一种教学发声的模拟展示方法及设备与流程
本申请实施例涉及一种教学发声的模拟展示方法及设备。
背景技术:
传统声乐教学模式仍旧多采用“一对一”教学,通过示范和模仿这样口传心授的模式来传承,在声乐教学与学习过程中,教师的讲解与示范占据了极为重要的地位与主导作用,所以,传统的声乐学习需要几年到几十年的时间。传统声乐的教与学虽然是一种出色的教育形式,但在实际运用中也存在诸多局限:声乐学习是学生通过发声训练慢慢体会声乐技巧并不断取得进步的过程。在这一过程中老师是最重要的向导,通过教授学生必要的发声技巧去引导。而实际上,老师不可能在学生的每一次训练中出现,因此,学生自主的学习显得尤为重要。由于学习者一开始缺乏敏锐的自我听辨能力,不能准确判断和把握自己的发声状态,不能区别自己发声方法是否正确,因此容易在自我练习的时走入误区。并且,传统教学无法自由地选择地点和学习时间。传统声乐的教学是面对面教学,老师要根据每一个学生的不同条件和声音特点因材施教,然而,正是由于声乐教学对实际教学环境这样严格的要求,使得很多没有条件面对面跟教师学习的学生失去了学习机会。绝大多数声乐教师对身体构造不够了解和重视。而声乐的学习离不开科学的发声方法,由于身体的“乐器”是看不见摸不着的,因此太多学生声乐大多数的声乐学生不了解自己的身体构造,以至于在学习的道路上走许多弯路。传统的声乐教学中老师不但要在发声方法上还要在作品分析与演唱风格的把握上作出必要指导。原有的教学模式中,声乐教师对作品的阐述和分析成为学生理解作品最重要的途径,但这一定程度上制约了学生自己理解作品的能力以及学习的能力,也造成学生对老师的依赖性和懒惰性。
技术实现要素:
为解决上述技术问题,本申请实施例期望提供一种教学发声的模拟展示方法及设备。
本发明的技术方案是这样实现的:
本申请实施例提供一种教学发声的模拟展示方法,生成三维人体模特,所述三维人体模特至少包括口、鼻、舌、声源器官、调音区相关器官及其主要肌肉群组;所述方法包括:
至少获取演唱者演唱时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
记录所述演唱者的声音信息,基于所述演唱者演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱者的口型信息;基于所述演唱者演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱者的声源器官的开合状态;基于所述演唱者演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱者的调音区相关器官的肌肉受力状态,模拟所述演唱者的调音区相关器官的形状状态;
根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频文件;
基于针对所述视频文件的调用指令,将所述视频文件输出或上载至服务器。
作为一种实现方式,所述方法还包括:
获取演唱专家演唱设定曲目时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
记录所述演唱专家的声音信息,基于所述演唱专家演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱专家的口型信息;基于所述演唱专家演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱专家的声源器官的开合状态;基于所述演唱专家演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱专家的调音区相关器官的肌肉受力状态,模拟所述演唱专家的调音区相关器官的形状状态;
根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频教学文件;
