基于扬声器引入的语音信号失真特性的回放攻检测方法与流程
本发明属于数字媒体处理领域,涉及一种回放攻击检测方法,特别涉及一种判别语音是否为回放攻击的语音内容安全的方法。
背景技术:
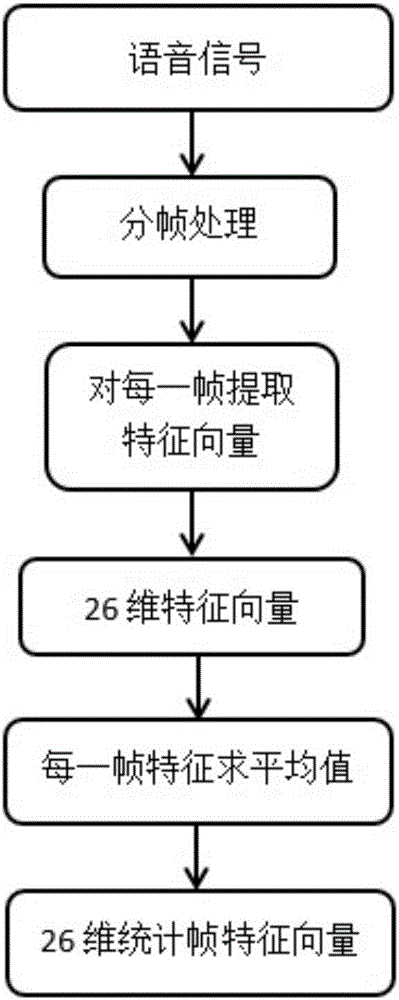
:生物特征作为生物体固有属性这一优势导致生物识别技术由之出现,说话人识别隶属于生物识别,是根据使用者的语音样本来实现身份认证。由于语音相对其他生物特征,具有拾音设备简单、随时随地可用、数据量小等优势,声纹验证技术从提出后已经经过了60多年的发展并且取得了巨大的进步,得到了广泛的应用。但是,目前针对声纹的身份认证系统却面临着各种伪装攻击,包括录音回放、语音合成、语音转换和语音模仿四种方式,其中回放攻击是指攻击者使用录音设备录制合法用户进入认证系统时的语音,然后在系统的拾音器端通过扬声器回放,达到伪装用户进入系统的目的。由于现有录音设备的低廉性和便携性,使得这一攻击操作简便,实现容易,录音回放攻击已成为最广泛威胁性最大的伪装攻击手段。现有的主流的说话人识别平台对于回放攻击的错误接受率极高,这表明录音回放攻击对于声纹认证平台的安全有极大的威胁性,由此可见如何实现录音回放攻击检测成为基于声纹的身份认证系统中急需解决的一个重要问题。自录音回放攻击出现以来,国内外仅有少数研究团队对此进行了研究,其主要技术成果集中在2011年以前,近年来发展缓慢。并且现有研究成果对于语音采样频率,系统存储空间,语音采集环境等条件有严格要求和限制,也无法达到准确率高,实时性强的识别效果,所以均不能广泛适用于现有声纹识别平台。语音信号频谱图可以准确直观的反映出语音信号被修改前后的变化和差异,而回放攻击的过程相比于原始语音引入了麦克风采集,数字压缩和扬声器播放三个环节,每一个环节都可能会引起语音信号的改变。所以根据三个环节中语音信号频谱图的变化进行分析,提出基于语音信号频谱特性的回放攻击检测算法,可以设计实现出具有良好普适性、实时性和较高准确性的回放攻击检测算法。技术实现要素:本发明针对现有声纹识别系统无法抵抗回放攻击的安全漏洞,提供了一种基于扬声器引入的语音信号失真特性的回放攻检测方法。本发明所采用的技术方案是:一种基于扬声器引入的语音信号失真特性的回放攻检测方法,其特征在于,包括以下步骤:步骤1:对待检测语音进行预处理,保留其中的浊音帧;步骤2:针对预处理后语音信号中的每一个浊音帧进行特征提取,得到基于语音信号线性失真和非线性失真特性的特征向量;步骤3:所有的浊音帧的特征向量求平均值,形成统计特征向量,获得待测语音的特征模型;步骤4:提取训练语音样本的特征向量,获得训练语音特征模型,并利用该训练语音特征模型来训练SVM模型,获得语音模型库;步骤5:将待测语音的特征模型与已训练好的语音模型库进行SVM模式匹配,输出判决结果。作为优选,步骤1所述对待检测语音进行预处理,是使用汉明窗对语音信号进行分帧加窗处理,帧长为70ms,保留其中的浊音帧。作为优选,步骤2所述针对预处理后语音信号中的每一个浊音帧进行特征提取,是提取基于语音信号线性失真和非线性失真特性的26维特征向量。