动态音频源分离的方法和系统与流程
本发明涉及音频源分离的方法和系统。具体地,该方法和系统针对音频源分离利用基于组合的文本和示例的方法。本发明还涉及适用于这种方法或系统的计算机可读介质。
背景技术:
音频源分离涉及将音频混合分解为其组成声源。这提供了在音频/语音增强、后期制作、3D音频等中宽泛的应用范围。尤其,盲源分离(BSS)假定在不具有关于源、混合、和/或生成混合的混合过程的情况下执行音频源分离。另一方面,消息源分离(ISS)允许利用来自一些辅助信息的指导来执行音频源分离。
大多数用于监督式音频源分离的现有方法是基于示例的方法。这些方法的先决条件是事先获得一些类似于目标音频源的音频样本,这通常比较繁琐且并非总是可能的。当音频样本事先是不可用的时,替代地,可以使用简单文本查询来搜索音频文件。该用于音频源分离的基于文本查询的方法对于用户更为容易并且更为有效,因为用户仅需要例如听音频混合并提供描述他们想要分离的内容的文字。然而,尽管在[XII]中描述了基于本文查询的方法,但是目前为止还没有任何能够有效地处理噪声或非代表性取回示例的实际解决方案。
对于基于示例的音频源分离,单频道源分离是欠定的问题,并因此是在最具挑战的问题之中。若干算法提议考虑预先学习单个声源的频谱特性,以便将它们从音频混合中分离。为了实现该目的,需要获得初期训练数据来学习并指示单个目标源的频谱特性。基于非负矩阵分解(NMF)[I,II,III]或其被称为概率性潜在分量分析(PLCA)[IV,V]的概率性公式来提出监督式算法的类别。然而,当训练数据不可用或不足以代表音频源时,上述方法在不具有关于源的补充信息的情况下变得不再适用。例如,补充信息包括模仿混合中的“哼(hummed)”的声音[V],或者相应的音频混合的文本转录[VI]。
最近已经提出了基于NMF的针对音频源分离的用户指导方法[VII],借此整体的音频源分离过程可能包括若干交互式分离步骤。这些方法允许终端用户手动地注释关于每个声源的活动性的信息。代替上述所提到的训练数据,使用该注释的信息来指导源分离过程。此外,用户能够通过在分离过程期间注释中间分离结果的频谱图显示来核查分离结果并纠正其错误。
然而,对于上述用户指导方法和交互式方法,需要用户具有一些关于音频源频谱图和音频信号处理的基本知识,以便手动地指定音频源的特性,从而与分离过程进行交互。换句话说,可选择的交互和音频源分离的干扰对于终端用户并非容易和实用。此外,注释过程即使对于专业操作员也是很耗时的。
技术实现要素:
本发明的目的是提出一种改进的用于音频源分离的解决方案,具体在于简化用户交互,以便没有经验的中断用户可以容易地执行源分离任务。
根据本发明的第一方面,一种音频源分离的方法包括:接收音频混合和与音频混合相关联的至少一个文本查询;通过将文本查询和与辅助音频数据库相关联的语义信息进行匹配从辅助音频数据库中取回至少一个音频样本;评估从辅助音频数据库中取回的音频样本;以及使用取回的音频样本将音频混合分离成多个音频源。在本发明的一个实施例中,评估音频样本和分离音频混合是通过对音频混合和音频样本应用非负矩阵分解(NMF)来被共同执行的。
因此,被配置为实现音频源分离的方法的系统,包括:接收单元,被配置为接收音频混合和与音频混合相关联的至少一个文本查询;以及处理器,被配置为通过将文本查询和与辅助音频数据库相关联的语义信息进行匹配从辅助音频数据库中取回至少一个音频样本,从而评估从辅助音频数据库中取回的音频样本,以及使用该音频样本将音频混合分离成多个音频源。