将所述视频教学文件上载至服务器以供下载。
作为一种实现方式,所述方法还包括:
确定所述设定曲目演唱中的演唱难度超出设定阈值的部分片段,查找所述部分片段所对应的视频片段;
在所述视频片段中为所述三维人体模特的口型、声源器官、调音区相关器官的肌肉添加标示信息;所述标示信息包括发声要点、姿势要点、发力要点的图示及文字说明。
作为一种实现方式,所述方法还包括:
接收所述演唱者的视频文件,根据所述视频文件中所述演唱者的声音信息识别所述视频文件中所述演唱者的演唱曲目;
根据所述演唱者的演唱曲目查找与所述演唱曲目相同的由所述演唱专家演唱的演唱曲目的视频文件;
将所述演唱者的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态与所述演唱专家的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态分别进行比对,确定出所述演唱者的演唱过程中与所述演唱专家演唱过程中的演唱动作之间的差异,将差异超出设定阈值的演唱动作对应的视频或视频截图进行输出,以供演唱者观看学习所述演唱者与所述演唱专家之间的演唱差距。
作为一种实现方式,所述方法还包括:
接收针对所述演唱者的视频文件的评论信息或点播请求,基于所述评论信息对所述演唱者的视频文件进行排序,以及基于所述点播请求为请求者播放所述演唱者的视频文件。
本申请实施例提供还一种教学发声的模拟展示设备,包括:
第一生成单元,用于生成三维人体模特,所述三维人体模特至少包括口、鼻、舌、声源器官、调音区相关器官及其主要肌肉群组;
获取单元,用于至少获取演唱者演唱时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
记录单元,用于记录所述演唱者的声音信息;
模拟单元,用于基于所述演唱者演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱者的口型信息;基于所述演唱者演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱者的声源器官的开合状态;基于所述演唱者演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱者的调音区相关器官的肌肉受力状态,模拟所述演唱者的调音区相关器官的形状状态;
第二生成单元,用于根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频文件;
上载输出单元,用于基于针对所述视频文件的调用指令,将所述视频文件输出或上载至服务器。
作为一种实现方式,所述获取单元还用于获取演唱专家演唱设定曲目时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
所述记录单元还用于记录所述演唱专家的声音信息;
所述模拟单元还用于基于所述演唱专家演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱专家的口型信息;基于所述演唱专家演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱专家的声源器官的开合状态;基于所述演唱专家演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱专家的调音区相关器官的肌肉受力状态,模拟所述演唱专家的调音区相关器官的形状状态;
第二生成单元还用于根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频教学文件;
所述上载输出单元还用于将所述视频教学文件上载至服务器以供下载。
作为一种实现方式,所述设备还包括:
