尾音识别方法及语音遥控器与流程
本发明涉及语音遥控器的技术领域,尤其涉及一种尾音识别方法及语音遥控器。
背景技术:
目前,随着数字化技术的发展,遥控器的功能也越来越多,有蓝牙,红外,语音等功能。而语音功能是智能设备非常重要的一种功能,其语音识别的准确率也是非常重要的。现有遥控器是通过蓝牙或者2.4G技术传输声音,但在遥控器的语音数据接收模块外一层存在屏幕遮挡,且受到周围复杂环境的影响,使得遥控器的语音识别能力比较差,容易丢失尾音。
技术实现要素:
本发明的主要目的在于提出一种尾音识别方法及语音遥控器,旨在解决遥控器的语音识别能力比较差,容易丢失尾音的技术问题。
为实现上述目的,本发明提供的一种尾音识别方法,所述尾音识别方法包括以下步骤:
根据用户触发的采集指令对用户的语音进行采集;
当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,并判断通过采集获得的总录音数据是否为完整录音数据;
若所述总录音数据不为所述完整录音数据,则继续对用户的语音进行采集,直至所述总录音数据为完整录音数据时,停止对用户的语音进行采集。
可选地,所述根据用户触发的采集指令对用户的语音进行采集的步骤包括:
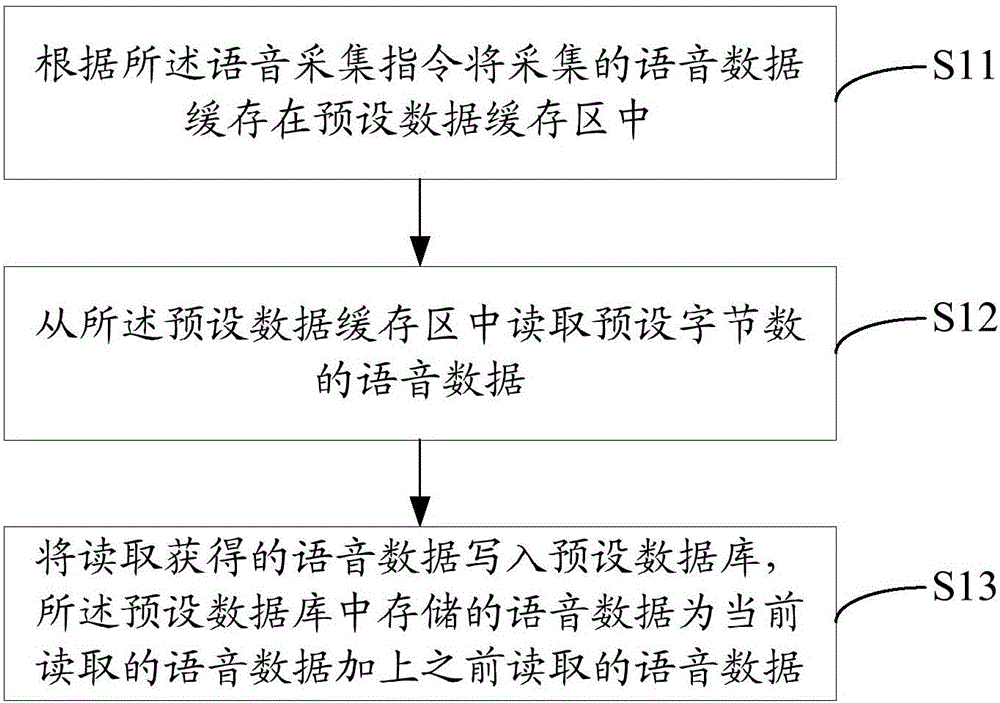
根据所述语音采集指令将采集的语音数据缓存在预设数据缓存区中;
从所述预设数据缓存区中读取预设字节数的语音数据;
将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据。
可选地,所述判断通过采集获得的总录音数据是否为完整录音数据的步骤包括:
判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数;
所述继续对用户的语音进行采集,直至所述总录音数据为完整录音数据时,停止对用户的语音进行采集的步骤包括:
若所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则执行从所述预设数据缓存区中读取预设字节数的语音数据的步骤;
若所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
可选地,所述判断通过采集获得的录音数据是否为完整录音数据的步骤之前,所述尾音识别方法还包括:
获取用户触发语音采集指令的时间,记为开始时间;
当接收到用户触发的采集停止指令,记录停止时间;
根据所述开始时间、所述停止时间和预设比特率计算获得完整录音数据的字节数。
可选地,所述尾音识别方法还包括:
根据从所述预设数据缓存区中读取语音数据的次数计算延迟时间;
判断所述延迟时间是否大于预设时间;
若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据。
此外,为实现上述目的,本发明还提供一种语音遥控器,所述语音遥控器包括:
采集模块,用于根据用户触发的采集指令对用户的语音进行采集;
所述采集模块,还用于当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,并判断通过采集获得的总录音数据是否为完整录音数据;
停止模块,用于若所述总录音数据不为所述完整录音数据,继续对用户的语音进行采集,直至所述总录音数据为完整录音数据时,停止对用户的语音进行采集。
可选地,所述采集模块包括:
缓存单元,用于根据所述语音采集指令将采集的语音数据缓存在预设数据缓存区中;
读取单元,用于从所述预设数据缓存区中读取预设字节数的语音数据;
写入单元,用于将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据。
可选地,所述语音遥控器还包括:
判断模块,用于判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数;
所述读取单元,还用于若所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则从所述预设数据缓存区中读取预设字节数的语音数据;
所述停止模块,还用于若所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
可选地,所述语音遥控器还包括:
获取模块,用于获取用户触发语音采集指令的时间,记为开始时间;
记录模块,用于当接收到用户触发的采集停止指令,记录停止时间;