此外,一种存储有用于音频混合的音频源分离的指令的计算机可读介质,当指令由计算机执行时,使得计算机:接收音频混合和与音频混合相关联的至少一个文本查询;通过将文本查询和与辅助音频数据库相关联的语义信息进行匹配从辅助音频数据库中取回至少一个音频样本;评估从辅助音频数据库中取回的音频样本;以及使用音频样本将音频混合分离成多个音频源。
本发明的音频源分离的方法简化过程并改进源分离的结果。通过结合本文和样本的方法,允许终端用户通过简单地提供描述混合中的声音的文本查询或口语音频很容易地与执行音频源分离的系统进行交互。在后一种情况中,语音到文本接口被用来将口语音频查询转换为文本查询。评估最初取回的音频样本通过提供更好的训练源样本来改进后续的音频源分离。在本发明的一个实施例中,源样本的评估和音频混合的源分离是被共同执行的,音频源分离的整个过程变得更为有效。
附图说明
为了更好地理解本发明,现在参考附图来更详细地解释下面的描述。应当理解的是,本发明不限于公开的示例性实施例,并且在不脱离由所附的权利要求所定义的本发明的范围的情况下,指定的特征还可以被适当地合并和/或修改。
图1是示出了根据本发明的音频源分离方法的优选实施例的流程图。
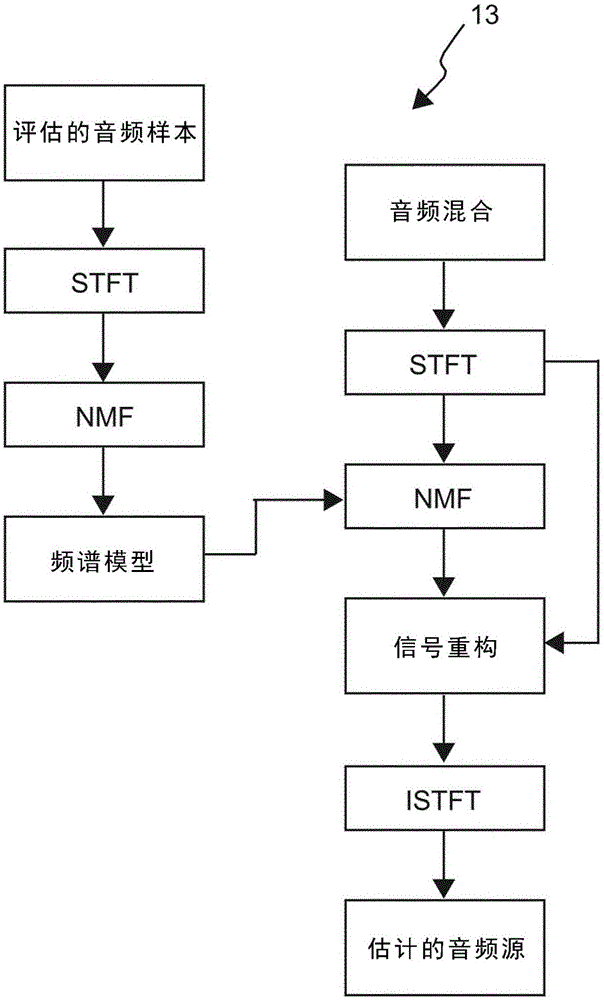
图2是示出了根据本发明的源分离阶段的一个实施例的流程图。
图3是示出了NMF分解的示例性图示。
图4是示出了根据本发明的方法的另一优选实施例的流程图。
图5是示出了在迭代过程期间权衡参数λ在NMF应用的优化函数公式中适应性地改变的一个实施例的图示。
图6是示出了用于本发明的NMF应用的组稀疏惩罚方法的效果的示例性图示。
图7是示出了用于本发明的NMF应用的结合组稀疏惩罚方法和行稀疏惩罚方法的效果的示例性图示。
图8是示出了根据本发明的实现音频源分离的方法的系统的示意图。
具体实施方式
参考图1,根据本发明的音频源分离的方法的一个优选实施例,包括:接收10音频混合和与音频混合相关联的至少一个文本查询;通过将文本查询和与辅助音频数据库相关联的语义信息进行匹配从辅助音频数据库中取回11至少一个音频样本;评估12从辅助音频数据库中取回的音频样本;以及使用该音频样本将音频混合分离13成多个音频源。音频源分离的方法可以在系统中和/或由处理器、服务器、或任意合适的设备执行。
文本查询可以由用户通过用户输入设备等(例如,打字设备或远程控制)来提供。用户听取音频混合,区分音频混合中的音频源,然后任意地提供文本查询。替代地,文本查询可以由执行语音转文字或类似的技术的设备直接提供。文本查询优选地描述了包括在音频混合中的音频源(例如,犬吠、鸟鸣等)和/或诸如语音内容之类的音频混合的文本内容。此外,其他指定的参数(例如,采样率、信道数、音频文件类型(wav、mp3等))也可以被包括在文本查询中以及与文本查询相结合,每个文本查询涉及单个或若干个音频源。当然,文本查询的长度、形式、和/或其他特性并不限于此,并且对于不同的需求是灵活变化的。