第一查找单元,用于确定所述设定曲目演唱中的演唱难度超出设定阈值的部分片段,查找所述部分片段所对应的视频片段;
标示单元,用于在所述视频片段中为所述三维人体模特的口型、声源器官、调音区相关器官的肌肉添加标示信息;所述标示信息包括发声要点、姿势要点、发力要点的图示及文字说明。
作为一种实现方式,所述设备还包括:
第一接收单元,用于接收所述演唱者的视频文件;
识别单元,用于根据所述视频文件中所述演唱者的声音信息识别所述视频文件中所述演唱者的演唱曲目;
第二查找单元,用于根据所述演唱者的演唱曲目查找与所述演唱曲目相同的由所述演唱专家演唱的演唱曲目的视频文件;
确定单元,用于将所述演唱者的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态与所述演唱专家的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态分别进行比对,确定出所述演唱者的演唱过程中与所述演唱专家演唱过程中的演唱动作之间的差异;
输出单元,用于将差异超出设定阈值的演唱动作对应的视频或视频截图进行输出,以供演唱者观看学习所述演唱者与所述演唱专家之间的演唱差距。
作为一种实现方式,所述设备还包括:
第二接收单元,用于接收针对所述演唱者的视频文件的评论信息或点播请求;
排序单元,用于基于所述评论信息对所述演唱者的视频文件进行排序;
播放单元,用于基于所述点播请求为请求者播放所述演唱者的视频文件。
本申请实施例的技术方案与现有技术相比具有如下优点:
本申请实施例的教学发声的模拟展示方法及设备,教学不受时间和空间上的限制,学习者的学习效率将大大提高。学习者不论在哪里,不论何时,都可以根据自己的需要选择课程。绝大多数的声乐学习者尤其是初学者不够了解自己的“乐器”,通过设置三维人体模特,以3d动画的方式将发声特点及演唱细节要求,使用户树立正确的发声意识和理论知识,并且能做到因材施教,提高用户的学习效率。本申请实施例改变了传统的教学模式,不再是一对一的口传心授,也提高了教学效率。凡是上过线下声乐培训课的学习者,培训学习的费用较高,本申请实施例的教学方式成本更低。另外,由于目前优质教育资源分布不均衡,本申请实施例支持远程教学,从而可以使偏远地区的学习者也可以基于弥补这一不足。
附图说明
图1为本申请实施例的教学发声的模拟展示方法的流程示意图;
图2为本申请实施例的教学发声的模拟展示设备的组成结构示意图。
具体实施方式
在不冲突的情况下,本发明所记载的实施例之间的技术方案能够合并。
下面将结合附图对本发明的技术方案做具体地描述。
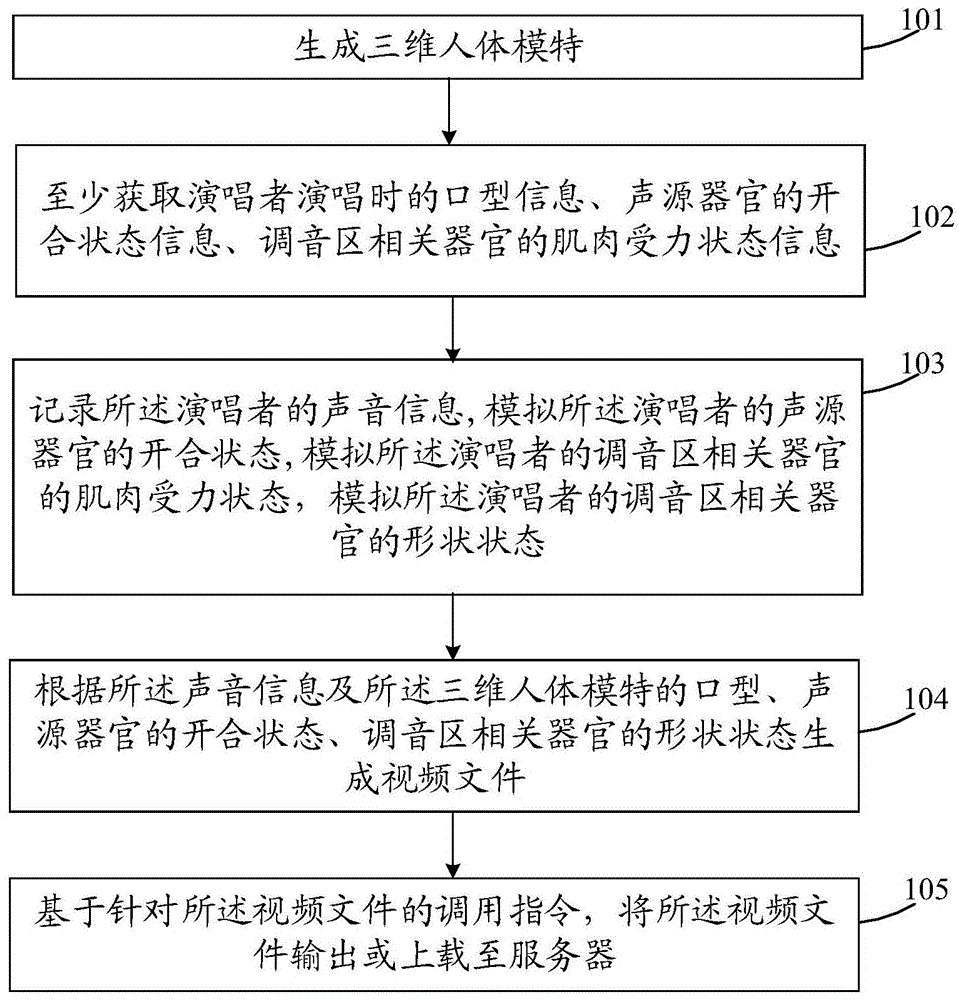
图1为本申请实施例的教学发声的模拟展示方法的流程示意图,如图1所示,本申请实施例的教学发声的模拟展示方法包括以下步骤:
步骤101,生成三维人体模特,所述三维人体模特至少包括口、鼻、舌、声源器官、调音区相关器官及其主要肌肉群组。本申请实施例即是通过3d模特模拟真人演唱过程中的演唱相关的口型、口鼻在发声过程中的肌肉变化情况,声带及喉头的开合姿态,主要发声方式等,以及肺、横膈膜、气管等的变化状态等,口腔、鼻腔、咽腔、腹腔等的姿态及相关肌肉受力情况的说明等,以全方位确定演唱者在演唱过程中的演唱动作,使演唱者能更清楚自己与演唱专家之间的差距,依据如何基于演唱专家的演唱动作改变演唱者自身的演唱动作,更佳地掌握演唱技巧。
步骤102,至少获取演唱者演唱时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
歌唱发声器官的发出声音是发声器官协调工作产生的生理现象,这个现象的产生是气息运动和声带振动所形成的物理现象,但歌唱的发声运动又和平时说话的发声有所不同,因而歌唱发声又是一个物理的声学、音响学现象。因此的歌唱运动可以说是生理、物理的行为。