作为优选,所述提取基于语音信号线性失真特征向量,由低频比、低频方差、低频差分方差、低频拟合和全局低频比五种特征,共计10维向量组成;所述低频比其中X(f)为对每一帧的快速傅里叶变换;所述低频方差其中所述低频差分方差其中所述低频拟合是利用6维拟合特征对于0~500Hz的FFT采样点进行拟合,拟合公式为其中x为0~500Hz的FFT采样点,ai表示拟合的系数;所述全局低频比作为优选,所述提取基于语音信号非线性失真特征向量,包括总谐波失真、削波比和音色向量三种特征,共计16维特征向量;所述总谐波失真其中X(f)为每一帧的快速傅氏变换,f1为基音频率,fi为i倍基音频率;所述削波比其中x为时域谱,len为时域谱长度;所述音色向量作为优选,步骤3所述统计特征向量,是26维统计特征向量。作为优选,步骤4所述训练语音样本,来自若干设备和若干位录制者,包括回放语音和原始语音。作为优选,步骤4中在提取训练语音样本特征向量以后,利用LIBSVM对训练语音样本集中的特征数据库进行二分类训练,所述特征数据库由训练语音样本特征向量组成。本发明的有益效果是:本发明可以集成于现有的声纹识别平台,实现对回放语音实时有效的检测,为当前信息时代的司法取证、电子商务、金融系统等领域提供安全有效的身份认证技术支持。附图说明图1是本发明实施例的算法总体流程图;图2是本发明实施例的特征提取流程图;图3是本发明实施例的回放攻击引入的差异对比图;图4是本发明实施例的加速度频率响应曲线图;图5是本发明实施例的描述低频衰减失真的频谱图;图6是本发明实施例的描述高频谐波失真的频谱图。具体实施方式为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。本发明实施例中涉及的相关术语解释如下:1)回放攻击:利用录音设备录制说话人的声音,然后对说话人识别系统播放这段录音,从而使得说话人识别系统判断其为说话人。2)信号频谱:信号各分量的幅度或相位关于频率的函数。3)线性失真:由电路的线性电抗组件对不同频率的响应不同而引起的幅度或者相位的失真,输出信号中不会有新的频率分量4)非线性失真:输出信号中产生新的谐波成分,表现为输出信号与输入信号不成线性关系。5)基音:在复音中,频率最低的声音叫做基音,乐音的音调是由基音的频率决定的。本发明是基于语音信号频谱特性的回放攻击检测算法,以扬声器对语音信号造成的线性失真和非线性失真特性为技术原理,提取相应特征向量,并采用SVM进行分类判决,可实现对回放语音实时有效的检测。请见图1,是本发明的算法流程图,参照该图所示,对一段语音的回放攻击检测过程有如下步骤:步骤1:针对待检测语音,首先使用汉明窗对信号进行分帧加窗处理,帧长为70ms,保留其中的浊音帧。步骤2:针对预处理后语音信号中的每一个浊音帧进行特征提取,得到基于语音信号线性失真和非线性失真特性的26维特征向量。如图3所示,回放攻击的过程相比于原始语音引入了麦克风采集,数字压缩和扬声器播放三个环节,其中扬声器对语音信号的影响最为显着,且具有多个性能评价指标,扬声器放音的过程对于语音信号的影响可以分为线性失真和非线性失真两种。线性失真是由于电路中存在线性组件,其阻抗随频率的不同而不同,从而导致系统对不同频率的信号分量的放大倍数与延迟时间不同。线性失真会使不同频率信号分量的大小及相对时间关系发生变化,但不会产生输入信号所没有的新的频率成分。如图5所示,上面为原始语音,下面为回放语音,线性失真在扬声器上主要体现为低频部分的衰减现象。如图4所示,由于声辐射和加速度成正比,因此把扬声器纸盆的固有频率设计得低于工作频率,扬声器工作在质量工作区,当Qm=1时频率响应较为平坦。在这种工作状态下,扬声器会出现明显低频衰减。非线性失真是由于电路中的非线性组件或进入非线性区域而引起的。