文本查询随后被用于从辅助数据库中音频取回11音频样本。辅助音频数据库是与一些语义信息相关联的数据库,该语义信息优选地标识了数据库的音频数据的内容。当然,语义信息可能具有适用于源分离的任意形式,例如,标签、文件名称、相应的网页等。优选地,辅助数据库是公共的并且容易访问的数据库(例如,公开的搜索引擎,如Google和Find sounds)。在该情况中,取回的音频样本可以被本地下载用于进一步处理和/或URL的列表可以由辅助数据库提供。替代地,辅助数据库还可以是针对音频源分离所预备的、本地的或任意类型的数据库。
由于存在至少与辅助数据库相关联的一些语义信息,所以通过将接收的文本查询与辅助数据库的语义信息相匹配来执行音频样本的取回。换句话说,音频样本的音频取回可以基于任意已知的基于文本的音频取回技术来执行。
评估12取回的音频样本可以基于本地服务器或辅助数据库的供应商的各种标准来执行。因此,随后可以使用每个取回的音频样本或只是它们的子集根据音频样本的评估结果来执行音频混合的分离13。可以通过包括不同算法的若干方法来实现音频样本的评估12。
在本发明的一个实施例中,取回11和评估12音频样本是由辅助数据库的供应商执行的。辅助数据库(例如,互联网搜索引擎)提供音频样本的列表,这些音频样本根据它们与所提供的本文查询的匹配被排序。音频样本的顺序可选择地从最佳匹配开始到最差匹配排列。任意地,某一数量的最佳匹配被用于后续的音频分离。例如,用户可以决定使用排在前三的音频样本并排除剩余的音频样本。此外,用户可以基于匹配度对每个样本分配不同的权重。
在本发明的一个实施例中,音频样本根据它们与所接收到的音频混合的相关性被排序。音频样本暂时与音频混合交叉关联,并且总结输出以获得单个音频样本的得分。例如,越高的得分可以表示音频样本与音频混合越匹配。类似地,音频样本的子集可以被选择用于后续的音频源分离。
在本发明的另一实施例中,音频样本根据音频特征相似度被排序,这可以提供音频样本和音频混合之间更为稳定的匹配。首先,音频特征(例如,频谱矩心、美尔倒谱系数(MFCC)、频谱传播、频谱带能量等)被分别从取回的音频样本和音频混合中提取。基于所提取的特征,音频样本和音频混合的特征向量被分别计算,并且与标准化交叉相关比较。在该情况中,音频样本和音频混合根据导出的特征向量而不是其原始信号被具体地比较和匹配。替代特征向量,表示音频样本和音频混合的词袋可以被提取,随后使用相关性、余弦相似性、或其他距离度量在音频样本和混合之间进行比较。
当然,其他替代的方法还可以被用来评估12从辅助数据库中取回的音频样本。此外,在评估12音频样本之后,可以通过将更多的权重给予排序较高的音频样本来可选地应用加权的非负矩阵分解[VIII,IX]。
图2示出了根据本发明的方法的源分离阶段的一个优选实施例。应该注意的是,在以下说明书中,为了简单起见,基于NMF模型的方法作为示例被描述。动态(on-the-fiy)源分离方法和系统也可以使用其他频谱模型,例如,概率性潜在分量分析(PLCA)[IV,V]或高斯混合模型(GMM)等。
首先,评估的音频样本经由短时傅里叶变换(STFT)被变换至时频表示,并且使用音频样本的STFT系数(称为频谱图、矩阵)的幅度或均方根幅度。该矩阵通过非负矩阵分解(NMF)算法被分解,以获得描述音频源的频谱特性的频谱模型矩阵(W)、以及时间激活矩阵(H)。频谱矩阵W被学习并且被用来指导音频混合的频谱图的分解,该音频混合的频谱图也是经由STFT转换获得的。通过对音频混合的频谱图应用NMF,频谱矩阵的部分或者所有的列由从音频示例中预先学习的音频所固定,音频源的评估的STFT系数通过众所周知的维纳过滤获得。最终,反STFT(ISTFT)被应用来获得源的时域估计,使得源可以被保存为例如波形文件。
