一种声调评估方法与流程
本发明涉及声调识别
技术领域:
,特别涉及一种声调评估方法。
背景技术:
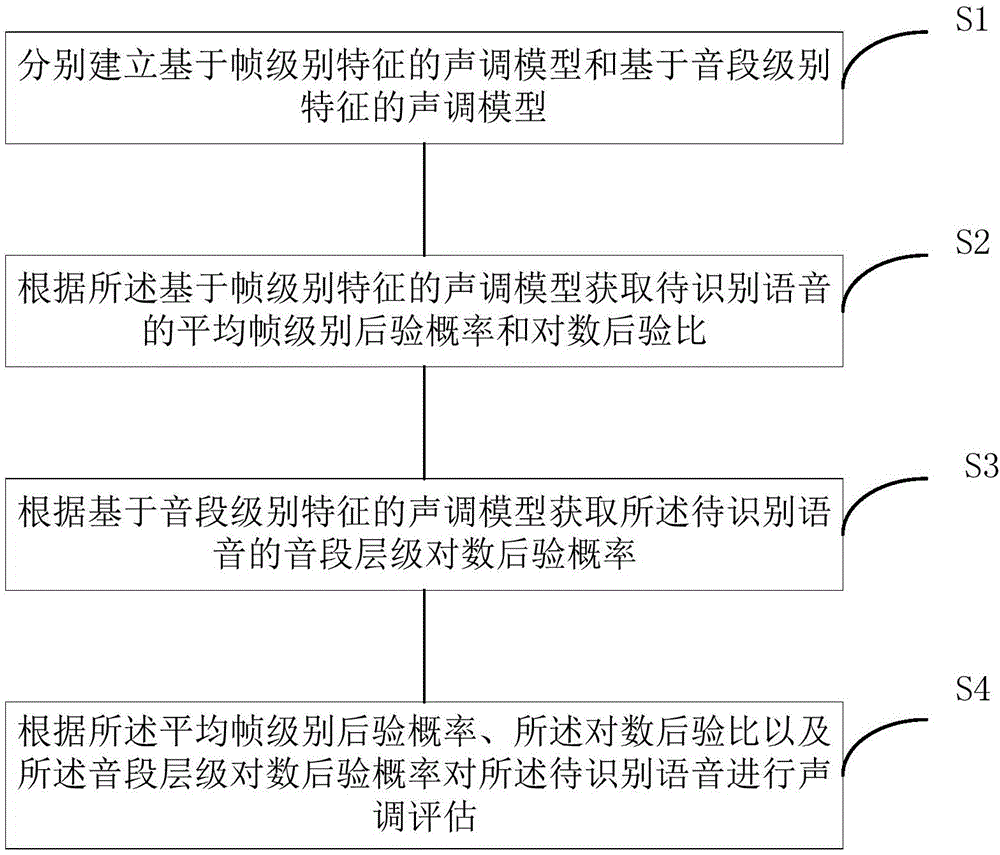
:随着第二外语的大力推广和普及,加之课堂教学模式(时间地点固定,人员数量多)和教师主观测评(个体差异性大,稳定性差)存在的缺陷,急需一种更加便利和有效的手段,可以对外语学习者的发音质量进行及时有效的评估和反馈。CAPT(Computer-AidedPronunciationTraining,计算机辅助发音教学)为以上问题的解决提供了可能性,其以人机交互智能技术为媒介,帮助或引导学生进行发音练习的教学方法。在CAPT系统中,比较重要的一块为“发音质量评价”,也就是计算机自动评估学习者发音的质量好坏,适合用于对发音者的整体语言发音能力进行评判,类似于教学中的考试环节。在过去的几年里,CAPT系统中的“发音质量评价”研究取得了显著进展,主要集中在“音段”层级上的评估和检测。以汉语为例,由于其是“声调”语言,“声调”起到相当重要的词义区分角色以及韵律相关作用,如外国留学生的“洋腔洋调”现象,不仅与“音段”的发音偏误有关,而且与“声调”的异常也有很大关系。因此,对于一个汉语CAPT系统,“声调评测”也是非常关键的。而“声调识别”又是“声调评测”的基础。对于标准语音,如果声调识别系统的“调型”识别率很高,那么建立在该声调识别技术基础上的声调评测系统就能准确地分辨出声调的正确与否,从而比较可靠地评价出声调发音的水平。在“孤立音节”中,标准的声调发音基本符合其原有声调模式,声调评测可以根据是否符合声调的标准模式进行评价。相对于“孤立音节”的声调识别,在“连续语流”中,“声调识别”是非常困难的,原因是在连续语流中声调存在很多复杂变化,具体如下:第一,在语音学中有一种sandi规则:由于声调间连接,声调曲线会发生改变。比如,相邻的上声+上声序列可能会变成阳平+上声;第二,音节的声调曲线会受到它相邻音节基频曲线的影响,这种现象被称作“协同发音”影响,“协同发音”主要是由于人的发音器官的局限性,也就是说,发音器官不能够充分的活动以保持基频F0曲线为它们的标准模式;第三,调阶与句子语调结构保持一致,如在陈述句中,基频F0曲线一般呈现逐渐下降的趋势。除此之外,“调形”、“调阶”还会受到其他因素的影响,比如交叉话者,焦点变化,话题变换等等。这些复杂的变化都为在连续语流中声调识别带来了困难,使得音节声调之间存在着不容忽视的连续性,而且普遍存在的变调现象又具有多样性,进一步导致了自然语流的声调识别难度的增加,进而也影响了声调评测系统的准确性。技术实现要素:本发明旨在至少在一定程度上解决上述技术中的技术问题之一。为此,本发明的一个目的在于提出一种声调评估方法,能够提高声调评估的鲁棒性。为达到上述目的,本发明提出了一种声调评估方法,包括:分别建立FLTM(FrameLevelToneModel,基于帧级别特征的声调模型)和SLTM(SegmentLevelToneModel,基于音段级别特征的声调模型);根据所述基于帧级别特征的声调模型获取待识别语音的平均帧级别后验概率和对数后验比;根据基于音段级别特征的声调模型获取所述待识别语音的音段层级对数后验概率;根据所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率对所述待识别语音进行声调评估。根据本发明提出的声调识别方法,把韵律特征、频谱特征和发音特征融合在一起而建立基于帧级别特征的声调模型,与此同时,训练一个以音段特征为输入特征的基于音段级别特征的声调模型,根据上述两个声调模型,提取与声调相关的帧层级和音段层级的多层级置信度量而进行声调评测,实现了上述两个置信度量的互补性,提高了声调评估的鲁棒性。