基于静音游程的语音识别方法及其系统与流程
本发明涉及语音识别领域,具体说的是基于静音游程的语音识别方法及其系统。
背景技术:
说话人识别是指根据人的语音信号由程序自动判断出说话者的身份,属于计算机生物特征识别的一种,可用于智能身份鉴别。一般语音信号可分为有声部分和静音部分(即说话中的无声停顿部分),由于静音部分不包含语音信息,因此在传统的说话人识别方法中一般都是将静音部分去除,提取有声信号的特征进行识别,例如基音周期、过零率、明亮度、线性预测系数、线性预测倒谱系数、mfcc、lpcc等特征。传统方法对于说话人识别的准确率达到一定水平后难以继续大幅提高,需要寻找新的识别特征和识别方法。
技术实现要素:
本发明所要解决的技术问题是:提供一种基于静音游程的语音识别方法及其系统,有效提高语音识别的准确度。
为了解决上述技术问题,本发明采用的技术方案为:
基于静音游程的语音识别方法,包括:
预设分别对应静音信号和非静音信号的二进制基本算符;
对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列;
依据所述游程序列中的静音信号提取游程特征,并存储至数据库;
获取待识别的一段语音信号对应的待识别游程序列;
依据所述待识别游程序列中的静音信号提取待识别游程特征;
将所述待识别游程特征与数据库中的游程特征进行匹配。
本发明提供的另一个技术方案为:
基于静音游程的语音识别系统,包括:
预设模块,用于预设分别对应静音信号和非静音信号的二进制基本算符;
转换模块,用于对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列;
第一提取模块,用于依据所述游程序列中的静音信号提取游程特征,并存储至数据库;
获取模块,用于获取待识别的一段语音信号对应的待识别游程序列;
第二提取模块,用于依据所述待识别游程序列中的静音信号提取待识别游程特征;
匹配模块,用于将所述待识别游程特征与数据库中的游程特征进行匹配。
本发明的有益效果在于:区别于现有技术的语音识别技术均是基于有声部分的特征进行识别,其准确率难以再提升的困境。本发明提供一种基于静音游程的语音识别方法,通过提取语音信号中的静音特征,依据静音特征反映出的说话节奏变化、频率、停顿等个性化区别,从而更准确的从数据库中识别出与待识别语音信号最为匹配的语音信号,进而为待识别语音信号的身份确认提供准确的依据。
附图说明
图1为本发明基于静音游程的语音识别方法的流程示意图;
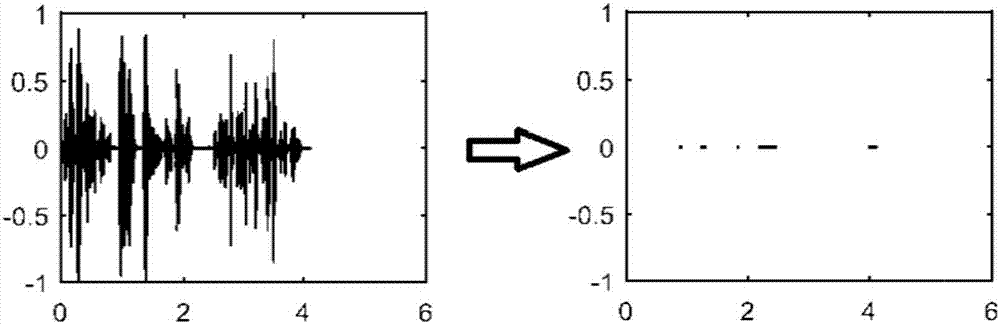
图2为本发明将语音声波转换得到静音部分的示意图;
图3为实施例二中训练样本中说话者a的声波图;
图4为实施例二中训练样本中说话者b的声波图;
图5为实施例二中训练样本中说话者a的静音游程;
图6为实施例二中训练样本中说话者b的静音游程;
图7为实施例二中待识别说话者的声波图;
图8为实施例二中待识别说话者的静音游程;
图9为本发明基于静音游程的语音识别系统的功能模块组成示意图;
图10为实施例三的语音识别系统的功能模块组成示意图。
标号说明:
1、预设模块;2、转换模块;3、第一提取模块;4、获取模块;
5、第二提取模块;6、匹配模块;
21、预设单元;22、第一获取单元;23、确定单元;24、转换单元;
61、计算单元;62、第二获取单元。
具体实施方式
为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
本发明最关键的构思在于:提取语音信号中的静音特征,依据静音特征从数据库中识别出与待识别语音信号最为匹配的预存的语音信号。
请参照图1和图2,本发明提供基于静音游程的语音识别方法,包括:
预设分别对应静音信号和非静音信号的二进制基本算符;
对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列;
依据所述游程序列中的静音信号提取游程特征,并存储至数据库;
获取待识别的一段语音信号对应的待识别游程序列;
依据所述待识别游程序列中的静音信号提取待识别游程特征;
将所述待识别游程特征与数据库中的游程特征进行匹配。
