信息处理设备、信息处理方法及程序与流程
本公开内容涉及信息处理设备、信息处理方法及程序。
背景技术:
近来,已经存在用于对通过麦克风采集的声音信息执行语音识别处理以从声音信息获得语音识别处理结果的技术(例如,参见专利文献1)。在一个示例中,根据预定的显示模式将通过语音识别处理获得的语音识别处理结果显示在显示设备上。
引用列表
专利文献
专利文献1:jp2013-025605a
技术实现要素:
技术问题
然而,仅通过视觉地识别语音识别处理结果,用户难以直观地了解语音识别处理执行的情况。因此,需要提供一种能够使用户直观地了解执行语音识别处理的情况的技术。
问题的解决方案
根据本公开内容,提供了一种信息处理设备,包括:信息获取单元,该信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及输出单元,该输出单元被配置成基于根据所述参数而指定的显示模式来输出显示信息,该显示信息用于显示该声音信息的语音识别处理结果。
根据本公开内容,提供了一种信息处理方法,该方法包括:获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及由处理器基于根据参数而指定的显示模式来输出显示信息,该显示信息用于显示该声音信息的语音识别处理结果。
根据本公开内容,提供了一种用于使计算机用作信息处理设备的程序,该信息处理设备包括:信息获取单元,该信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及输出单元,该输出单元被配置成基于根据参数而指定的显示模式来输出显示信息,该显示信息用于显示声音信息的语音识别处理结果。
本发明的有益效果
如上所述,根据本公开内容提供了一种能够使用户直观地了解执行语音识别处理的情况的技术。注意,上述效果不一定是限制性的。与上述效果一起或取代上述效果,还可以实现在本说明书中描述的任一效果或者通过本说明书能够领会的其他效果。
附图说明
[图1]是示出了根据本公开内容的实施方式的通信系统的配置示例的图。
[图2]是示出了根据本实施方式的信息处理系统的功能配置示例的框图。[图3]是被示出以描述信息处理系统的概况的图。
[图4]是被示出以描述将包括在声音信息中的用户的发声音量用作为与语音识别处理有关的参数的情况以及将文本的大小用作为根据该参数而指定的显示模式的情况的图。
[图5]是被示出以描述将包括在声音信息中的噪声量用作为参数的情况以及将文本的破裂度用作为根据该参数而指定的显示模式的情况的图。
[图6]是被示出以描述将包括在声音信息中的噪声量用作为参数的情况以及将文本的模糊度用作为根据该参数而指定的显示模式的情况的图。
[图7]是被示出以描述将包括在声音信息中的噪声量用作为参数的情况以及将添加至文本的对象的类型用作为根据该参数而指定的显示模式的情况的图。
[图8a]是被示出以描述将噪声方向用作为参数的情况以及将文本的模糊度用作为根据该参数而指定的显示模式的情况的图。
[图8b]是被示出以描述将噪声方向用作为参数的情况以及将文本的模糊度用作为根据该参数而指定的显示模式的情况的图。
[图9a]是被示出以描述将包括在声音信息中的噪声的类型用作为参数的情况以及将添加到文本的对象的类型用作为根据该参数而指定的显示模式的情况的图。
[图9b]是被示出以描述将包括在声音信息中的噪声的类型用作为参数的情况以及将添加到文本的对象的类型用作为根据该参数而指定的显示模式的情况的图。
[图9c]是被示出以描述将包括在声音信息中的噪声的类型用作为参数的情况以及将添加到文本的对象的类型用作为根据该参数而指定的显示模式的情况的图。
[图10]是示出了在将声音采集单元所采集的基于声音信息的预定数据用作为参数的情况下所指定的文本的显示模式的示例的图。
[图11]是示出了在将通过对图像输入单元所输入的输入图像进行分析而获得的结果用作为参数的情况下所指定的文本的显示模式的示例的图。
[图12]是示出了在将通过对生物信息输入单元所输入的生物信息进行分析而获得的结果用作为参数的情况下所指定的文本的显示模式的示例的图。
[图13]是示出了显示模式基于用户的改变操作而改变的示例的图。
[图14]是示出了信息处理系统的操作示例的流程图。
[图15]是被示出以描述信息处理系统的发送显示信息的功能的图。
[图16]是被示出以描述信息处理系统的接收显示信息的功能的图。
[图17]是示出了在用户的专注水平超过阈值的情况下所发送的显示信息的示例的图。
[图18]是示出了在用户没有视觉地识别聊天画面的情况下所发送的显示信息的示例的图。
[图19]是示出了在用户使用信息处理系统的情况下所发送的显示信息的示例的图。
[图20a]是示出了在用户的行为信息指示用户正在跑步的情况下被添加至文本的对象的示例的图。
[图20b]是示出了在用户的环境信息指示周围有人的情况下被添加至文本的对象的示例的图。
[图20c]是示出了在用户的行为信息指示用户正在开车的情况下被添加至文本的对象的示例的图。
[图21]是示出了根据本实施方式的信息处理系统的硬件配置示例的框图。
具体实施方式
在下文中,将参照附图详细地描述本公开内容的一种或多种优选实施方式。在本说明书和附图中,使用相同的附图标记来表示具有基本上相同功能和结构的结构元件,并且省略对这些结构元件的重复说明。
注意,在本说明书和附图中,有时使用相同附图标记之后的不同数字来区分具有基本相同功能和结构的结构元件。然而,当不需要特别区分具有基本相同功能和结构的结构元件时,只附上相同的附图标记。
此外,将按以下顺序给出描述。
1.本公开内容的实施方式
1.1.系统配置示例
1.2.功能配置示例
1.3.信息处理系统的功能的详情
1.4.修改
1.5.硬件配置示例
2.结论
<1.本公开内容的实施方式>
[1.1.系统配置示例]
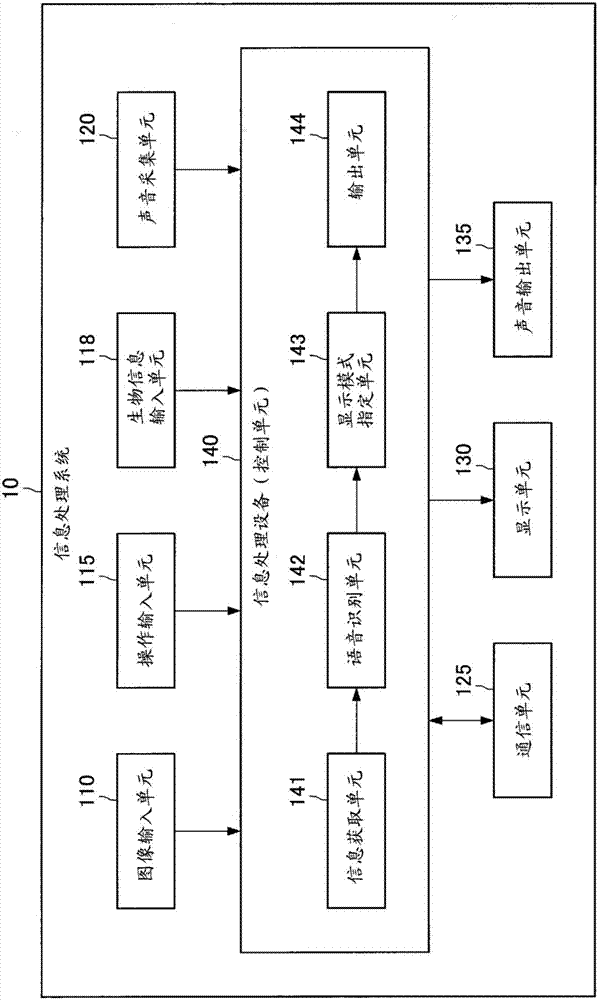
将参照附图来描述根据本公开内容的实施方式的通信系统的配置示例。图1是示出了根据本公开内容的实施方式的通信系统的配置示例的图。如图1所示,根据本实施方式的通信系统被配置成包括信息处理系统10-1和信息处理系统10-2。信息处理系统10-1和信息处理系统10-2中的每一个被配置成包括图像输入单元110、操作输入单元115、生物信息输入单元118、声音采集单元120、显示单元130、声音输出单元135以及信息处理设备(以下还称为“控制单元”)140。
信息处理系统10-1中的信息处理设备140可以经由网络931与信息处理系统10-2中的信息处理设备140通信。此外,在信息处理系统10中,图像输入单元110、声音采集单元120以及声音输出单元135被设置在显示单元130的框架上。然而,图像输入单元110、声音采集单元120以及声音输出单元135被设置的位置并不受限制。可以将图像输入单元110、声音采集单元120以及声音输出单元135设置在不同于显示单元130的框架的位置处,或者可以设置在不同于显示单元130的位置处(例如,操作输入单元115处),并且可以将声音采集单元120所采集的声音信息发送至信息处理设备140。