本发明的方法的优选实施例实现NMF模型。传统的NMF的公式可以被定义为其中V是维度为F×N的非负矩阵。NMF的目的是将矩阵V近似为维度分别是F×K和K×N的两个简单非负矩阵W和H的乘积,当矩阵V近似由W·H重构时误差最小。可以使用各种成本函数来测量近似的误差。
应用NMF的公式,即,在本发明的实施例中,V表示音频混合的非负频谱图矩阵,该音频混合的非负频谱图矩阵是输入混合信号的时频表示。W和H分别表示频谱源的频谱原子和它们相应的激活。F表示全部的频点,N是时间帧的数量,并且K表示NMF分量的数量,NMF分量是描述音频源的频谱特性的频谱基础。换句话说,NMF可以通过将矩阵W的不同列(和矩阵H的相应行)与不同的声源相关联来分离单信道音频混合。图3示出了分解的示例。
因此目的是为了通过解决以下最优化的问题来使得近似误差最小化:
其中
其中,d(.|.)是散度,f(频率点指数)和n(时间帧指数)指示第f行第n列中的元素。可能的示例性散度包括Itakura-Saito散度[III]。
可选地,频谱基础矩阵W可以被保持固定或者可以被更新。如果取回的音频样本相对较好,则优选固定所学习的W用于进一步的音频源分离。另一方面,更新的W是灵活的,并且关于输入音频混合收敛到更好的近似。替代地,另一选择是首先在第一参数更新迭代期间固定矩阵W,随后在稍后的迭代中调整和更新W,这会更好地适应音频混合中音频源的频谱特性。
图4示出了根据本发明的音频源分离的方法的另一优选实施例。在该实施例中,评估12音频样本和分离12音频混合被共同执行。换句话说,评估并没有在音频源分离之前被执行,并且所有取回的音频样本被提供为对音频源分离阶段的输入。
通常,通过使用大型频谱图样字典对音频混合应用非负矩阵分解来共同执行评估音频样本和分离音频混合,频谱图样字典是通过结合从不同的源的音频示例学习的频谱图样矩阵所构建的。更具体地,作为两个源的示例,频谱图样的矩阵首先被构建为W=[W11,...,W1P,W21,...,W2Q],其中P和Q分别是针对源1和2的取回的示例数量,W1p(p=1,..,P)和W1q(q=1,..,Q)分别是由NMF分别从源1(由p索引)和源2(由q索引)的每个示例中学习的频谱图样的矩阵。时间激活的矩阵H是以同样的方式构建的,但是所有的条目首先是被随机初始化,然后经由优化过程被更新。在本发明的该实施例中,对矩阵H实施组稀疏的惩罚功能在全球优化开销中有所体现,使得允许仅选择从示例学习的最为合适的频谱图样来指导混合的NMF分解。该策略在图6中针对两个源的示例情况作出解释,针对每个源的两个示例:W11和W12是针对第一个源从两个示例中学习的频谱图样,类似地W21和W22是针对第二个源的。矩阵H由块H11,H12,H21,和H22组成,这些块是对应于频谱图样的激活。在优化后,H12和H22的条目是零,意味着每个源仅有一个取回的示例(由1索引)已经自动被选为指导分离过程。
为了在音频源分离中直接整合实现NMF模型的音频样本的评估,在NMF成本函数中引入对激活矩阵H和Ψ(H)的稀疏惩罚:
其中D(V|WH)被定义为如上,λ是对稀疏约束的贡献进行加权的权衡参数。