从上述描述可知,本发明的有益效果在于:相较传统的语音识别方式,采用静音特征匹配来识别语音信号的身份,基于说话者反映出的节奏变化、频率、停顿等识别说话者的身份,提高语音识别的准确性;还能与传统语音识别相结合,进一步的提升语音识别的精确度。
进一步的,所述游程特征包括游程距m1;
依据公式
由上述描述可知,提取的静音特征中包含游程距,游程距代表说话人的平均停顿时长,能够综合反映说话人语速快慢特点。
进一步的,所述游程特征还包括游程中心距m2、游程绝对矩m3、游程熵m4和游程方差m5;
依据公式
依据公式
依据公式
依据公式
由上述描述可知,提取的静音特征中还包括游程中心距、游程绝对矩、游程熵和游程方差,它们能够多角度的描述说话人停顿的稳定性特征,综合反映一个人说话是否平顺的特点。因此,依据游程序列中的静音信号提取的游程序列,能充分反映说话人的说话节奏变化、频率、停顿等个性化特点,从而提高语音识别的准确率。
进一步的,所述对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列,具体为:
预设语音强度阈值;
获取大于预设长度的一段语音模拟信号;
依据所述语音强度阈值,逐个确定所述语音信号中模拟信号为静音信号还是非静音信号;
依据静音信号和非静音信号各自对应的二进制基本算符,将所述语音模拟信号转换成由二进制基本算符组成的游程序列。
由上述描述可知,获取的语音信号必须大于预设的长度,才会有足够的停顿信息,据此获取的静音特征才能充分、准确的反映出说话人的节奏变化、频率、停顿等个性化特点,防止停顿随机性造成的误差。
进一步的,数据库中存储的游程特征的个数为两个以上;对应各游程特征预设唯一的标识符。
由上述描述可知,可以准确地判断待识别语音信息与数据库中预存的多个身份标识的语音信息的匹配程度,进而确认待识别语音信息的身份,为门禁系统或者警务需求的身份识别提供服务。
进一步的,所述将所述待识别游程特征与数据库中的游程特征进行匹配,具体为:
依据欧式距离公式,分别计算所述待识别游程特征与数据库中存储的各个游程特征的特征距离;
获取数值最小的特征距离对应的游程特征的标识符。
由上述描述可知,可以依据欧式距离公式准确判断待识别语音信息与预存的语音信息的匹配程度。
请参阅图9,本发明提供的另一个技术方案为:
基于静音游程的语音识别系统,包括:
预设模块,用于预设分别对应静音信号和非静音信号的二进制基本算符;
转换模块,用于对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列;
第一提取模块,用于依据所述游程序列中的静音信号提取游程特征,并存储至数据库;
获取模块,用于获取待识别的一段语音信号对应的待识别游程序列;
第二提取模块,用于依据所述待识别游程序列中的静音信号提取待识别游程特征;
匹配模块,用于将所述待识别游程特征与数据库中的游程特征进行匹配。
请参阅图10,进一步的,所述提取模块提取的游程特征包括游程距m1、游程中心距m2、游程绝对矩m3、游程熵m4和游程方差m5;
依据公式
依据公式
依据公式
依据公式
依据公式
进一步的,所述转换模块包括:
预设单元,用于预设语音强度阈值;
第一获取单元,用于获取大于预设长度的一段语音模拟信号;
确定单元,用于依据所述语音强度阈值,逐个确定所述语音信号中模拟信号为静音信号还是非静音信号;
转换单元,用于依据静音信号和非静音信号各自对应的二进制基本算符,将所述语音模拟信号转换成由二进制基本算符组成的游程序列。
进一步的,所述第一提取模块中存储在数据库中的游程特征的个数为两个以上;
所述预设模块,还用于对应各游程特征预设唯一的标识符;
所述匹配模块包括:
计算单元,用于依据欧式距离公式,分别计算所述待识别游程特征与数据库中存储的各个游程特征的特征距离;
第二获取单元,用于获取数值最小的特征距离对应的游程特征的标识符。
请参照图1和图2,本发明的实施例一为:
本实施例提供一种基于静音游程的语音识别方法,可适用于各种语音识别需求,如门禁系统基于语音的身份识别需求,以及警务系统对犯罪嫌疑人的语音身份识别需求。
首先,预设分别对应静音信号和非静音信号的二进制基本算符;预设语音强度阈值t(单位分贝);如预设静音信号对应二进制基本算符1,非静音信号对应二进制基本算符0,或者二者互换,二进制基本算符用于标示语音信号对应的是静音还是非静音。所述语音强度阈值优选取人耳能分辨的最小音量3分贝,即t=3。