此外,在图1所示的示例中,信息处理设备140是游戏控制台,但是信息处理设备140的形式不限于游戏控制台。在一个示例中,信息处理设备140可以是智能电话、移动电话、平板电脑终端或个人电脑(pc)。在下面的描述中,在本文中彼此区分地使用术语语音(或话音)和声音。
以上描述了根据本实施方式的通信系统的配置示例。
[1.2.功能配置示例]
接下来,描述根据本实施方式的信息处理系统10的功能配置示例。图2是示出了根据本实施方式的信息处理系统10的功能配置示例的框图。如图2所示,信息处理系统10被配置成包括图像输入单元110、操作输入单元115、生物信息输入单元118、声音采集单元120、通信单元125、显示单元130、声音输出单元135以及控制单元140。
图像输入单元110具有输入图像的功能。在一个示例中,图像输入单元110包括相机,并且接收由相机拍摄的图像作为输入。图像输入单元110中包括的相机的数量不限于特定数量,只要该数量为一个或多个即可。图像输入单元110中包括的一个或多个相机中的每一个被设置的位置也不限于特定位置。此外,一个或多个相机的示例可以包括单目相机或立体相机。
操作输入单元115具有输入用户操作的功能。在一个示例中,操作输入单元115可以包括游戏控制台的控制器。此外,操作输入单元115可以具有输入用户操作的功能,因此可以包括触摸板。触摸板所采用的类型的示例可以包括但不限于静电电容型、电阻膜型、红外型或超声型。此外,操作输入单元115可以被配置成包括相机。
生物信息输入单元118具有输入用户的生物信息的功能。在一个示例中,在生物信息输入单元118设置有压力传感器的情况下,能够使用压力传感器来输入由用户持握的控制器的持握压力作为生物信息。此外,在生物信息输入单元118设置有心跳传感器的情况下,能够使用该心跳传感器来输入用户的心跳作为生物信息。此外,在生物信息输入单元118设置有汗液传感器的情况下,能够使用该汗液传感器来输入用户的排汗率作为生物信息。此外,在本实施方式中,主要描述了将生物信息输入单元118设置在游戏控制台的控制器中的情况,但是可以将生物信息输入单元118设置在可穿戴设备中。
声音采集单元120具有通过声音采集来获得声音信息的功能。正如参考图1所描述的,可以将声音采集单元120设置在显示单元130的框架上,但是也可以设置在不同于显示单元130的框架的位置处,或者可以设置在不同于显示单元130的位置处(例如,操作输入单元115处)。声音采集单元120中包括的麦克风的数量不限于特定数量,只要该数量为一个或多个即可。此外,声音采集单元120中包括的一个或多个麦克风中的每一个被设置的位置也不限于特定位置。
然而,在声音采集单元120设置有多个麦克风的情况下,可以基于多个麦克风中的每一个进行的声音采集所获得的声音信息来估计声音的到达方向。替选地,在声音采集单元120设置有定向麦克风的情况下,可以基于定向麦克风进行的声音采集所获得的声音信息来估计声音的到达方向。
控制单元140对信息处理系统10的每个部件执行控制。如图2所示,控制单元140被配置成包括信息获取单元141、语音识别单元142、显示模式指定单元143以及输出单元144。后面将描述这些功能块中的每一个的详情。此外,控制单元140可以由例如中央处理单元(cpu)构成。在信息处理设备140由诸如cpu的处理设备构成的情况下,该处理设备可以由电子电路构成。
通信单元125具有与另一信息处理系统10通信的功能。在一个示例中,通信单元125由通信接口构成。在一个示例中,通信单元125可以经由网络931与该另一信息处理系统10通信。
显示单元130具有显示画面的功能。在一个示例中,显示单元180可以是液晶显示器、有机电致发光(el)显示器或头戴式显示器(hmd)。然而,显示单元180可以是其他形式的显示器,只要其具有显示画面的功能即可。
声音输出单元135具有输出声音信息的功能。在一个示例中,声音输出单元135可以是扬声器、头戴式耳机或耳机。然而,声音输出单元135可以是其他形式的声音输出设备,只要其具有输出声音信息的功能即可。
以上描述了根据本实施方式的信息处理系统10的功能配置示例。
[1.3.信息处理系统的功能的详情]
接下来,将详细描述信息处理系统10的功能。图3是被示出以描述信息处理系统10的概况的图。参照图3,视频图像显示画面131位于显示单元130中,在视频图像显示画面131上显示有通过控制单元140再现的视频图像。这里,控制单元140被设想为游戏控制台,因此显示在视频图像显示画面131上的视频图像可以是游戏应用中包括的视频图像。
此外,参照图3,由控制单元140来执行用于使信息处理系统10-1的用户u1能够与信息处理系统10-2的用户聊天的聊天应用,并且由显示单元130来显示该聊天应用的执行画面作为聊天画面134。参照图3,将通过对以下声音信息执行语音识别处理而获得的语音识别处理结果“hello”显示在信息处理系统10-1的聊天画面134上:该声音信息包括信息处理系统10-2的用户“约翰”的发声。语音识别处理结果可以是通过对声音信息进行语音识别处理而获得的单字符数据,或者是其中排列了多个字符的字符串数据。本文使用术语“文本”作为语音识别处理结果的示例。
另一方面,作为信息处理系统10-1的声音采集单元120所采集的声音信息的语音识别处理结果的示例,显示有文本的发声画面133也位于显示单元130中。发声画面133显示用于开始语音识别处理的语音识别处理开始按钮132。此外,发声画面133显示文本tx-10“hello”作为信息处理系统10-1的声音采集单元120所采集的声音信息的语音识别处理结果的示例。
在一个示例中,可以将文本tx-10添加至聊天画面134。此外,可以将文本tx-10发送至信息处理系统10-2的控制单元140,并且可以在信息处理系统10-2的聊天画面上显示。在这里,仅通过视觉地识别文本tx-10,用户u1难以直观地了解语音识别处理执行的情况。因此,需要提供一种能够使用户u1直观地了解语音识别处理执行的情况的技术。
更具体地,在本公开内容的实施方式中,当用户u1执行用于选择语音识别处理开始按钮132的操作(以下还称为“识别开始操作”)时,操作输入单元115输入该识别开始操作,并且用户u1开始发声。当声音采集单元120采集到声音信息时,信息获取单元141获取由声音采集单元120采集的声音信息。此外,在本实施方式中,由声音采集单元120采集的信号指的是声音信息,但是声音信息可以是通过对声音采集单元120所采集的信号执行任意种类的信号处理而获得的信号。
然后,当通过语音识别单元142执行语音识别处理而获得文本tx-10时,显示模式指定单元143根据与对声音信息的语音识别处理有关的参数来指定文本tx-10的显示模式。后面将对这种参数的详情进行描述。输出单元144根据指定的显示模式来输出用于显示文本tx-10的显示信息。显示信息可以包括文本和指示显示模式的显示模式信息。此外,尽管显示信息的输出目的地不受限制,但是当显示信息被输出至显示单元130时,显示单元130可以基于该显示信息在发声画面133上显示取决于这样的显示模式的文本tx-10。
