一种基于SSTM的中医证候智能诊断方法与流程
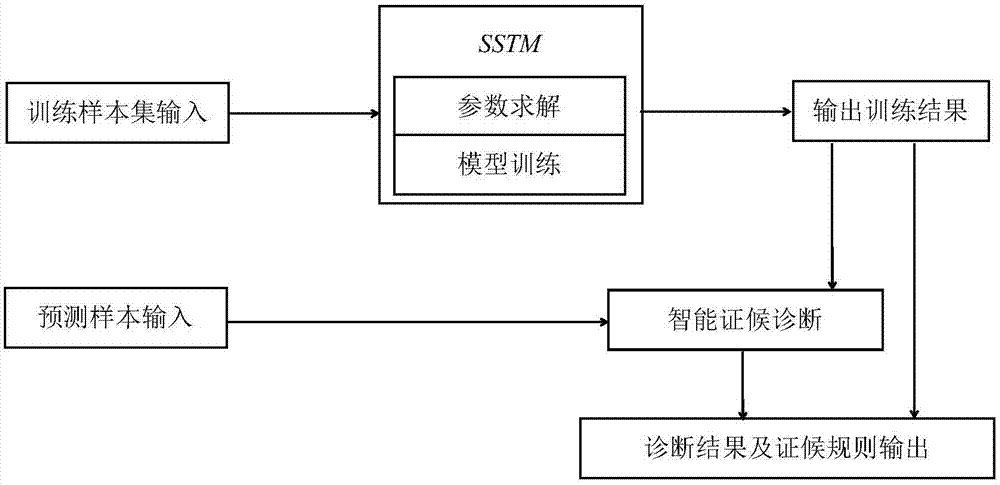
本发明涉及一种中医智能诊断方法,具体涉及一种基于sstm的中医证候智能诊断方法。
背景技术:
:“辨证论治”是中医的特色之一,在中医诊疗过程中,一个关键环节是“辩证”,即:医生需通过病人的“四诊”信息—望闻问切进行证候诊断,从而确定治疗方案及方剂配伍,“辩证”体现了中医的知识、经验和水平。由于证候具有复杂性、多样性和模糊性等特点,中医学习者,尤其是青年医生要掌握“辩证”规律往往需要花数年甚至说十年的时间,从数据挖掘的角度,中医尤其是名老中医关于证候诊断的丰富经验和知识隐藏在大量的诊疗历史记录中。现有的关于中医智能诊断的数据分析和挖掘技术,主要采用多元统计及常规数据挖掘方法,不能有效应对复杂的证候诊断规律挖掘,未能达到实际应用的水平。技术实现要素:发明目的:本发明提供一种基于sstm的中医证候智能诊断方法,本方法可应用于中医学习系统中,大大降低中医诊断知识学习和掌握的难度,还能应用于各种中医智能化诊疗系统中,对促进证候诊断智能化和标准化具有重要意义。技术方案:本发明所述的一种基于sstm的中医证候智能诊断方法,包括以下步骤:(1)输入计算机程序可识别的病人电子文档诊疗记录数据集;(2)构建sstm,并对模型中的参数求解;(3)对sstm进行训练,保存训练结果;(4)输入预测样本;(5)智能证候诊断—采用松弛sstm进行增量训练;(6)诊断结果及其症候规则输出;其中,松弛sstm是sstm在初始化和抽样阶段取消对证候随机分配的显性约束条件。所述数据集的每一条数据视作一个文档d,由一个或者多个证候及相应多个症状组成。所述步骤(2)包括以下步骤:(21)构建sstm,模型主题由来自数据集中显性变量—证候标签充当,对主题的分配只针对主症,次症不被分配主题,一个症状sdn的生成概率公式如下:其中,d表示一条中医诊疗记录,s表示症状,sdn表示文档d的第n个症状,z表示证候,zdn表示文档d的第n个症状所属证候,y为主症和次症标记,ydn=0表示文档d的第n个症状为主症,ydn=1表示文档d的第n个症状为次症;(22)对sstm参数采样求解,具体公式如下:其中,“-”表示排除当前位置症状t;表示在文档d中,排除当前位置症状t后所有y=1的症状的计数,表示在文档d中排除当前位置症状t后所有症状的计数,表示训练集中排除当前位置症状t后,所有出现t的计数,表示训练集中排除当前位置症状t后,所有症状的计数,v表示训练集中症状个数,ν为beta(ν)分布超参数,η为dirichlet(η)分布超参数;其中,“-”表示排除当前位置症状t,表示在文档d中,排除当前位置症状t后所有y=0的症状的计数,表示在文档d中排除当前位置症状t后所有症状的计数,表示训练集中排除当前位置症状t后,编号为k的证候中所有出现t的计数;表示训练集中排除当前位置症状t后,编号为k的证候中所有症状的计数;表示在文档d中,排除当前位置症状t后所有被标记为证候编号为k的症状的计数,表示在文档d中排除当前位置症状t后所有被标记为y=0症状的计数,md表示文档d中证候的个数,ν为beta(ν)分布超参数,α和β为dirichlet分布超参数;为证候k的规则参数,具体到某一个症状t属于证候k的概率值采用均值参数估计法计算:表示症状t属于编号为k的证候的概率;θd表示文档d所含所有证候的概率参数,具体到某一个证候k属于文档d的概率,采用均值参数估计法:表示证候k属于文档d的概率。