融合韵律信息的汉语方言辨识方法与流程
本申请属于语音信号处理领域,特别涉及一种融合韵律信息的汉语方言辨识方法,它在多语言环境下的语音识别、口语翻译、信息检索和辅助人工咨询等方面具有广阔的应用前景。
背景技术:
作为语言辨识的一个重要分支,汉语方言辨识的研究还处于起步阶段,最早在中国台湾受到重视,随后新加坡也开展了此项研究,国内在这方面的研究比较少。2002年,我国台湾学者tsaiw.h.等提出了直接利用未标注语音的声学特征和韵律特征,建立高斯混合二元模型进行方言辨识的方法,取得了一定的成功。新加坡学者limb.p.等则提出了利用局部和全局音位配列特征的汉语方言辨识方法,对三种方言和一种外来语的辨识实验中取得了很好的识别效果。国内的顾明亮利用高斯混合模型与语言模型相结合,提出了一种基于音位配列特征的汉语方言辨识方法,在不用标注语音样本的前提下,系统取得了很好的效果。
分析以上方法不难看出,目前汉语方言辨识中区别特征的选择主要集中在声学特征、音位配列特征和韵律特征,而且在应用方式上主要集中在其中的一种或两种。另一方面,在韵律特征和其他特征的融合方式上,仅仅局限在简单的加权研究,这种方法在特征子空间增大了空间的维数,在训练同样多参数的情况下,特征效果并不会有太大改进,有时反而会引起性能下降。
技术实现要素:
本申请所要解决的问题是克服传统方言辨识中仅仅使用单一特征和简单加权的信息融合缺陷,提出了融合韵律信息的汉语辨识方法。为实现上述目的,本发明提供如下技术方案:
本申请实施例公开了一种融合韵律信息的汉语方言辨识方法,包括:
s1、输入汉语方言信号进行语音信号提取,提取信号包括声学特征和韵律特征,所述声学特征包括sdc特征,所述韵律特征包括基频特征、能量包络特征和时长特征;
s2、将提取的不同质的特征经过模型建模,转化成具有统一度量标准的特征矢量,然后进行组合构成一个统一矢量送分类器决策。
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述sdc特征的计算由4个整型参数决定,即(n,d,p,k),其中n是每帧中倒谱特征的维数,d是计算差分倒谱的差分时间,p是k个倒谱块之间的转移时间,k是构成一个sdc特征的倒谱块的个数,在t帧第j个sdc特征的计算公式是δcj,t=cj,(t+d)-cj,(t-d):cj,t在t帧的第j个mffcc特征参数,所以在t帧时sdc的特征可表示为:
每帧sdc特征向量的维数为n×k维。
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述基频特征中,基音频率包含在语音信号的浊音段中,浊音信号的每一帧可以写成:
其中,n=0,…,n-1,n是每一帧语音的样本点数,i是拟合的谐波数αi,ωi,
其中,τ=0,…,n-1,定义相邻两帧信号的自相关协方差为该帧语音的基频流特征:
其中,μt(τ)=e{rt(τ)},d∈(n/2,n/2]是特征矢量的下标,令:
其中,δi=ωt,i-ωt+1,i,δ={δi,i=1,…,i},通过求导得到,
假设分帧后的语音信号为
优选的,在上述的融合韵律信息的汉语方言辨识方法中,基音特征流的具体计算方法包括:
(i)利用傅里叶变换(dft)计算各帧的功率谱密度:
pt(k)=|dft(xt(n))|2
其中,k=0,1,...k-1.
