一种用于PM2.5小时浓度预测的混合集成模型
本发明涉及pm2.5浓度预测技术领域,具体来说,涉及一种用于pm2.5小时浓度预测的混合集成模型。
背景技术:
随着近些年国民经济和城市化进程的快速发展,空气污染、灰霾事件频发,空气质量预报日益成为政府和公众关注的焦点问题。其中预报的污染物浓度数据包括pm2.5、pm10、o3、no2、so2、co等6种污染物浓度。
pm2.5又称细颗粒物,细颗粒物指环境空气中空气动力学当量直径小于等于2.5微米的颗粒物。它能较长时间悬浮于空气中,其在空气中含量浓度越高,就代表空气污染越严重。虽然pm2.5只是地球大气成分中含量很少的组分,但它对空气质量和能见度等有重要的影响。与较粗的大气颗粒物相比,pm2.5粒径小,面积大,活性强,易附带有毒、有害物质(例如,重金属、微生物等),且在大气中的停留时间长、输送距离远,因而对人体健康和大气环境质量的影响更大。
现有技术将pm2.5数据分解后都需要一个预测模型,且没有考虑分解分量之间的相似性造成的模型冗余,预测效果差。而现有方案采用ceemdan算法将复杂的pm2.5数据分解为有限平稳的imf分量。将每个静止的imf展开为轨迹矩阵。该方法将轨迹矩阵划分为一组聚类样本。然后,通过训练聚类样本建立lstm模型。计算聚类中心与测试样本之间的距离,选择最优的lstm模型,并选择相应的最小距离,对各子层的测试数据进行预测。构造各子层的预测,得到最终结果。ceemdan-fcm-lstm混合模型可以很容易地应用于pm2.5预测。
检索中国发明专利cn112132336a公开了一种pm2.5浓度的季度预测方法,属于空气质量预测技术领域。它包括步骤:s100:收集区域的数据并对数据进行筛选,其中,数据包括气象数据、污染数据和基准排放清单数据;s200:根据筛选后的数据构建区域的气象-空气质量模型;s300:根据筛选后的数据和气象-空气质量模型获取区域的反演季度排放清单;s400:收集全球气象预报场数据,并根据全球气象预报场数据构建预测模型;s500:根据反演季度排放清单并利用预测模型模拟得到区域pm2.5的季度预测浓度。其克服了现有技术中,无法实现长时间尺度的pm2.5浓度预测的不足,提供了一种pm2.5浓度的季度预测方法,可以实现长时间尺度的pm2.5浓度预测,从而可以为精细化治理提供更多的管控提前量。但其存在预测精度较低,且适应性较差,且存在一定局限性的问题。
针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
针对相关技术中的问题,本发明提出一种用于pm2.5小时浓度预测的混合集成模型,以克服现有相关技术所存在的上述技术问题。
本发明的技术方案是这样实现的:
一种用于pm2.5小时浓度预测的混合集成模型,包括以下步骤:
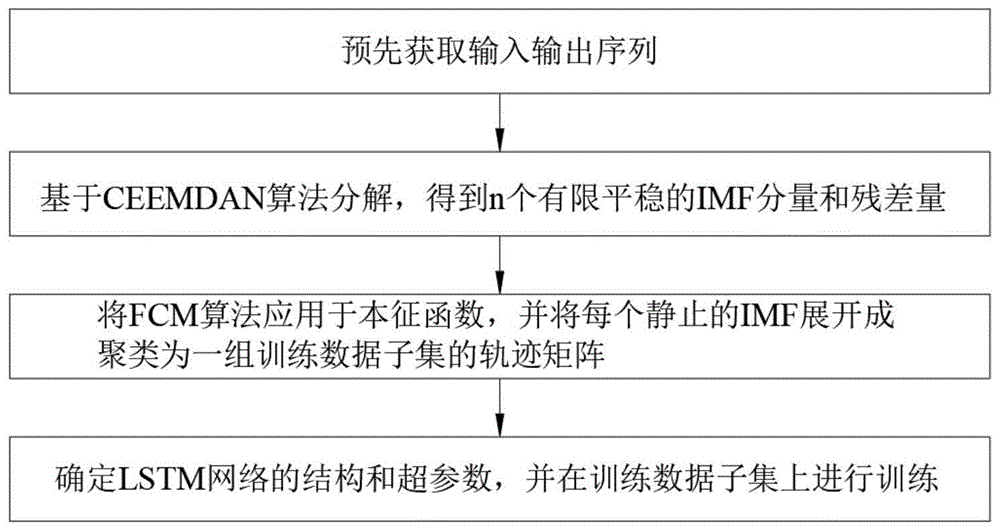
预先获取输入输出序列,表示为:{x(1),x(2),...,x(t)}和{y(1),y(2),...,y(t)};
基于ceemdan算法分解x(t),(t=1,...,t),得到n个有限平稳的imf分量和残差量;
将fcm算法应用于本征函数,并将每个静止的imf展开成聚类为一组训练数据子集的轨迹矩阵;
确定lstm网络的结构和超参数,并在训练数据子集上进行训练。
进一步的,所述获取输入输出序列,还包括以下步骤:
进行对数据进行归一化处理。
进一步的,还包括以下步骤:
训练阶段结束后,用于预测后续测试样本的输出。
本发明的有益效果:
本发明用于pm2.5小时浓度预测的混合集成模型,通过预先获取输入输出序列,基于ceemdan算法分解x(t),(t=1,...,t),得到n个有限平稳的imf分量和残差量,将fcm算法应用于本征函数,并将每个静止的imf展开成聚类为一组训练数据子集的轨迹矩阵,确定lstm网络的结构和超参数,并在训练数据子集上进行训练,实现基于ceemdan数据分解和fcm聚类的lstm网络混合模型预测策略。采用ceemdan数据分解方法降低原始pm2.5数据序列的复杂度,采用fcm聚类方法将特征相似的成分聚到一起,利用粒子群优化lstm网络建立pm2.5预测模型,预测精度高,且计算程度低,适应性强。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的流程示意图;
图2是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的ceemdan-fcm-lstm建模框架示意图;
图3(a)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的a气象局ceemdan分解结果示意图;
图3(b)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的b水厂ceemdan分解结果示意图;
图3(c)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的c酿酒公司ceemdan分解结果示意图;
图4(a)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的a气象局测试集上的预报结果示意图;
图4(b)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的b水厂测试集上的预报结果示意图;
图4(c)是根据本发明实施例的一种用于pm2.5小时浓度预测的混合集成模型的c酿酒公司测试集上的预报结果示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
根据本发明的实施例,提供了一种用于pm2.5小时浓度预测的混合集成模型。
如图1-图2所示,根据本发明实施例的用于pm2.5小时浓度预测的混合集成模型,包括以下步骤:
预先获取输入输出序列,表示为:{x(1),x(2),...,x(t)}和{y(1),y(2),...,y(t)};
基于ceemdan算法分解x(t),(t=1,...,t),得到n个有限平稳的imf分量和残差量;
将fcm算法应用于本征函数,并将每个静止的imf展开成聚类为一组训练数据子集的轨迹矩阵;
确定lstm网络的结构和超参数,并在训练数据子集上进行训练。
其中,所述获取输入输出序列,还包括以下步骤:
进行对数据进行归一化处理。
其中,还包括以下步骤:
训练阶段结束后,用于预测后续测试样本的输出。
借助于上述技术方案,通过预先获取输入输出序列,基于ceemdan算法分解x(t),(t=1,...,t),得到n个有限平稳的imf分量和残差量,将fcm算法应用于本征函数,并将每个静止的imf展开成聚类为一组训练数据子集的轨迹矩阵,确定lstm网络的结构和超参数,并在训练数据子集上进行训练,实现基于ceemdan数据分解和fcm聚类的lstm网络混合模型预测策略。采用ceemdan数据分解方法降低原始pm2.5数据序列的复杂度,采用fcm聚类方法将特征相似的成分聚到一起,利用粒子群优化lstm网络建立pm2.5预测模型,预测精度高,且计算程度低,适应性强。
另外,如图3(a)-图3(c)所示,研究a气象局、b水厂、c酿酒公司三个不同经济发展水平和自然环境的监测点,以满足丰富多样的环境条件,三组数据的ceemdan分解结果如图3(a)-图3(c)所示。