计算模块,用于根据所述开始时间、所述停止时间和预设比特率计算获得完整录音数据的字节数。
可选地,所述计算模块,还用于根据从所述预设数据缓存区中读取语音数据的次数计算延迟时间;
所述判断模块,还用于判断所述延迟时间是否大于预设时间;
所述停止模块,还用于若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据。
本发明在接收到用户触发的采集指令后,对用户的语音进行采集,当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,直至采集获得的录音数据为完整录音数据时,停止对用户的语音进行采集,本方案在接收到用户触发的采集停止指令时,继续对用户的语音进行采集直至采集获得的录音数据为完整录音数据,因此本发明能够保证录音数据的完整性,使得尾音不丢失,可以准确有效的识别用户的语音。
附图说明
图1为本发明尾音识别方法第一实施例的流程示意图;
图2为本发明第二实施例中所述根据用户触发的采集指令对用户的语音进行采集步骤的细化流程示意图;
图3为本发明尾音识别方法第三实施例的流程示意图;
图4为本发明尾音识别方法第四实施例流程示意图;
图5为本发明尾音识别方法第五实施例的流程示意图;
图6为本发明语音遥控器第一实施例的功能模块示意图;
图7为本发明第二实施例中所述采集模块的细化功能模块示意图;
图8为本发明语音遥控器第三实施例的功能模块示意图;
图9为本发明语音遥控器第四实施例的功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种尾音识别方法。
参照图1,图1为本发明尾音识别方法第一实施例的流程示意图。
在本实施例中,该尾音识别方法包括:
步骤S10,根据用户触发的采集指令对用户的语音进行采集;
用户在所述语音遥控器上按下录音按键,此时所述遥控器接收到录音按键的状态的为down,从而获取触发的语音采集指令,然后根据所述语音采集指令启动所述语音遥控器的录音功能,并消除历史录音数据,为保存新的录音数据做准备,然后语音遥控器对用户的语音数据进行采集,同时监听采集获得的语音数据,判断采集获得的语音数据是否异常。具体实施中,当用户用手指按下所述录音按键,即处于down状态,在很短的时间内移开手指,使得所述录音按键处于up状态,所述语音遥控器不启动录音功能。在更多的实施中,用户连续按下按上所述录音按键,即所述录音按键的状态在down状态和up状态之间来回变化时,所述语音遥控器也不启动录音功能。
步骤S20,当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,并判断通过采集获得的总录音数据是否为完整录音数据;
所述遥控器接收到用户触发的采集停止指令,即所述遥控器中的录音按键处于up状态时,此时由于遥控器外层有外壳阻挡和周围网络环境的影响等,用户的语音数据会延迟传输,因此不会立即停止对用户的语音进行采集,所述遥控器继续对用户的语音进行采集,获得总录音数据,然后判断此时所述数据采集模块采集获得的总录音数据是否为完整录音数据。具体实施中,可根据预设算法获得的完整录音数据的字节数,然后判断该总录音数据的字节数是否与完整录音数据的字节数相等,从而判断该总录音数据是否为完整录音数据。所述预设算法是人为设置的,可以根据不同的实际情况进行不同的设置。所述完整录音数据的字节数是通过预设算法得到的,即要保证录音数据的完整性需要获取的语音数据字节数的大小,只有当获取的语音数据的字节数与完整录音数据的字节数相等,则可以保证录音数据的完整性。在更多的实施中,可预设数据缓存区,将采集获得数据缓存在该数据缓存区中,然后读取固定大小的语音数据,当读取完该数据缓存区中的语音数据时,读取获得的语音数据即可判定为完整录音数据。
步骤S30,若所述总录音数据不为所述完整录音数据,则继续对用户的语音进行采集,直至所述总录音数据为完整录音数据时,停止对用户的语音进行采集。
通过判断得到所述语音遥控器采集获得的总录音数据不为所述完整录音数据,则继续对用户的语音进行采集,直至语音遥控器采集获得的总录音数据为完整录音数据时,停止对用户的语音进行采集,从而保证录音数据的完整性。
在本实施例中,本发明在接收到用户触发的采集指令后,对用户的语音进行采集,当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,直至采集获得的录音数据为完整录音数据时,停止对用户的语音进行采集,本方案在接收到用户触发的采集停止指令时,继续对用户的语音进行采集直至采集获得的录音数据为完整录音数据,因此本发明能够保证录音数据的完整性,使得尾音不丢失,可以准确有效的识别用户的语音。