发音器官是由生理作用各不相同的人体器官构成,当这些器官参与发音活动时,它们被称作发音器官,形成一个具有社会功能的独特系统。歌唱的发声器官是由呼吸器官、发音器官、共鸣器官和咬字器官四个部分组成,它们是歌唱发声的全部物质基础,是歌唱发声运动中的主要功能系统。
唱歌发声器官包括喉头、声带。喉头是一个精巧的小室,位于颈前正中部,由软骨、韧带等肌肉组成。
人体的发音器官可以分为三大部分:动力区、声源区、调音区。
语音是由声音器官发出声音器官及其活动决定语音的区别。
动力区包括肺、横膈膜、气管等相关器官。
肺是呼吸气流的活动风扇,呼吸的气流是语音的动力。肺部呼出的气流,通
过支气管器官到达喉头,作用于声带、咽腔、口腔、鼻腔等发音器官。
声源区包括声带,声带位于喉头的中间,是两片富有弹性的带状薄膜。两片声带之间的空隙叫声门,肌肉的收缩,杓状软骨活动起来可使声带放松或收紧,使声门打开或关闭,从肺中出来的气流通过声门使声音振动发出声音,控制声带松紧的变化可以发出高低不同的声音来。
调音区包括口腔、鼻腔、咽腔等相关器官。口腔(包括唇、齿和舌头)后面是咽腔,咽头上通口腔、鼻腔,下接喉头。口腔和鼻腔靠软腭和小舌分开。软腭和小舌上升时鼻腔关闭,口腔畅通,这是发出的声在口腔中共鸣,叫口音。软腭和小舌下垂,口腔成阻,气流只能从鼻腔中发出,这是发出的音主要在鼻腔中共鸣,叫做鼻音。如果口腔没有阻碍,气流从口腔和鼻腔同时呼出,发出的音在口腔和鼻腔同时产生共鸣,叫鼻化音(也叫半鼻音或口鼻音)。
本申请实施例的主要思想就是记录演唱者在演唱过程中的演唱动作,根据演唱者的演唱动作来作出该演唱者的演唱水平,根据演唱者与演唱专家之间的演唱动作比对,确定出演唱者需要改进的演唱动作,使学习者基于演唱专家的演唱动作更佳地提升自己的演唱水平。
本申请实施例中,可以基于深度相机等对演唱者的口型、演唱外形动作等进行信息采集,通过演唱者演唱血压变化、肌肉变化、各器官的开合状态等确定演唱动作,这些可以演唱相关器官的状态变化可通过相应的传感器来采集其状态变化指标,从而确定出演唱相关器官的状态。
例如,呼吸器官可以看作演唱的“源”动力,是由口、鼻、咽喉、气管、支气管、肺脏以及胸腔、膈肌(又称横膈膜)、腹肌等组成。气息从鼻、口吸入,经过咽、喉、气管、支气管,分布到左右肺叶的肺气泡之中(肺中由两个叶状的海绵组织的风箱构成,它包含了许许多多装气的小气泡);然后经过相反的方向,从肺的出口处分支的气管(支气管)将气息汇集到两面三刀个大气管,最后形成一个气管,再经过咽喉从口、鼻呼出。与呼吸系统相关的各肌肉群,他们的运动也关系到呼吸的能力,是歌唱“源”的动力和能量的保证。日常的呼吸比较平静,比较浅,用不着使用全部的肺活量,但歌唱时的呼吸运动就不同了,吸气动作很快,呼气动作很慢。如果遇上较长的乐句,气息就必须坚持住。而一首歌曲的高、低、强、弱、顿挫、抑扬变化,也全靠吸气、呼气肌肉群的坚强和灵活的运动才能完成。以上呼吸器官的动作可通过相关肌肉群或相关器官的运动状态等确定出相关的演唱动作。
例如,发声器官,即发出声音的器官。它包括喉头、声带。喉头是一个精巧的小室,位于颈前正中部,由软骨、韧带等肌肉组成。声带位于喉头的中间,是两片呈水平状左右并列的、对称的又富有弹性的白色韧带,性质非常坚实。声带的中间又称声门,声带是靠喉头内的软骨和肌肉得到调节的。吸气时两声带分离,声门开启,吸入气息;发声时,两声带靠拢闭合发生声音。声带在不发出声音的时候是放松并张开的,以便使气息顺利通过。声带发声,一部分是自身机能,一部分是依靠声带周边的肌肉群协助进行发声运动。在声乐训练的时候,应该充分注意到这些肌肉群的功能作用,合理地运用它们,养成良好的习惯,避免在不正确的发声习惯下唱坏了嗓子。还有喉咙的上部与舌根之间,有一个很重要的软骨,叫会厌。会厌的功能有两个方面,一是起到声门的保护作用,当吞咽食物和饮水的时候,它本能地自动盖住气管,让食物通过时避免进入气管,往往有时不小心喝水“呛”了气,就是会厌动作不协调所致。第二个作用是歌唱的时候,会厌竖起,形成通道让声音流畅地输出。