以这种方式,在本公开内容的实施方式中,根据与语音识别处理有关的参数来指定文本tx-10的显示模式,并且根据这种显示模式来输出用于显示文本tx-10的显示信息。该配置使得用户u1能够根据文本tx-10的显示模式来直观地了解语音识别处理执行的情况。在下文中,作为示例,将描述针对每个词来指定显示模式的情况,但是指定显示模式的单位不限于特定单位。在一个示例中,可以针对每个短语或每个句子来指定显示模式。
此外,与语音识别处理有关的参数不限于特定参数,而是可以包括例如在声音采集单元120所采集的声音信息中包括的用户u1的发声信息。此外,根据参数而指定的显示模式不限于特定模式,并且可以包括以下中的至少一个:文本tx-10的大小、形状、饱和度、字体、模糊度、以及破裂度、被添加至文本tx-10的动画图像的类型、以及被添加至文本tx-10的对象的类型。
下面将描述这种参数以及根据该参数而指定的显示模式的示例。图4是被示出以描述将包括在声音信息中的用户(图3所示的用户u1)的发声音量用作为与语音识别处理有关的参数的情况以及将文本(图3所示的文本tx-10)的大小用作为根据该参数而指定的显示模式的情况的图。参照图4,沿水平轴示出了用户的发声音量以及根据该发声音量而指定的文本“hello”的大小。
如图4所示,显示模式指定单元143可以随着发声音量在从预定下限音量到预定上限音量的范围内增大而增大文本“hello”的大小。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的发声音量。另一方面,在发声音量下降至预定下限音量之下的情况下,显示模式指定单元143可以将文本“hello”的大小设置成固定值。此外,在发声音量超过预定上限音量的情况下,显示模式指定单元143可以将文本“hello”的大小设置成固定值。
此外,参数可以包括与用户的发声相对应的噪声有关的信息,与噪声有关的信息包括在由声音采集单元120所采集的声音信息中。与噪声有关的信息不限于特定类型,并且与噪声有关的信息的示例可以包括噪声的类型、噪声的音量(以下还称为“噪声量”)、以及从噪声源到声音采集单元120的方向(以下还称为“噪声方向”)。图5是被示出以描述将包括在声音信息中的噪声量用作为参数的情况以及将文本(图3所示的文本tx-10)的破裂度用作为根据该参数而指定的显示模式的情况的图。
参照图5,沿水平轴示出了噪声量以及根据该噪声量而指定的文本“hello”的破裂度。如图5所示,显示模式指定单元143可以随着噪声量的增大而增大文本“hello”的破裂度。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的噪声量。
图6是被示出以描述将包括在声音信息中的噪声量用作为图7的参数的情况以及将文本(图3所示的文本tx-10)的模糊度指定为取决于该参数的显示模式的情况的图。参照图6,沿水平轴示出了噪声量以及根据该噪声量而指定的文本“hello”的模糊度。如图6所示,显示模式指定单元143可以随着噪声量的增大而增大文本“hello”的模糊度。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的噪声量。
图7是被示出以描述将包括在声音信息中的噪声量用作为参数的情况以及将添加至文本(图3所示的文本tx-10)的对象的类型用作为根据该参数而指定的显示模式的情况的图。参照图7,沿水平轴示出了噪声量以及根据该噪声量而指定的对象bj的类型。
如图7所示,在噪声量处于从预定上限噪声量到预定下限噪声量的范围内的情况下,显示模式指定单元143可以指定对象bj-22作为要添加至文本“hello”的对象。此外,在噪声量超过预定上限噪声量的情况下,显示模式指定单元143可以指定对象bj-21作为要添加至文本“hello”的对象。此外,在噪声量下降到预定下限噪声量之下的情况下,显示模式指定单元143可以指定对象bj-23作为要添加至文本“hello”的对象。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的噪声量。
此外,尽管图7示出了将对象bj-21至对象bj-23添加至文本“hello”的末尾的示例,但是对象bj-21至对象bj-23被添加的位置不限于文本“hello”的末尾。在一个示例中,可以将对象bj-21至对象bj-23添加至文本“hello”的开头。此外,在这里,设想对象bj-21至对象bj-23是静态图像,但是对象bj-21至bj-23可以是任何数据。在一个示例中,对象bj-21至对象bj-23可以是运动图像或者可以是文本数据。
图8a和图8b是被示出以描述将噪声方向用作为参数的情况以及将文本(图3所示的文本tx-10)的模糊度用作为根据该参数而指定的显示模式的情况的图。参照图8a和图8b,示出了噪声方向以及根据噪声方向而指定的文本“hello”的模糊度。
如图8a所示,在噪声方向是从屏幕的左侧至右侧的情况下,显示模式指定单元143可以使文本“hello”左侧的模糊度大于右侧的模糊度。替选地,如图8b所示,在噪声方向是从屏幕的上侧至下侧的情况下,显示模式指定单元143可以使文本“hello”上侧的模糊度大于下侧的模糊度。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的噪声方向。
图9a、图9b和图9c是被示出以描述将包括在声音信息中的噪声的类型用作为参数的情况以及将被添加到文本(图3所示的文本tx-10)的对象的类型用作为根据该参数而指定的显示模式的情况的图。参照图9a至图9c,尽管根据噪声量而指定的对象bj-21被添加至文本“hello”,然而不一定要将根据噪声量而指定的对象bj-21添加至文本“hello”。
如图9a所示,在噪声的类型是来自火车的噪声的情况下,显示模式指定单元143可以指定对象bj-31作为要添加至文本“hello”的对象。此外,在噪声的类型是来自电视设备的噪声的情况下,显示模式指定单元143可以指定对象bj-32作为要添加至文本“hello”的对象。此外,在噪声的类型是人类声音的情况下,显示模式指定单元143可以指定对象bj-33作为要添加至文本“hello”的对象。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的噪声类型。
此外,尽管图9a、图9b和图9c示出了将对象bj-31至对象bj-33添加至文本“hello”的末尾的示例,但是对象bj-31至bj-33被添加的位置不限于文本“hello”的末尾。在一个示例中,可以将对象bj-31至对象bj-33添加至文本“hello”的开头。此外,在这里,设想对象bj-31至对象bj-33是静态图像,但是对象bj-31至bj-33可以是任何数据。在一个示例中,对象bj-31至对象bj-33可以是运动图像或者可以是文本数据。
