用于经由非线性衰减/增益函数来消除音乐噪声的方法和装置与流程
本申请要求于2015年8月18日递交的第14/829,052号美国发明专利申请的优先权,并且还要求于2014年9月3日递交的第62/045,367号美国临时申请的权益。上述申请的全部公开内容通过引用并入本文。
技术领域
本公开涉及音频信号中的噪声的衰减和/或去除。
背景技术:
在语音增强系统中,数字信号处理器(DSP)接收包括模拟音频信号的样本的输入信号。模拟音频信号可以是语音信号。输入信号包括噪声,因而被称为具有有噪语音样本的“有噪语音”信号。DSP信号对有噪语音信号进行处理,以衰减噪声并输出与输入信号相比具有减少的噪声量的“净化的(cleaned)”语音信号。噪声的衰减是具有挑战性的问题,因为在定义语音和/或噪声的输入信号中不包括边信息(side information)。唯一可用的信息是所接收的有噪语音样本。
存在用于对有噪语音信号中的噪声进行衰减的传统方法。然而,这些方法引入和/或导致“音乐噪声”的输出。音乐噪声不一定是指音乐信号的噪声,而是指在窄频带内的“类似音乐”的有声噪声。音乐噪声被包括在作为执行这些传统方法的结果而输出的净化的语音信号中。音乐噪声可以被听者听到并且可能令听者不快。
作为示例,输入信号的样本可以被划分为重叠的帧,并且可以确定先验信噪比(SNR)ξ(k,l)和后验SNRγ(k,l),其中:ξ(k,l)是输入信号的先验SNR;γ(k,l)是输入信号的后验(或瞬时)SNR;l是用以标识帧中的特定一个帧的帧索引;并且k是标识输入信号的短时傅里叶变换(STFT)的频率范围的频段(frequency bin)(或范围)索引。先验SNRξ(k,l)是干净语音信号的功率电平(或语音的频率幅度)与噪声的功率电平(或噪声的频率幅度)的比。后验SNRγ(k,l)是观察到的有噪语音信号的平方幅度与噪声的功率电平的比。可以针对输入信号的每个频段计算先验SNRξ(k,l)和后验SNRγ(k,l)两者。先验SNRξ(k,l)可以使用等式1来确定,其中λX(k,l)是输入信号的STFT的语音幅度的先验估计方差,并且λN(k,l)是输入信号的STFT的估计的噪声先验方差。
后验SNRγ(k,l)可以使用等式2来确定,其中R(k,l)是输入信号的STFT的有噪语音的幅度。
对于每个k和l,增益G被计算为ξ(k,l)和γ(k,l)的函数。增益G被乘以R(k,l)以提供干净语音的幅度的估计每个增益值可以大于或等于0并且小于或等于1。增益G的值基于ξ(k,l)和γ(k,l)来计算,使得语音的频带(或频段)被保持并且噪声的频带(或频段)被衰减。执行干净语音的幅度的快速傅里叶逆变换(IFFT)以提供净化的语音的时域样本。净化的语音是指被净化的输入信号(即噪声已被衰减)的STFT的有噪语音部分。
例如,当ξ(k,l)高时,对应频率的语音的幅度高,并且存在很少的噪声(即噪声的幅度低)。对于这种情况,将增益G设置为接近1(或0dB)以保持语音的幅度。因此,干净语音的幅度被设置为近似等于R(k,l)。作为另一示例,当ξ(k,l)低时,对应频率的语音的幅度低,并且存在强噪声(即噪声的幅度高)。对于这种情况,增益G设置为接近0,以使噪声衰减。因此,干净语音的幅度被设置为接近0。
先验信噪比(SNR)ξ(k,l)可以使用等式3来估计,其中α是在0和1之间的常数,并且P(k,l)是算符,其可以由等式4表示。