进一步地,参照图2,基于上述第一实施例可得本发明发明尾音识别方法第二实施例中所述步骤S10的细化流程示意图,在本实施例中,所述步骤S10包括:
步骤S11,根据所述语音采集指令将采集的语音数据缓存在预设数据缓存区中;
所述语音遥控器接收到用户触发的语音采集指令后,即所述语音遥控器中的录音按键处于down状态,根据所述语音采集指令传输到启动所述语音遥控器的录音功能。在本实施例中,所述语音遥控器中预设有语音数据缓存区,用于缓存采集获得的语音数据,即根据所述语音采集指令先将用户的语音数据缓存在预设数据缓存区中。
步骤S12,从所述预设数据缓存区中读取预设字节数的语音数据;
所述语音遥控器将用户的语音数据缓存在所述预设数据缓存区中后,所述语音遥控器从所述预设数据缓存区中读取预设字节数的语音数据,即读取固定大小的语音数据。所述预设字节数可以认为设置,具体实施中,可通过多次试验获得不同实际情况下的最优值,当然也可以设置一个普遍的值,提高所述语音遥控器的兼容性。所述语音遥控器在所述预设缓存区读取语音数据的同时,所述预设缓存区可缓存用户的语音数据,即缓存和读取可同时进行。当然也可以在用户的语音数据缓存完之后,再从预设数据缓存区中读取语音数据。具体实施中,当所述数据缓存区中的语音数据的字节数小于预设字节数时,所述语音遥控器读取该语音数据后,需记录该语音数据的字节数,即记录实际读取获得的语音数据的字节数。
步骤S13,将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据。
所述语音遥控器读取获得语音数据后,将读取获得的语音数据写入预设数据库,所述预设数据库用于存储读取获得的语音数据,包括当前读取的语音数据和之前读取的语音数据,即所述预设数据库中的语音数据为当前读取的语音数据和之前读取的语音数据之和。具体实施中,在事件完成之后,所述预设数据库中的语音数据以及所述预设缓存区中的语音数据都会清空,便于下一次采集,当然也可以在下一次采集开始时,清空历史语音数。
在本实施例中,本发明该语音遥控器中预设有语音数据缓存区,可将用户的语音数据进行缓存,然后所述语音遥控器从所述数据缓存区中读取固定大小的语音数据,并将其写入预设数据库中,使得所述预设数据库中的语音数据为当前读取的语音数据和之前读取的语音数据之和,因此本发明能够在缓存用户的语音数据的同时,读取获得语音数据,减少采集时间。
进一步地,参照图3,基于上述第一或第二实施例可得本发明尾音识别方法第三实施例的流程示意图,在本实施例中,所述步骤S20包括:
步骤S21,判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数;
所述语音遥控器在接收到用户触发的采集停止指令后,即所述录音按键的状态处于up状态,继续对用户的语音进行采集,所述语音遥控器从所述预设数据缓存区中读取语音数据后,判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数。
所述步骤S30包括:
若所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则执行步骤S12,即从所述预设数据缓存区中读取预设字节数的语音数据;
步骤S31,若所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
所述语音遥控器通过判断发现所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则执行步骤S12:从所述预设数据缓存区中读取预设字节数的语音数据,即继续对用户的语音进行采集,然后将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据,在所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
在本实施例中,本发明在接收到用户触发的采集停止指令后,所述语音遥控器继续从所述预设数据缓存区中读取语音数据,然后判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数,若等于,则停止读取,若小于,则继续读取,本方案通过在预设数据缓存区缓存语音数据和读取语音数据,并在触发停止指令时,继续读取语音数据,可快速采集用户的语音数据,也能够有效的保证录音数据的完整性。
