一种人声智能识别触控开关及其控制方法与流程
本发明涉及智能开关技术领域,尤其是一种人声智能识别触控开关及其控制方法。
背景技术:
随着智能家居产品的普及,人声智能识别开关的产品在市场上层出不穷。不过,现有的人声智能识别开关的识别精度不高,为了提高识别精度,通常使用实现录音的手段,这就导致用户体验较差,使用不方便。
技术实现要素:
本发明要解决的技术问题是提供一种人声智能识别触控开关及其控制方法,能够解决现有技术的不足,提高了人声识别的精确度。
为解决上述技术问题,本发明所采取的技术方案如下。
一种人声智能识别触控开关,包括,
语音采集模块,用于采集语音信号;
滤波模块,用于采集到的语音信号进行滤波处理;
数据库模块,用于存储标准语音命令;
语音识别模块,用于将语音信号与数据库模块中的标准语音命令进行比对识别;
执行模块,根据语音识别模块的识别结果执行相应命令。
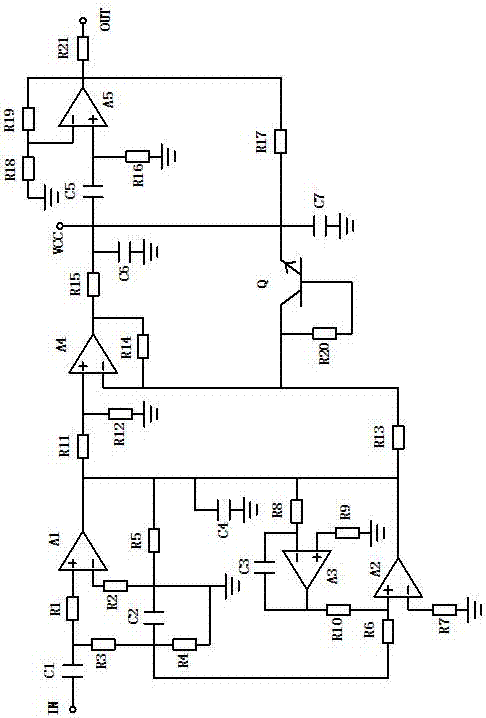
作为优选,所述述滤波模块的输入端通过串联的第一电容和第一电阻连接至第一运放的正相输入端,第一运放的反相输入端通过第二电阻接地,第一电容和第一电阻之间通过串联的第三电阻和第四电阻接地,第三电阻和第四电阻之间通过第二电容接地,第一运放的输出端通过第五电阻接地,第三电阻和第四电阻之间通过第六电阻连接至第二运放的正相输入端,第二运放的反相输入端通过第七电阻接地,第二运放的输出端通过第八电阻连接至第三运放的反相输入端,第三运放的正相输入端通过第九电阻接地,第三运放的输出端通过第十电阻连接至第二运放的正相输入端,第三运放的反相输入端通过第三电容连接至第三运放的输出端,第一运放的输出端通过第十一电阻连接至第四运放的正相输入端,第四运放的正相输入端通过第十二电阻接地,第二运放的输出端通过第十三电阻连接至第四运放的反相输入端,第一运放的输出端和第二运放的输出端通过第四电容接地,第四运放的反相输入端通过第十四电阻连接至第四运放的输出端,第四运放的输出端通过串联的第十五电阻和第五电容连接至第五运放的正相输入端,第十五电阻和第五电容之间通过第六电容接地,第五电容和第五运放的正相输入端通过第十六电阻接地,第十五电阻和第五电容之间通过第十七电阻连接至第五运放的输出端,第五运放的反相输入端通过第十八电阻接地,第五运放的输出端通过第十九电阻连接至第五运放的反相输入端,第四运放的反相输入端连接至三极管的集电极,三极管的集电极通过第二十电阻连接至三极管的基极,三极管的发射极连接至第五电容和第十七电阻之间,三极管的发射极通过第七电容接地,第五运放的输出端通过第二十一电阻连接至输出端。
一种上述的人声智能识别触控开关的控制方法,包括以下步骤:
a、语音采集模块对语音信号进行采集;
b、采集到的语音信号通过滤波模块处理后进入语音识别模块;
c、语音识别模块将语音信号进行分解,与数据库模块内的标准语音命令进行比对,若比对出相同的语音命令,则将此语音命令发送至执行模块进行执行,然后等待下一个语音信号,若未比对出相同的语音命令,则直接等待下一个语音信号。
作为优选,所述语音采集模块对采集的语音信号进行预识别,识别语音信号中重复的信号段,统计信号段的重复率,将重复率超出阈值的语音信号段或者重复次数超出阈值的语音信号段进行剔除;重复率为,
其中,p为重复率,n为重复次数,t为统计时间。
作为优选,所述重复率阈值为2~5次/秒,重复次数阈值为10~20次。
作为优选,数据库模块根据语音识别模块做出的比对结果对存储的标准语音命令进行优化;首先,抓取语音识别模块识别出的语音命令,将识别出的语音命令与标准语音命令进行对比,将其声波模型偏差量按照时域形式进行暂存;第二,建立最近邻算法模型,然后对模型中训练样本和测试样本的距离进行优化,
其中,
根据上述距离最小值对训练样本进行修正;第三,利用最近邻算法模型得出最优化的声波模型偏差量,使用得出的声波模型偏差量对原标准语音命令进行修改,得到优化后的标准语音命令。