图1示出了有噪语音信号10和干净语音信号12。有噪语音信号10包括语音(或语音样本)和噪声。干净语音信号12是没有噪声的语音。有噪语音信号10的示例性帧在方框14内。由方框14指定的帧具有很少的语音(即语音的幅度接近零)和大量噪声(即,对于此帧,与语音相比,噪声的幅度高和/或SNR低)。
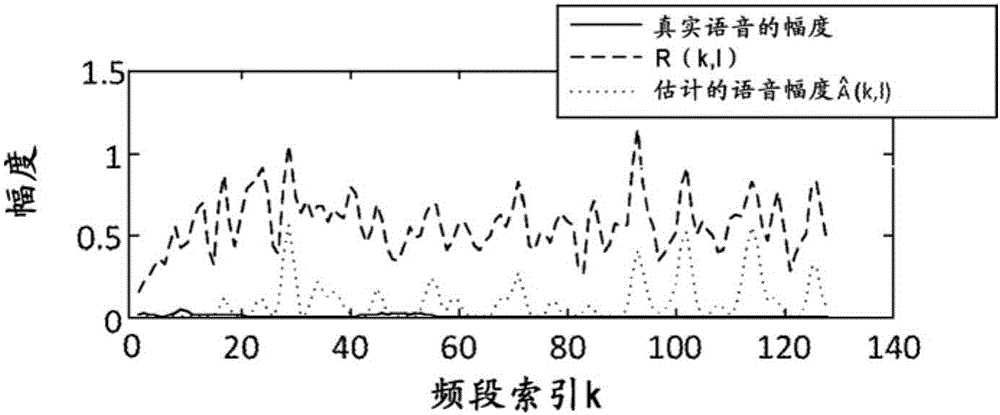
图2A和2B示出了说明如何产生音乐噪声的曲线图。图2A示出了真实语音的幅度、有噪语音的幅度R(k,l)、和估计的语音幅度的示例。图2B的值对应于图2A的值。图2B示出了等式4中的变量的值的示例。
如图2B所示,R(k,l)2和λN(k,l)均是随机“之字形”并且处于大约相同的平均水平(即具有相似的幅度)。在某些频段,R(k,l)2<λN(k,l),因而根据等式4,P(k,l)的值为零。在其他频段中,R(k,l)2>λN(k,l),因而根据等式4,P(k,l)的值是非零值。由于R(k,l)2和λN(k,l)在某些频段处是随机的之字形,所以对应P(k,l)的值是非零的,但是在与具有非零P(k,l)值的频段相邻的频段处,P(k,l)的值为零。因此,P(k,l)在某些频段处示出孤立的峰,并且根据等式3,对于相同频段,先验SNRξ(k,l)也具有孤立的峰。取决于常数α,先验SNRξ(k,l)的孤立峰的幅度可以小于P(k,l)的幅度。
低的先验SNRξ(k,l)的值可以导致远小于1(例如,接近0并且大于或等于0)的增益。高的先验SNRξ(k,l)的值导致接近1且小于或等于1的增益。因此,估计的语音幅度是增益乘以有噪语音的幅度R(k,l),其在P(k,l)具有孤立的峰的频段处具有孤立的峰。这在图2A中示出。估计的语音幅度的孤立的峰是音乐噪声。
对于上述由方框14指定的帧,R(k,l)2和λN(k,l)处于类似的平均水平。这是因为由方框14指定的帧的内容大部分是噪声。因此,R(k,l)2是瞬时噪声电平。λN(k,l)是估计的平滑噪声电平或如上所述的估计的噪声先验方差。R(k,l)2具有与λN(k,l)相似的平均电平的这一事实指示λN(k,l)被正确地估计。
技术实现要素:
提供了一种系统,包括第一增益模块、算符模块、先验模块、后验模块和第二增益模块。第一增益模块被配置为:应用非线性函数以基于(i)第一语音信号的幅度和(ii)估计的噪声先验方差来生成增益信号,噪声被包括在第一语音信号中。算符模块被配置为:基于(i)增益信号和(ii)估计的噪声先验方差来生成算符。先验模块被配置为基于该算符来确定先验信噪比。后验模块被配置为基于(i)第一语音信号的幅度和(ii)估计的噪声先验方差来确定后验信噪比。第二增益模块被配置为:基于(i)先验信噪比和(ii)后验信噪比来确定增益值,以及基于(i)第一语音信号的幅度和(ii)增益值来生成与语音信号的幅度的估计相对应的第二语音信号,其中第二语音信号基本上没有音乐噪声。
在其它特征中,提供了一种方法,并且包括:应用非线性函数以基于(i)第一语音信号的幅度和(ii)估计的噪声先验方差来生成增益信号,噪声被包括在第一语音信号中;基于(i)增益信号和(ii)估计的噪声先验方差来生成算符;基于该算符来确定先验信噪比;以及基于(i)所述第一语音信号的幅度和(ii)估计的噪声先验方差来确定后验信噪比。该方法还包括:基于(i)先验信噪比和(ii)后验信噪比来确定增益值;以及基于(i)所述第一语音信号的幅度和(ii)增益值,生成与第一语音信号的幅度的估计相对应的第二语音信号,其中第二语音信号基本上没有音乐噪音。
根据详细的描述、权利要求和附图,本公开的其它适用领域将变得明显。详细的描述和具体示例仅旨在用于说明的目的,并且不旨在限制本公开的范围。