(ii)对所得的功率谱密度进行平滑处理:
pt(k)=pt(k)·w(k)
其中,窗函数为:w(k)=1+cos(2πk/k)
(iii)归一化平滑后的功率谱密度:
(iv)计算归一化能量谱的逆傅里叶变换(idft):
rt(k)=dft-1(pt(k))
(v)则基频流特征为:
其中c是归一化常数,特征矢量下标的取值范围是:-d≤d≤d。
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述能量包络特征中,语音信号各帧的能量参数记为:e={e1,e2,…,en},其中,ei为:
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述时长特征中,对能量特征矢量作差分,然后检查差分能量中变号的次数以及两次变号间隔,将变号次数及平均变号间隔作为时长特征。
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述步骤s2中,采用模型融合的方法进行特征融合,计算每种特征在方言的高斯混合模型和语言模型下的概率分数。
优选的,在上述的融合韵律信息的汉语方言辨识方法中,在高斯混合模型下,设语音信号经特征提取后为
其中,m为高斯混合元数目,也是符号总数,
优选的,在上述的融合韵律信息的汉语方言辨识方法中,在语言模型下,首先采用插值法对数据进行平滑处理,然后建立各种语言的二元插值语言模型,其算法如下:
设经过第k个gmm模型下得到的语音符号串为:
其中,
优选的,在上述的融合韵律信息的汉语方言辨识方法中,所述步骤s2中,分类器设计中采用的是支持矢量机,最优分类函数的算法如下:
给定样本训练集x={(x1,y1),(x2,y2),…,(xn,yn)},x∈rd,y∈y={+1,-1},
求解最优超平面可以转化为以下最优化问题,
式中,xi表示样本特征矢量,参数w和b决定超平面位置的两个参数,使分类间隔最大,该优化问题可以转化为其对偶问题求解,
解得最优分类函数为:
对于两类非线性可分问题,可以通过引入核函数将其转化为高维空间的线性可分问题,通过引入松弛变量ξi转化成下列优化问题:
其中,c为常数,表示对错分样本的惩罚大小,
其中,αi为与每个样本对应的lagrange乘子,k(xi,xj)为满足mercer条件的核函数,最终解得的最优分类函数是:
与现有技术相比,本发明的优点在于:本发明融合韵律信息的模型方法增加了汉语方言间的区别性,大大提升了方言辨识的正确率。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
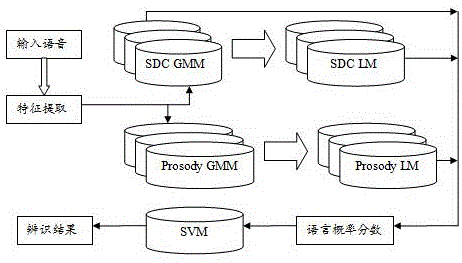
图1所示为本发明具体实施例中汉语方言辨识方法的原理示意图;
图2所示为本发明具体实施例中sdc特征的参数和计算的原理示意图;
图3所示为本发明具体实施例中两类线性可分情况下svm分类示意图。
具体实施方式
汉语是一种声调语言,相同的汉字由于不同的声调而具有不同的含义,此外方言间在语调的类型、重音模型以及时长特征上具有很大的不同,也就是在韵律特征上具有很大的不同。本发明方法充分利用这一特点,在提取声学特征基础上,提取了方言的韵律特征,包括基频特征、能量包络特征和时长特征。
为了解决多信息融合问题,本发明将不同质的特征先经过模型建模,转化成具有统一度量标准的特征矢量,然后进行组合构成一个统一矢量送分类器决策,即提出了模型融合的辨识方法。
实验结果表明融合韵律信息的模型方法增加了汉语方言间的区别性,大大提升了方言辨识的正确率。
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行详细的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
结合图1所示,融合韵律信息的汉语方言辨识方法主要包括预处理,特征提取,特征融合以及分类器设计四个部分。
1、预处理
主要包括有声与无声判别、预加重、分段和加窗运算等。
2、特征提取
(1)声学特征
声学特征通过声学参数建模来反映每种语言中的音素特征,也就是各种语音谱特征参数,如线性预测参数lpcc、美尔倒谱系数mfcc和差分倒谱系数sdc,其中mfcc特征是语音识别中应用最多的特征,而sdc特征是在mfcc上提出的一种新的反映长时相关声学信息的特征,sdc特征也称为移位的差分谱特征,其实质是由若干块跨多帧语音的差分倒谱组成,从而使一个特征矢量内包含多帧语音的长时相关声学信息.它的计算由4个整型参数决定,即(n,d,p,k)其中n是每帧中倒谱特征的维数,d是计算差分倒谱的差分时间,p是k个倒谱块之间的转移时间,k是构成一个sdc特征的倒谱块的个数,sdc特征的参数和计算如图2所示。
在t帧第j个sdc特征的计算公式是:δcj,t=cj,(t+d)-cj,(t-d)cj,t在t帧的第j个mffcc特征参数,所以在t帧时sdc的特征可表示为:
由上式可以得出,每帧sdc特征向量的维数为n×k维。
(2)韵律特征
语言学上,语言的韵律特征主要表现为:节律、轻重、重音和声律等超语音现象。这些语言现象表现在物理上即为:语言的音调、时长和强度等声学特征。其中,基频特征是最重要的言语辨识特征,其次,时长和能量包络也是非常重要的特征。
i基频特征
语音信号处理理论指出,基音频率是反映声门激励周期性变化的一个重要参数,它包含在语音信号的浊音段中,由于其准周期性,该浊音信号可以用一组谐波信号的叠加来描述。即浊音信号的每一帧可以写成:
其中,n=0,…,n-1。n是每一帧语音的样本点数,i是拟合的谐波数,αi,ωi,
其中,τ=0,…,n-1。定义相邻两帧信号的自相关协方差为该帧语音的基频流特征:
其中,μt(τ)=e{rt(τ)},d∈(n/2,n/2]是特征矢量的下标。令:
其中,δi=ωt,i-ωt+1,i,δ={δi,i=1,…,i}。通过对上式求导不难得到,
假如分帧后的语音信号为
(i)利用傅里叶变换(dft)计算各帧的功率谱密度:
pt(k)=|dft(xt(n))|2k=0,1,…k-1.