人体的共鸣器官主要有胸腔、口腔和头腔三大共鸣腔体。胸腔包括喉头以下的气管、支气管和整个肺部。口腔包括喉、咽腔及口腔。头腔包括鼻腔、上颌窦、额窦、蝶窦等。在歌唱中,由于音商的不同,使用这些共鸣腔的比例是有所不同的。一般来说,唱低音时,胸腔共鸣发挥最大,唱中音时口腔共鸣应用较多,而唱高音时主要是靠头腔鸣发挥作用了。如果能正确、合理地运用好这些共鸣腔体,并相互协调配合好,那我闪就能获得圆润、悦耳、丰满、动听的歌声。
咬字吐字器官咬字吐字器官(即语言器官)包括唇、舌、牙齿和上腭等。这些器官活动时的位置和不同的着力部位,形成了辅音和元音(即语言)。发声歌唱时,咬字、吐字器官各组成部分的动作比平时说话要更加敏捷而夸张。敏捷是为了使咬字准确清晰,夸张是为了使美化的元音或韵母通畅地引长发挥。所以语言器官是在吐字咬字时的物质基础,也是学习吐字咬字时出声、引长和归韵的重要器官。因此,可以通过相应的传感器或相机等获取演唱者的演唱器官的活动情况。
步骤103,记录所述演唱者的声音信息,基于所述演唱者演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱者的口型信息;基于所述演唱者演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱者的声源器官的开合状态;基于所述演唱者演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱者的调音区相关器官的肌肉受力状态,模拟所述演唱者的调音区相关器官的形状状态。
声音是歌唱的基础,要训练好声音进行歌唱,首先要了解所参与发声器官的构造和作用。歌唱运动的感觉远不如看得见、摸得着的如钢琴、小提琴训练那样的肌体运动来得容易,这就要求每个歌唱者要有敏锐的自我感觉,并在专业声乐教师的指导下反复训练,以形成条件反射去断定自己的声音是否正确,是否符合声器官运动的基本规律。
步骤104,根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频文件。
本申请实施例中,通过设置三维人体模特,并根据演唱者在演唱过程中所采集到的演唱动作,以三维人体模特来模拟演唱者的演唱动作,以三维动画展现演唱者在演唱过程中的人体构造,让演唱者更加了解自己的“乐器”,不再是只依赖“感觉”来演唱,而是通过了解身体构造,更加科学地发声,树立正确的发声意识和审美方向。
步骤105,基于针对所述视频文件的调用指令,将所述视频文件输出或上载至服务器。
本申请实施例中,当获取演唱者所演唱的模拟三维模拟视频后,可以直接由演唱者进行观看,并基于演唱专家的相关演唱模拟动作,对自身的演唱动作进行更正,以提升自我的演唱水平。
本申请实施例中,不仅演唱者的模拟动作需要进行演唱动作采集,对于演唱专家,也需要进行演唱动作采集,以生成教学视频的三维模拟演唱动作,以使学习者参考学习。具体包括以下步骤:
获取演唱专家演唱设定曲目时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
记录所述演唱专家的声音信息,基于所述演唱专家演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱专家的口型信息;基于所述演唱专家演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱专家的声源器官的开合状态;基于所述演唱专家演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱专家的调音区相关器官的肌肉受力状态,模拟所述演唱专家的调音区相关器官的形状状态;
根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频教学文件;