尽管以上详细描述了参数以及根据参数而指定的显示模式的一些示例,但是参数以及根据参数而指定的显示模式不限于以上描述的示例。参数(用户u1的发声信息)的示例可以包括以下中的至少一个:包括在声音信息中的用户u1的发声音量、声音信息的语音相似度、声音信息的频率、包括在声音信息中的语音的发声速度、包括在声音信息中的与语音的词尾有关的信息、以及文本的置信度水平。
此外,所述显示模式是进一步基于与用户u1有关的信息来指定的。在这里,与用户u1有关的信息不限于特定信息,并且与用户u1有关的信息可以包括用户u1的生物信息和情感信息中的至少一个。可以由生物信息输入单元118来输入生物信息。用户u1的生物信息不限于特定信息,并且用户u1的生物信息可以包括由用户u1持握的控制器的持握压力、用户u1的排汗、以及用户u1的心跳中的至少一个。
可以以任何方式获得用户u1的情感信息。在一个示例中,可以通过显示模式指定单元143对声音信息或输入图像进行分析来获得用户u1的情感信息。此外,用户u1的情感信息不限于特定信息,并且用户u1的情感信息可以包括用户u1的喜悦、惊奇、以及愤怒中的至少一个。替选地,用户u1的情感信息可以包括其他情感。
此外,与用户u1有关的信息可以包括用户u1的性别和年龄中的至少一个。可以以任何方式获得用户u1的性别和年龄。在一个示例中,可以通过显示模式指定单元143对输入图像进行分析来获得用户u1的性别和年龄。年龄可以是以预定单位来指示年龄的数据,例如,以十年为单位来指示年龄的数据。
图10是示出了在将基于声音采集单元120所采集的声音信息的预定数据用作参数的情况下所指定的文本(图3所示的文本tx-10)的显示模式的示例的图。在一个示例中,如图10所示,显示模式指定单元143可以基于包括在声音采集单元120所采集的声音信息中的用户u1的发声音量来控制文本的大小。
此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息的语音相似度(语音音量或噪声音量)来控制文本的模糊度、文本的破裂度、或要添加至文本的对象的类型。此外,显示模式指定单元143可以基于包括在声音采集单元120所采集的声音信息中的噪声量来控制文本的模糊度、文本的破裂度、或要添加至文本的对象的类型。
此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息中包括的噪声方向来控制文本的模糊部分。此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息的频率分布(声音的音调)来控制文本的饱和度。
此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息中包括的语音的发声速度来指定要添加至文本的动画图像。在一个示例中,在语音采集单元120所采集的声音信息中包括的语音的发声速度超过预定上限速度的情况下,显示模式指定单元143可以指定闪烁动画图像作为要添加至文本的动画图像。此外,在一个示例中,在语音采集单元120所采集的声音信息中包括的语音的发声速度降低到预定下限速度之下的情况下,显示模式指定单元143可以指定3d动画图像作为要添加至文本的动画图像。
此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息中包括的对语音的语音识别处理的置信度水平(文本的置信度水平)来控制文本的透明度。在一个示例中,显示模式指定单元143可以随着置信度水平的降低而增大文本“hello”的透明度。这使得用户可以直观地了解作为语音识别处理执行的情况的示例的、语音识别处理的置信度水平。
此外,显示模式指定单元143可以基于声音采集单元120所采集的声音信息中包括的与语音的词尾有关的信息来指定要添加至文本的动画图像。在一个示例中,在语音采集单元120所采集的声音信息中包括的语音的词尾的延伸时间超过预定时间的情况下,显示模式指定单元143可以指定在左右方向上移动的动画图像作为要添加至文本的动画图像。
此外,在通过对声音信息进行分析而获得的情感信息指示喜悦的情况下,显示模式指定单元143可以控制显示模式,使得将预定对象添加至文本的末尾。此外,在通过对声音信息进行分析而获得的情感信息指示惊奇的情况下,显示模式指定单元143可以控制显示模式,使得将预定符号(例如“!”)和预定对象添加至文本的末尾。此外,在通过对声音信息进行分析而获得的情感信息指示愤怒的情况下,显示模式指定单元143可以控制显示模式,使得文本的颜色变成预定颜色(例如红色)并且将预定对象添加至文本的末尾。
图11是示出了在以下情况下所指定的文本(图3所示的文本tx-10)的显示模式的示例的图:将通过对图像输入单元所输入的输入图像进行分析而获得的结果用作为参数的情况。如图11所示,在通过对输入图像进行分析而获得的情感信息指示喜悦的情况下,显示模式指定单元143可以控制显示模式,使得将预定对象添加至文本的末尾。
此外,在通过对输入图像进行分析而获得的情感信息指示惊奇的情况下,显示模式指定单元143可以控制显示模式,使得将预定符号(例如“!”)和预定对象添加至文本的末尾。此外,在通过对输入图像进行分析而获得的情感信息指示愤怒的情况下,显示模式指定单元143可以控制显示模式,使得文本的颜色变成预定颜色(例如红色)并且将预定对象添加至文本的末尾。
此外,显示模式指定单元143可以根据通过对输入图像进行分析而获得的性别来控制文本的字体(例如字符风格)。此外,显示模式指定单元143可以根据通过对输入图像进行分析而获得的年龄来控制文本的颜色。此外,显示模式指定单元143可以根据通过对输入图像进行分析而获得的用户u1的专注水平(或兴奋水平)来控制文本的颜色、文本的大小或要添加至文本末尾的对象。
图12是示出了在以下情况下所指定的文本(图3所示的文本tx-10)的显示模式的示例的图:将通过对生物信息输入单元118所输入的生物信息进行分析而获得的结果用作为参数的情况。如图12所示,显示模式指定单元143可以根据通过对生物信息进行分析而获得的用户u1的专注水平(或兴奋水平)来控制文本的颜色、文本的大小或要添加至文本末尾的对象。
设想的是专注水平可以根据各种类型的生物信息而不同。因此,用于计算专注水平的生物信息可以包括以下中的至少一个:用户u1的体温、排汗量、脉搏率、呼吸率、眨眼率、眼睛运动、注视持续时间、瞳孔直径的大小、血压、脑波、身体运动、身体姿势、皮肤温度、皮肤电阻(galvanicskinresistance)、微振动(mv)、肌电位(myoelectricpotential)和spo2(血液氧饱和度水平)。
此外,显示模式指定单元143可以基于控制器的持握压力来控制文本的大小。在一个示例中,与持握压力小于预定压力的情况相比,在控制器的持握压力大于预定压力的情况下,显示模式指定单元143可以增大文本的大小。此外,在用户u1的排汗量超过预定上限排汗量的情况下,显示模式指定单元143可以控制显示模式,使得将预定对象添加至文本的末尾。
