信息编码器,提取文本信息的文本特征,并对文本信息中的句子指令进行标记与编码包括以下步骤:
42、s221、基于clip预训练模型中的语言编码器构建文本信息编码器,并利用clip预训练模型的线性层获取文本信息中每个单词标记的单词嵌入,单词嵌入的表达式为:
43、
44、式中,表示单词嵌入;表示文本信息编码器的第一个嵌入输出;ln表示层归一化;wx表示投影矩阵;表示区分指令与视觉观察的类型嵌入;
45、s222、基于文本信息中的单词标记提取文本特征,并对文本信息中的句子指令进行标记与编码。
46、进一步的,将文本特征与视觉特征融合,通过对文本信息的学习,不断更新优化文本与任务之间的依赖关系,使其通过文本更好的理解任务,对机器人未来动作进行预测包括以下步骤:
47、s31、利用transformer模型的自注意力机制学习多个相机视图之间的关系、当前观察和指令之间的关系以及当前观察与历史观察之间的关系,自注意力机制学习的表达式为:
48、
49、式中,q、k、v分别表示transformer模型自注意力机制的三组向量,wq、wk、wv均表示可学习参数;
50、s32、利用一个跨注意层学习视觉标记集合与其条件上下文之间的模态间关系,跨注意层学习模态间关系的表达式为:
51、
52、式中,表示模态间关系;gt表示视觉标记集合;ct表示条件上下文;
53、s33、利用自注意力层学习从多个相机的视图中获得的补丁令牌之间的模态关系,自注意力层学习模态关系的表达式为:
54、
55、式中,表示补丁令牌之间的模态关系;
56、s34、采用由两个线性层组成前馈网络,将transformer模型的输出嵌入与原始编码的视觉表示的嵌入连接在通道维度上,并将平坦的序列重塑为预测特征映射;
57、s35、依据预测特征映射及卷积神经网络对夹持器未来的状态进行预测,输出机器人的预测动作序列。
58、进一步的,依据预测特征映射及卷积神经网络对夹持器未来的状态进行预测,输出机器人的预测动作序列包括以下步骤:
59、s351、将预测特征映射反馈至卷积神经网络的解码网络,利用线性层回归向量对机器人的旋转角度进行预测,预测结果为[qt+1,ct+1];
60、s352、将夹持器的预测位置分解为点云上的预期点坐标与偏移量坐标,预测位置的分解表达式为:
61、
62、式中,pt+1表示预测位置;表示预期点坐标;表示偏移量坐标;
63、s353、对于每个相机,利用卷积神经网络的上采样层预测点云坐标上的注意力图,注意力图上的每个值对应末端执行器到达该点云坐标的概率,再计算期望点坐标,期望点坐标的运算表达式为:
64、
65、式中,表示注意力图中的数值;表示与注意力图中对应的点云坐标;
66、s354、从指令中预测任务序列id,再依据当前步骤id计算偏移量坐标,偏移量坐标的运算表达式为:
67、
68、式中,表示偏移量坐标;pr(m)表示预测任务序列id;m表示特征向量;e0表示可学习的嵌入;t表示当前时间步;t+1表示下一个时间步;
69、s355、结合旋转角度及夹持器状态的预测,输出机器人未来的预测动作序列at+1=[pt+1;qt+1;ct+1]。
70、进一步的,通过对文本信息的学习,进一步学习文本信息与动作之间的依赖关系,对动作序列进行优化包括以下步骤:
71、s41、在整体学习任务的基础上,机器人与周围环境进行交互,预测每个环境状态的动作,以及用于完成动作所需要的工具;
72、s42、学习密集的嵌入机器人的环境,以及训练现有语义表示的知识语料库,允许机器人将预测推广至填充有新对象的新环境;
73、s43、利用语料库的人类展示计划对模型进行训练,语料库包含任务的排序工具交互的常识知识。
74、本发明的有益效果为:
75、1、通过将文本信息与视觉信息结合,通过文本信息与机器人过去的多视角视觉信息和先前的动作信息预测下一步的动作,可以适用于不同的任务,其中融合文本指令和运动信息的网络具有更高的动作预测准确率,为机器人运动规划提供保障。
76、2、通过采用全局和局部融合的形式,将机器人周围的视觉信息投影到鸟瞰视角作为全局信息,同时将机器人主视角作为局部信息,然后将全局特征与局部特征的融合,得到融合后更细粒的视觉特征,从而有效的提高分割精度与速度;其次,通过条件动作解码,利用历史视觉信息和动作信息的学习,结合上下文条件,对机器人下一步运动动作进行预测,相比于其它的运动规划网络具有更好的预测性能和泛化能力的特点。
- 还没有人留言评论。精彩留言会获得点赞!