另外,并对三组数据进行了建模,验证了所提模型的建模性能和泛化性。进行获取2020年1月1日至12月31日逐时地面监测pm2.5数据。其中,2020年共366天是闰年,每个监测点共采集8784个样本,将其分成两部分:1-10月的7320个样本用于培训,11-12月的7320个样本用于测试。三组pm2.5数据的统计指标见表1。
表1四组pm2.5数据的统计指标
此外,采用三种不同的bp、rbf和lstm神经网络作为预测网络模型方法。bp神经网络的权值由遗传优化法确定,rbf的模型结构由试错法确定。通过粒子群优化算法(pso)得到lstm网络的学习率、隐含层神经元的数量和批处理的规模。选取某地区不同地区的3个监测点。采用结合ceemdan和fcm方法的不同神经网络模型及其改进方法对这三个地区的pm2.5进行逐时预测。各模型在不同监测点试验集上的结果见表2、表3、表4。
表2各模型在平桥气象局测试集上的评价结果
表3各模型在南湾水厂测试集上的评价结果
表4各模型在酿酒公司测试集上的评价结果
另外,其bp、rbf、lstm神经网络模型结合ceemdan分解器可以有效提高预测性能,统计指标如表2、表3、表4所示。例如,在a气象局,bp、rbf和lstm模型结合ceemdan分解后的均方根误差分别比没有ceemdan分解的模型降低26.29%、22.46%和59%。ceemdan方法可以在多尺度上分解非线性、非平稳的pm2.5数据序列。imf子序列和残差项可以降低原始pm2.5数据序列的复杂度,从而使每个子序列或残差项的建模更加准确。
虽然使用ceemdan方法可以得到imf子序列和残差项,但其中一些子序列相关性较强,因此没有必要对每个子序列建模。从评价结果还可以看出,对这些子序列进行聚类集成的fcm方法对提高模型预测的精度有着重要的影响。ceemdan-bp模式、ceemdan-rbf模式和ceemdan-lstm模式结合fcm后的rmse分别比未结合fcm的模式降低了4.49%、5.15%和3.19%。
此外,本发明的ceemdan-fcm-lstm方法在各个监测测试集的预测性能最好。该方法不仅结合了ceemdan分解方法和fcm聚类策略,而且lstm网络具有特殊的门结构和记忆功能。同时,pso算法可以帮助lstm网络获得最好的超参数,从人工试错选择的繁琐任务中解放出来。
另外,如图4(a)-图4(c)所示,其为了更直观的对比,图4(a)、图4(b)、图4(c)分别显示了三组不同监测点的详细预测结果。可以看出,ceemdan-fcm-lstm方法的综合性能优于其他模型,从预测结果对比图中可以看出类似的结果。以a气象局预报结果为例,预报结果与原曲线吻合较好,该模型的预测曲线最接近真实曲线。因此,本发明ceemdan-fcm-lstm方法适用于描述pm2.5数据行为,可以提高预测性能。
综上所述,借助于本发明的上述技术方案,通过预先获取输入输出序列,基于ceemdan算法分解x(t),(t=1,...,t),得到n个有限平稳的imf分量和残差量,将fcm算法应用于本征函数,并将每个静止的imf展开成聚类为一组训练数据子集的轨迹矩阵,确定lstm网络的结构和超参数,并在训练数据子集上进行训练,实现基于ceemdan数据分解和fcm聚类的lstm网络混合模型预测策略。采用ceemdan数据分解方法降低原始pm2.5数据序列的复杂度,采用fcm聚类方法将特征相似的成分聚到一起,利用粒子群优化lstm网络建立pm2.5预测模型,预测精度高,且计算程度低,适应性强。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!