此外,显示模式指定单元143可以控制显示模式,使得根据用户u1的心率将运动动画图像添加至文本。在一个示例中,显示模式指定单元143可以控制显示模式,使得将以下动画图像添加至文本:该动画图像的运动随着用户u1的心率的增大而增大。
以上描述了参数以及根据参数而指定的显示模式的示例。以这种方式指定的显示模式可以是用户u1不可改变的,但是考虑到用户u1的方便性,可以优选地基于用户u1的预定改变操作来改变。改变操作不限于特定一种操作,并且改变操作可以是按压或轻敲与显示模式对应的按钮的操作。
图13是示出了基于用户u1的改变操作来改变显示模式的示例的图。参照图13,作为对用户u1的发声的语音识别处理结果的示例,在发声画面133-1上显示有大尺寸的文本tx-21“我正在打游戏”。此外,作为根据参数而指定的显示模式,在发声画面133-1上还显示有“红色”、“大尺寸”、“滑入”以及“3d”。
这里,设想用户u1想要减小文本tx-21“我正在打游戏”的大小。在这种情况下,用户u1可以按压或轻敲作为显示模式的示例的“大尺寸”。然后,按压或轻敲“大尺寸”的操作由操作输入单元115输入,并且显示模式指定单元143取消作为文本tx-21“我正在打游戏”的显示模式的“大尺寸”。作为结果,在发声画面133-2上显示小尺寸文本tx-22“我正在打游戏”。
现在将描述信息处理系统10-1的操作示例。图14是示出了信息处理系统10-1的操作示例的流程图。图14所示的流程图示出了信息处理系统10-1的示例性操作。因此,信息处理系统10-1的操作不限于该示例。当用户u1执行识别开始操作时,通过操作输入单元115来输入该识别开始操作,并且用户u1开始发声。当声音采集单元120采集声音信息时,信息获取单元141获取由声音采集单元120所采集的声音信息。
然后,如果通过使语音识别单元142对声音信息执行语音识别处理而获得文本(步骤s11),则操作进行至步骤s19。另一方面,显示模式指定单元143通过对图像输入单元110所输入的输入图像进行图像分析来获取图像分析结果(步骤s12),并且获取与该图像分析结果对应的显示模式信息(步骤s13)。如果获取到与图像分析结果对应的显示模式信息,则操作进行至步骤s19。
此外,显示模式指定单元143通过对声音采集单元120所采集的声音信息进行声音分析来获取声音分析结果(步骤s14),并且获取与该声音分析结果对应的显示模式信息(步骤s15)。如果获取到与声音分析结果对应的显示模式信息,则操作进行至步骤s19。此外,显示模式指定单元143通过分析生物信息输入单元118所输入的生物信息来估计用户的状态(步骤s17),并且获取与用户的状态对应的显示模式信息(步骤s18)。如果获取到与用户的状态对应的显示模式信息,则操作进行至步骤s19。
接下来,显示模式指定单元143基于获取的显示模式信息来控制通过语音识别处理而获得的文本(步骤s19)。由显示模式指定单元143控制的文本被通知给应用(例如聊天应用)(步骤s20)并且在该应用中使用。在将文本用于聊天应用中的情况下,可以将显示模式指定单元143以这种方式控制的文本(即,包括文本和显示模式信息的显示信息)发送至用户u2的信息处理系统10-2。
以上主要描述了用户u1的信息处理系统10-1中的操作。然而,如上所述,当聊天应用被启动时,可以将信息处理系统10-1中的显示模式指定单元143所控制的文本(即,包括文本和显示模式信息的显示信息)发送至用户u2的信息处理系统10-2。因此,在下面的描述中,将主要描述信息处理系统10-1和信息处理系统10-2之间的合作。
图15是被示出以描述信息处理系统10-1的发送显示信息的功能的图。参照图15,与图3所示的示例相似,显示单元130具有视频图像显示画面131,但是不同的是,用户u1正在玩游戏,因此在视频图像显示画面131上显示有游戏应用中包括的视频图像。
此外,作为信息处理系统10-1的声音采集单元120所采集的声音信息的语音识别处理结果的示例,在发声画面133上显示有具有与声音信息的音量对应的大小的文本tx-21“我正在打游戏”,并且与用户u1的专注水平对应的对象bj-10被添加至文本tx-21。以这种方式显示的文本tx-21以及显示模式信息(例如大小以及对象bj-10)被作为显示信息发送至信息处理系统10-2。
图16是被示出以描述信息处理系统10-2的接收显示信息的功能的图。参照图16,用户u2对操作输入单元115进行操作。如图16所示,当信息处理系统10-2从信息处理系统10-1接收到作为显示信息的文本tx-21和显示模式信息(例如大小和对象bj-10)时,在聊天画面134上显示添加有对象bj-10的文本tx-21。以这种方式,信息处理系统10-1中的输出单元144能够输出显示信息,使得用户u2能够根据显示模式指定单元143所指定的显示模式来视觉地识别文本。
以上描述了信息处理系统10-1中的输出单元144输出显示信息使得用户u2能够根据显示模式指定单元143所指定的显示模式来视觉地识别文本tx-21的示例。然而,信息处理系统10-1中的输出单元144可以切换是否输出显示信息以使得用户u2能够根据显示模式指定单元143所指定的显示模式来视觉地识别文本。在一个示例中,信息处理系统10-1中的输出单元144可以基于用户u2的状态来切换是否输出显示信息以使得用户u2能够根据显示模式指定单元143所指定的显示模式来视觉地识别文本。
在一个示例中,在用户u2的状态处于预定状态的情况下,信息处理系统10-1的输出单元144可以输出显示信息以使得用户u2能够根据与显示模式指定单元143所指定的显示模式不同的另一显示模式来视觉地识别文本。图17是示出了在用户u2的专注水平超过阈值的情况下发送的显示信息的示例的图。在如图17所示的示例中,用户u2专注于显示在视频图像显示画面131上的视频图像,因此设想用户u2的专注水平超过阈值。
在这种情况下,信息处理系统10-1中的输出单元144除了显示模式指定单元143所指定的显示模式之外还添加预定动画图像,然后输出文本tx-21以及显示模式信息(例如预定动画图像、大小和对象bj-10)。然后,如图17所示,将添加有预定动画图像(图17所示示例中的闪烁动画图像)的文本tx-21显示在信息处理系统10-2中,从而用户u2可以容易地注意到文本tx-21。
图18是示出了在用户u2未视觉地识别到聊天画面134的情况下发送的显示信息的示例的图。在如图18所示的示例中,设想用户u2没有视觉地识别聊天画面134。在这种情况下,信息处理系统10-1中的输出单元144可以除了发送显示模式指定单元所指定的显示模式之外还发送预定声音。然后,如图18所示,在信息处理系统10-2中,声音输出单元135输出所接收到的声音(在图18所示的示例中,通过读取文本tx-21“我正在打游戏”而获得的语音),从而用户u2可以容易地注意到文本tx-21。
此外,可以通过对信息处理系统10-2中的图像输入单元110所输入的输入图像进行分析来确定用户u2是否视觉地识别到聊天画面134。可以在信息处理系统10-1或信息处理系统10-2中执行对输入图像的分析。