附图说明
图1是有噪语音信号和干净语音信号的曲线图。
图2A是与图1的有噪语音信号和干净语音信号相对应的真实语音的幅度、有噪语音的幅度R(k,l)和估计的语音幅度的曲线图。
图2B是用于估计图1的语音幅度的R(k,l)2、估计的噪声先验方差λN(k,l)和算符P(k,l)的曲线图。
图3是有噪语音信号和干净语音信号的另一曲线图。
图4A是与图3的有噪语音信号和干净语音信号相对应的真实语音的幅度、有噪语音的幅度R(k,l)和估计的语音幅度的曲线图。
图4B是用于估计图3的语音幅度的R(k,l)2、估计的噪声先验方差λN(k,l)和算符P(k,l)的曲线图。
图5是根据本公开的一个方面的包含具有语音估计模块的网络设备的音频网络的功能性框图。
图6是根据本公开的一个方面的包含语音估计模块的控制模块的功能性框图。
图7示出了根据本公开的一个方面的语音估计方法。
图8是根据本公开的一个方面的非线性衰减/增益函数的曲线图。
图9A是根据本公开的一个方面的使用用于有噪语音信号的非线性衰减/增益函数而提供的真实语音的幅度、有噪语音的幅度R(k,l)和估计的语音幅度的曲线图。
图9B是在应用图9A的非线性衰减/增益函数之前和之后的估计的噪声先验方差λN(k,l)、算符P(k,l)、和R(k,l)2的曲线图。
图10A是根据本公开的一个方面的使用用于另一有噪语音信号的非线性衰减/增益函数而提供的真实语音的幅度、有噪语音的幅度R(k,l)和估计的语音幅度的曲线图。
图10B是在应用图10A的非线性衰减/增益函数之前和之后的估计的噪声先验方差λN(k,l)、算符P(k,l)、和R(k,l)2的曲线图。
在附图中,附图标记可以重新用于标识类似和/或完全相同的元件。
具体实施方式
参考图2A和2B,可以考虑估计的噪声先验方差λN(k,l)的缩放,以消除在比较R(k,l)2和λN(k,l)时产生的孤立的峰。去除峰导致音乐噪声的消除。例如,可以修改以上给出的等式4以提供等式5,其中s是大于1的值。
s的值越大,P(k,l)中孤立的峰越少。然而,只要P(k,l)中存在孤立的峰,就会产生音乐噪声。在具有较少的孤立的峰的情况下,音乐噪声被更窄地带化,并且因此可能对听者而言更加不快。为了完全消除孤立的峰值,s必须增加到大的值,使得对于所有的k值,均有R(k,l)2<s·λN(k,l)。这需要大的s值,因为R(k,l)是瞬时的(没有被平滑)。现在参考图1的示例性有噪语音信号12,为了完全消除P(k,l)的孤立的峰,s将必须大到5。大的s值导致对应语音信号中的失真。
作为另一个例子,图3示出了有噪语音信号30和干净语音信号32的曲线图。有噪语音信号30包括语音(或语音样本)和噪声。干净语音信号32是没有噪声的语音。有噪语音信号30的示例性帧在方框34内。由于语音的平均幅度远大于噪声的平均幅度,所以由方框34指定的帧包含有效语音。
图4A示出了真实语音的幅度、有噪语音(或有噪语音信号)的幅度R(k,l)和估计的语音幅度的示例。图4B示出在s等于5的情况下等式5中变量的值的示例。图4B的值对应于图4A的值。从图4B可以看出,R(k,l)2的第一峰40和第四峰42以及真实语音的第一峰43和第四峰45在幅度上小于s·λN(k,l)的峰或与s·λN(k,l)的峰相当。因此,使用等式5基本上忽略了第一峰40和第四峰42。如图4A所示,与峰40、42、43、45相对应的估计的语音幅度的点被显著减小,其中第一峰(由点44指示)被消除,并且第四峰(由点46指定)的幅度减小。与真实语音信号的第四峰45相比,第四峰46的幅度减小。因此,使用上述等式5的降噪处理不消除音乐噪声和/或导致语音失真。使用等式5的降噪处理不消除音乐噪声(例如,少量孤立的峰保留在P(k,l)中)或者在语音信号中产生失真。以下公开了具有最小语音失真的消除音乐噪声的示例。