作为优选,步骤c中,语音识别模块将语音信号进行识别包括以下步骤,
c1、提取数据库模块内的标准语音命令的特征向量,组成标准矩阵,然后建立不同特征向量之间的映射函数;
c2、将语音信号进行分解,提取分解出的语音片段的特征向量,组成比对矩阵,然后建立不同特征向量之间的映射函数;
c3、使用比对矩阵与标准矩阵进行比对,比对出同一比对矩阵与不同标准矩阵的偏差度,以及对应的映射函数线性偏差度;
c4、将矩阵偏差度与映射函数线性偏差度进行加权求和,如果存在求和结果小于判定阈值的标准语音命令,则将求和结果最小的标准语音命令认定为执行命令,若不存在求和结果小于判定阈值的标准语音命令,则结束识别,等待下一个语音信号。
作为优选,所述矩阵偏差度的权重值为0.65,映射函数线性偏差度的权重值为0.35。
采用上述技术方案所带来的有益效果在于:本发明通过建立标准语音命令数据库,无需用户录入语音命令,便于用户使用。通过语音采集模块和滤波模块对语音信号的过滤,可以有效去除语音信号中包含的背景杂音和干扰信号。滤波模块通过设计两条音频处理通道,可以对音频中包含的脉冲干扰进行有效的剔除,并且保证了输出音频信号的强度和失真度。本发明的数据库模块通过对标准语音命令进行实时优化,可以有效提高对于语音命令的识别度。在对语音信号进行识别时,使用与标准矩阵的偏差度和映射函数线性偏差度作为识别的对象,通过加权求和,得到优化后的识别目标值,解决了单一识别目标容易导致识别误差大的原因。
附图说明
图1是本发明一个具体实施方式的原理图。
图2是本发明一个具体实施方式中滤波模块的电路图。
图中:1、语音采集模块;2、滤波模块;3、数据库模块;4、语音识别模块;5、执行模块;in、输入端;out、输出端;r1、第一电阻;r2、第二电阻;r3、第三电阻;r4、第四电阻;r5、第五电阻;r6、第六电阻;r7、第七电阻;r8、第八电阻;r9、第九电阻;r10、第十电阻;r11、第十一电阻;r12、第十二电阻;r13、第十三电阻;r14、第十四电阻;r15、第十五电阻;r16、第十六电阻;r17、第十七电阻;r18、第十八电阻;r19、第十九电阻;r20、第二十电阻;r21、第二十一电阻;c1、第一电容;c2、第二电容;c3、第三电容;c4、第四电容;c5、第五电容;c6、第六电容;c7、第七电容;a1、第一运放;a2、第二运放;a3、第三运放;a4、第四运放;a5、第五运放;q、三极管;vcc、反馈信号注入端。
具体实施方式
本发明中使用到的标准零件均可以从市场上购买,异形件根据说明书的和附图的记载均可以进行订制,各个零件的具体连接方式均采用现有技术中成熟的螺栓、铆钉、焊接、粘贴等常规手段,在此不再详述。
参照图1-2,本发明一个具体实施方式包括语音采集模块1,用于采集语音信号;
滤波模块2,用于采集到的语音信号进行滤波处理;
数据库模块3,用于存储标准语音命令;
语音识别模块4,用于将语音信号与数据库模块3中的标准语音命令进行比对识别;
执行模块5,根据语音识别模块4的识别结果执行相应命令。
滤波模块2的输入端in通过串联的第一电容c1和第一电阻r1连接至第一运放a1的正相输入端,第一运放a1的反相输入端通过第二电阻r2接地,第一电容c1和第一电阻r1之间通过串联的第三电阻r3和第四电阻r4接地,第三电阻r3和第四电阻r4之间通过第二电容c2接地,第一运放a1的输出端通过第五电阻r5接地,第三电阻r3和第四电阻r4之间通过第六电阻r6连接至第二运放a2的正相输入端,第二运放a2的反相输入端通过第七电阻r7接地,第二运放a2的输出端通过第八电阻r8连接至第三运放a3的反相输入端,第三运放a3的正相输入端通过第九电阻r9接地,第三运放a3的输出端通过第十电阻r10连接至第二运放a2的正相输入端,第三运放a3的反相输入端通过第三电容c3连接至第三运放a3的输出端,第一运放a1的输出端通过第十一电阻r11连接至第四运放a4的正相输入端,第四运放