此外,信息处理系统10-1中的输出单元144可以基于用户u1与信息处理系统10-2的用户u2之间的关系来切换是否输出显示信息以使得信息处理系统10-2的用户u2能够根据显示模式指定单元143所指定的显示模式来视觉地识别文本。图19示出了在用户u3使用信息处理系统10-2的情况下所发送的显示信息的示例的图。在图19所示的示例中,设想用户u3正在使用信息处理系统10-2。在一个示例中,设想与用户u1具有家庭关系的用户u3在使用信息处理系统10-2。
在这种情况下,信息处理系统10-1中的输出单元144可以将预定显示模式(例如大小)排除在由显示模式指定单元143指定的显示模式之外,然后可以发送文本tx-21以及显示模式信息(例如对象bj-10)。通过这么做,如图19所示,将文本tx-21中不由预定显示模式(图19所示的示例中的大小)控制的文本(添加有正常大小的对象bj-10的文本)显示在信息处理系统10-2中。另一方面,如图16所示,在与用户u1具有好朋友关系的用户u2使用信息处理系统10-2的情况下,信息处理系统10-1中的输出单元144可以发送所有文本tx-21和显示模式信息(例如大小和对象bj-10)。通过这么做,如图16所示,将文本tx-21中由显示模式(图16所示示例中的大小和对象bj-10)所控制的文本(添加有大于正常大小的对象bj-10的文本)显示在信息处理系统10-2中。这可以使在用户u2和用户u3之间视觉地识别的文本的显示模式不同。
此外,可以预先针对每个用户或针对该用户所属的每个组(例如朋友、领导、好朋友、及家庭成员)来登记要发送的显示模式信息,并且可以基于以该方式预先登记的显示模式信息来确定要发送的显示模式信息。替选地,可以由用户u1来指定要发送的显示模式信息,并且可以基于用户u1所指定的显示模式信息来确定要发送的显示模式信息。可以由信息处理系统10-1中的显示模式指定单元143来确定要发送的显示模式信息。
以上描述了信息处理系统10-1与信息处理系统10-2之间的合作。
[1.4.修改]
如上所述,可以基于与用户u1有关的信息来进一步指定显示模式。在这里,如上所述,与用户u1有关的信息不限于特定信息。在一个示例中,与用户u1有关的信息包括以下中的至少一个:用户u1的行为信息、用户u1所操作的设备的类型、以及用户u1周围的环境信息。可以以任何方式来获得行为信息,比如可以通过对用户u1所持有的设备的位置信息进行分析来获得行为信息。此外,可以以任何方式来获得环境信息,比如可以通过对在用户u1附近采集的声音信息进行分析来获得环境信息。
图20a是示出了在用户u1的行为信息指示用户正在跑步的情况下被添加至文本的对象的示例的图。如图20a所示,在获得指示用户u1正在跑步的行为信息的情况下,可以添加与文本tx-31对应的对象bj-41。
图20b是示出了在用户u1的环境信息指示周围有人的情况下被添加至文本的对象的示例的图。如图20b所示,在获得指示用户u1周围有人的环境信息的情况下,可以添加与文本tx-32对应的对象bj-42。
图20c是示出了在用户u1的行为信息指示用户正在开车的情况下被添加至文本的对象的示例的图。如图20c所示,在获得指示用户u1正在开车的行为信息的情况下,可以添加与文本tx-33对应的对象bj-43。
[1.5.硬件配置示例]
下面将参照图21来描述根据本公开内容的实施方式的信息处理系统10的硬件配置。图21是示出了根据本公开内容的实施方式的信息处理系统10的硬件配置示例的框图。
如图21所示,信息处理系统10包括中央处理单元(cpu)901、只读存储器(rom)903以及随机存取存储器(ram)905。此外,信息处理系统10可以包括主机总线907、桥909、外部总线911、接口913、输入设备915、输出设备917、存储设备919、驱动921、连接端口923和通信设备925。根据需要,信息处理系统10还可以包括图像捕获设备933和传感器935。连同cpu901一起或取代cpu901,信息处理系统10可以具有被称为数字信号处理器(dsp)或专用集成电路(asic)的处理电路。
cpu901用作算术处理单元和控制设备,并且根据存储在rom903、ram905、存储设备919或可移动存储介质927中的各种程序来控制信息处理系统10的总体操作或部分操作。rom903存储例如由cpu901使用的程序和操作参数。ram905临时存储例如在cpu901的运行中使用的程序和在执行该程序中适当改变的参数。cpu901、rom903和ram905经由主机总线907彼此连接,主机总线907由诸如cpu总线的内部总线构成。此外,主机总线907经由桥909连接至诸如外围设备互连(pci)/接口总线的外部总线911。
输入设备915例如是由用户操作的设备,如鼠标、键盘、触摸板、按钮、开关和操作杆。输入设备915可以包括用于检测用户声音的麦克风。输入设备915可以是例如使用红外线或其他无线电波的远程控制设备,或者可以是符合信息处理系统10的操作的外部连接设备929,如蜂窝电话。输入设备915包括基于用户输入的信息来生成输入信号并将该输入信号输出至cpu901的输入控制电路。用户将各种数据输入至信息处理系统10,并且通过操作输入设备915来指示信息处理系统10进行处理操作。此外,后面将描述的图像捕获设备933通过捕获用户的手或手指等的移动也可以充当输入设备。在这种情况下,可以根据手的移动或手指的取向来确定指向位置。
输出设备917由能够视觉地或听觉地将所获取的信息通知给用户的设备构成。输出设备917可以是诸如液晶显示器(lcd)、等离子显示面板(pdp)、有机电致发光(el)显示器和投影仪的显示设备,全息显示设备,诸如扬声器、头戴式耳机的音频输出设备,以及打印机设备等。输出设备917将通过信息处理系统10的处理而获得的结果输出为诸如文本或图像的视频,或者输出为诸如语音或声音的音频。此外,输出设备917可以包括例如用于照亮周围的灯。
存储设备919是被配置为信息处理系统10的存储部的示例的数据存储设备。存储设备919例如由诸如硬盘驱动(hdd)的磁存储设备、半导体存储设备、光存储设备、和磁光存储设备构成。存储设备919存储由cpu901执行的程序、各种数据、从外部获得的各种类型的数据等。
驱动921是用于诸如磁盘、光盘、磁光盘和半导体存储器的可移除存储介质927的读写器,并且可以合并在信息处理系统10中,或者在外部附接到信息处理系统10。驱动921读取存储在所附接的可移除存储介质927中的信息,并将该信息输出至ram905。此外,驱动921还在所附接的可移除存储介质927中进行写入。
连接端口923是用于直接将设备连接至信息处理系统10的端口。连接端口923可以是例如通用串行总线(usb)端口、ieee1394端口、或小型计算机系统接口(scsi)端口。此外,连接端口923可以是例如rs-232c端口、光学音频端子或高清晰度多媒体接口(hdmi,注册商标)端口。外部连接设备929被连接至连接端口923,从而可以在信息处理系统10与外部连接设备929之间进行各种类型的数据的交换。