进一步地,参照图4,基于上述第一、第二或第三实施例可得本发明尾音识别方法第四实施例流程示意图,在本实施例中,所述步骤S20之前,所述尾音识别方法还包括:
步骤S40,获取用户触发语音采集指令的时间,记为开始时间;
所述语音遥控器接收到用户触发的数据采集指令,即所述语音遥控器中的录音按键处于down状态,此时记录用户触发语音采集指令的时间,该时间为数据采集的开始时间。
步骤S50,当接收到用户触发的采集停止指令,记录停止时间;
所述语音遥控器接收到用户触发的采集停止指令,即所述语音遥控器中的录音按键处于up状态,此时记录用户触发采集停止指令的时间,该时间为采集停止时间,但所述所述语音遥控器继续从所述预设数据缓存区中读取语音数据。
步骤S60,根据所述开始时间、所述停止时间和预设比特率计算获得完整录音数据的字节数。
所述所述语音遥控器获得所述开始时间、所述停止时间和预设比特率后,可根据所述开始时间、所述停止时间和预设比特率计算完整录音数据的字节数,即根据开始时间和停止时间计算获得采集时间,然后采集时间与预设比特率相乘可以得到完整录音数据的字节数,在该总录音数据的字节数等于所述完整录音数据的字节数时,判定所述总录音数据为所述完整录音数据。所述预设比特率可以通过多次试验获得最优值。在本实施例中,所述预设比特率为每毫秒1600字节。
在本实施例中,本发明根据采集语音数据的开始时间和停止时间可以得到采集时间,然后将所述采集时间与预设比特率相乘得到完整录音数据的字节数,在该总录音数据的字节数等于完整录音数据的字节数时,判定所述总录音数据为所述完整录音数据,本发明通过计算完整录音数据的字节数,可快速判定总录音数据的完整性,增强语音识别的准确度。
进一步地,参照图5,基于上述第一、第二、第三或第四实施例可得本发明尾音识别方法第五实施例的流程示意图,在本实施例中,所述尾音识别方法还包括:
步骤S70,根据从所述预设数据缓存区中读取语音数据的次数计算延迟时间;
步骤S80,判断所述延迟时间是否大于预设时间;
步骤S90,若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据。
所述语音遥控器从所述预设数据缓存区中读取语音数据的次数,根据所述次数计算延迟时间,然后判断所述延迟时间是否大于预设时间,若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据,则所述所述语音遥控器判定当前的语音数据的状态为异常,并停止读取所述预设数据缓存区中的语音数据,
在本实施例中,本发明所述语音遥控器获取从所述预设数据缓存区中读取语音数据的次数,并根据该次数计算延迟时间,在该延迟时间大于所述预设时间时,停止读取所述预设数据缓存区中的语音数据,本发明通过预设时间验证延迟时间的有效性,能够在异常情况下,立即停止采集语音,不会造成时间的浪费。
本发明进一步提供一种语音遥控器。
参照图6,图6为本发明语音遥控器第一实施例的功能模块示意图。
在本实施例中,该语音遥控器包括:
采集模块10,用于根据用户触发的采集指令对用户的语音进行采集;
用户在所述语音遥控器上按下录音按键,此时所述遥控器接收到录音按键的状态的为down,从而获取触发的语音采集指令,然后根据所述语音采集指令启动所述语音遥控器的录音功能,并消除历史录音数据,为保存新的录音数据做准备,然后语音遥控器对用户的语音数据进行采集,同时监听采集获得的语音数据,判断采集获得的语音数据是否异常。具体实施中,当用户用手指按下所述录音按键,即处于down状态,在很短的时间内移开手指,使得所述录音按键处于up状态,所述语音遥控器不启动录音功能。在更多的实施中,用户连续按下按上所述录音按键,即所述录音按键的状态在down状态和up状态之间来回变化时,所述语音遥控器也不启动录音功能。
所述采集模块10,还用于当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,并判断通过采集获得的总录音数据是否为完整录音数据;