本实施例的语音识别方法可以包括训练子步骤以及识别子步骤。
(一)训练子步骤
训练子步骤用于获取多个已知身份的语音信号,然后提取对应的游程特征,存入数据库,作为语音识别的基础数据库。
具体的,训练子步骤可以包括:
s1:通过录音设备获取一个已知身份用户(假设该用户标识为user1),一段足够长度的录音,即用户标识为user1的一段语音信号。
s2:判断该段语音信号的长度是否大于预设长度,优选所述预设长度为30秒;如果是,进入s3;如果否,则训练条件不满足,提示用户重新录音,返回步骤s1。
s3:该段语音信号假设用y=f(t)表示,其中,t代表采样时刻,f表示录音设备对声音模拟信号的处理,y表示处理得到的数字信号值(单位分贝);
对于任意采样时刻,如果y<t,则令y=1;即该时刻的语音信号小于预设的强度阈值t,标记为静音信号,用二进制基本算符1表示;
如果y≥t,则令y=0;
对整段语音信号进行转换,形成一个由0和1组成的游程序列。
s4:基于游程序列中的静音信号,提取包括游程矩m1、游程中心矩m2、游程绝对矩m3、游程熵m4、游程方差m5的游程特征。
具体提取方法如下:
s41:用i代表游程序列中数值为1的游程长度的随机变量,则p(i)定义为:游程长度为i的游程数量与数值为1的总的游程数量的比值。
游程矩m1计算公式如式(1)所示:
游程矩m1代表说话人平均停顿时长,m1综合反映一个人说话语速快慢特点。
s42:游程中心矩m2的计算公式如式(2)所示:
s43:游程绝对矩m3的计算公式如式(3)所示:
s44:游程熵m4的计算公式如式(4)所示:
s45:游程方差m5的计算公式如式(5)所示:
通过m2到m5可以从多个角度描述说话人停顿的稳定性特征,综合所映一个人说话是否平顺的特点。
s5:将m1到m5组合成用户user1的游程特征向量,记为vuser1={mu1,mu2,mu3,mu4,mu5};将其存入数据库中,完成对于user1的语音特征训练。对于其它用户采用同样的方式提取特征向量,并记录于数据库中。
(二)识别子步骤
识别子步骤用于将未知身份的一段语音信号基于其中的静音信号提取游程特征,并与数据库中存储的所有游程特征进行匹配,获取与其特征距离最小的游程特征,进而识别出该说话人的身份。
具体的,识别步骤可以包括:
ss1:通过录音设备获取一个未知身份用户x的一段足够长度的语音信号,即待识别语音信号。
ss2:判断待识别语音信号长度是否大于预设长度,如果是进入ss3;如果否,则识别条件不满足,提示用户重新录音,返回步骤ss1。
ss3:参照训练子步骤的中的步骤s3-s4,获取该未知身份用户x对应的待识别语音信号的待识别游程特征m1到m5,组成用户x的待识别游程特征向量,记为x={m1,m2,m3,m4,m5}。
ss4:假设数据库中一共存储有k个用户,从数据库中取出这k个用户的特征像量vuser1,vuser2,vuser3,……vuserk;然后分别计算x与vuseri(i=1,2,3,……,k)的特征距离di,特征距离采用欧式距离,距离公式如下式(6)所示:
ss5:比较所有di(i=1,2,……,k)的值,选择di最小的值对应的用户useri作为未知用户x的语音识别结果,从而识别出x的身份为useri。
作为另一具体实施例,可以将上述实施例基于静音部分的语音识别方法与传统基于非静音部分的语音识别方式相结合,作为对传统识别方式的辅助补充,显著提高对说话人语音识别的准确性。
请参照图3-图8,本发明的实施例二为:
本实施例为基于实施例一的一具体运用场景。
(1)说话人训练
假设训练样本个数为2,即只需要从两个人的声音样本中识别出说话人身份。两人说同一段话内容,采集到的声波如图3和图4所示,图3的声音样本为说话者a,图4的声音样本为说话者b。
按照实施例一中步骤s3的方法,以3分贝为强度阈值对语音信号进行二值化,并把小于3分贝的语音信号采样点标记为1,得到图5和图6的静音游程;图中横线部份为标1的游程,表示说话语音的静音部分,其余白色部分为语音中的有声部分。
说话人a(图5)的游程数据为:
[0000000000011000001111000000100000011111111111000000000000001111111];