图5示出了包含网络设备52、54、56的音频网络50。网络设备52、54、56直接地或经由网络60(例如,互联网)彼此通信。通信可以是无线的或经由有线的。诸如语音信号的音频信号可以在网络设备52、54、56之间传输。网络设备52示出为具有音频系统58,音频系统58具有多个模块和设备。网络设备54、56可以包括与网络设备52类似的模块和/或设备。网络设备54、56中的每一个可以是例如移动设备、蜂窝电话、计算机、平板电脑、电器设备(appliance)、服务器、外围设备和/或其他网络设备。
网络设备52可以包括:具有语音估计模块72的控制模块70;物理层(PHY)模块74、介质访问控制(MAC)模块76、麦克风78、扬声器80和存储器82。语音估计模块72接收有噪语音信号,对有噪语音信号中的噪声进行衰减,并且消除和/或防止具有最小语音失真或没有语音失真的音乐噪声的生成。有噪语音信号可以由网络设备52经由网络60从网络设备54接收,或者由网络设备52直接从网络设备56接收。有噪语音信号可以经由天线84在PHY模块74处接收并且经由MAC模块76转发到控制模块70。作为替选,有噪语音信号可以基于由麦克风78检测到的模拟音频信号来生成。有噪语音信号可以由麦克风78生成,并且从麦克风78提供给控制模块70。
语音估计模块72基于有噪语音信号来提供估计的语音幅度信号(有时称为估计的干净语音信号)。语音估计模块72可以对估计的语音幅度信号执行快速傅里叶逆变换(IFFT)和数模(D/A)转换,以提供输出信号。输出信号可以被提供给扬声器80用于播出,或者可以经由模块74、76和天线84被传送回网络设备54、56之一。
音频(或有噪语音)信号可以经由麦克风78在网络设备52处发起和/或从存储器82访问并且传递通过语音估计模块72。由语音估计模块72生成的与音频信号相对应的所得信号可以在扬声器80上播出和/或经由模块74、76和天线84发送到网络设备54、56。
现在还参考图6,图6示出了根据一个实施例的控制模块70。控制模块70可以包括模数(A/D)转换器100、语音估计模块72和D/A转换器102。A/D转换器100从诸如以下的音频源接收模拟有噪语音信号104:经由模块74、76和天线84的网络设备54、56之一;麦克风78;存储器82;和/或其他音频源。A/D转换器100将模拟有噪语音信号转换为数字有噪语音信号。语音估计模块72在衰减数字有噪语音信号中的噪声以提供估计的语音幅度信号的同时,从数字有噪语音信号中消除音乐噪声和/或防止音乐噪声的生成。语音估计模块72可以直接从音频源104接收数字有噪语音信号。D/A转换器102可以在播出和/或到网络设备54、56之一的传输之前,将从语音估计模块72接收的估计的语音幅度信号转换为模拟信号。
语音估计模块72可以包括快速傅里叶变换(FFT)模块110、幅度模块112、噪声模块114、衰减/增益模块116、平方模块117、除法器模块118、先验SNR模块120、,后验(或瞬时)SNR模块122、第二增益模块124和IFFT模块126。模块116、117、118可以包括在单个非线性功能模块中和/或实现为单个非线性功能模块。模块117和118可以包括在单个算符模块中和/或实现为单个算符模块。参考图7的方法描述模块110、112、114、116、117、118、120、122、124和126的操作。