所述遥控器接收到用户触发的采集停止指令,即所述遥控器中的录音按键处于up状态时,此时由于遥控器外层有外壳阻挡和周围网络环境的影响等,用户的语音数据会延迟传输,因此不会立即停止对用户的语音进行采集,所述遥控器继续对用户的语音进行采集,获得总录音数据,然后判断此时所述数据采集模块采集获得的总录音数据是否为完整录音数据。具体实施中,可根据预设算法获得的完整录音数据的字节数,然后判断该总录音数据的字节数是否与完整录音数据的字节数相等,从而判断该总录音数据是否为完整录音数据。所述预设算法是人为设置的,可以根据不同的实际情况进行不同的设置。所述完整录音数据的字节数是通过预设算法得到的,即要保证录音数据的完整性需要获取的语音数据字节数的大小,只有当获取的语音数据的字节数与完整录音数据的字节数相等,则可以保证录音数据的完整性。在更多的实施中,可预设数据缓存区,将采集获得数据缓存在该数据缓存区中,然后读取固定大小的语音数据,当读取完该数据缓存区中的语音数据时,读取获得的语音数据即可判定为完整录音数据。
停止模块20,用于若所述总录音数据不为所述完整录音数据,则继续对用户的语音进行采集,直至所述总录音数据为完整录音数据时,停止对用户的语音进行采集。
通过判断获得所述语音遥控器中的数据采集模块采集获得的总录音数据不为所述完整录音数据,则继续对用户的语音进行采集,直至数据采集模块采集获得的总录音数据为完整录音数据时,停止对用户的语音进行采集,从而保证录音数据的完整性。
在本实施例中,本发明在接收到用户触发的采集指令后,对用户的语音进行采集,当接收到用户触发的采集停止指令时,继续对用户的语音进行采集,直至采集获得的录音数据为完整录音数据时,停止对用户的语音进行采集,本方案在接收到用户触发的采集停止指令时,继续对用户的语音进行采集直至采集获得的录音数据为完整录音数据,因此本发明能够保证录音数据的完整性,使得尾音不丢失,可以准确有效的识别用户的语音。
进一步地,参照图7,基于上述第一实施例可得本发明发明语音遥控器第二实施例中所述采集模块的细化功能模块示意图,基于上述实施例,在本实施例中,所述采集模块10包括:
缓存单元11,用于根据所述语音采集指令将采集的语音数据缓存在预设数据缓存区中;
所述语音遥控器接收到用户触发的语音采集指令后,即所述语音遥控器中的录音按键处于down状态,根据所述语音采集指令传输到启动所述语音遥控器的录音功能。在本实施例中,所述语音遥控器中预设有语音数据缓存区,用于缓存采集获得的语音数据,即根据所述语音采集指令先将用户的语音数据缓存在预设数据缓存区中。
读取单元12,用于从所述预设数据缓存区中读取预设字节数的语音数据;
所述语音遥控器将用户的语音数据缓存在所述预设数据缓存区中后,所述语音遥控器从所述预设数据缓存区中读取预设字节数的语音数据,即读取固定大小的语音数据。所述预设字节数可以认为设置,具体实施中,可通过多次试验获得不同实际情况下的最优值,当然也可以设置一个普遍的值,提高所述语音遥控器的兼容性。所述语音遥控器在所述预设缓存区读取语音数据的同时,所述预设缓存区可缓存用户的语音数据,即缓存和读取可同时进行。当然也可以在用户的语音数据缓存完之后,再从预设数据缓存区中读取语音数据。具体实施中,当所述数据缓存区中的语音数据的字节数小于预设字节数时,所述语音遥控器读取该语音数据后,需记录该语音数据的字节数,即记录实际读取获得的语音数据的字节数。
写入单元13,用于将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据。
所述语音遥控器读取获得语音数据后,将读取获得的语音数据写入预设数据库,所述预设数据库用于存储读取获得的语音数据,包括当前读取的语音数据和之前读取的语音数据,即所述预设数据库中的语音数据为当前读取的语音数据和之前读取的语音数据之和。具体实施中,在事件完成之后,所述预设数据库中的语音数据以及所述预设缓存区中的语音数据都会清空,便于下一次采集,当然也可以在下一次采集开始时,清空历史语音数。
在本实施例中,本发明该语音遥控器中预设有语音数据缓存区,可将用户的语音数据进行缓存,然后所述语音遥控器从所述数据缓存区中读取固定大小的语音数据,并将其写入预设数据库中,使得所述预设数据库中的语音数据为当前读取的语音数据和之前读取的语音数据之和,因此本发明能够在缓存用户的语音数据的同时,读取获得语音数据,减少采集时间。
进一步地,参照图8,基于上述第一或第二实施例可得本发明语音遥控器第三实施例的功能模块示意图,在本实施例中,所述语音遥控器还包括:
判断模块30,用于判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数;