所述步骤(3)包括以下步骤:(31)输入抽样迭代次数iter,超参数ν、η、α和β,训练样本集;(32)随机初始化1:遍历训练数据集,对训练数据集中每一个文档的每一个症状s,随机的赋予一个y值,由向量y保存;(33)随机初始化2:遍历训练数据集,对每一个文档所有被赋予y=0的症状s,从该文档的λd的集合中随机分配一个证候编号,由向量z保存;(34)重新遍历训练数据集,对每一个s,当s的主次症指示变量ys=1是按照公式(2)重新采样ys值,当ys=0按照公式(3)重新采样s的证候编号,并在y和z数据中更新;(35)重复以上对数据集的采样过程iter次,直至吉布斯采样收敛;(36)根据公式(4)统计得到证候规则φk;(37)输出y和z,证候规则φk。步骤(5)中所述松弛sstm是sstm在初始化和抽样阶段取消对证候随机分配的显性约束条件λd。所述步骤(5)包括以下步骤:(51)输入抽样迭代次数iter,超参数ν、η、α和β,待预测样本,步骤(36)中所得的y和z;(52)随机初始化1:遍历待预测样本,对其中的每一个症状s,随机的赋予一个y值,由更新向量y保存;(53)随机初始化2:遍历待预测样本,对其中所有被赋予y=0的症状s,从所有在z中出现的证候编号集合中随机分配一个证候编号;(54)重新遍待预测样本,对其中的每一个s,当s的主次症指示变量ys=1是按照公式(2)重新采样ys值;当ys=0按照公式(3)重新采样s的证候编号,并在y和z中更新;(55)重复以上对数据集的采样过程iter次,直至吉布斯采样收敛;(56)根据公式(5)统计得到待预测病人的证候诊断结果θd;(57)输出待预测样本证候诊断结果θd。有益效果:与现有技术相比,本发明的有益效果:1、提出了一个新的症状-证候主题模型(sstm);2、sstm模型中区分了主症和次症的不同地位,降低了次要症状对证候诊断的干扰;3、待诊断病人的无证候标签数据采用松弛sstm进行智能辩证,能够提高中医智能辩证准确率。附图说明图1为本发明的流程图;图2为证候与症状关系图。具体实施方式下面结合附图对本发明作进一步详细说明,图1为本发明的流程图。1、训练样本集和预测样本的选取具体样本数据自于国家人口与健康科学数据共享平台,采集了21种中医疾病专题数据库数据,涉及1741种疾病,共有127,541条数据,除去没有证候标记的数据后有51,144条,进一步除去症状和证候数量少于3个的数据后,为8,751条数据;随机取其中的90%条数据作为训练集,其余10%条作为测试集。关于样本数据的具体格式如表1所示。表1训练样本数据示例2、构建sstm,模型主题由来自数据集中显性变量—证候标签充当,对主题的分配只针对主症,次症不被分配主题,采用如图2所描述症候与症状的深度关系,这种描述反映了中医主症与次症的辩证原则,能够更加准确的描述中医证候诊断过程。3、参数设置sstm模型训练阶段参数:对sstm按照上述训练算法进行训练,抽样迭代次数iter=1000;超参数ν=0.5、γ=0.01、η=0.01、α=k/50(k为训练数据集中出现的无重复的证候数)和β=0.01。松弛sstm进行增量训练阶段参数:对松弛sstm按照上述训练算法进行训练,抽样迭代次数iter=1000;超参数ν=0.5、η=0.01、α=k/50和β=0.01。