(ii)对所得的功率谱密度进行平滑处理:
pt(k)=pt(k)·w(k)
其中,窗函数为:w(k)=1+cos(2πk/k)
(iii)归一化平滑后的功率谱密度:
(iv)计算归一化能量谱的逆傅里叶变换(idft):
rt(k)=dft-1(pt(k))
(v)则基频流特征为:
其中c是归一化常数,特征矢量下标的取值范围是:-d≤d≤d,由此可以构成一个(2d+1)维的特征矢量。
ii能量包络特征
语音信号各帧的能量参数记为:e={e1,e2,…,en},其中,ei可用公式(11)得到:
iii时长特征
为了得到时长参数,我们对能量特征矢量作差分(由前后两帧能量相减所得),然后检查差分能量中变号的次数以及两次变号间隔,将变号次数及平均变号间隔作为时长特征。
3、特征融合
特征融合采用的是模型融合的方法。在提取方言的以上三种特征后,计算每种特征在方言的高斯混合模型和语言模型下的概率分数。
设语音信号经预处理和特征提取后为
其中,m为高斯混合元数目,也是符号总数。
语言模型是用来描述自然语言内在规律的数学模型,通常采用的是基于统计的语言模型,也就是概率模型。其实质是借助于统计语言模型的概率参数,估计出语言中每个词出现的可能性以及词之间的搭配概率。由于语料库的大小究竟有限,有可能造成严重的数据稀疏和训练不足问题。为了解决这些问题,实验中首先采用插值法对数据进行平滑处理,然后建立各种语言的二元插值语言模型,其算法如下:
设经过第k个gmm模型下得到的语音符号串为:
其中,
4、分类器设计
分类器设计中采用的是支持矢量机(svm),支持矢量机是20世纪90年代中期在统计学习理论基础上发展起来的分类方法,对解决小样本、非线性和高维模式识别问题中显示了许多独特的优势,在模式识别、数据挖掘和非线性控制等领域得到了成功的应用。
对于两类线性可分问题,它要求划分两类的决策超平面不仅能将两类样本无错误地分开,而且要使两个类别的分类间隔达到最大。图3是两类线性可分情况下svm分类示意图。
给定样本训练集x={(x1,y1),(x2,y2),…,(xn,yn)},x∈rd,y∈y={+1,-1},
求解最优超平面可以转化为以下最优化问题。
式中,xi表示样本特征矢量,参数w和b决定超平面位置的两个参数。使分类间隔最大,该优化问题可以转化为其对偶问题求解。
解得最优分类函数为:
对于两类非线性可分问题,可以通过引入核函数将其转化为高维空间的线性可分问题,通过引入松弛变量ξi转化成下列优化问题:
其中,c为常数,表示对错分样本的惩罚大小。
其中,αi为与每个样本对应的lagrange乘子,k(xi,xj)为满足mercer条件的核函数,常用的三种核函数为:多项式核函数,径向基核函数和sigmoid核函数。显然,这是一个不等式约束下的二次函数寻优问题。可以证明,它存在唯一解,且解中将只有一部分αi不为零,对应的样本就是支撑矢量。最终解得的最优分类函数是:
此外,在多类分类问题。svm通常采用“一对其他”和“一对一”的解决办法。“一对其他”的方法中,对于类问题需要构造n个两类分类器,训练时,第i个svm分类器用第i类中的训练样本作为正的训练样本,而将其他的样本作为负的训练样本。测试时,取所有两类分类器输出最大的那一类。“一对一”的方法中,训练时,先构造n(n-1)/2个两类svm分类器,测试时,对上述分类器进行投票,得票最多的类别为测试样本所属的类别。本方法采用的是“一对其他”的方法。
最后,还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
- 还没有人留言评论。精彩留言会获得点赞!