具体地,所述根据所述基于帧级别特征的声调模型获取待识别语音的AFLP(AverageFrameLevelProbability,平均帧级别后验概率)和LPR(Logposteriorratio,对数后验比),包括:提取所述待识别语音的MFCC(MelFrequencyCepstrumCoefficient,梅尔频率倒谱系数)特征以及基频F0特征;基于提取的所述待识别语音的MFCC特征,利用DNN(DeepNeuralNetworks,深度神经网络)分类器获取所述待识别语音的发音特征;基于所述待识别语音的所述MFCC特征、所述基频F0特征以及所述发音特征,利用DNN-HMM(DeepNeuralNetworks-HiddenMarkovModel,深度神经网络-隐马尔可夫模型)获取所述待识别语音的所述平均帧级别后验概率和所述对数后验比。根据本发明的一个实施例,所述平均帧级别后验概率由以下公式估计:AFLP(p)=logp(p|o;ts,te)≈1te-ts+1Σt=tstelogp(p|ot)]]>p(p|ot)=Σs∈pp(s|ot)]]>其中,s是帧t对应的HMM状态标签,通过将所述待识别语音的音素p进行强制对齐得到,{s|s∈p}表示所有属于所述音素p的HMM状态集合,Ot是帧t输入观测向量参数,ts或te分别表示所述音素p的开始和结束的帧索引号。所述对数后验比由以下公式得到:LPR(pj|pi)=logp(pj|o;ts,te)-logp(pi|o;ts,te)根据本发明的一个实施例,所述利用DNN分类器获取所述待识别语音的发音特征包括:所述DNN分类器通过预先定义的发音属性类别列表提取所述待识别语音的发音特征。根据本发明的一个实施例,所述根据基于音段级别特征的声调模型获取所述待识别语音的SLP(SegmentLogProbability,音段层级对数后验概率)包括:分别提取所述待识别语音的当前音节参数和相邻音节参数,其中,音节参数包括音节的基频F0曲线拟合参数、音节时长、音节基频均值和音节能量均值;基于所述待识别语音的所述当前音节参数和所述相邻音节参数,利用DNN模型获取所述待识别语音的所述音段层级对数后验概率。根据本发明的一个实施例,所述音段层级对数后验概率通过以下公式得到:SLP(tk)=logp(tk|o)其中,tk表示所述待识别语音的声调标签,k={1,2,3,4},o表示相应的输入参数。根据本发明的一个实施例,根据所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率对所述待识别语音进行声调评估包括:基于所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率、通过SVM(SupportVectorMachine,支持向量机)建立声调评估模型;通过所述声调评估模型对所述待识别语音进行声调评估。根据本发明的一个实施例,所述通过所述声调评估模型对所述待识别语音进行声调评估包括:将所述待识别语音的所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率作为输入量,基于所述声调评估模型获取针对所述待识别语音的检测结果;根据获取的检测结果分别计算FAR(FalseAcceptanceRate,错误接受率)、FRR(FalseRejectionRate,错误拒绝率)和DA(DiagnosticAccurateRate,诊断正确率),公式如下:FAR=FAFA+TR]]>FRR=FRFR+TA]]>DA=TA+TRTA+TR+FA+FR]]>其中,TA表示正确接受的检测结果,TR表示正确拒绝的检测结果,FA表示错误接受的检测结果,FR表示错误拒绝的检测结果。