非线性失真的主要特征是产生了输入信号所没有的新的频率的成分。可以分为谐波失真和瞬态互调失真。谐波失真指原有频率的各种倍频的有害干扰。如图6所示为一段原始语音信号和相应的回放语音信号,由于放大器不够理想,输出的信号除了包含放大的输入成分之外,还新添了一些原信号的整数倍的频率成分(谐波),致使输出波形走样。由于晶体管工作特性不稳定,易受温度等因素影响而产生失真,因此会采用大深度的负反馈。为了减小由深度负反馈所引起的高频振荡,晶体管放大器一般要在前置推动级晶体管的基极和集电极之间加入一个小电容,使高频段的相位稍为滞后,称为滞后价或称分补价。当输入信号含有速度很高的瞬态脉冲时,电容来不及充电,线路是处于没有负反馈状态。由于输入讯号没有和负回输讯号相减,造成讯号过强,这些过强讯号会使放大线路瞬时过载,结果使输出讯号出现削波现象。请见图2,本实施例基于线性失真原理和非线性失真原理特征提取过程如下:基于线性失真现象提出的特征均是在500Hz范围下进行处理,从而达到更好的区分效果。这里我们提出了低频比、低频方差,低频差分方差,低频拟合和全局低频比五种特征,共计10维向量来描述线性失真中的低频衰减特性。①低频比(LowSpectralRatio)回放语音信号在250~350Hz的范围内谱峰分布低于原始语音,而在接近500Hz的范围时又高于原始语音,所以用250~350Hz的特征参数比上400~500Hz特征参数可以最明显的区分两者。公式1所示,其中X(f)为对每一帧的快速傅里叶变换。②低频方差(LowSpectralVariance)低频方差用于描述信号在低频区域的波动情况。首先对500Hz以内的FFT采样点进行统计,在帧长为70ms的情况下,16kHz的采样点总共有1120个,在0~500Hz以内的采样点共计35个;③低频差分方差(LowSpectralDifferenceVariance)一阶差分常用来描述数据的变化程度。这里,通过一阶差分的方差值,来更准确的描述低频部分的数据波动程度。④低频曲线拟合(LowSpectralCurveFit)利用6维拟合特征对于0~500Hz的FFT采样点进行拟合。其中x为0~500Hz的FFT采样点,ai表示拟合的系数;⑤全局低频比(GlobalLowSpectralRatio)此特征的提出是基于现有的频带特征检测算法和扬声器对语音信号的衰减作用,通过对原有算法的改进使其具有广泛适用性。低频比例特征的提取验证了语音信号总体在低频部分衰减的特点。其中X(f)为每一帧的快速傅氏变换,本实验所使用的音频信号采样频率均为16kHz,衰减部分主要发生在500Hz以下。对于非线性失真现象,提取总谐波失真,削波比和音色向量三种特征,共计16维特征向量,用于描述非线性失真中的高频谐波失真和瞬态互调失真现象。①总谐波失真(TotalHarmonicDistortion)此特征的提出是基于扬声器对于语音高频部分的谐波失真现象。各次谐波的方均根值与基波方均根值的比例称为该次谐波的谐波含量。所有谐波的方均根值的方和根与基波方均根值的比例称为总谐波失真其中X(f)为每一帧的快速傅氏变换。f1为基音频率,fi为i倍基音频率。②削波比(ClippingRatio)将时域谱绝对值的平均值和最大值作比,用来量化由瞬态互调失真带来的削波现象。其中x为时域谱,len为时域谱长度。③音色向量(TimbreVector)回放信号与原始信号在谐波上差异明显。音色主要由各个谐波(泛音)的相对大小决定。