通信设备925是例如由通信设备等构成的通信接口,通信设备925用于连接至通信网络931。通信设备925可以是例如用于有线或无线局域网(lan)、蓝牙(注册商标)或无线usb(wusb)的通信卡。此外,通信设备925可以是例如用于光通信的路由器、用于非对称数字用户线(adsl)的路由器或用于各种通信的调制解调器。通信设备925使用诸如tcp/ip的预定协议与因特网或其他通信装置发送和接收信号等。此外,连接至通信设备925的通信网络931是通过有线或无线连接的网络,例如因特网、家庭lan、红外通信、无线电波通信、卫星通信等。
图像捕获设备933通过使用诸如电荷耦合器件(ccd)或互补金属氧化物半导体(cmos)的图像传感器以及各种部件(诸如用于控制图像传感器上的对象图像的成像的透镜)来捕获真实空间并生成捕获的图像。图像捕获设备933可以捕获静态图像或运动图像。
传感器935是例如各种传感器,如加速度计、陀螺仪传感器、地磁传感器、光电传感器和声音传感器。传感器935获取有关信息处理系统10本身的状态的信息(如信息处理系统10的壳体的姿态),以及关于信息处理系统10的周围环境的信息(如信息处理系统10周围的亮度或噪声)。传感器935还可以包括gps传感器,gps传感器接收全球定位系统(gps)信号,并且测量纬度、经度和海拔高度。
以上描述给出了信息处理系统10的硬件配置的示例。上述部件中的每一个可以使用通用部件来配置,或者可以使用专用于每个部件的功能的硬件来配置。可以根据在实施时的技术水平来适当的改变这样的配置。
<2.结论>
如上所述,根据本公开内容的实施方式,提供了包括信息获取单元141和输出单元144的信息处理设备140。信息获取单元141被配置成获取与对声音采集单元120所采集的声音信息进行的语音识别处理有关的参数。输出单元144被配置成输出显示信息,该显示信息用于基于根据参数而指定的显示模式来显示声音信息的语音识别处理结果。该配置使得用户能够基于语音识别处理结果的显示模式来直观地了解语音识别处理执行的情况。
特别地,根据本公开内容的实施方式,在未获得期望的语音识别处理结果的情况下,可以通过视觉地识别根据与语音识别处理有关的参数而指定的语音识别结果,来直观地了解为什么没有获得期望的语音识别处理。在下一次发声中结合所理解的原因使得可以增大在下一次获得期望的语音识别处理结果的可能性。
此外,根据本公开内容的实施方式,可以在发声的同时地改变语音识别处理结果的显示模式。因此,根据本公开内容的实施方式,与以下情况相比,可以通过简单的方法来改变语音识别处理结果的显示模式:与发声分离地通过手动来进行改变显示模式的情况。
以上参照附图描述了本公开内容的优选实施方式,但是本公开内容不限于上述示例。本领域技术人员可以在所附权利要求的范围内找到各种变型和修改,并且应当理解,它们将自然地落入本公开的技术范围内。
此外,可以产生程序,该程序用于使结合在计算机中的硬件(诸如cpu、rom和ram)执行与上述控制单元140的功能等同的功能。此外,还可以提供存储有该程序的计算机可读记录介质。
此外,在实现上述信息处理系统10的操作时,每个部件的位置不限于特定位置。作为特定示例,可以将控制单元140设置在与以下设备不同的设备中:所述设备设置有图像输入单元110、操作输入单元115、声音采集单元120、通信单元125、显示单元130和声音输出单元135。这些设备可以经由网络连接。在这种情况下,控制单元140可以对应于例如服务器(如网络服务器或云服务器)。图像输入单元110、操作输入单元115、生物信息输入单元118、声音采集单元120、通信单元125、显示单元130和声音输出单元135可以对应于经由网络连接至服务器的客户端。
此外,控制单元140中包括的所有部件不一定被设置在同一设备中。在一个示例中,可以将信息获取单元141、语音识别单元142、显示模式指定单元143、以及输出单元144中的一些包括在与设置有控制单元140的设备不同的设备中。在一个示例中,可以将语音识别单元142和显示模式指定单元143包括在与设置有控制单元140的服务器不同的服务器中,其中该控制单元140包括信息获取单元141和输出单元144。
此外,在本说明书中描述的效果仅是说明性和示例性的效果,不是限制性的。换言之,与上述效果一起或取代上述效果,根据本公开内容的技术可以实现根据本说明书的描述对本领域技术人员而言清楚明显的其他效果。
此外,本技术也可配置如下。
(1)
一种信息处理设备,包括:
信息获取单元,所述信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
输出单元,所述输出单元被配置成输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果。
(2)
根据(1)所述的信息处理设备,
其中,所述参数包括用户的发声信息,所述发声信息被包括在所述声音信息中。
(3)
根据(1)所述的信息处理设备,
其中,所述参数包括与对应于用户的发声的噪声有关的信息,与所述噪声有关的信息被包括在所述声音信息中。
(4)
根据(3)所述的信息处理设备,
其中,与所述噪声有关的信息包括以下中的至少一个:噪声的类型、噪声的音量、以及从噪声源到声音采集单元的方向。
(5)
根据(2)所述的信息处理设备,
其中,所述用户的发声信息包括以下中的至少一个:所述声音信息中包括的用户的发声音量、声音信息的语音相似度、声音信息的频率、所述声音信息中包括的语音的发声速度、与所述声音信息中包括的语音的词尾有关的信息、以及语音识别处理结果的置信度水平。
(6)
根据(1)至(5)中任一项所述的信息处理设备,还包括:
其中,所述显示模式包括以下中的至少一个:语音识别处理结果的尺寸、形状、饱和度、字体、模糊度、及破裂度、被添加至语音识别处理结果的动画图像的类型、以及被添加至语音识别处理结果的对象的类型。
(7)
根据(1)至(6)中任一项所述的信息处理设备,
其中,所述显示模式被进一步基于与第一用户有关的信息来指定。
(8)
根据(7)所述的信息处理设备,
其中,与第一用户有关的信息包括所述第一用户的生物信息和情感信息中的至少一个。
(9)
根据(7)所述的信息处理设备,
其中,与第一用户有关的信息包括所述第一用户的性别和年龄中的至少一个。
(10)
根据(7)所述的信息处理设备,
其中,与第一用户有关的信息包括以下中的至少一个:所述第一用户的行为信息、所述第一用户所操作的设备的类型、以及所述第一用户周围的环境信息。
(11)
根据(7)至(10)中任一项所述的信息处理设备,
其中,所述输出单元能够输出所述显示信息,使得基于所述显示模式的语音识别处理结果被不同于所述第一用户的第二用户视觉地识别。
(12)
根据(11)所述的信息处理设备,
其中,所述输出单元能够切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
(13)
根据(12)所述的信息处理设备,
其中,所述输出单元基于所述第二用户的状态来切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