将所述视频教学文件上载至服务器以供下载。
作为一种实现方式,所述方法还包括:
确定所述设定曲目演唱中的演唱难度超出设定阈值的部分片段,查找所述部分片段所对应的视频片段;
在所述视频片段中为所述三维人体模特的口型、声源器官、调音区相关器官的肌肉添加标示信息;所述标示信息包括发声要点、姿势要点、发力要点的图示及文字说明。
本申请实施例中,针对演唱曲目中演唱动作较难的地方,可以将演唱动作更细化地采集,并在演唱模拟视频中相应的较难的演唱片段中增加相应的图片、声音或文字说明,以使学习者更好地掌握演唱动作的要领。
作为一种实现方式,所述方法还包括:
接收所述演唱者的视频文件,根据所述视频文件中所述演唱者的声音信息识别所述视频文件中所述演唱者的演唱曲目;
根据所述演唱者的演唱曲目查找与所述演唱曲目相同的由所述演唱专家演唱的演唱曲目的视频文件;
将所述演唱者的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态与所述演唱专家的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态分别进行比对,确定出所述演唱者的演唱过程中与所述演唱专家演唱过程中的演唱动作之间的差异,将差异超出设定阈值的演唱动作对应的视频或视频截图进行输出,以供演唱者观看学习所述演唱者与所述演唱专家之间的演唱差距。
本申请实施例还支持将演唱者的演唱动作与演唱专家的演唱动作之间进行自动比对,确定出演唱者演唱动作不足之处,并向演唱者输出,以使演唱者知道自己演唱动作存在哪些不足,需要提升演唱水平的片段是哪些。
作为一种实现方式,所述方法还包括:
接收针对所述演唱者的视频文件的评论信息或点播请求,基于所述评论信息对所述演唱者的视频文件进行排序,以及基于所述点播请求为请求者播放所述演唱者的视频文件。
本申请实施例中,演唱者可以根据自己的性别和嗓音的种类选择相应的演唱动作采集。演唱者演唱完后可以根据大数据分析结果,将用户演唱的结果反馈给用户,并提供与之相对应的3d动画,可与名家的3d动画相比较,用户将更加直观地看到问题所在,从而提高学习效率。
用户可在app里发布自己的演唱练习片段,其他用户可点赞评论转发等。app平台可发布一些针对作品的演唱背景、作品分析等一系列视频。
基于演唱者的演唱视频,可建立论坛、群聊等,可以资源共享,交流学习经验,提高学习积极性。
本申请实施例可选择远程教学,进行实时教学,因材施教,进而更加准确把握歌曲的演唱风格。
图2为本申请实施例的教学发声的模拟展示设备的组成结构示意图,如图2所示,本申请实施例的教学发声的模拟展示设备包括:
第一生成单元20,用于生成三维人体模特,所述三维人体模特至少包括口、鼻、舌、声源器官、调音区相关器官及其主要肌肉群组;
获取单元21,用于至少获取演唱者演唱时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
记录单元22,用于记录所述演唱者的声音信息;
模拟单元23,用于基于所述演唱者演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱者的口型信息;基于所述演唱者演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱者的声源器官的开合状态;基于所述演唱者演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱者的调音区相关器官的肌肉受力状态,模拟所述演唱者的调音区相关器官的形状状态;
第二生成单元24,用于根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频文件;
上载输出单元25,用于基于针对所述视频文件的调用指令,将所述视频文件输出或上载至服务器。