本文公开的系统可以使用多种方法来操作,示例性方法在图7中示出。在图7中,示出了语音估计方法。尽管主要关于图5-6和图8-10的实施方式描述了以下任务,但是可以容易地对任务进行修改以应用于本公开的其他实施方式。任务可以迭代地执行。
该方法可以在150处开始。在152,FFT模块110可以对接收和/或访问的音频(或有噪语音)信号y(t)执行快速傅立叶变换,以提供数字有噪语音信号Yk,其中t是时间,并且k是频段索引。在154处,幅度模块112可以确定数字有噪语音信号Yk的幅度,并且生成有噪语音幅度信号R(k,l)。有噪语音幅度信号R(k,l)可以被生成为复数数字有噪语音信号Yk的幅度。在156,噪声模块114基于数字有噪语音信号Yk来确定估计的噪声先验方差λN(k,l)。
任务158和160可以根据等式6来执行,其中g[]是具有输入R(k,l)和λN(k,l)的非线性衰减/增益函数。
在158,衰减/增益(或第一函数)模块116基于有噪语音幅度信号R(k,l)和估计的噪声先验方差λN(k,l)来生成衰减/增益信号ag(k,l)。衰减/增益信号ag(k,l)是非线性衰减/增益函数g[]的结果,并且可以根据以下规则生成:
1.如果R(k,l)2>>λN(k,l),则非线性衰减/增益函数g[]的输出或ag(k,l)等于R(k,l)。符号“>>”意指基本上大于并且可以指代大于λN(k,l)的预定量。这由图8的曲线图的第一部分I表示。第一部分I可以是线性的。图8示出了表示非线性衰减/增益函数的示例性曲线图。该曲线图包括三个部分I、II、III,并且是非线性衰减/增益函数g[]的输出相对于估计的噪声先验方差λN(k,l)。
2.如果R(k,l)2基本上不大于λN(k,l),则非线性衰减/增益函数g[]的输出或ag(k,l)可以是R(k,l)的衰减版本,或者增益的量可以减少到0。衰减量或增益的量可以是预定的、固定的和/或变量。衰减量可以随着R(k,l)减小而增加,如图8的曲线图的部分II和III所示。部分III的R(k,l)的衰减的量大于部分II的R(k,l)的衰减的量。部分II可以是非线性的,并且随着减少的R(k,l)从减少量的增益转变为增加量的衰减。部分III可以是线性的并且随着减小的R(k,l)而提供增加量的衰减。点159和161是部分I、II和III之间的点,在此处图8的总曲线的斜率从部分I、II、III中的第一部分的第一斜率改变为部分I、II、III中的第二部分的第二斜率。尽管图8所示的非线性衰减/增益函数具有某些线性和/或非线性的三个部分,但是非线性衰减/增益函数可以具有任意数量的具有相应线性和/或非线性的部分。部分I、II、III具有相应的衰减和/或增益的量。
3.由衰减/增益模块116执行的从R(k,l)到输出ag(k,l)的映射是连续且单调的。由于R(k,l)大于或等于0,输出ag(k,l)在R(k,l)是0时为0,并且为非负数。
在160,平方(或第二函数)模块117对输出ag(k,l)求平方以提供ag(k,l)2。在162,除法器(或第三函数)模块118将ag(k,l)2除以λN(k,l),以提供等式6的P(k,l)。