4、对sstm模型进行训练sstm训练算法如下:输入:抽样迭代次数iter,超参数ν、η、α和β,训练样本集;输出:向量y和z,证候规则(1)随机初始化1:遍历训练数据集,对训练数据集中每一个文档的每一个症状s,随机的赋予一个y值(y=0,ory=1),由向量y保存;(2)随机初始化2:遍历训练数据集,对每一个文档所有被赋予y=0的症状s,从该文档的λd的集合中随机分配一个证候编号,由向量z保存(其中,对训练数据集中所有文档出现的证候进行编号,λd为文档d中所证候的编号集合);(3)重新遍历训练数据集,对每一个s,当s的主次症指示变量ys=1是按照公式(2)重新采样ys值;当ys=0按照公式(3)重新采样s的证候编号(采用过程受λd约束),并在y和z数据中更新;(4)重复以上对数据集的采样过程(3)iter次,直至gibbssampling收敛;(5)根据公式(4)统计得到证候规则φk;(6)输出y和z;证候规则φk。5、基于sstm训练结果的证候规则基于sstm训练结果的证候规则,选取部分证候前5个概率值最大的症状如表2所示:表2证候规则示例6、智能证候诊断—松弛sstm进行增量训练在智能证候诊断阶段,接收的输入为病人的多个症状信息,未知证候,而sstm模型为有监督的学习,不能直接用于证候诊断的增量训练;因此,本发明采用松弛sstm进行增量训练,松弛sstm是在sstm的初始化和抽样阶段取消对证候随机分配的显性约束条件λd,松弛sstm可用于对未知证候标签的待诊断病人症状信息重新进行增量模型训练,从而得到智能诊断结果。松弛sstm训练算法如下:输入:抽样迭代次数iter,超参数ν、η、α和β,待预测样本,训练阶段所得的y和z;输出:预测样本证候诊断结果θd;(1)随机初始化1:遍历待预测样本,对其中的每一个症状s,随机的赋予一个y值(y=0,ory=1),由更新向量y;(2)随机初始化2:遍历待预测样本,对其中所有被赋予y=0的症状s,从所有在z中出现的证候编号集合中随机分配一个证候编号;(3)重新遍待预测样本,对其中的每一个s,当s的主次症指示变量ys=1是按照公式(2)重新采样ys值;当ys=0按照公式(3)重新采样s的证候编号(采用过程随机分配的证候编号来自所有在z中出现的证候编号集合),并在y和z中更新;(4)重复以上对数据集的采样过程(3)iter次,直至gibbssampling收敛;(5)根据公式(5)统计得到待预测病人的证候诊断结果θd。(6)输出待预测样本证候诊断结果θd。7、诊断结果示例输出θd中概率最大的前m个证候为待诊断病人的诊断结果,输出该病人所有症状的主要症状和次要症状的标记向量yd,输出保存k个证候的规则输入待预测病人症状:咳喘,胸闷,痰黄粘脓,发热,流涕,咽痛,口渴,溺黄,大便干结,舌红,苔黄,脉滑数,咳声无力,痰液清稀,喘促,自汗,纳呆,腹胀,神疲,乏力,大便溏烂,舌质淡,苔白,脉濡缓,喘咳输出诊断结果:证候诊断:痰热蕴肺证,脾肺气虚证,肺肾阴虚证,主症(必然症):咳喘、胸闷、发热、流涕、咽痛、口渴、大便干结、舌红、苔黄、脉滑数、痰液清稀、喘促、乏力、舌质淡、喘咳;次症(或然症):痰黄粘脓、溺黄、咳声无力、自汗、纳呆、腹胀、神疲、大便溏烂、苔白、脉濡缓。本方法涉及的证候诊断问题可划归为机器学习的多标签分类问题:一个样本由多个症状和一个或多个证候组成,这些症状可视为样本的内容数据,证候可视为样本的分类标签。因此,可采用多标签分类任务的评价指标进行方法结果对比评价,这里选用准确率和评判综合指标f1进行结果评价,本发明提出的方法(sstm)与支持向量机(svm)、朴素贝叶斯(nb)两种分类算法进行比较,如表3所示:表3三种方法证候诊断结果比较方法准确率(%)f1值nb68.2160.21svm75.6567.98sstm79.1472.61由表3可看出,使用本方法对中医证候智能诊断的准确率最高,综合指标值也最高。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1