附图说明图1为根据本发明一个实施例的声调评估方法的流程图;图2为根据本发明一个实施例的基于帧级别特征的声调模型;图3为根据本发明一个实施例的声调评估模型;图4为根据本发明一个实施例的根据不同置信度量的不同声调的测试结果。具体实施方式下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。下面结合附图来描述本发明实施例的声调评估方法。图1为根据本发明一个实施例的声调评估方法的流程图。如图1所示,一种声调评估方法包括以下步骤:Step1:分别建立基于帧级别特征的声调模型和基于音段级别特征的声调模型。1.1基于帧级别特征的声调模型为获得优化的FLTM,首先需要探究音质参数与基频之间的关系,并以此为基础,设计和提取待识别语音的发音特征以用来进行声调识别。以汉语为例,其音节可以分为两个部分:声母和韵母。音系学研究表明根据发音位置、发音方法等,可以进一步对声韵母进行详细分类。比如,对于声母,首先根据声带是否振动,可以将其划分为浊声母与清声母两大类;其次,鉴于清声母中塞擦音、塞音、擦音对所在音节的基频具有不同的影响,可以进一步将其划分为不同的子类,具体分类详情如表1。表1:发音属性类别列表然而,由于人工对语音信号标注AF(Acousticfeature,发音特征)是相当费时费力的,因此设计一种智能的AF分类器是必要的。优选的,一种合理产生AF分类器训练语料的方式可以通过基于音素的训练文本转换到发音特征文本,具体可以通过预先定义的音素和发音特征之间的转换表来实现。我们计划使用发音类别的后验概率作为AF。为了根据待识别语音得到AF,本发明计划使用一个“深度神经网络分类器”进行AF的提取。如图2所示,在本实施例中,AF“深度神经网络分类器”使用待识别语音的MFCC参数作为输入特征。如附图2所示,训练好AF“深度神经网络分类器”后,产生的AF与从所述待识别语音提取的F0和MFCC拼接到一起,作为DNN-HMM模型的输入量。此处需要注意,在上述拼接操作之前,F0+MFCC特征需经过一系列特征变换,如其转换为LDA+MLLT+FMLLR。1.2基于音段级别特征的声调模型对于每一个音节,F0曲线拟合参数、音节时长、音节能量均值和基频均值均作为输入量以用来构建SLTM。F0使用ESPS工具中的get_f0命令(参数设置:wind_dur=0.01,min_f0=60,max_f0=650)得到,并且在话者层级上做了0均值1方差的规整。进一步的,使用f(x)=ax2+bx+c二阶线性回归来拟合F0曲线,参数{a,b,c}用来进行声调识别。考虑到“协同发音”对声调模式的影响,对于待识别语音的当前音节,与之相邻的音节的相应特征也需要被用来进行声调建模。上述所述待识别语音的当前音节参数和相邻音节参数均被用来作为基于DNN的SLTM的输入特征,如表2所示。表2SLTM使用的输入特征1拟合F0曲线的参数3维2当前音节的时长1维3当前音节基频的均值1维4当前音节能量的均值1维5相邻音节上述特征12维Step2:根据所述基于帧级别特征的声调模型获取待识别语音的AFLP和LPR。2.1平均帧级别后验概率在训练基于DNN-HMM的FLTM时,多层的神经网络被训练用来提供HMM状态(也可以称作“senone”)的后验概率估计。给定观测参数向量,我们可以直接使用“senone”的后验概率,而不用转换成HMM的转移似然值。