通过使用上述规则和等式6,通过避免产生孤立的峰来消除音乐噪声。注意,等式6不包括等式4和/或等式5中的减法。由于语音能量大于噪声能量,如果R(k,l)2>>λN(k,l),则对应的信号能量很可能是语音能量而不是噪声能量。为此,信号不被修改。换句话说,输出ag(k,l)等于R(k,l)。否则,信号能量为语音的可能性降低,并且信号能量为噪声的可能性随着减小的R(k,l)而增加。为此,生成减小的增益量和/或衰减的P(k,l),导致降低的噪声量。当R(k,l)2与λN(k,l)差不多相同(例如,在其预定量内)或小于λN(k,l)时,则R(k,l)很可能是噪声并且被严重衰减。这减小了噪声并且还有助于防止孤立的峰的形成。
孤立的峰是由于与例如等式4相关联的不连续性而形成。这是因为在一个特定频段处,当R(k,l)2<λN(k,l)时等式4导致P(k,l)等于0,而在下一频段处,当R(k+1,l)2>λN(k+1,l)时等式4为提供非零的、大的值。在所提出的算法中,由于与等式6相关联的上述规则的特征3,所以P(k,l)>0。此外,由于上述规则的特征2,P(k+1,l)可以是严重衰减的值。由于这些原因,不会产生将导致音乐噪声的孤立的峰。
存在可用于g[]的若干可能的非线性衰减/增益函数。图8和上述规则提供了一个示例。作为另一个例子,如果R(k,l)大于第一预定量(例如3)与λN(k,l)的乘积,则ag(k,l)被设置为等于R(k,l)。否则,如果R(k,l)小于或等于第一预定量与λN(k,l)的乘积和/或则ag(k,l)被设置为等于R(k,l)的衰减版本,诸如第二预定量(例如0.1)与R(k,l)的乘积。
在164处,先验SNR模块(或第一SNR模块)120基于P(k,l)和λN(k,l)和先前幅度来确定先验SNRξ(k,l)。增益模块124可以为所接收到的和/或访问得到的语音信号的先前帧生成先前幅度在166处,后验SNR模块(或第二SNR模块)122可以基于R(k,l)和λN(k,l)来确定后验SNRγ(k,l)。
在168,增益(或第二增益)模块124可以根据ξ(k,l)和/或γ(k,l)生成估计的语音幅度信号作为示例,等式7到等式10可以用于生成估计的语音幅度信号其中v是由等式7定义的参数并且G是应用于R(k,l)的增益。
估计的语音幅度信号可以从增益模块124提供给IFFT模块126。增益G的值可以大于或等于0并且小于或等于1。增益G的值被设置为衰减噪声,并且保持语音的幅度。在170,IFFT模块126执行估计的语音幅度信号的IFFT以提供输出信号,该输出信号可以被提供给D/A转换器102。该方法可以在172处结束。
上述任务意在是说明性的示例;任务可以根据应用来顺序地、同步地、同时地、连续地、在重叠时间段期间或以不同的顺序而执行。此外,取决于实现和/或事件的顺序,任何任务可以不被执行或跳过。例如,可以跳过任务152和/或任务170。
通过应用上述非线性衰减/增益函数以提供算符P(k,l),先验SNRξ(k,l)的随后确定和估计的干净语音信号的生成不引入音乐噪声。例如,通过应用图8的非线性衰减/增益函数,对于图1的有噪语音信号10的由方框14指定的帧,提供图9A的估计的语音幅度在被“净化”之前(即,在应用非线性衰减/增益函数并且增益模块124将增益函数G应用于有噪语音的幅度R(k,l)之前),由方框14指定的帧具有大部分噪声。图9A示出了以下项的曲线图:真实语音的幅度;有噪语音的幅度R(k,l);以及使用非线性衰减/增益函数针对有噪语音信号提供的估计的语音幅度图9B示出了以下项的曲线图:在应用非线性衰减/增益函数之前和之后的R(k,l)2;估计的噪声先验方差λN(k,l);和用于估计图9A的语音幅度的算符P(k,l)。