可选地并优选地,成本函数公式中的权衡参数λ可以是自适应的λ=f(i),其中f是函数,i是参数更新过程中的迭代次数。想法是首先具有高λ,以给予稀疏惩罚更多的权重,并因此选择基底音频样本,随后逐渐地降低λ以更好地符合第一项,即,散度D(V|WH),来得到更好的近似。该策略中线性适应权衡参数λ的示例在图5中示出。
在[II],描述了通过乘法更新来优化上述成本函数的迭代算法的更为详细的推导和解释。
通过选择不同的稀疏惩罚,实现了若干优化方案,这是以利用音频样本的频谱特性来指导分离过程的不同方式为基础的。如下文中给出了推荐的稀疏惩罚,可以导出相应参数估计的相应更新规则。
在一个实施例中,稀疏惩罚被定义为:
其中,G表示组的数量,与所使用的音频样本的数量相对应,Hg是与第g个源(第g组)相对应的激活矩阵H的部分。Ψ(x)可以由不同的函数定义,例如在[I,II]中所示。一个示例是Ψ(x)=log(x),该示例是为了简便起见在该实施例中使用。当然,也可以使用不同的函数Ψ。
该组稀疏方法允许有效地执行对从辅助数据库中取回的相关训练源样本的评估和选择,其中,一个组表示一个训练音频样本。作为[I]的改进,假设仅有一个源的好的模型被获得,则在该实施例中,所有音频源的更多模型通常被学习和实现。如图6所示,激活矩阵H被强制几乎不包括与较高排序的音频样本相对应的激活的块。
在一个实施例中,系数惩罚被定义为:
其中hg是激活矩阵的第g行。该行稀疏方法允许较高的灵活性,并且甚至从不同的音频样本中选择最好的频谱原子。
在一个实施例中,应用了成对的组稀疏方法,其中稀疏惩罚被定义为:
定义该组为训练音频样本对(每一个训练音频样本来自一个音频源),以避免这样的情况:稀疏惩罚保持来自仅一个源的仅一个激活组。该方法可以在每个音频源中保持至少一个激活组。
在另一实施例中,类似地,该方法基于成对的行稀疏,其中稀疏惩罚被定义为:
优选地,在又一实施例中,应用结合组稀疏和行稀疏惩罚的方法。针对该混合方法的成本函数被定义为:
其中,∝和β是确定每个惩罚的贡献的权重。该方法可以在图7中可见,其中,该算法可以在不同的源中选择好的频谱图样。
在本发明的另一实施例中,所考虑的频谱模式可以与空间模型[X]相结合,以便在多信道音频混合中执行动态源分离。对于多信道情况所考虑的框架的扩展是简单的,并且在[XI]中被描述。
图8示意性地示出了根据本发明的配置为执行音频源分离的方法的系统20的优选实施例。系统20包括接收单元21和处理器22,接收单元21被配置为接收10音频混合和与音频混合相关联的至少一个文本查询;处理器22被配置为通过将文本查询和与辅助音频数据库23相关联的语义信息进行匹配从辅助音频数据库23中取回11至少一个音频样本,从而评估12从辅助音频数据库23中取回的音频样本,以及使用该音频样本将音频混合分离13成多个音频源。
优选地,处理器22评估12音频样本和分离13音频混合是共同进行的。更优选地,处理器22通过对接收的音频混合应用NMF来分离13音频混合。
参考文献
[I]D.L.Sun and G.J.Mysore.“Universal Speech Models for Speaker Independent Single Channel Source Separation,(非特定人单信道源分离的通用语音模式)”IEEE International Conference on Acoustics,Speech,and Signal Processing(ICASSP),May 2013(2013年5月).