(14)
根据(13)所述的信息处理设备,
其中,所述输出单元在所述第二用户处于预定状态的情况下输出所述显示信息,使得基于不同于所述显示模式的另一显示模式,所述语音识别处理结果被所述第二用户视觉地识别。
(15)
根据(12)至(14)中任一项所述的信息处理设备,
其中,所述输出单元基于所述第一用户与所述第二用户之间的关系来切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
(16)
根据(15)所述的信息处理设备,
其中,所述输出单元在所述第一用户与所述第二用户之间的关系指示预定关系的情况下输出所述显示信息,使得基于不同于所述显示模式的另一显示模式,所述语音识别处理结果被所述第二用户视觉地识别。
(17)
根据(7)至(16)中任一项所述的信息处理设备,
其中,能够基于所述第一用户的预定改变操作来改变所述显示模式。(18)
根据(1)至(17)中任一项所述的信息处理设备,还包括:
显示模式指定单元,该显示模式指定单元被配置成根据所述参数来指定所述显示模式。
(19)
一种信息处理的方法,所述方法包括:
获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
由处理器输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果。
(20)
一种用于使计算机用作信息处理设备的程序,所述信息处理设备包括:
信息获取单元,所述信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
输出单元,所述输出单元被配置成输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果。
附图标记列表
10信息处理系统
110图像输入单元
115操作输入单元
118生物信息输入单元
120声音采集单元
125通信单元
130显示单元
135声音输出单元
140控制单元(信息处理设备)
141信息获取单元
142语音识别单元
143显示模式指定单元
144输出单元
180显示单元
权利要求书(按照条约第19条的修改)
1.一种信息处理设备,包括:
信息获取单元,所述信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
输出单元,所述输出单元被配置成输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果,
其中,所述显示模式包括以下中的至少一个:被添加至所述语音识别处理结果的动画图像的类型以及被添加至所述语音识别处理结果的对象的尺寸。
2.根据权利要求1所述的信息处理设备,
其中,所述参数包括用户的发声信息,所述发声信息被包括在所述声音信息中。
3.根据权利要求1所述的信息处理设备,
其中,所述参数包括与对应于用户的发声的噪声有关的信息,与所述噪声有关的信息被包括在所述声音信息中。
4.根据权利要求3所述的信息处理设备,
其中,所述与噪声有关的信息包括以下中的至少一个:噪声的类型、噪声的音量、以及从噪声源到声音采集单元的方向。
5.根据权利要求2所述的信息处理设备,
其中,所述用户的发声信息包括以下中的至少一个:所述声音信息中包括的用户的发声音量、所述声音信息的语音相似度、所述声音信息的频率、所述声音信息中包括的语音的发声速度、与所述声音信息中包括的语音的词尾有关的信息、以及语音识别处理结果的置信度水平。
6.根据权利要求1所述的信息处理设备,
其中,所述显示模式包括以下中的至少一个:语音识别处理结果的尺寸、形状、饱和度、字体、模糊度、及破裂度,以及被添加至语音识别处理结果的对象的类型。
7.根据权利要求1所述的信息处理设备,
其中,所述显示模式被进一步基于与第一用户有关的信息来指定。
8.根据权利要求7所述的信息处理设备,
其中,与第一用户有关的信息包括所述第一用户的生物信息和情感信息中的至少一个。
9.根据权利要求7所述的信息处理设备,
其中,与第一用户有关的信息包括所述第一用户的性别和年龄中的至少一个。
10.根据权利要求7所述的信息处理设备,
其中,与第一用户有关的信息包括以下中的至少一个:所述第一用户的行为信息、所述第一用户所操作的设备的类型、以及所述第一用户周围的环境信息。
11.根据权利要求7所述的信息处理设备,
其中,所述输出单元能够输出所述显示信息,使得基于所述显示模式的语音识别处理结果被不同于所述第一用户的第二用户视觉地识别。
12.根据权利要求11所述的信息处理设备,
其中,所述输出单元能够切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
13.根据权利要求12所述的信息处理设备,
其中,所述输出单元基于所述第二用户的状态来切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
14.根据权利要求13所述的信息处理设备,
其中,所述输出单元在所述第二用户的状态为处于预定状态的情况下输出所述显示信息,使得基于不同于所述显示模式的另一显示模式,所述语音识别处理结果被所述第二用户视觉地识别。
15.根据权利要求12所述的信息处理设备,
其中,所述输出单元基于所述第一用户与所述第二用户之间的关系来切换是否输出所述显示信息,使得基于所述显示模式的语音识别处理结果被所述第二用户视觉地识别。
16.根据权利要求15所述的信息处理设备,
其中,所述输出单元在所述第一用户与所述第二用户之间的关系指示预定关系的情况下输出所述显示信息,使得基于不同于所述显示模式的另一显示模式,所述语音识别处理结果被所述第二用户视觉地识别。
17.根据权利要求7所述的信息处理设备,
其中,能够基于所述第一用户的预定改变操作来改变所述显示模式。
18.根据权利要求1所述的信息处理设备,还包括:
显示模式指定单元,所述显示模式指定单元被配置成根据所述参数来指定所述显示模式。
19.一种信息处理方法,所述方法包括:
获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
由处理器输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果,
其中,所述显示模式包括以下中的至少一个:被添加至所述语音识别处理结果的动画图像的类型以及被添加至所述语音识别处理结果的对象的尺寸。
20.一种用于使计算机用作信息处理设备的程序,所述信息处理设备包括:
信息获取单元,所述信息获取单元被配置成获取与对基于声音采集的声音信息进行的语音识别处理有关的参数;以及
输出单元,所述输出单元被配置成输出显示信息,所述显示信息用于基于根据所述参数而指定的显示模式来显示所述声音信息的语音识别处理结果,
其中,所述显示模式包括以下中的至少一个:被添加至所述语音识别处理结果的动画图像的类型以及被添加至所述语音识别处理结果的对象的尺寸。
- 还没有人留言评论。精彩留言会获得点赞!