所述语音遥控器在接收到用户触发的采集停止指令后,即所述录音按键的状态处于up状态,继续对用户的语音进行采集,所述语音遥控器从所述预设数据缓存区中读取语音数据后,判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数。
所述读取单元12,还用于若所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则返回所述读取单元,用于从所述预设数据缓存区中读取预设字节数的语音数据;
所述停止模块20,还用于若所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
所述语音遥控器通过判断发现所述预设数据库中存储的语音数据的字节数小于所述完整录音数据的字节数,则返回所述读取单元12,用于从所述预设数据缓存区中读取预设字节数的语音数据,即继续对用户的语音进行采集,然后将读取获得的语音数据写入预设数据库,所述预设数据库中存储的语音数据为当前读取的语音数据加上之前读取的语音数据,在所述预设数据库中存储的语音数据的字节数等于所述完整录音数据的字节数,则停止从所述预设数据缓存区中读取语音数据。
在本实施例中,本发明在接收到用户触发的采集停止指令后,所述语音遥控器继续从所述预设数据缓存区中读取语音数据,然后判断所述预设数据库中存储的语音数据的字节数是否等于所述完整录音数据的字节数,若等于,则停止读取,若小于,则继续读取,本方案通过在预设数据缓存区缓存语音数据和读取语音数据,并在触发停止指令时,继续读取语音数据,可快速采集用户的语音数据,也能够有效的保证录音数据的完整性。
进一步地,参照图9,基于上述第一、第二或第三实施例可得本发明语音遥控器第四实施例的功能模块示意图,在本实施例中,所述语音遥控器还包括:
获取模块40,用于获取用户触发语音采集指令的时间,记为开始时间;
所述语音遥控器接收到用户触发的数据采集指令,即所述语音遥控器中的录音按键处于down状态,此时记录用户触发语音采集指令的时间,该时间为数据采集的开始时间。
记录模块50,用于当接收到用户触发的采集停止指令,记录停止时间;
所述语音遥控器接收到用户触发的采集停止指令,即所述语音遥控器中的录音按键处于up状态,此时记录用户触发采集停止指令的时间,该时间为采集停止时间,但所述语音遥控器继续从所述预设数据缓存区中读取语音数据。
计算模块60,用于根据所述开始时间、所述停止时间和预设比特率计算获得完整录音数据的字节数。
所述所述语音遥控器获得所述开始时间、所述停止时间和预设比特率后,可根据所述开始时间、所述停止时间和预设比特率计算完整录音数据的字节数,即根据开始时间和停止时间计算获得采集时间,然后采集时间与预设比特率相乘可以得到完整录音数据的字节数。所述预设比特率可以通过多次试验获得最优值。在本实施例中,所述预设比特率为每毫秒1600字节。
在本实施例中,本发明根据采集语音数据的开始时间和停止时间可以得到采集时间,然后将所述采集时间与预设比特率相乘得到完整录音数据的字节数,在该总录音数据的字节数等于完整录音数据的字节数时,判定所述总录音数据为所述完整录音数据,本发明通过计算完整录音数据的字节数,可快速判定总录音数据的完整性,增强语音识别的准确度。
进一步地,基于上述第一、第二、第三或第四实施例可得本发明语音遥控器第五实施例,在本实施例中,所述计算模块60,用于根据所述语音遥控器中的数据采集模块从所述预设数据缓存区中读取语音数据的次数计算延迟时间;
所述判断模块30,用于判断所述延迟时间是否大于预设时间;
所述停止模块20,用于若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据。
所述语音遥控器从所述预设数据缓存区中读取语音数据的次数,根据所述次数计算延迟时间,然后判断所述延迟时间是否大于预设时间,若所述延迟时间大于所述预设时间,则停止读取所述预设数据缓存区中的语音数据,则所述所述语音遥控器判定当前的语音数据的状态为异常,并停止读取所述预设数据缓存区中的语音数据,
在本实施例中,本发明所述语音遥控器获取从所述预设数据缓存区中读取语音数据的次数,并根据该次数计算延迟时间,在该延迟时间大于所述预设时间时,停止读取所述预设数据缓存区中的语音数据,本发明通过预设时间验证延迟时间的有效性,能够在异常情况下,立即停止采集语音,不会造成时间的浪费。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!