作为一种实现方式,所述获取单元21还用于获取演唱专家演唱设定曲目时的口型信息、声源器官的开合状态信息、调音区相关器官的肌肉受力状态信息;
所述记录单元22还用于记录所述演唱专家的声音信息;
所述模拟单元23还用于基于所述演唱专家演唱时的口型信息调整所述三维人体模特的口型以模拟所述演唱专家的口型信息;基于所述演唱专家演唱时的声源器官的开合状态信息调整所述三维人体模特的声源器官肌肉群组受力状态,模拟所述演唱专家的声源器官的开合状态;基于所述演唱专家演唱时的调音区相关器官的肌肉受力状态信息,模拟所述演唱专家的调音区相关器官的肌肉受力状态,模拟所述演唱专家的调音区相关器官的形状状态;
第二生成单元24还用于根据所述声音信息及所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态生成视频教学文件;
所述上载输出单元25还用于将所述视频教学文件上载至服务器以供下载。
作为一种实现方式,所述设备还包括:
第一查找单元(图中未示出),用于确定所述设定曲目演唱中的演唱难度超出设定阈值的部分片段,查找所述部分片段所对应的视频片段;
标示单元(图中未示出),用于在所述视频片段中为所述三维人体模特的口型、声源器官、调音区相关器官的肌肉添加标示信息;所述标示信息包括发声要点、姿势要点、发力要点的图示及文字说明。
作为一种实现方式,所述设备还包括:
第一接收单元(图中未示出),用于接收所述演唱者的视频文件;
识别单元(图中未示出),用于根据所述视频文件中所述演唱者的声音信息识别所述视频文件中所述演唱者的演唱曲目;
第二查找单元(图中未示出),用于根据所述演唱者的演唱曲目查找与所述演唱曲目相同的由所述演唱专家演唱的演唱曲目的视频文件;
确定单元(图中未示出),用于将所述演唱者的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态与所述演唱专家的视频文件中的所述三维人体模特的口型、声源器官的开合状态、调音区相关器官的形状状态分别进行比对,确定出所述演唱者的演唱过程中与所述演唱专家演唱过程中的演唱动作之间的差异;
输出单元(图中未示出),用于将差异超出设定阈值的演唱动作对应的视频或视频截图进行输出,以供演唱者观看学习所述演唱者与所述演唱专家之间的演唱差距。
作为一种实现方式,所述设备还包括:
第二接收单元(图中未示出),用于接收针对所述演唱者的视频文件的评论信息或点播请求;
排序单元(图中未示出),用于基于所述评论信息对所述演唱者的视频文件进行排序;
播放单元(图中未示出),用于基于所述点播请求为请求者播放所述演唱者的视频文件。
本领域技术人员应当理解,本申请实施例的教学发声的模拟展示设备的技术方案可参照前述教学发声的模拟展示方法的实施例而理解,其中的处理单元可通过软件或模拟电路的方式而实现。
本申请实施例的教学发声的模拟展示方法及设备,教学不受时间和空间上的限制,学习者的学习效率将大大提高。学习者不论在哪里,不论何时,都可以根据自己的需要选择课程。绝大多数的声乐学习者尤其是初学者不够了解自己的“乐器”,通过设置三维人体模特,以3d动画的方式将发声特点及演唱细节要求,使用户树立正确的发声意识和理论知识,并且能做到因材施教,提高用户的学习效率。本申请实施例改变了传统的教学模式,不再是一对一的口传心授,也提高了教学效率。凡是上过线下声乐培训课的学习者,培训学习的费用较高,本申请实施例的教学方式成本更低。另外,由于目前优质教育资源分布不均衡,本申请实施例支持远程教学,从而可以使偏远地区的学习者也可以基于弥补这一不足。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述,仅为本申请的较佳实施例而已,并非用于限定本申请的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!