a4的正相输入端通过第十二电阻r12接地,第二运放a2的输出端通过第十三电阻r13连接至第四运放a4的反相输入端,第一运放a1的输出端和第二运放a2的输出端通过第四电容c4接地,第四运放a4的反相输入端通过第十四电阻r14连接至第四运放a4的输出端,第四运放a4的输出端通过串联的第十五电阻r15和第五电容c5连接至第五运放a5的正相输入端,第十五电阻r15和第五电容c5之间通过第六电容c6接地,第五电容c5和第五运放a5的正相输入端通过第十六电阻r16接地,第十五电阻r15和第五电容c5之间通过第十七电阻r17连接至第五运放a5的输出端,第五运放a5的反相输入端通过第十八电阻r18接地,第五运放a5的输出端通过第十九电阻r19连接至第五运放a5的反相输入端,第四运放a4的反相输入端连接至三极管q的集电极,三极管q的集电极通过第二十电阻r20连接至三极管q的基极,三极管q的发射极连接至第五电容c5和第十七电阻r17之间,三极管q的发射极通过第七电容c7接地,第五运放a5的输出端通过第二十一电阻r21连接至输出端out。
此外,在上述滤波电路的基础上,在语音识别模块4上设置语音信号监控装置,对滤波处理后的语音信号进行监控,当出现未被过滤的连续性干扰信号时,通过设置在第十五电阻r15和第五电容c5之间的反馈信号注入端vcc注入反馈补偿信号,从而对语音信号进行反馈补偿,改善了滤波电路对于动态干扰滤波效果较差的问题。
一种上述的人声智能识别触控开关的控制方法,包括以下步骤:
a、语音采集模块1对语音信号进行采集;
b、采集到的语音信号通过滤波模块2处理后进入语音识别模块4;
c、语音识别模块4将语音信号进行分解,与数据库模块3内的标准语音命令进行比对,若比对出相同的语音命令,则将此语音命令发送至执行模块5进行执行,然后等待下一个语音信号,若未比对出相同的语音命令,则直接等待下一个语音信号。
语音采集模块1对采集的语音信号进行预识别,识别语音信号中重复的信号段,统计信号段的重复率,将重复率超出阈值的语音信号段或者重复次数超出阈值的语音信号段进行剔除;重复率为,
其中,p为重复率,n为重复次数,t为统计时间。
重复率阈值为3次/秒,重复次数阈值为15次。
数据库模块3根据语音识别模块4做出的比对结果对存储的标准语音命令进行优化;首先,抓取语音识别模块4识别出的语音命令,将识别出的语音命令与标准语音命令进行对比,将其声波模型偏差量按照时域形式进行暂存;第二,建立最近邻算法模型,然后对模型中训练样本和测试样本的距离进行优化,
其中,
根据上述距离最小值对训练样本进行修正;第三,利用最近邻算法模型得出最优化的声波模型偏差量,使用得出的声波模型偏差量对原标准语音命令进行修改,得到优化后的标准语音命令。
步骤c中,语音识别模块4将语音信号进行识别包括以下步骤,
c1、提取数据库模块3内的标准语音命令的特征向量,组成标准矩阵,然后建立不同特征向量之间的映射函数;
c2、将语音信号进行分解,提取分解出的语音片段的特征向量,组成比对矩阵,然后建立不同特征向量之间的映射函数;
c3、使用比对矩阵与标准矩阵进行比对,比对出同一比对矩阵与不同标准矩阵的偏差度,以及对应的映射函数线性偏差度;
c4、将矩阵偏差度与映射函数线性偏差度进行加权求和,如果存在求和结果小于判定阈值的标准语音命令,则将求和结果最小的标准语音命令认定为执行命令,若不存在求和结果小于判定阈值的标准语音命令,则结束识别,等待下一个语音信号。
矩阵偏差度的权重值为0.65,映射函数线性偏差度的权重值为0.35。
在此基础上,发明人发现,对于矩阵偏差度和映射函数线性偏差度的权重值,还可以进行进一步优化。对于经过优化后的标准语音命令组成的标准矩阵,其偏差度权重值进行增加,增加的幅度与标准语音命令优化的次数成正比,矩阵偏差度的最大权重值不大于0.85。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!