本文中声调音素的后验概率由以下公式估计:AFLP(p)=logp(p|o;ts,te)≈1te-ts+1Σt=tstelogp(p|ot)---(0)]]>p(p|ot)=Σs∈pp(s|ot)---(2)]]>其中,p(s|ot)是DNN模型最后的softmax层的输出,s是帧t对应的“senone”标签,通过给定文本中的音素p进行强制对齐得到的,{s|s∈p}表示所有属于音素p的“senone”集合,比如属于triphone(HMM模型)的所有状态。Ot是帧t输入观测向量参数,ts或te分别表示声调音素p的开始或结束的帧的索引号。2.2对数后验比(LPR)音素pj和pi的对数似然比定义如下:LPR(pj|pi)=logp(pj|o;ts,te)-logp(pi|o;ts,te)(3)其中,p(p|o)是通过公式(1)计算得到的。Step3:根据基于音段级别特征的声调模型获取所述待识别语音的音段层级对数后验概率。首先通过强制对齐得到每一个音节中声母和韵母的边界信息,然后提取在表1中描述的音段层级的特征。相应声调的后验概率是通过训练好的SLTM得到的,具体的,可以直接使用SLTM最后的softmax层的输出为相应声调的后验概率,用公式(4)表示如下:SLP(tk)=logp(tk|o)(4)其中,tk表示声调的标签,k={1,2,3,4},o表示相应的输入参数。Step4:根据所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率对所述待识别语音进行声调评估。首先,基于所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率、通过支持向量机SVM建立声调评估模型。如附图3所示,提取相应的置信度量后,即“所述平均帧级别后验概率”、“所述对数后验比”以及“所述音段层级对数后验概率”,使用一个分类器对所提取的置信度量进行建模。优选的,所述声调评估模型可以使用SVM来对上述多层级置信度量进行建模,而所述SVM可以使用常用的“LibSVM”工具包进行实现。每一个音段层级的特征由FLTM输出的帧后验矩阵(帧索引ts到帧索引te)和SLTM输出的音段层级的后验概率组成。最终,学习者声调音素对应的音段层级的特征定义如下:[AFLP(p1),AFLP(p2),...,AFLP(pM),LPR(p1|pi),LPR(p2|pi),...,LPR(pM|pi),SLP(p1),SLP(p2),...,SLP(pM)]T其中,M是所有音素的个数,此处优选M=4。然后,通过所述声调评估模型对所述待识别语音进行声调评估。也就是说,将所述待识别语音的所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率作为输入量,基于所述声调评估模型获取针对所述待识别语音的检测结果。根据本发明提出的声调识别方法,把韵律特征、频谱特征和发音特征融合在一起而建立基于帧级别特征的声调模型,与此同时,训练一个以音段特征为输入特征的基于音段级别特征的声调模型,根据上述两个声调模型,提取与声调相关的帧层级和音段层级的多层级置信度量而进行声调评测,实现了上述两个置信度量的互补性,提高了声调评估的鲁棒性。为了进一步体现本发明实施例的声调评估方法相对于现有方法的优势,可以进行相关声调评估试验并将试验数据进行比对以直观体验。如表3所示,其给出了FLTM和SLTM在母语语音上的识别结果。表1不同声调模型在母语者数据上的声调错误率由此可见,在FLTM中,特征级上融合AF后,声调识别的性能得到明显提升,相对错误率下降了大约10.1%。为进一步验证本发明实施例的有益效果,可以将所述待识别语音的所述平均帧级别后验概率、所述对数后验比以及所述音段层级对数后验概率作为输入量,基于所述声调评估模型获取针对所述待识别语音的检测结果,并根据获取的检测结果分别计算错误接受率FAR、错误拒绝率FRR和诊断正确率DA。