通过应用图8的非线性衰减/增益函数,对于图3的有噪语音信号30的由方框34指定的帧,提供图10A的估计的语音幅度在被净化之前,由方框34指定的帧具有大量的语音。图10A示出了以下项的曲线图:真实语音的幅度;有噪语音的幅度R(k,l);和使用非线性衰减/增益函数提供的估计的语音幅度图10B示出了以下项的曲线图:在应用非线性衰减/增益函数之前和之后的R(k,l)2;估计的噪声先验方差λN(k,l);和用于估计图10A的语音幅度的算符P(k,l)。
从图9A中可以看出,没有尖锐的孤立的峰并且没有音乐噪声。尽管该实施例示出没有音乐噪声,但是在本公开的其他实施例中,音乐噪声基本上被消除,但是没有完全被消除。对于音乐噪声基本上被消除的实施例,基本上消除是指估计的语音幅度不具有尖锐的孤立的峰,并且音乐噪声的幅度小于真实语音和/或有噪语音信号的幅度的预定分数。在一个实施例中,预定分数为1/5、1/10或1/100。音乐噪声可以在预定分数的预定范围(例如,0.1)内。取代音乐噪声,存在具有低幅度的宽带噪声。宽带噪声可能听不到和/或不会令听者不快。从图10A可以看出,与图4A的估计的语音幅度的第一峰44和第四峰46不同,图10A的估计的语音幅度的第一峰200和第四峰202没有被衰减或最小程度地被衰减,并且未被扭曲。因此,与对应的真实语音和/或有噪语音信号R(k,l)的峰相比,语音的峰被保留。
本公开中描述的无线通信可以完全或部分地符合IEEE标准802.11-2012、IEEE标准802.16-2009、IEEE标准802.20-2008和/或蓝牙核心规范v4.0来进行。在各种实现中,可以通过蓝牙核心规范附录2、3或4中的一个或多个来修改蓝牙核心规范v4.0。在各种实现中,IEEE 802.11-2012可以由草案IEEE标准802.11ac、草案IEEE标准802.11ad、和/或草案IEEE标准802.11ah来补充。
上述描述本质上仅是说明性的,并且决不旨在限制本公开、其应用或使用。本公开的广泛教导可以以各种形式实现。因此,尽管本公开包括特定示例,但是本公开的真实范围不应当如此被限制,因为在研究附图、说明书和所附权利要求时,其他修改将变得明显。应当理解,在不改变本公开的原理的情况下,方法中的一个或多个步骤可以以不同的顺序(或同时地)执行。此外,尽管每个实施例在上面被描述为具有某些特征,但是关于本公开的任一实施例描述的那些特征中的任何一个或多个可以在其他实施例中任意一个的特征中实现和/或与其他实施例中任意一个的特征的组合来实现,即使该组合没有被明确地描述。换句话说,所描述的实施例不是相互排斥的,并且一个或多个实施例彼此的置换保持在本公开的范围内。
元件之间(例如,在模块、电路元件、半导体层等之间)的空间关系和功能关系使用包括“连接”、“接合”、“耦合”、“邻近”、“靠近”、“在...之上”、“在...上面”、“在...下面”和“设置”的各种术语来描述。当在上述公开中描述了第一元件和第二元件之间的关系时,除非明确描述为“直接的”,该关系可以是其中在第一元件和第二元件之间不存在其它中间元件的直接关系,但是也可以是其中在第一元件和第二元件之间存在(在空间上或功能上)一个或多个中间元件的间接关系。如本文所使用的短语A、B和C中的至少一个应当被解释为意味着使用非排他性逻辑OR的逻辑(A OR B OR C),并且不应被解释为表示“A中的至少一个、B中的至少一个、和C中的至少一个”。
在本申请中,包括以下定义,术语“模块”或术语“控制器”可以用术语“电路”替换。术语“模块”可以指代作为以下各项的一部分或包括以下各项:专用集成电路(ASIC);数字、模拟或混合的模拟/数字离散电路;数字、模拟或混合的模拟/数字集成电路;组合逻辑电路;现场可编程门阵列(FPGA);执行代码的处理器电路(共享的、专用的或组);存储由处理器电路执行的代码的存储器电路(共享的、专用的或组)、提供所描述的功能的其它合适的硬件组件;或上述的一些或全部的组合,诸如在片上系统中。