音色向量可以描述谐波的相对大小关系。步骤3:分别对每一个浊音帧提取完特征向量后,将所有的浊音帧的特征向量求平均值,形成26维统计特征向量。步骤4:提取训练语音样本的特征向量,获得训练语音特征模型,并利用该训练语音特征模型来训练SVM模型,获得语音模型库;步骤4.1:输入训练样本集,训练样本集中的训练音频来自多种设备和多位录制者,并包括回放语音和原始语音;如图2所示,对训练样本集中的所有语音样本提取26维统计特征向量。步骤4.2:语音的判定问题实际上是二分类问题,所以使用的模型为SVM;在提取出特征向量以后,利用LIBSVM对训练样本集中的特征数据库进行二分类训练。步骤5:将待测语音样本的特征模型与已训练好的语音模型库进行SVM模式匹配,进一步输出判决结果。步骤5.1:提取待测语音特征向量;步骤5.2:将待测样本特征向量与已有的语音模型库进行模式匹配,得到判决标准,进一步输出判决结果。将待测样本特征向量与已有的语音模型库进行模式匹配,训练过的SVM模型具有区分原始语音和回放语音的分类边界,可以实现对待测样本进行二分类,进一步输出判决结果,判决为回放/原始。为了验证本算法的有效性,设置三个实验来进行测试;实验1:不同年龄段以及不同性别的用户在频率、语调等声音特点方面差异较大,所以对不同用户人群进行分类测试,分别为18岁以下、18—40岁和40岁以上三个年龄段,每个年龄段都分别有男性录制者和女性录制者;不同用户人群分类测试结果请见下表1;表1不同用户人群分类测试结果测试分组Age1(<18)Age2(18-40)Age3(>40)平均测试指标ARARARAR男100%99.2054%98.2%99.14%女97.7941%98.3%98.8372%98.32%平均98.08%98.69%98.525%98.68%实验2:不同扬声器的物理结构不同,其扬声器的频响曲线相对不同,针对扬声器的测试可以验证不同主流设备的识别情况,测试设备分别为华为,iPhone,三星,魅族,谷歌nexus;不同扬声器分类测试结果请见下表2;表2不同扬声器分类测试结果设备类型样本数量FARARiPhone5s1728.55%91.45%华为1712.34%97.66%Nexus1550.65%99.35%魅族1751.15%98.85%三星2543.15%96.85%平均185.43.17%96.83%实验3:文献[1]中的算法是目前提出的较为优秀的回放攻击检测算法,所以将本发明的方法与文献[1]的算法进行对比测试,以验证本算法对于识别率的提升,算法对比测试结果请见下表3;表3算法对比测试实验结果表明,本发明提供的算法对于不同用户人群和不同扬声器设备均具有良好的检测通用性,并且算法的平均识别正确率率高达98%以上,相较于现有算法平均82%的识别率有了显着的提升。文献[1]Villalba,Jesús,andEduardoLleida."Detectingreplayattacksfromfar-fieldrecordingsonspeakerverificationsystems."EuropeanWorkshoponBiometricsandIdentityManagement.SpringerBerlinHeidelberg,2011.应当理解的是,本说明书未详细阐述的部分均属于现有技术。应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1