具体的,可将上述检测结果划分为如表4所示的4类,即“正确发音检测为正确发音”、“偏误发音检测为正确发音”、“偏误发音检测为偏误发音”和“正确发音检测为偏误发音”。表2检测结果分类TA正确发音检测为正确发音FA偏误发音检测为正确发音TR偏误发音检测为偏误发音FR正确发音检测为偏误发音根据上述四种检测结果,我们选择了比较常用的评价指标来衡量提出的方法的性能,分别是FAR:学习者的错误发音被检测为正确发音的百分比;FRR:学习者的正确发音被系统检测为错误发音的百分比;以及,DA:系统的检测正确率,也就是系统的检测结果与标注结果一致性。具体的计算公式如下:FAR=FAFA+TR---(5)]]>FRR=FRFR+TA---(6)]]>DA=TA+TRTA+TR+FA+FR---(7)]]>我们设计了三个实验系统,分别对应不同的置信度量。“系统1”采用由FLTM得到的AFLP和LPR置信度量作为SVM输入特征,“系统2”采用由SLTM得到的SLP置信度量作为SVM输入特征,“系统3”采用AFLP+LPR+SLP组成的多层级置信度量作为SVM输入特征。我们首先使用受试者工作特征曲线(ROC)比较是上述三个系统的性能。ROC曲线用来表示TPR(truepositiverate,真正类率)和FPR(falsepositiverate,假正类率)之间的关系。TPR表示分类器所识别出的正实例占所有正实例的比例,对应图4中Y轴所示。FPR表示分类器错认为正类的负实例占所有负实例的比例,对应图4中X轴。这也意味着图4中左上角是最理想的数据。如图4所示,使用多层级置信度量的系统在每个声调评估中性能都是最好。这表明我们提出的方法的有效性显著高于现有方法,充分利用了不同层级上声调相关的信息,同时也体现了帧级别上得分与音段层级上的得分有一定的互补性。尽管我们希望在保证诊断正确率高的同时,尽量降低两类错误率(即,FRR和FAR)。然而,错误拒绝率和错误接受率之间存在一种内在权衡。从CAPT的目的出发,关键是要避免把学习者的正确发音判为偏误发音而消减他们学习的信心。因此,实验中以高的诊断率和低的错误拒绝率为目标进行参数优化。表5进一步给出了“系统3”在三个指标上的结果,整体性能取得了FRR为5.63%,FAR为49.2%,DA为82.45%。由于我们旨在最大化DA。实际上,我们的语料库中发音正确的样本要比发音错误的样本多很多,这也就导致了在计算DA时,FRR更起作用,这也是FAR高的原因,尤其是在Tone3中。表3:系统3中各个声调三个评估指标的结果ToneFRRFARDATone111.8%39.5%78.3%Tone27.1%38.8%80.0%Tone32.1%70%81.7%Tone41.5%48.489.8%Overall5.63%49.2082.45在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”、“顺时针”、“逆时针”、“轴向”、“径向”、“周向”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。在本发明中,除非另有明确的规定和限定,第一特征在第二特征“上”或“下”可以是第一和第二特征直接接触,或第一和第二特征通过中间媒介间接接触。而且,第一特征在第二特征“之上”、“上方”和“上面”可是第一特征在第二特征正上方或斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”可以是第一特征在第二特征正下方或斜下方,或仅仅表示第一特征水平高度小于第二特征。在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1