模块可以包括一个或多个接口电路。在一些示例中,接口电路可以包括连接到局域网(LAN)、互联网、广域网(WAN)或其组合的有线或无线接口。本公开的任何给定模块的功能可以分布在经由接口电路连接的多个模块中。例如,多个模块可以允许负载均衡。在另一示例中,服务器(也称为远程或云)模块可以代表客户端模块来完成一些功能。
如上所使用的术语代码可以包括软件、固件和/或微代码,并且可以指程序、例程、函数、类、数据结构和/或对象。术语共享处理器电路涵盖执行来自多个模块中的一些或全部代码的单个处理器电路。术语组处理器电路涵盖处理器电路与附加处理器电路组合来执行来自一个或多个模块的一些或所有代码。对多个处理器电路的引用涵盖分立管芯上的多个处理器电路、单个管芯上的多个处理器电路、单个处理器电路的多个核、单个处理器电路的多个线程或以上的组合。术语共享存储器电路涵盖存储来自多个模块的一些或所有代码的单个存储器电路。术语组存储器电路涵盖与附加存储器组合来存储来自一个或多个模块中的一些或所有代码的存储器电路。
术语存储器电路是术语计算机可读介质的子集。如本文所使用的术语计算机可读介质不涵盖通过介质(诸如在载波上)传播的暂态的电信号或电磁信号;术语计算机可读介质因此可以被认为是有形的和非暂态的。非暂态有形计算机可读介质的非限制性示例是非易失性存储器电路(诸如闪存电路、可擦除可编程只读存储器电路、或掩模只读存储器电路)、易失性存储器电路(诸如静态随机存取存储器电路或动态随机存取存储器电路)、磁存储介质(诸如模拟或数字磁带或硬盘驱动器)、和光存储介质(诸如CD、DVD或蓝光光盘)。
本申请中所描述的装置和方法可以部分地或完全地由通过配置通用计算机来执行在计算机程序中实施的一个或多个特定功能而创建的专用计算机来实现。上述功能块、流程图组件和其他元件用作软件规范,其可以通过熟练的技术人员或程序员的例行工作转换成计算机程序。
计算机程序包括存储在至少一个非瞬时性有形计算机可读介质上的处理器可执行指令。计算机程序还可以包括或依赖于所存储的数据。计算机程序可以涵盖与专用计算机的硬件交互的基本输入/输出系统(BIOS)、与专用计算机的特定设备交互的设备驱动程序、一个或多个操作系统、用户应用程序、后台服务、后台应用程序等
计算机程序可以包括:(i)要解析的描述性文本,诸如HTML(超文本标记语言)或XML(可扩展标记语言),(ii)汇编代码,(iii)由编译器从源代码生成的目标代码,(iv)用于由解释器执行的源代码,(v)用于由即时编译器编译和执行的源代码等。仅作为示例,源代码可以使用来自包括C、C++、C#、Objective C、Haskell、Go、SQL、R、Lisp、Fortran、Perl、Pascal、Curl、OCaml、HTML5、Ada、ASP(动态服务器页面)、PHP、Scala、Eiffel、Smalltalk、Erlang、Ruby、VisualLua和的语言的语法来编写。
在权利要求中记载的元件都不旨在是35U.S.C.§112(f)的含义内的部件加功能(means-plus-function)元件,除非元件使用短语“用于......的部件”明确地记载或在使用短语“操作用于”或“用于...的步骤”的方法权利要求的情况下。
- 还没有人留言评论。精彩留言会获得点赞!