说话人b(图6)的游程数据为:
[1110011110101101001111000111100100111000000110010010101111101000010];
说话人a的游程序列中,共有5个数值为1的静音游程,长度分别为2,4,1,11,7。因此,按实施例一s4中的公式,说话人a的游程矩的计算为:
游程中心矩的计算为:
游程绝对矩的计算为:
游程熵m4的计算为:
游程方差m5的计算为:
因此说话人a所训练的游程特征向量为:
va={5,0,3.2,0.7,13.2};
说话人b的游程序列中,共有16个数值为1的静音游程,长度分别为3,4,1,2,1,4,4,1,3,2,1,1,1,5,1,1。因此,按实施例一s4的公式,其游程矩的计算为:
游程中心矩的计算为:
游程绝对矩的计算为:
游程熵的计算为:
游程方差的计算为:
因此,说话人b所训练的游程特征向量为:
vb={2.19,-0.04,19.76,0.588,1.902}
通过上述完成对说话人a和说话人b的训练,将va和vb存入数据库供识别时使用。
(2)说话人识别
有说话人说了同一内容的另一段语音(实际为说话人a说的),语音波形如图7所示;
参照上述方法,以3分贝为强度阈值对语音信号进行二值化,并把小于3分贝的语音信号采样点标记为1,得到的静音游程如图8所示,具体的游程序列为:[0000000000011000001111000000000000011111111111100010000110001111111];
待识别游程序列中,共有6个数值为1的游程,长度分别为2,4,12,1,2,7。因此,其游程矩的计算为:
游程中心矩的计算为:
游程绝对矩的计算为:
游程熵的计算为:
游程方差的计算为:
因此待识别人的游程特征向量为:
v={4.67,-0.001,3.227,0.678,14.56}
计算v与数据库中已训练的va、vb向量的距离。
对距离进行比较,da是距离最小的值,对应的用户a做为识别结果,即识别出待识别语音的说话人身份为a。
实施例三
请参阅图10,本实施例为基于实施例一和实施例二提供的基于静音游程的语音识别系统,具体的,可以包括:
预设模块1,用于预设分别对应静音信号和非静音信号的二进制基本算符;
转换模块2,用于对所获取的一段语音信号中的静音信号和非静音信号依据对应的二进制基本算符进行转换,获取由二进制基本算符组成的游程序列;
第一提取模块3,用于依据所述游程序列中的静音信号提取游程特征,并存储至数据库;
获取模块4,用于获取待识别的一段语音信号对应的待识别游程序列;
第二提取模块5,用于依据所述待识别游程序列中的静音信号提取待识别游程特征;
匹配模块6,用于将所述待识别游程特征与数据库中的游程特征进行匹配。
在一具体实施方式中,所述提取模块提取的游程特征包括游程距m1、游程中心距m2、游程绝对矩m3、游程熵m4和游程方差m5;
依据公式
依据公式
依据公式
依据公式
依据公式
在一具体实施例中,所述转换模块2包括:
预设单元21,用于预设语音强度阈值;
第一获取单元22,用于获取大于预设长度的一段语音模拟信号;
确定单元23,用于依据所述语音强度阈值,逐个确定所述语音信号中模拟信号为静音信号还是非静音信号;
转换单元24,用于依据静音信号和非静音信号各自对应的二进制基本算符,将所述语音模拟信号转换成由二进制基本算符组成的游程序列。
在一具体实施例中,所述第一提取模块3中存储在数据库中的游程特征的个数为两个以上;
所述预设模块1,还用于对应各游程特征预设唯一的标识符;
所述匹配模块6包括:
计算单元61,用于依据欧式距离公式,分别计算所述待识别游程特征与数据库中存储的各个游程特征的特征距离;
第二获取单元62,用于获取数值最小的特征距离对应的游程特征的标识符。
综上所述,本发明提供的基于静音游程的语音识别方法及其系统,能够依据静音特征反映出的说话节奏变化、频率、停顿等个性化区别,更准确的从数据库中识别出与待识别语音信号最为匹配的语音信号,进而为待识别语音信号的身份确认提供准确的依据;同时,还能与传统基于非静音部分的语音识别方式相结合,再进一步的提升语音识别的精确度。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!