[II]A.Lefevre,F.Bach,and C.Fevotte.“Itakura-Saito Non-negative Matrix Factorization with Group Sparsity,(利用组稀疏的Itakura-Saito非负矩阵分解)”.ICASSP2011.
[III]C.Fevotte,N.Bertin,and J.Durrieu.“Non-negative Matrix Factorization with the Itakura-Saito divergence.With Application to Music Analysis,(利用Itakura-Saito散度的非负分解与对音乐分析的应用)”.Neural Computation Vol.21No.3.March 2009(2009年3月).
[IV]P.Smaragdis,B.Raj,and M.Shashanka,“Supervised and semi-supervised separation of sounds from single-channel mixtures,(声音与单信道混合的监督式分离和半监督式分离)”in Proc.Int.Conf.on Independent Component Analysis and Signal Separation(ICA),2007,pp.414–421.
[V]P.Smaragdis and G.J.Mysore,“Separation by humming:User-guided sound extraction from monophonic mixtures,(通过哼唱分离:用户指导的从单声道混合中的声音提取)”inProc.IEEE Workshop on Applications of Signal Processing toAudio and Acoustics(WASPAA),2009,pp.69–72.
[VI]L.L.Magoarou,A.Ozerov,and N.Q.K.Duong,“Text-informed audio source separation using nonnegative matrix partial co-factorization,(使用非负矩阵部分共同分解的文本通知音频源分离)”in Proc.Int.Workshop on Machine Learning for Signal Processing(MLSP),2013.
[VII]N.Q.K.Duong,A.Ozerov,L.Chevallier,and J.Sirot,“An interactive audio source separation framework based on nonnegative matrix factorization,(基于非负矩阵分解的交互式音频源分离框架)”Proc.ICASSP 2014
[VIII]N.Q.K.Duong,A.Ozerov,and L.Chevallier“Method of audio source separation and corresponding apparatus,(音频源分离的方法和相应的装置)”European Patent Application No.13305759.6
[IX]N.Q.K.Duong,A.Ozerov,and L.Chevallier,“Temporal annotation based audio sourceseparation using weighted nonnegative matrix factorization(使用加权的非负矩阵分解的基于暂时注释的音频源分离)”,Proc.IEEE ICCE-Berlin,submitted,2014.
[X]N.Q.K.Duong,E.Vincent and R.Gribonval,“Under-determined reverberant audio source separation using a full-rank spatial covariance model,(使用满秩空间协方差模型的欠定回响音频源分离)”IEEE Transactions on Audio,Speech and Language Processing,Special Issue on Processing Reverberant Speech,Vol.18,No.7,pp.1830-1840,Sep.2010
[XI]S Arberet,A.Ozerov,N.Q.K Duong,E.Vincent,R Gribonval,F.Bimbot and P Vandergheynst,“Nonnegative matrix factorization and spatial covariance model for under-determined reverberant audio source separation,(欠定的回响音频源分离的非负矩阵分解和空间协方差模型)”Proc.International Conference on Information Science,Signal Processing and their Applications(ISSPA.IEEE),2010。
- 还没有人留言评论。精彩留言会获得点赞!